产品家族及基本概念
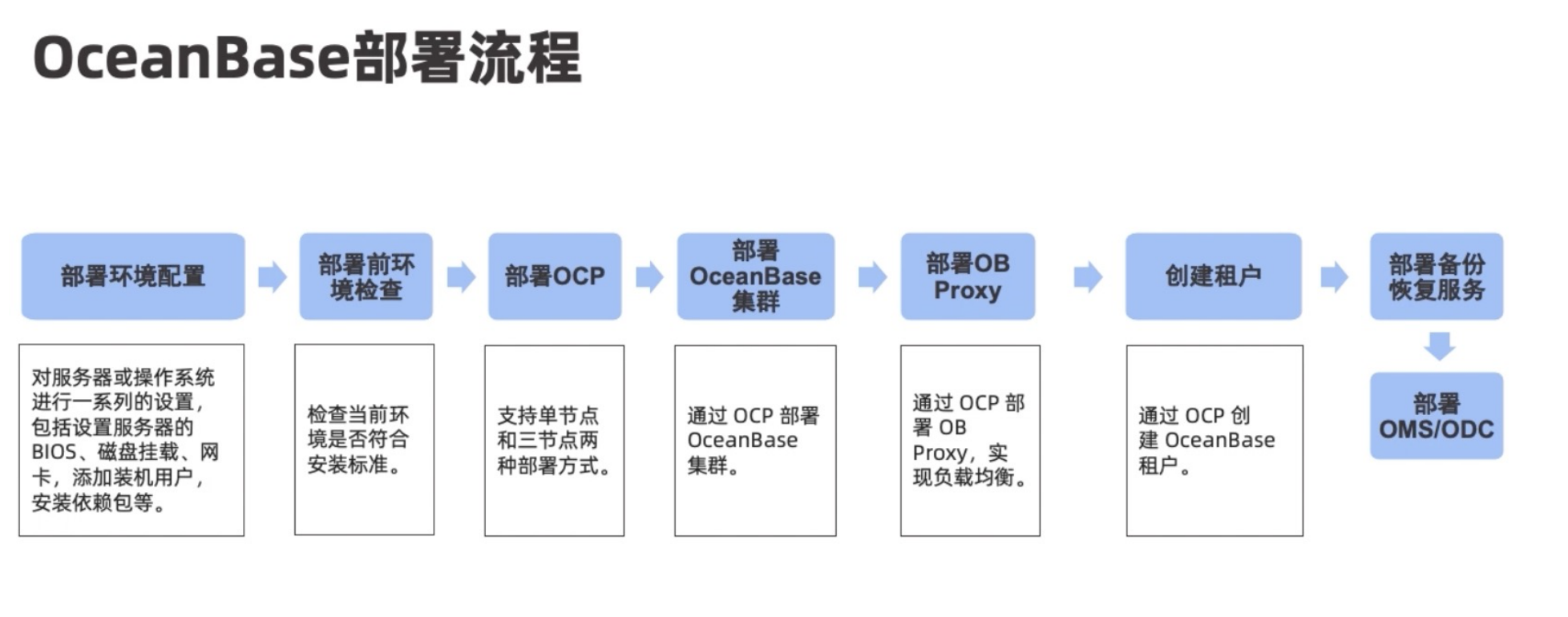
部署
部署形式: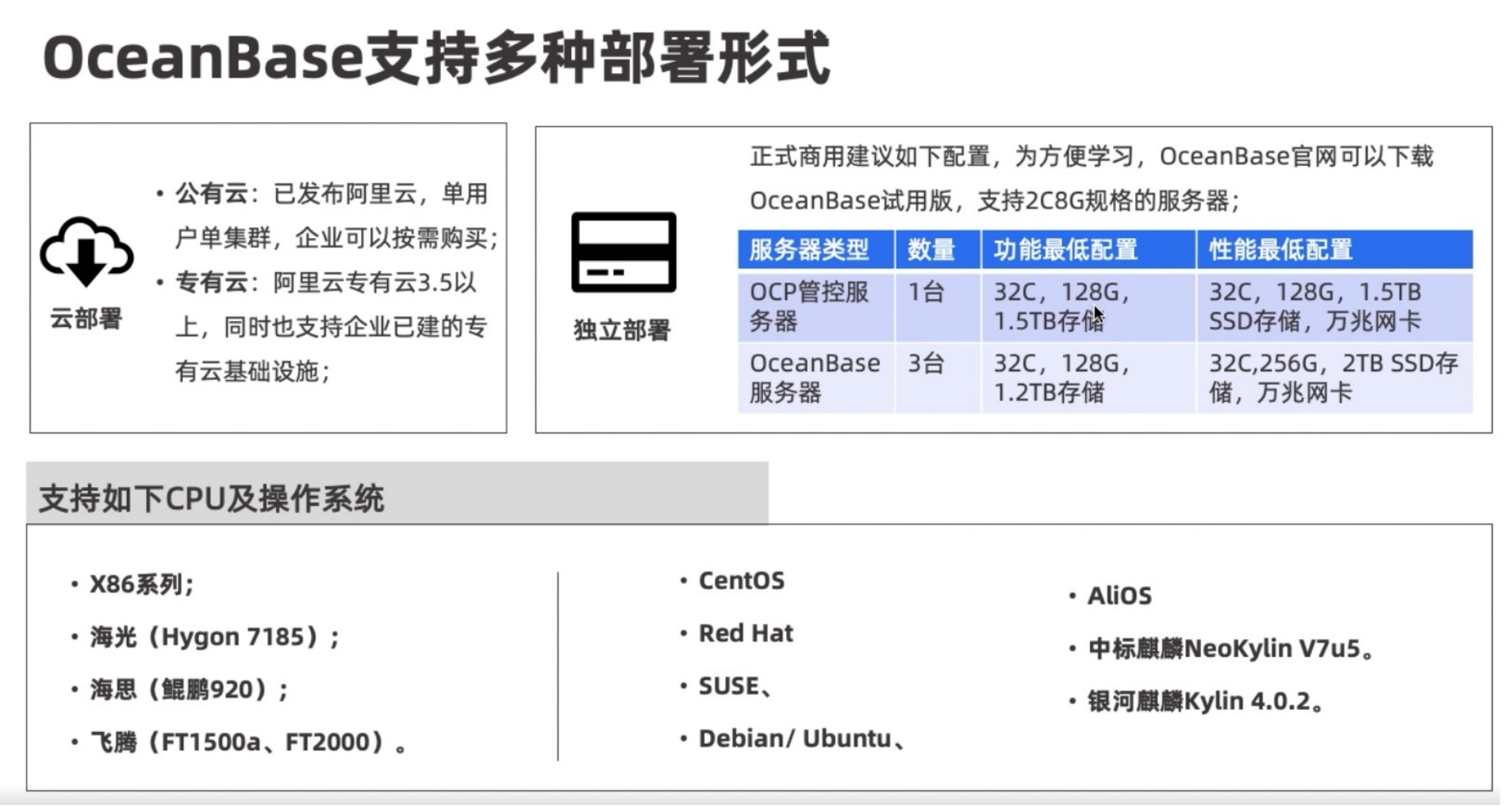
基础概念
主要的概念有集群、Zone、OB Server、资源池、租户
Zone就是区域,有几个Zone就会有几个副本;每个Zone又有多个OB Server,即服务器,每个OB Server具有独立的SQL内核和引擎;多个OB Server划分资源构成了一个资源池,用户无法直接使用,因此又有了租户的概念,每个租户会从资源池中获得一个虚拟的小的资源池,用以创建数据库表。
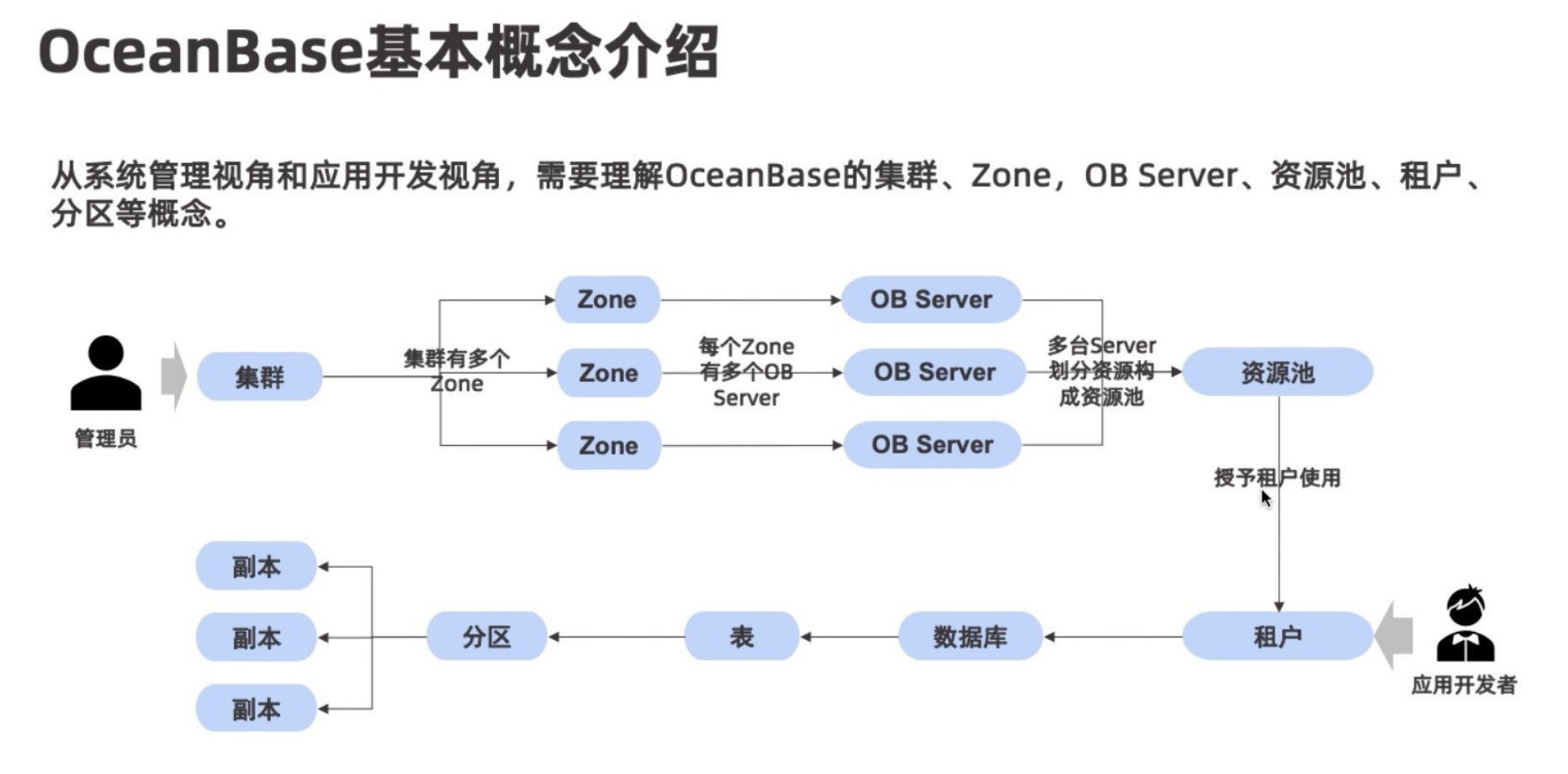
1.一个集群由多个Zone组成,给集群内的一批机器打上同一个tag,就属于同一个Zone;
