采样率,每秒采样上万点
从一个音频文件中解析出 采样率 采样位移
付利叶就是拆波,拆为正弦函数,光滑
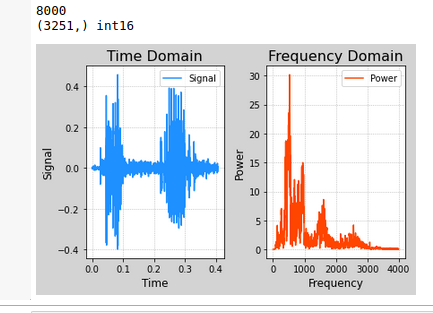
同一个单词,时域图的波形变化无常,难以对应关系
在频域中,描述频率和能量,能量分布和语音内容高度吻合
作为特征,交给svm,bayes 训练模型,建立起能量频率和已经学习的单词的对应
音频难以提取特征,有MFCC api,做分类业务

 构建样本输入输出,才能构建模型
构建样本输入输出,才能构建模型
 pyhton 的语音特征库
pyhton 的语音特征库
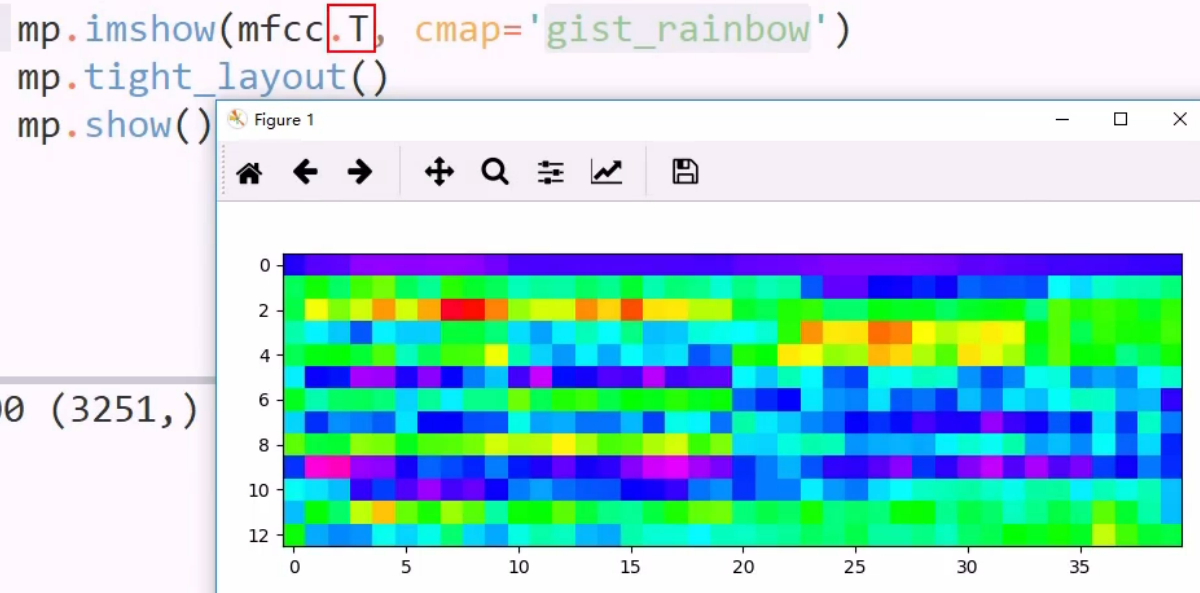
从音频文件中读取两个参数, 位移和采样率,给mfcc 从中提取特征,得到n行13 列矩阵
mfcc 只与字有关,与语调无关
 一秒采样8000个,只有最3251个
一秒采样8000个,只有最3251个
将mfcc 矩阵绘制
用skl 的分类器 设计分类业务
一个mfcc 作为一个样本,要变形
将mfcc 所有行求均值,作为一行
 共用7 × 14 个样本
共用7 × 14 个样本
svm 的linear poly 都可以,有置信概率可参考

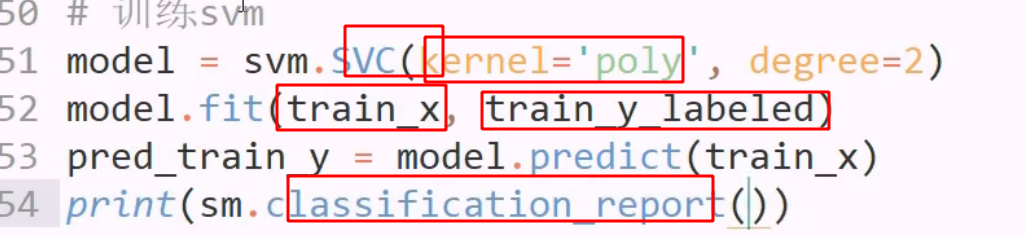

输出置信概率:

