ORM
即Object-Relational Mapping,它的作用是在关系型数据库和对象之间作一个映射,这样,我们在具体的操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了。
MyBatis的优点
- 使用线程池,复用;
- 方便配置;
- 对SQL有较好的封装。
与Hibernate的横向对比:
| MyBatis | Hibernate | |
|---|---|---|
| ORM标准程度 | 半标准 | 完全标准 |
| 难易程度 | 简单 | 难 |
| 不同数据库的迁移难易度 | 难 | 简单 |
| 重量级 | 轻量 | 重量 |
原理
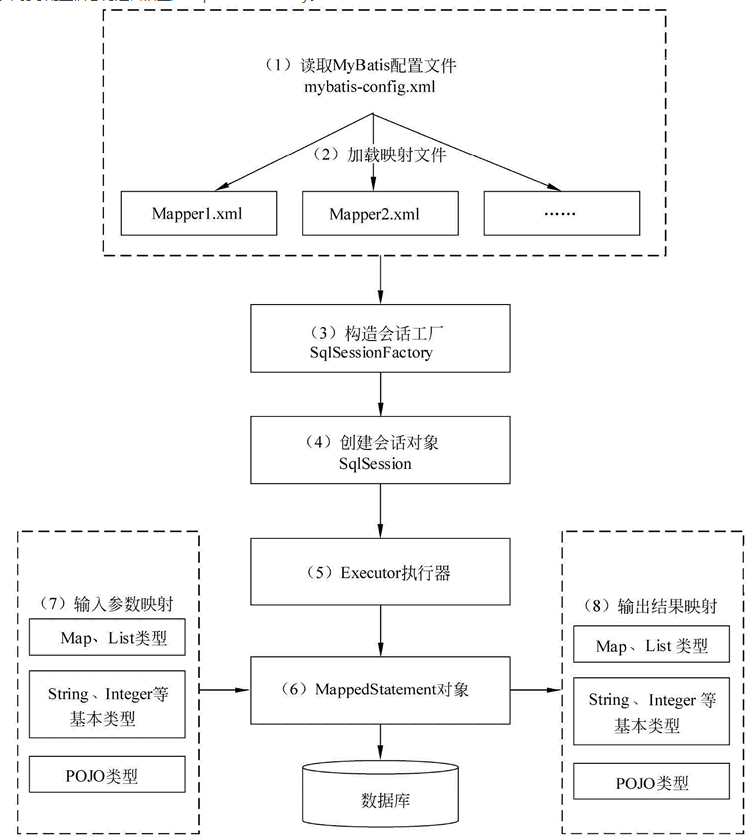
- 读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
- 加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
- 构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
- 创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
- Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
- MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
- 输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
${}和#{}的区别
{} 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符,一个 #{ } 被解析为一个参数占位符;而${}仅仅为一个纯碎的 string 替换,在动态 SQL 解析阶段将会进行变量替换。
{} 解析之后会将String类型的数据自动加上引号,其他数据类型不会;而${} 解析之后是什么就是什么,他不会当做字符串处理。
{} 很大程度上可以防止SQL注入(SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作);而${} 主要用于SQL拼接的时候,有很大的SQL注入隐患。
- 在某些特殊场合下只能用${},不能用#{}。例如:在使用排序时ORDER BY ${id},如果使用#{id},则会被解析成ORDER BY “id”,这显然是一种错误的写法。
动态SQL
使用场景:
对于一些复杂的查询,我们可能会指定多个查询条件,但是这些条件可能存在也可能不存在,需要根据用户指定的条件动态生成SQL语句。
主要元素:
- if
- choose / when / otherwise
- trim:可以用于where和set,可以写前缀与后缀
- where
- set
- foreach
命名空间
在MyBatis中,可以为每个映射文件起一个唯一的命名空间(接口的全限定名),这样定义在这个映射文件中的每个SQL语句就成了定义在这个命名空间中的一个ID。只要我们能够保证每个命名空间中这个ID是唯一的,即使在不同映射文件中的语句ID相同,也不会再产生冲突了。接口和XML的关联
当调用一个接口的方法时,会先通过接口的全限定名称和当前调用的方法名的组合得到一个方法 id,这个 id 的值就是映射 XML 中namespace和具体方法id的组合。所以可以在代理方法中使用 sqlSession 以命名空间的方式调用方法。通过这种方式可以将接口和XML文件中的方法关联起来。缓存
MyBatis中使用缓存来提高其性能。
MyBatis中的缓存分为两种:一级缓存和二级缓存。使用过MyBatis的可能听到过这样一句话“一级缓存是sqlSession级别的,二级缓存是mapper级别的”。这也说明了,当使用同一个sqlSession时,查询到的数据可能是一级缓存;而当使用同一个mapper是,查询到的数据可能是二级缓存。
如果配置了二级缓存,则查询顺序为:二级缓存→一级缓存→数据库。
一级缓存
一级缓存mybatis已近为我们自动开启,不用我们手动操作,而且我们是关闭不了的,但是我们可以手动清除缓存。执行查询时,SqlSession是将任务交给Executor来完成对数据库的各种操作,所以在Executor查询前,会先去查询缓存。
一级缓存在PerpetualCache中维护一个叫cache的HashMap来进行缓存的存储:
private Map<Object, Object> cache = new HashMap<Object, Object>();
根据 statementId 、 rowBounds 、传递给JDBC的SQL 和rowBounds.limit决定key中的hashcode。因此,相同的操作就会有相同的hashcode,来保证一个cacheKey对应一个操作。
总结:当查询相同的结果时,就会使用一级缓存。
二级缓存
当我们的配置文件mybatis-config.xml 配置了cacheEnabled=true时,就会开启二级缓存,二级缓存是mapper级别的,也就说不同的sqlsession使用同一个mapper查询是,查询到的数据可能是另一个sqlsession做相同操作留下的缓存。
SqlSession对象创建Executor对象时,会对Executor对象加上一个装饰者:CachingExecutor,然后将操作数据库的任务交给CachingExecutor,此时CachingExecutor会查找二级缓存是否有需要的数据,如果没有则将任务交给Executor对象。数据将会存放在Configuration中。
当在其他的Session中执行增删改操作时,二级缓存会被清空。
开启场景:
- 因为所有的增删改都会刷新二级缓存,导致二级缓存失效,所以适合在查询为主的应用中使用,比如历史交易、历史订单的查询。否则缓存就失去了意义。
- 如果多个namespace 中有针对于同一个表的操作,比如Blog 表,如果在一个namespace 中刷新了缓存,另一个namespace 中没有刷新,就会出现读到脏数据的情况。所以,推荐在一个Mapper 里面只操作单表的情况使用。

若有收获,就点个赞吧
0 人点赞