2.不同的Zone可以对应不同的城市,也可以对应不同的机房或是机架;
3.Zone个数应≥3,且应是奇数;
4.每个Zone均有且只有一份完整数据;
5.每台OB Server相互独立,有独立计算和存储引擎。
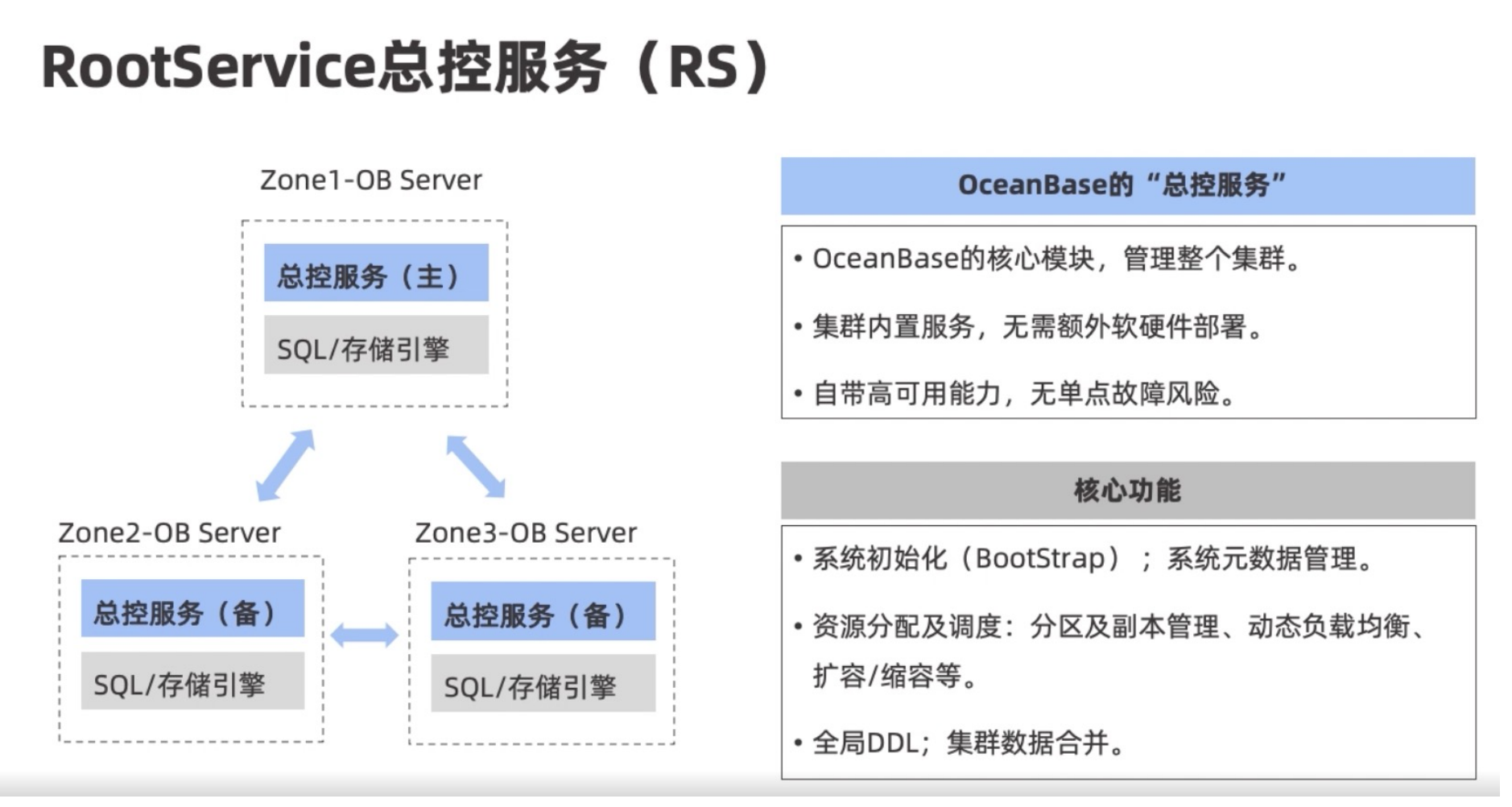
总控服务
总控服务相当于整个集群的大脑,负责协调资源分配等等,具体功能如下:
租户
租户相当于一个RDS实例,一个应用占用一个租户,可以申请符合实际要求的系统资源。主要分为系统租户和业务租户,系统租户主要存储系统表,业务租户给业务方使用。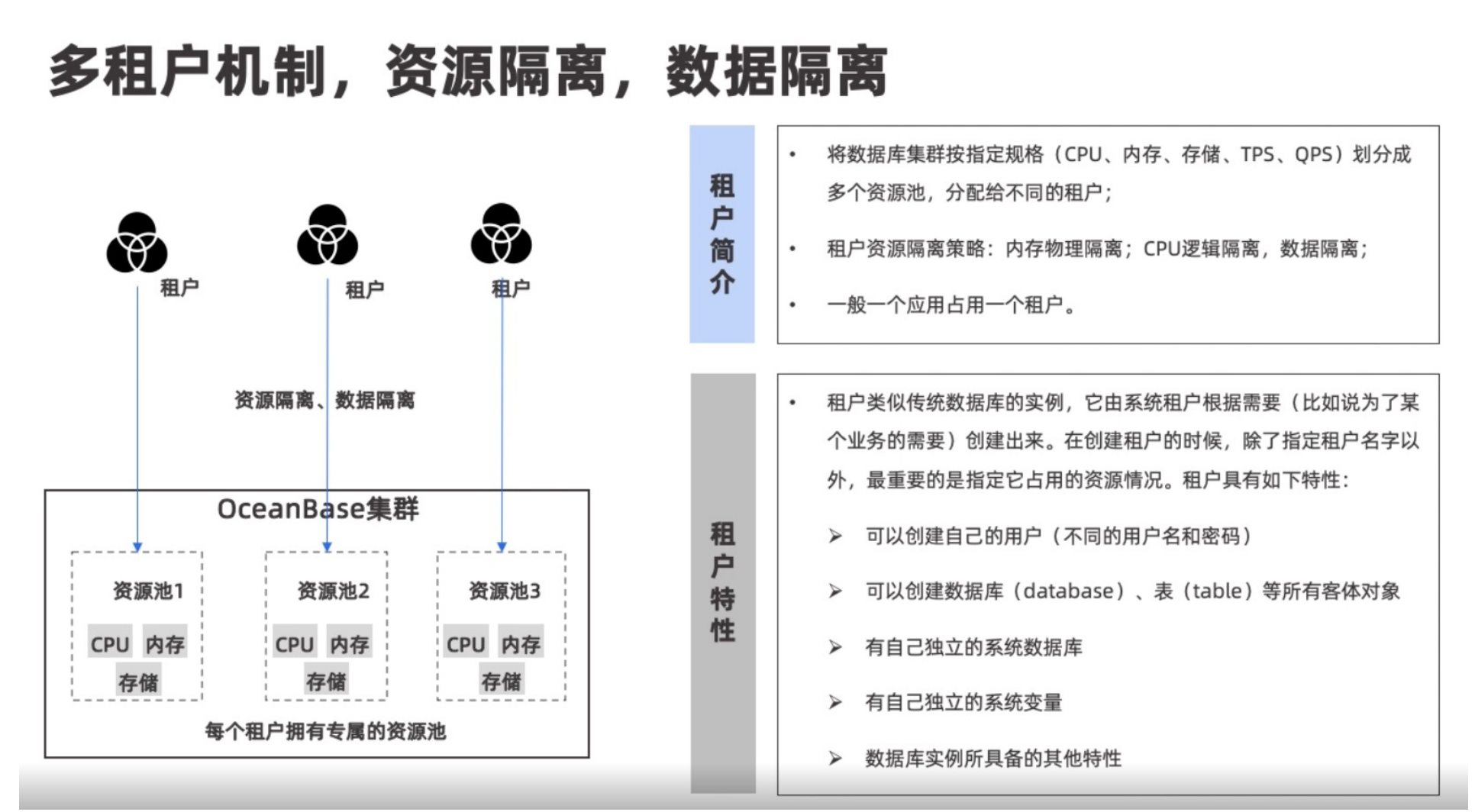
资源池分配
下图是每个租户在资源池中的分配情况,比较抽象,也比较重要。OceanBase有个核心的概念叫做Unit,即一个单元,如果数量为1,那么会在三个Zone中创建一个Unit;如果数量为2,那么会在三个Zone中创建两个Unit,并分配在不同的OB