 只有一个样本,则不予划分,在上一层结束划分(即上层叶子表有混杂) 青年女博士
只有一个样本,则不予划分,在上一层结束划分(即上层叶子表有混杂) 青年女博士
先按哪个字段划分 信息熵
决策树,以及很多算法都内置了优化
集合算法思想
 模型不好时使用的办法
模型不好时使用的办法
正向激励 带有权重的决策树 为样本随机分配初始权重
找到符合条件的预测样本时这,平均时 考虑权重
那一侧不准,就把他的权重放大 那就得到了第二棵决策树
这就是正向激励,宁可将已经很准的调整不准,也要把不准的做准
模型都是成熟的,调不好很可能是样本自身的问题,让人工试试
将预测错的单独都拿出来,人工看看是不是好预测
就是青年女博士,工资差很多,实时如此,确实无法预测准,虽然特征完全一样
考虑是否有其他特征没有预测到
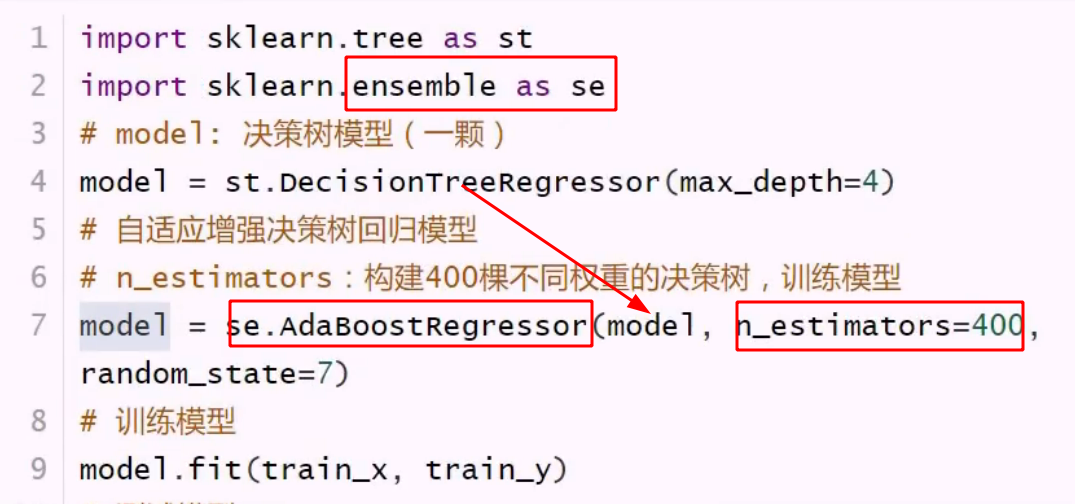 搞400棵树
搞400棵树
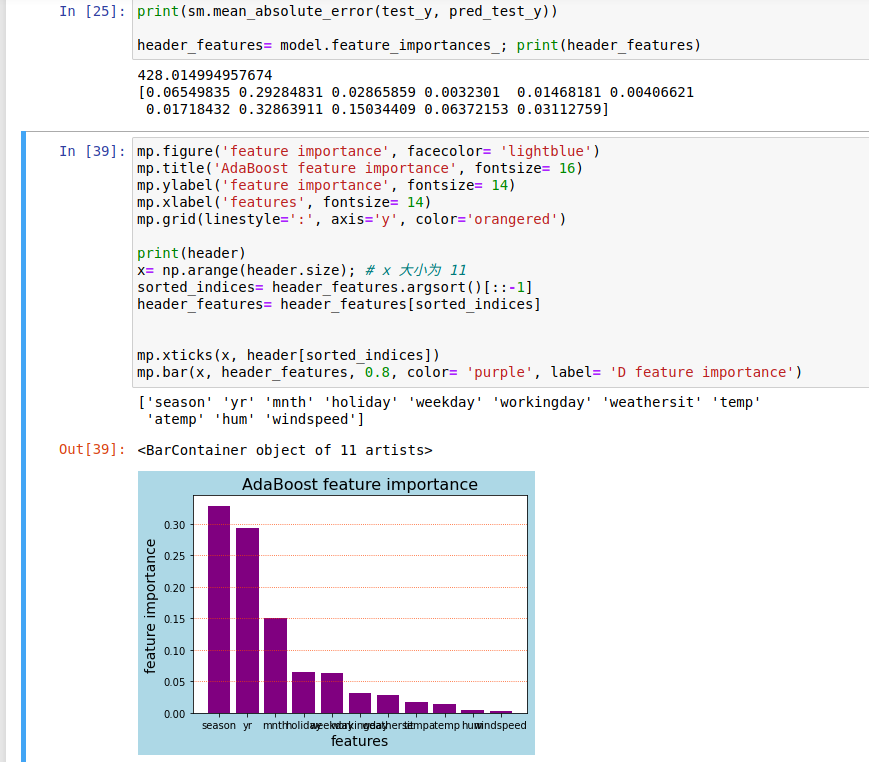
特征重要性和