 七种样本,7×7 矩阵
七种样本,7×7 矩阵

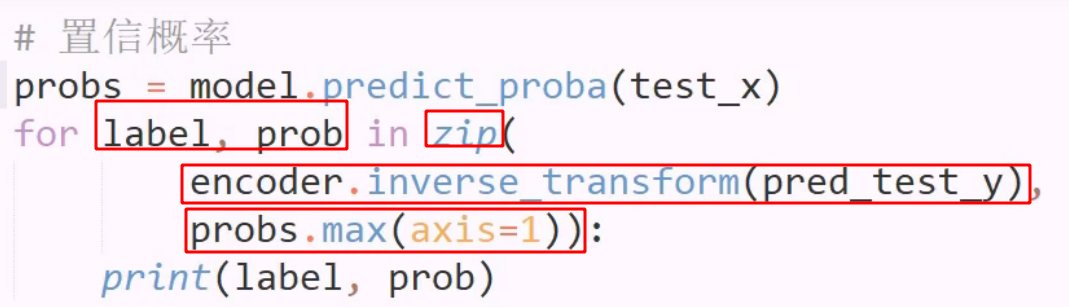

静默时长切割字,从而识别一句话
说话过于流畅,可能要两个字一起训练
语音的应用已经确定了,不需要做了
回顾 建模过程
fit 前,要做好一行一样本,一列一特征
不能抻平的,就要均化
隐马模型: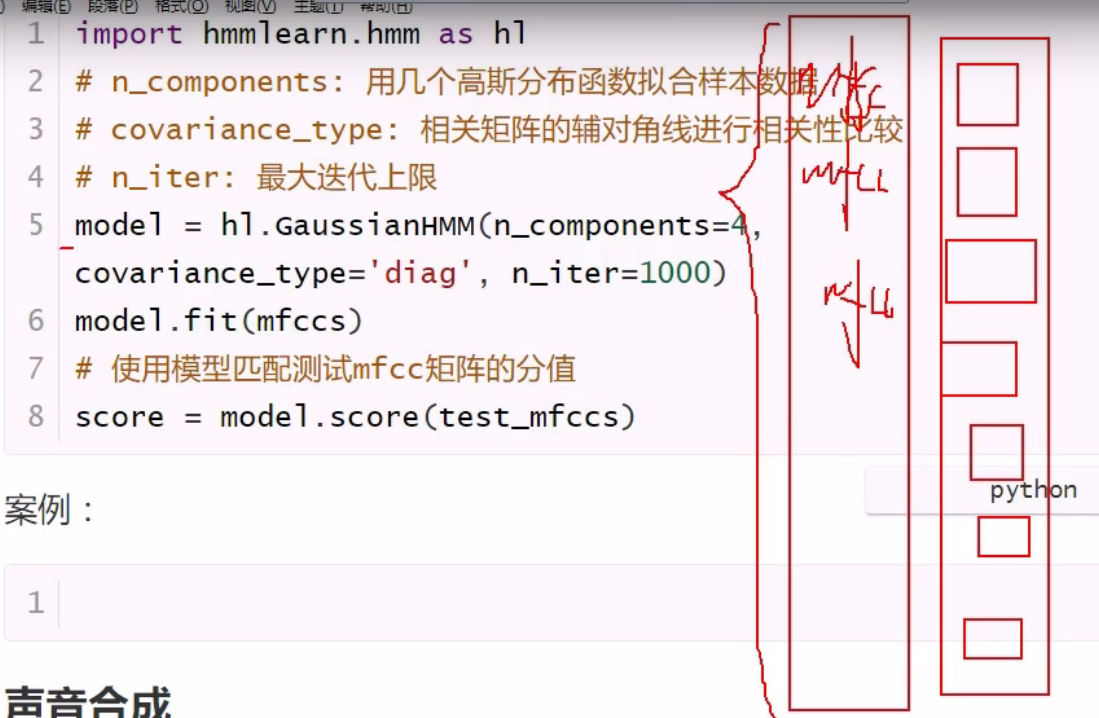
所有apple 的mfcc 落在一起,无论是mfcc 内部还是之间,都是服从apple 的能量分布的
可生成一个模型,专用于判断apple
每个类别都做一个隐码模型 用所有模型共同预测一个样本,得分大的为准,认为概率高
判别模型 是把所有类别训练成为一个模型 生成模型

若有收获,就点个赞吧
0 人点赞