Server上,一个租户在同一个Server上最多有一个Unit;数量为3同理。
OceanBase集群技术架构
Paxos协议与负载均衡
Oceanbase支持三种日志,分别是全能型,日志型和只读型,如下图所示。
OceanBase以分区为单位,实现更细粒度的管控;组员自动选举,不需要人工干预;分区默认均匀分布在机器上;
主副本默认均匀分布在各个Zone内;每台OBServer均可以独立执行SQL,如果需要访问不同OB Server,会自动路由,业务无感知。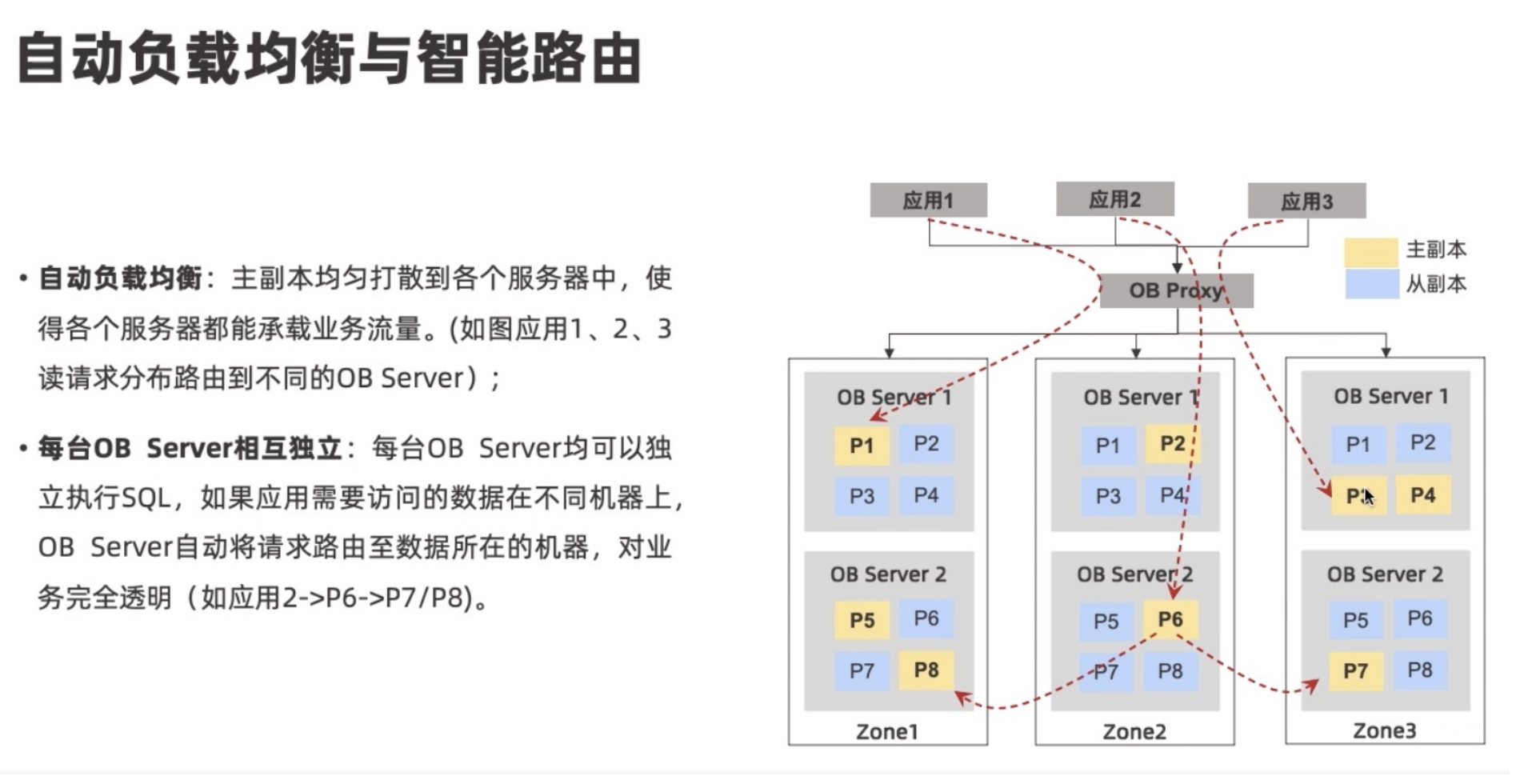
从副本数据同步:
1.Paxos通过redo-log同步;
2.多数派完成同步即反馈成功。
OB Proxy
功能:
1.对SQL做基本解析,确定leader所在机器;