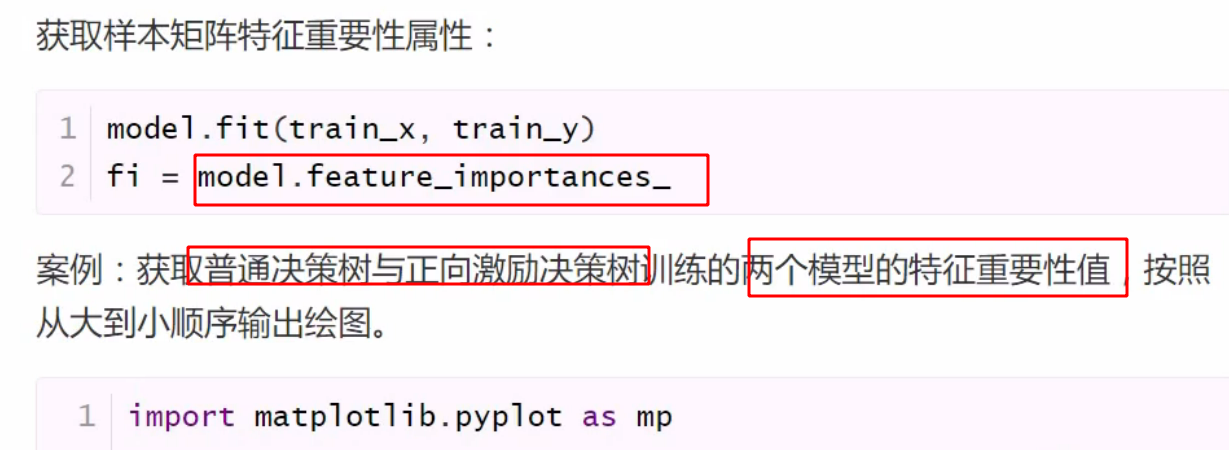
但凡是 _ 结尾的属性,都是训练得到的副产品
有重要性为0 的
正向激励兼顾了所有特征
用柱状图表示重要性

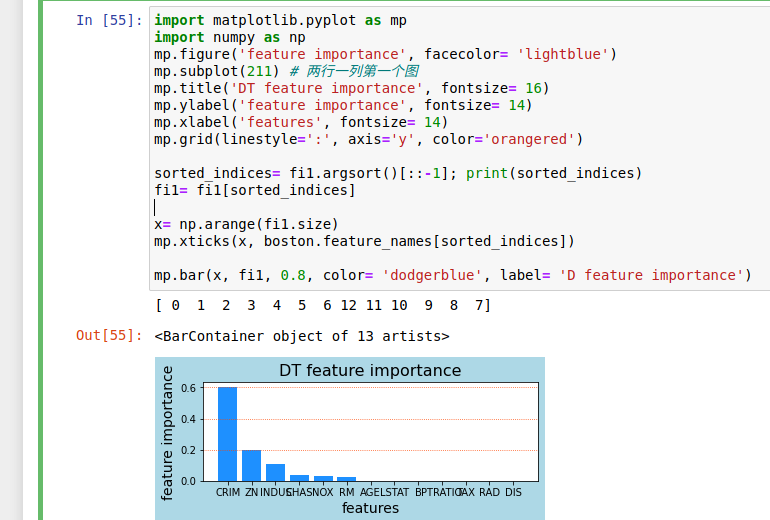
arg 开头的函数,返回值都是索引
用新的索引作为掩码,与其他数组运算
 使得原本数组元素从大到小排列的索引顺序 构成的数组
使得原本数组元素从大到小排列的索引顺序 构成的数组
 用掩码对原有数组 排序
用掩码对原有数组 排序
 同样对名称数组排序
同样对名称数组排序
x 已经排过,因此x位置上的name 字符也要排 这里纯粹为了显示方便

自主聚合 另一种集合算法

个别的强势样本 不一定是错误样本,不一定删除
有些精度,即使删掉,也提不上去 精度提不上去就罢了
没有长api 可用,自己循环抽取 建模,但随机森林可以完全替代之

列数和行数都被随机了,因此所有的树之间形体差异很大

如果只有两个元素,则不予以拆分 
怎么随机的,我们不关心
案例: 共享单车需求和投放
特征工程: 我们要在这里整理样本
已经做好了均值移除,范围缩放
日期不要,对预测无帮助,只有人口之类算累计量才会用到年份等
整理 x y
pandas readcdv 或者只with open 读进来拆行
 每行字符串结尾的换行去掉, 并转为列表中 最后得到二维列表
每行字符串结尾的换行去掉, 并转为列表中 最后得到二维列表
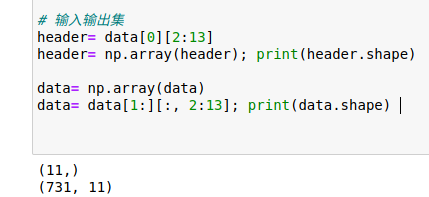
列表的切割比数组限制大,可以先找转为数组 (最好先切)
切割数据时,期望得到数据部分的2/13 列
 这样更好
这样更好
切了也是字符串,转为 float

迁移学习: 别人训练好了 我拿来用
那么多特征,又是离散又是连续

有无数学公式让他们建立联系? 多数离散,就选决策树等基于概率的模型
只是做区分的特征(离散),不应该让他们带入函数中
用公式就很别扭,有一个最初的模型选择的思路
对算法很了解,也选不对,因为样本的认知更加重要
我们这里的岭回归,是基于多个特征,
多项式回归只是一元的 ,是在整体某个特征不符合线性时,对其扩展的


若有收获,就点个赞吧
0 人点赞
