
核心业务: 先推荐什么,后推荐什么
两个步骤: 召回,排序
推荐引擎算法就是针对这两个步骤,是独立的,关注点不同的
推荐引擎和其他领域都有关
列个表,拿到需求,这就是召回
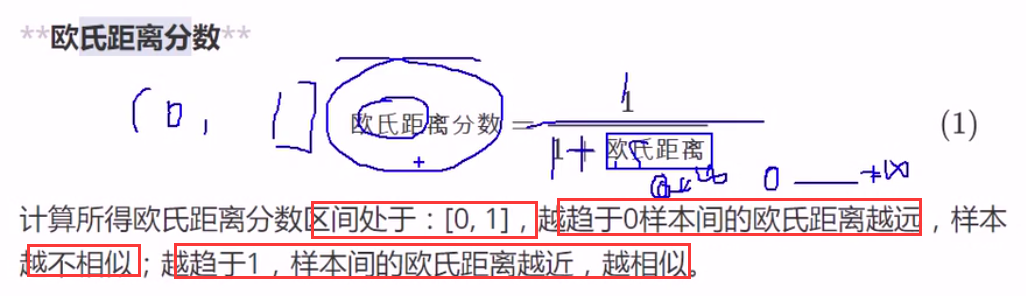
用距离 评判相似度 是计算相似度的算法
求谁的相似度:
基于用户的协同过滤(相似用户): 聚类 你是哪一类用户,召回
基于内容的协同过滤(相似商品):
训练得分矩阵,是最重要的,也是最麻烦的,考虑很多因素

四个人之间的相似度 是对称的
四部电影之间的相似度
现在我们的模型就是矩阵,所有训练结果数据都在其中
案例: json 电影用户的相似度
根据用户之间对电影的评分,计算相似度
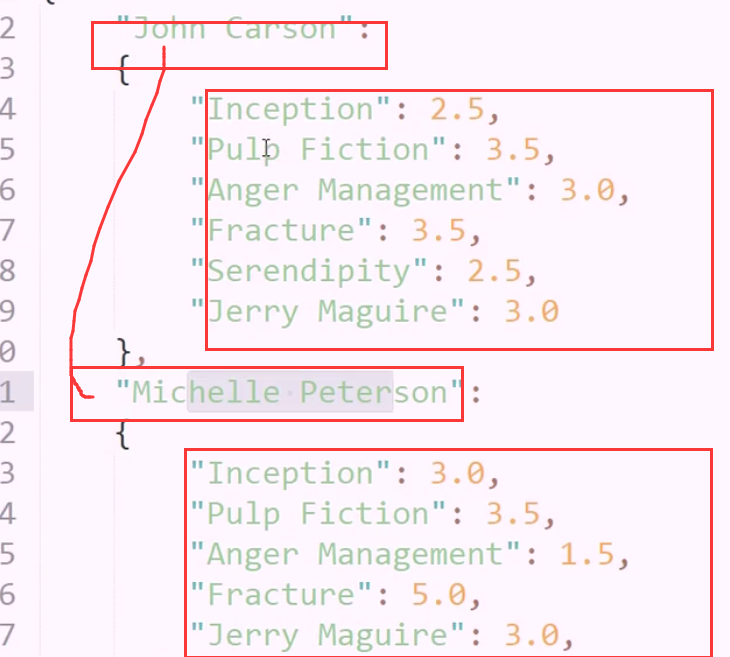
看的电影不同,打的分不同

若有收获,就点个赞吧
0 人点赞