2.反向代理,将请求路由至对应Leader,Leader位置未知则随机路由到一台OB Server;
3.轻量SQL解析+快速转发,保证高性能。
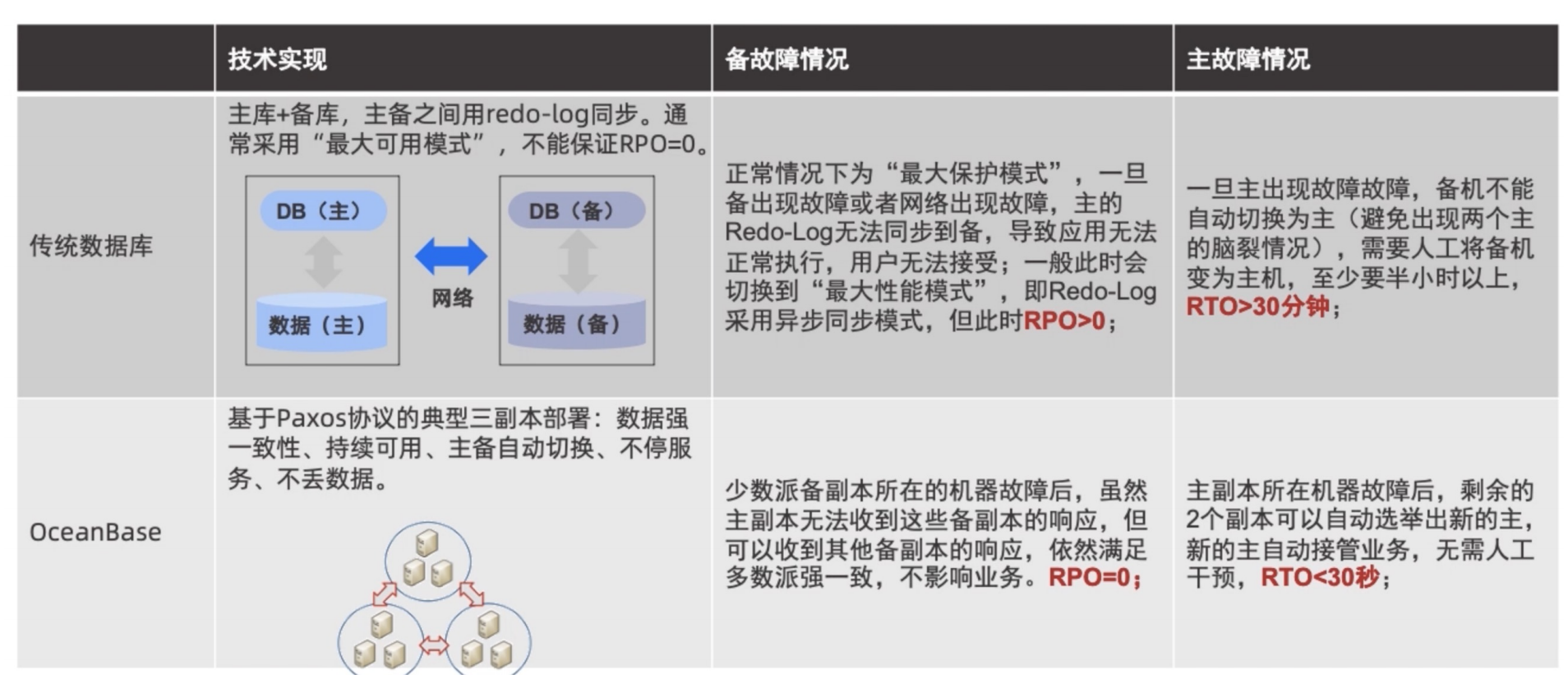
数据可靠及高可用
RTO(数据可用性):在故障或灾难发生之后,数据库停止工作的最高可承受时间,是一个最大容忍时限,必须在此时限内恢复数据;
RPO(数据可靠性):这是一个过去的时间点,当灾难或紧急时间发生时,数据可以恢复到的时间点,是业务系统所能容忍的数据丢失量。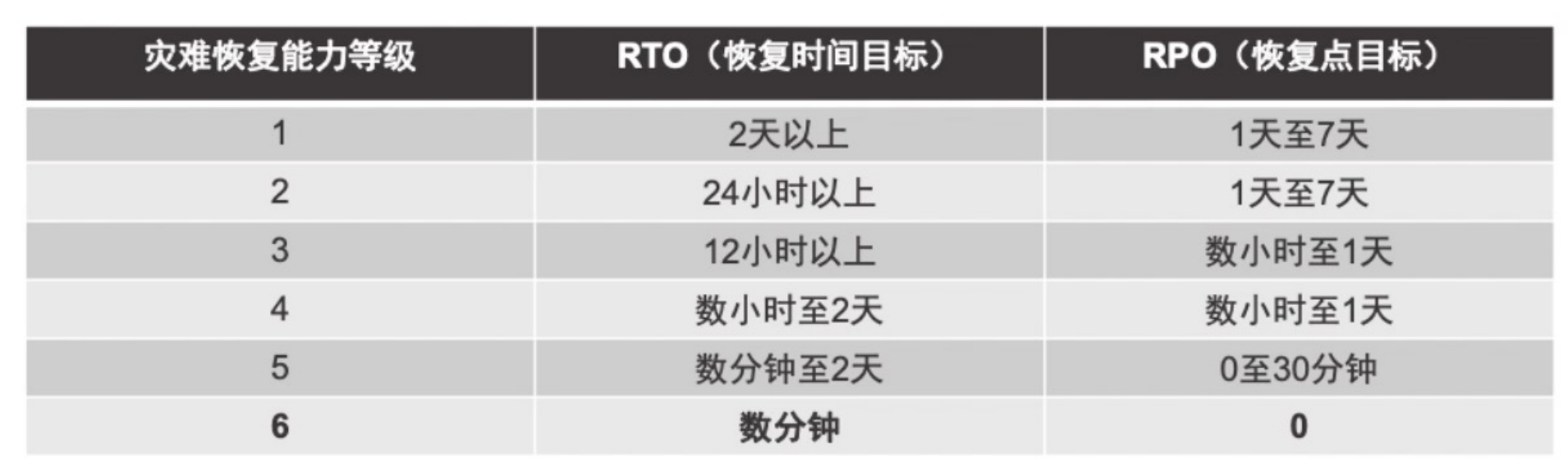
OceanBase RTO<30s;RPO=0,即能在30s内恢复业务,且不丢失任何数据。
故障自动恢复
容灾
同城三机房
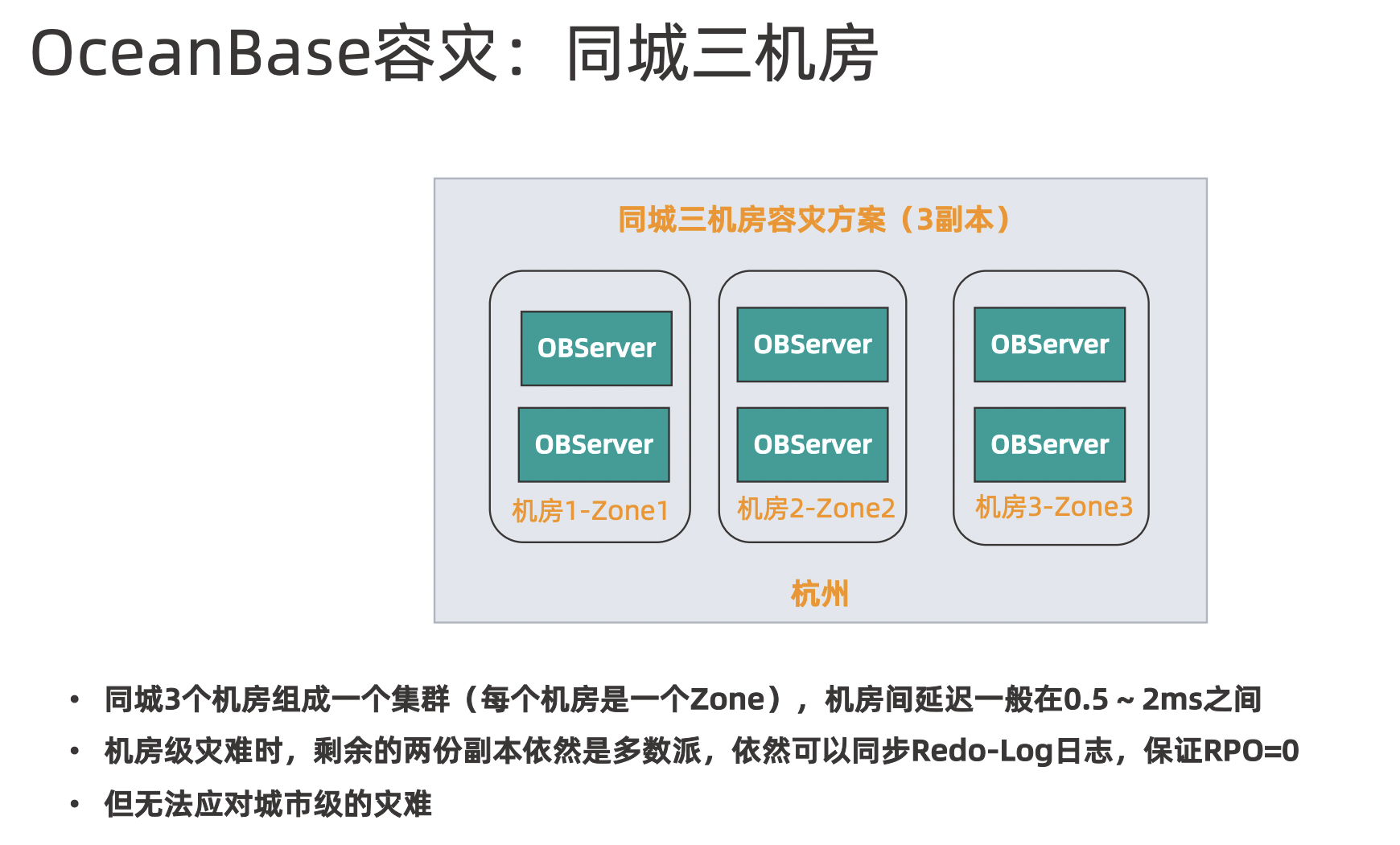
三地五中心
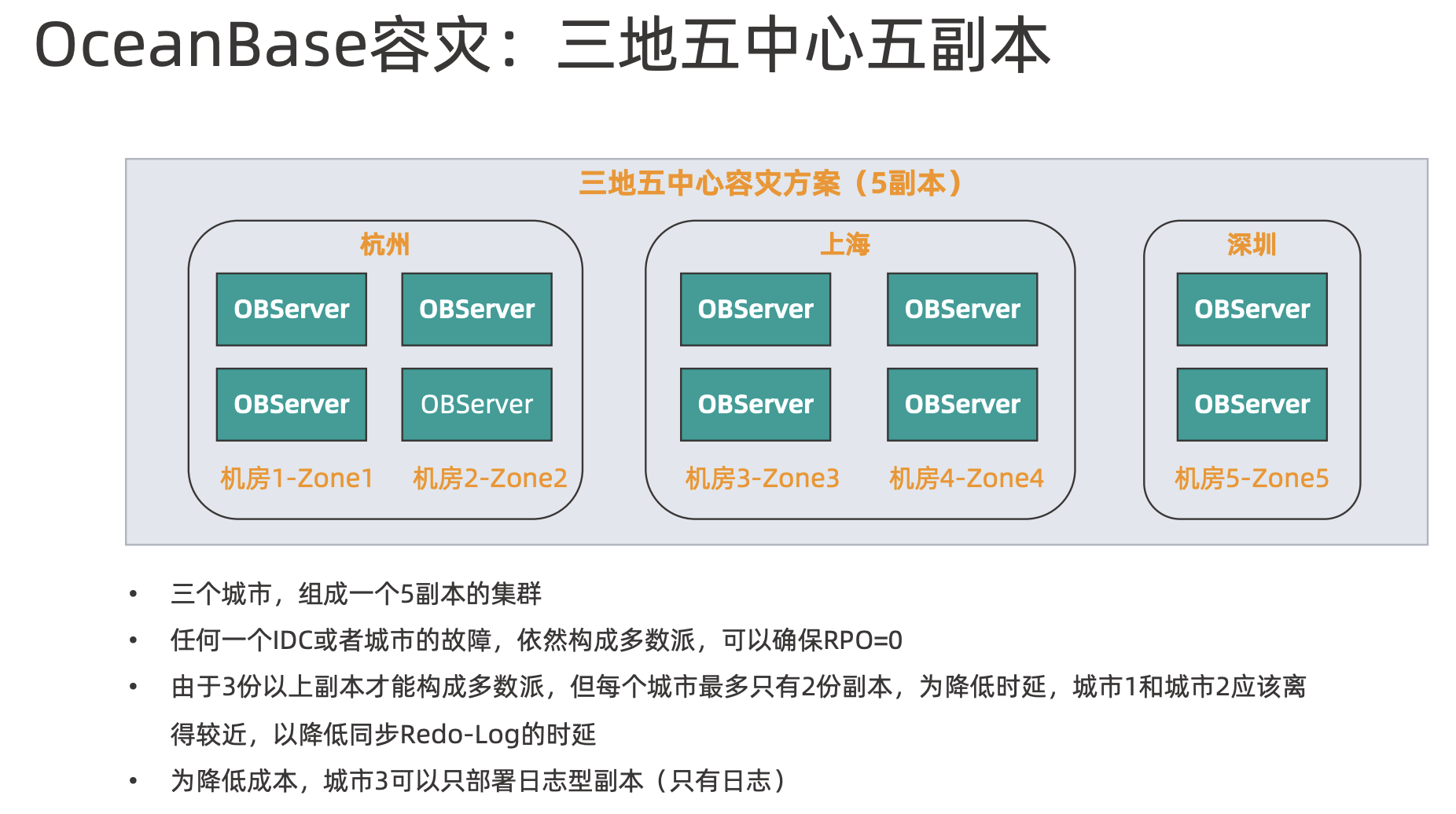
同城两机房-主备
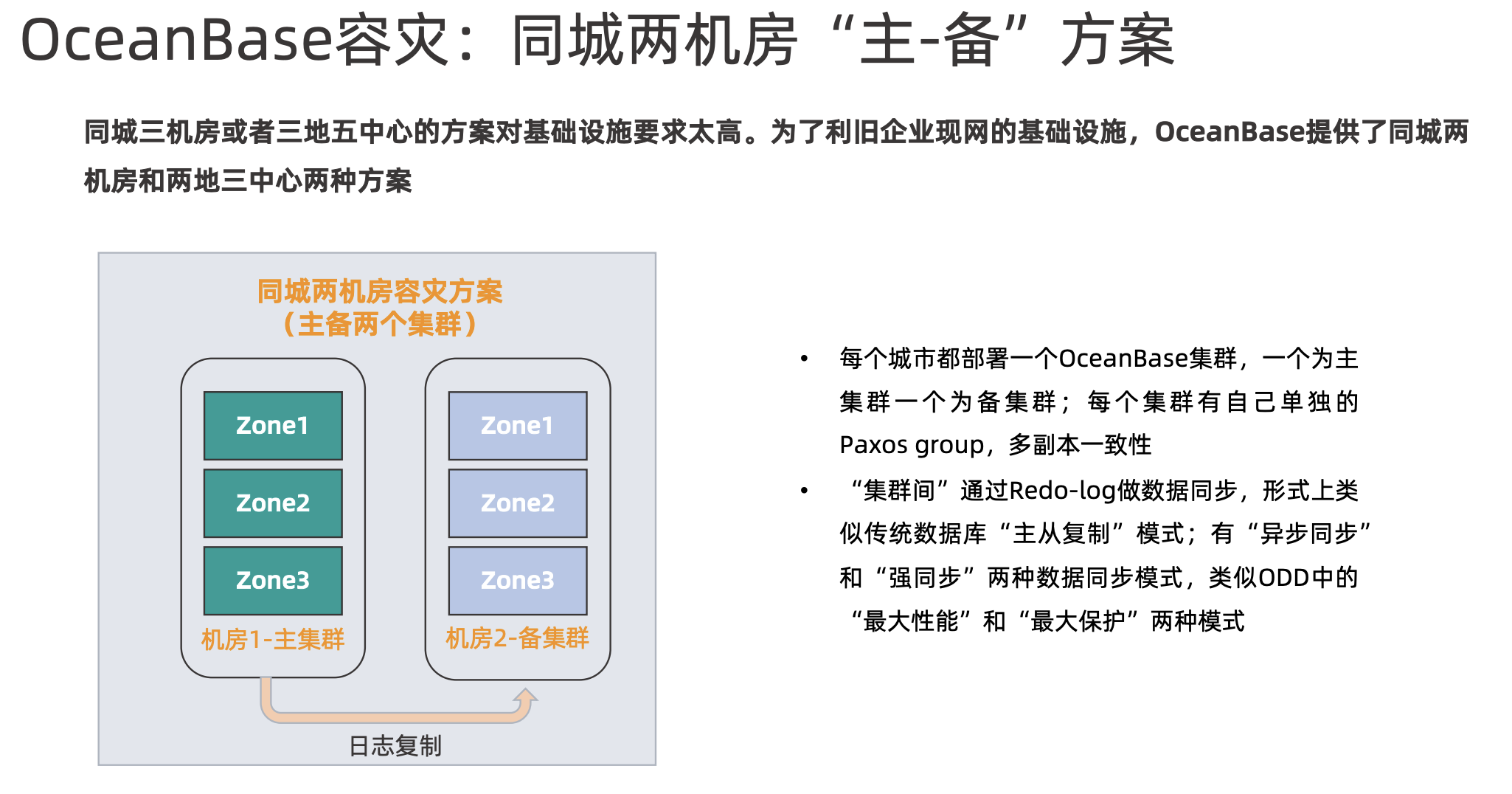
两地三中心-主备
扩容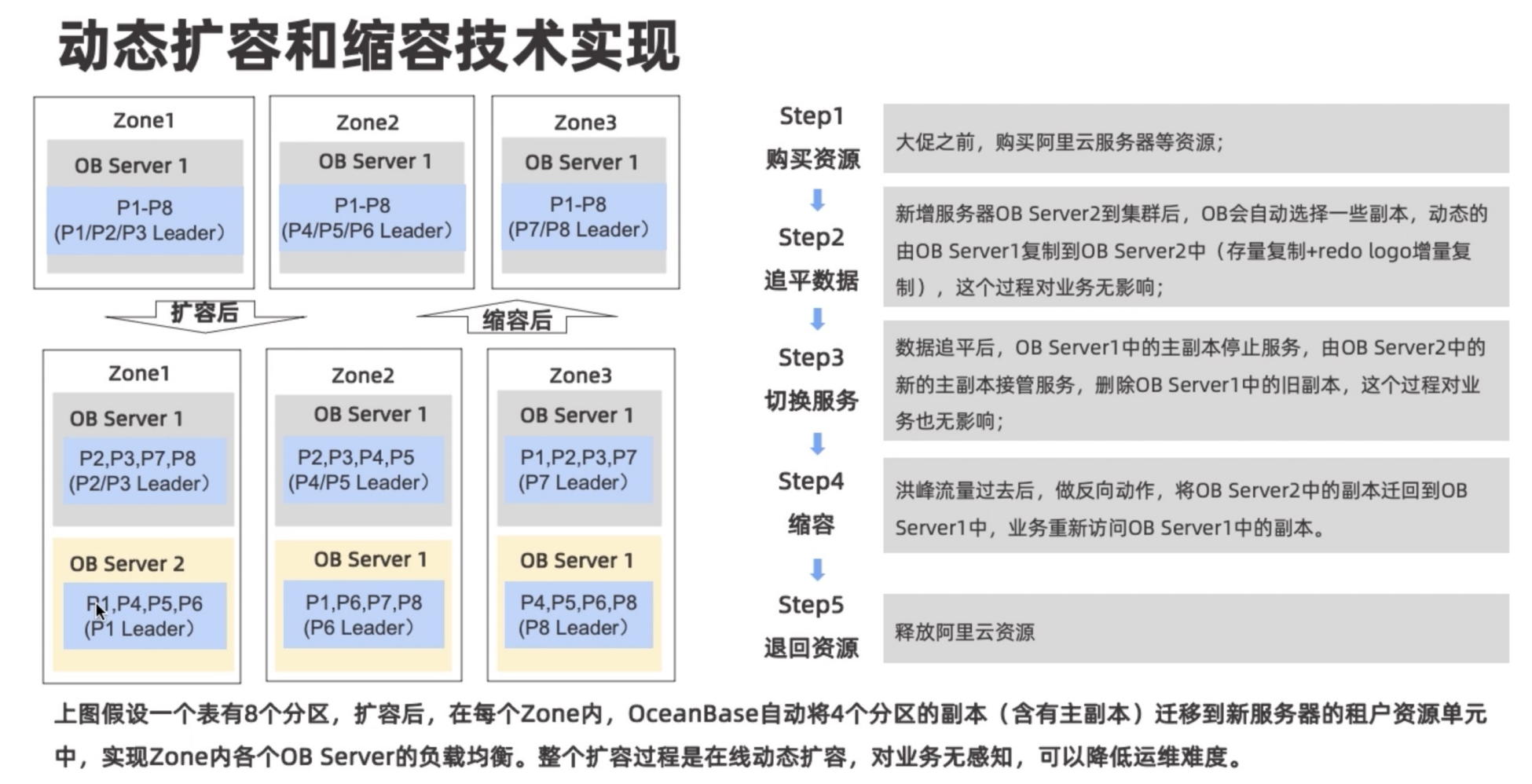
OceanBase整体扩容过程比较平滑,可以实现业务无感知,而不用去重新分配分片规则等等,系统可自动根据机器状况分配主从。
分布式事务、MVCC、事务隔离级别
原子性的保证:两阶段提交
隔离性保证:MVCC
一致性的保证:主键唯一约束,全局快照——1s内获取快照次数200万次
持久性的保证:Redo-Log使用Proxy协议做多副本同步
原子性
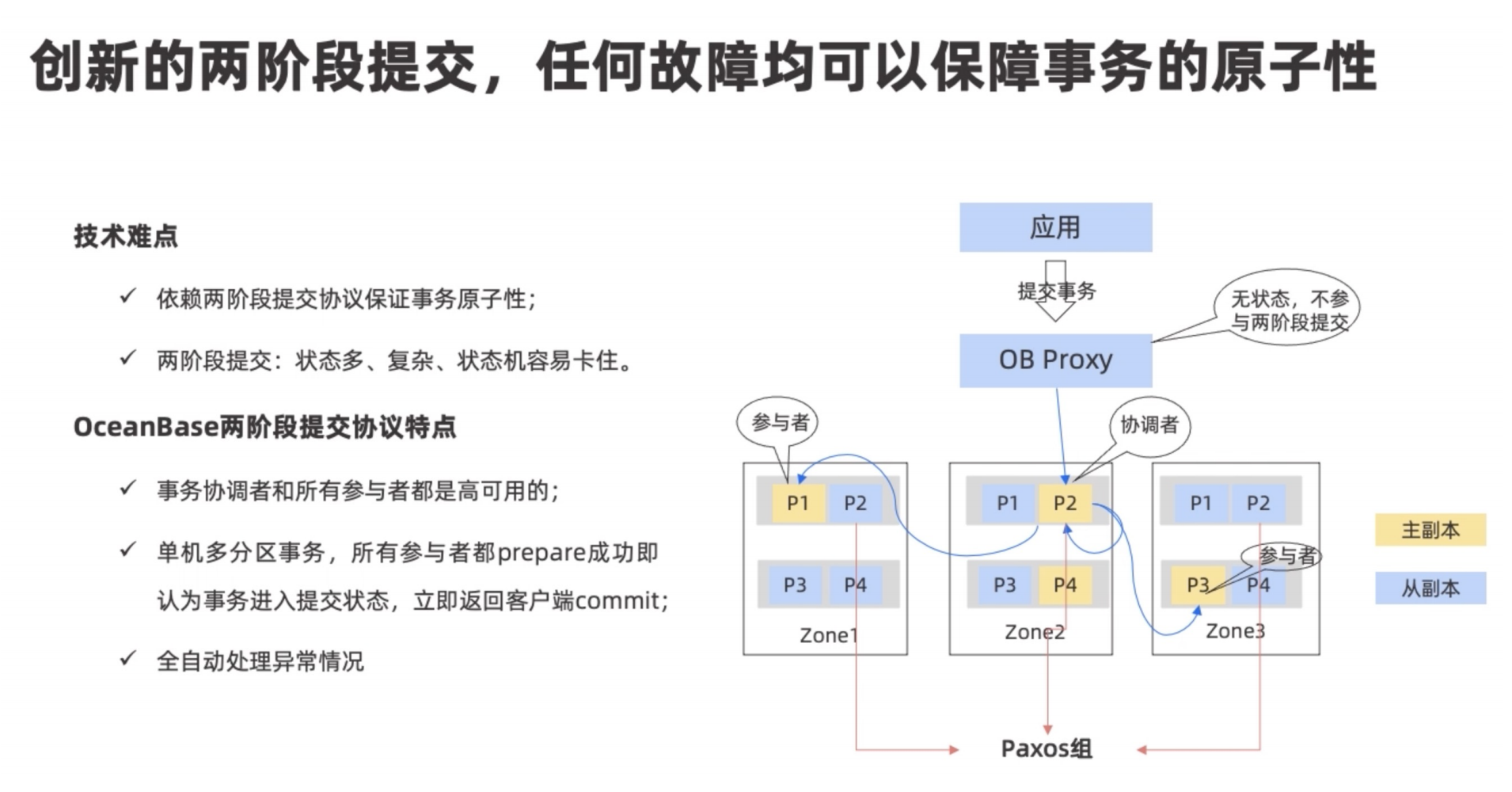
OceanBase的原子性通过两阶段提交保证。所有的协调者与参与者都是leader,事务执行过程中,主会向从同步redo-log,任意服务器发生故障后,剩下的从服务器会先选出主服务器,然后继续执行事务。
隔离性

OceanBase支持两种隔离级别,如下:
| 隔离级别 | 效果 | 是否默认 |
|---|---|---|
| Read-Committed | 不存在脏读,但存在不可重复读和幻读 | 是 |
| Serializable | 不存在脏读,不可重复读,幻读 | 否 |
OceanBase的SQL引擎与存储引擎
SQL引擎
兼容MySQL与Oracle,MySQL语法5.6全兼容,因此不需要学习额外的SQL语言。
存储引擎与备份恢复
传统存储引擎是从硬盘中各个页中读取,到内存处理后,还是需要将数据写回对应的页,容易造成大量的随机写,影响性能。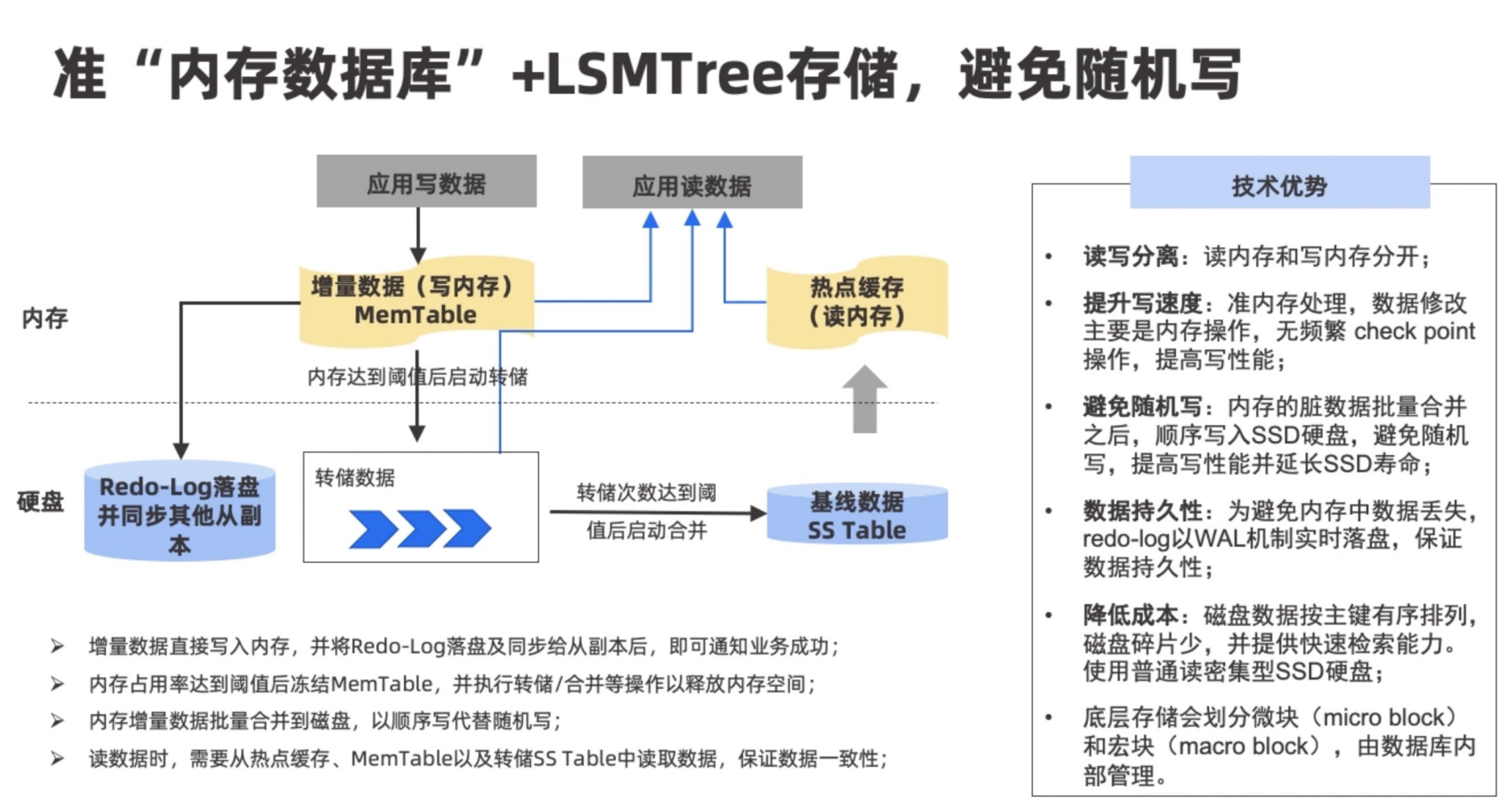
OceanBase在内存层面,专门分为了读内存与写内存;写内存根据阈值写入转储数据(由租户设定大小),并释放内存空间,转储数据再定时或根据阈值与基线数据合并,同时,为了安全,也同时Redo-Log落盘同步其他从副本;
读取时,需要从基线数据的热点缓存,转储数据,MemTable中读取,由于数据可能会不一致,还要做判断返回,因此读性能会有一定的损耗。
当然,也有合并的方式,跳过转储,内存直接与基线数据进行合并,但是由于通常是大批量数据进行合并,会有较大的性能影响,所以不推荐此方式。
一下是转储与合并方式的对比:
| 转储 | 合并 |
|---|---|
| Partition级别,只是MemTable的物化 | 全局级别,产生一个全局快照 |
| 每个Partition独立决定自己MemTable的冻结操作,主备Partition无需保持一致 | 全局partition一起做MemTable的冻结操作,要求主备Partition保持一致 |
| 转储只与相同大版本的Minor SSTable合并,产生新的Minor SSTable,所以只包含增量数据,最终被删除的行需要标记 | 合并会把当前大版本的SSTable和MemTable与前一个大版本的全量静态数据进行合并,产生新的全量数据 |


压缩策略
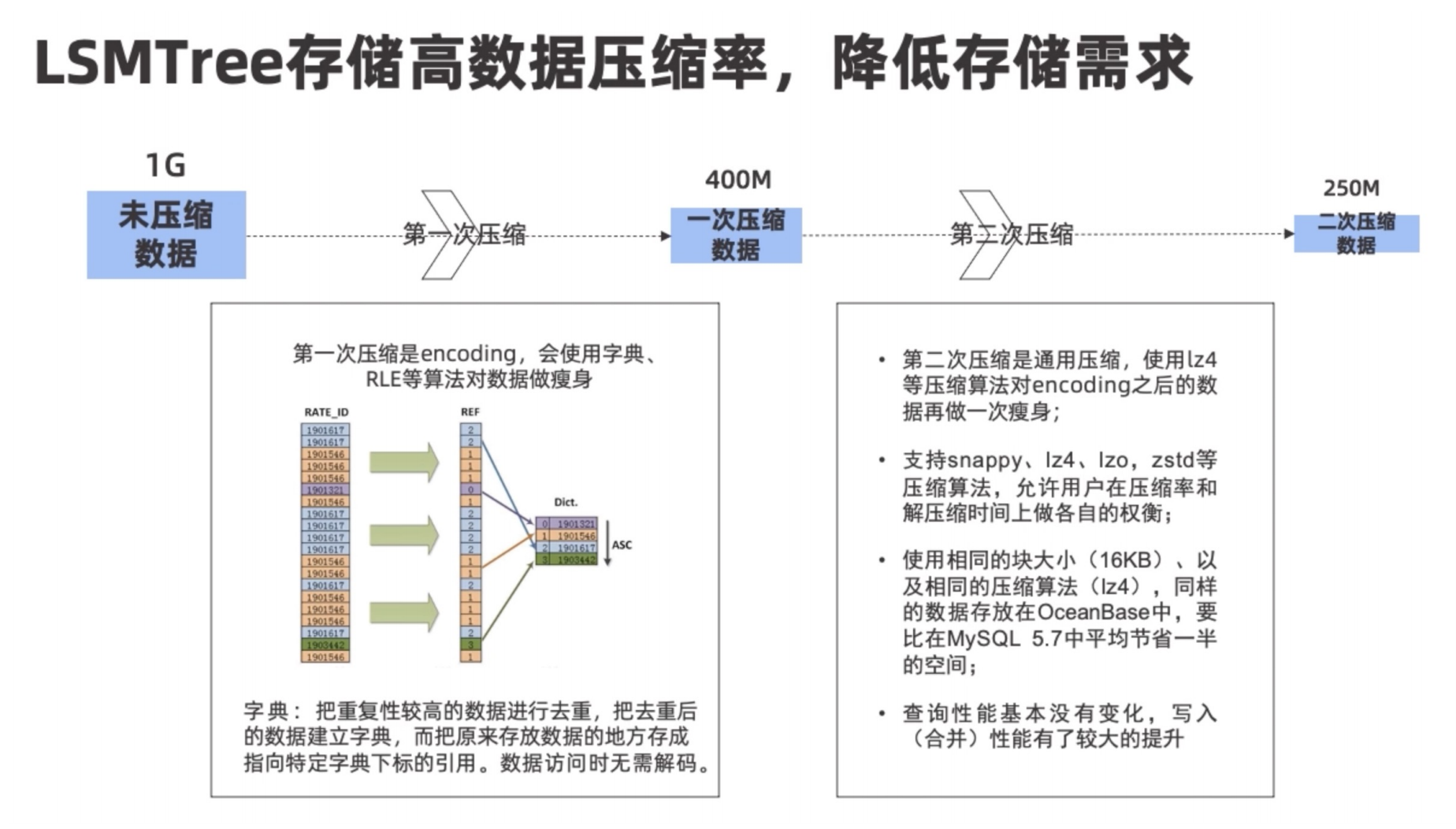
备份
OceanBase采用的是逻辑备份,需要有一个独立的备份组件,可以存储在NFS或阿里云OSS,备份支持基线数据+增量数据的形式,可以恢复任何操作,并且支持集群级别与租户级别的备份,增加了备份恢复的灵活性。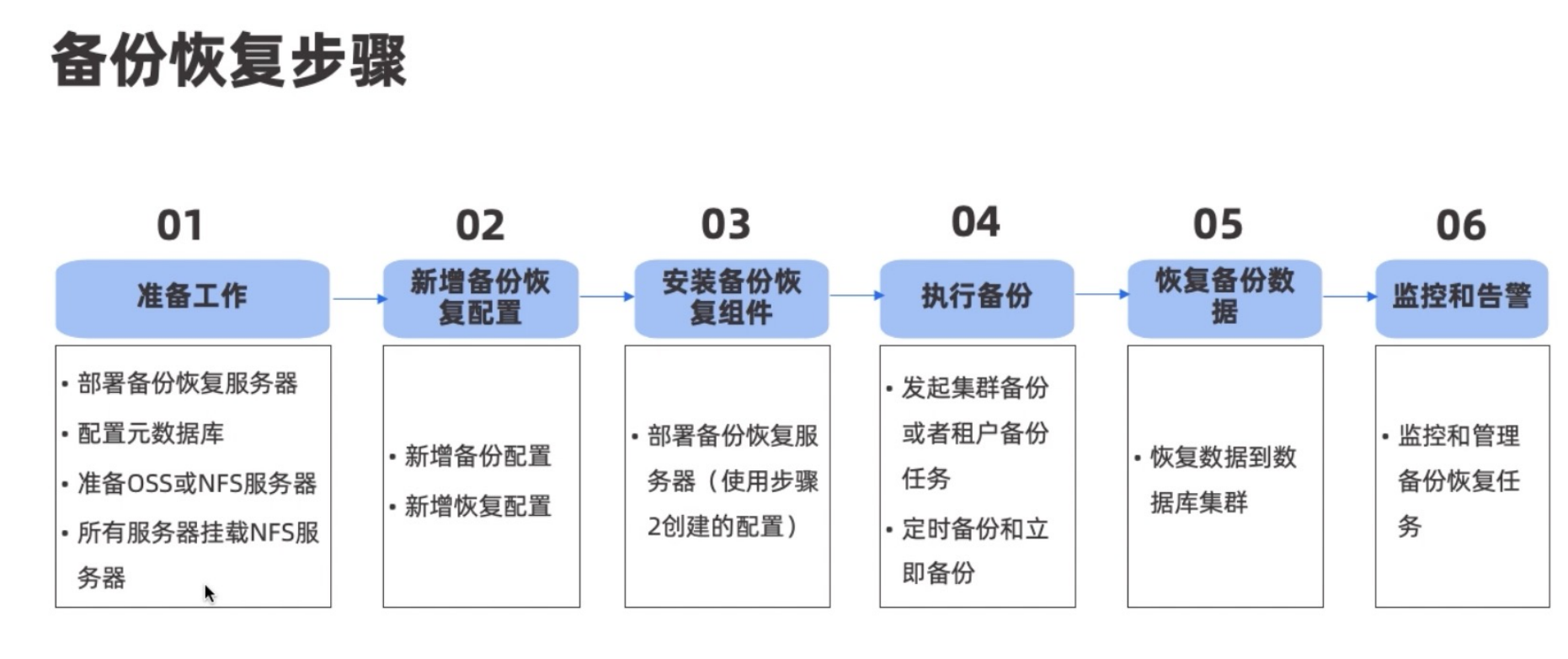

若有收获,就点个赞吧
0 人点赞
