比numpy api 更多 用到什么学什么
 大型结构化数据集: 就是操作表 不能操作图片/音频
大型结构化数据集: 就是操作表 不能操作图片/音频
可以修改index
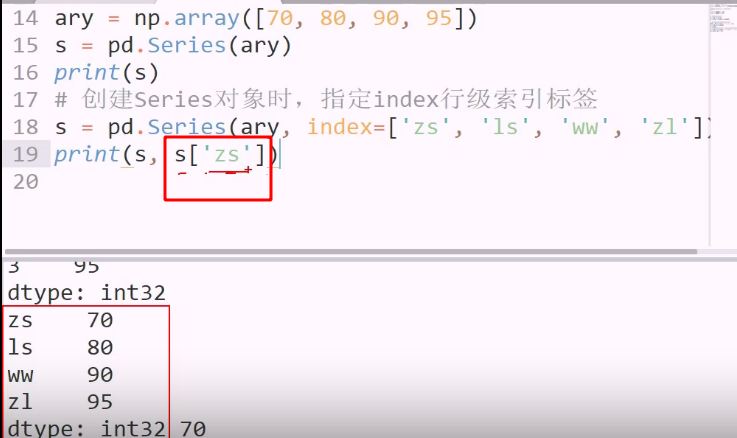 索引看作键,访问如同字典
索引看作键,访问如同字典
因此,可以用字典创建 serires
可以直接拿到数组: 。value 属性
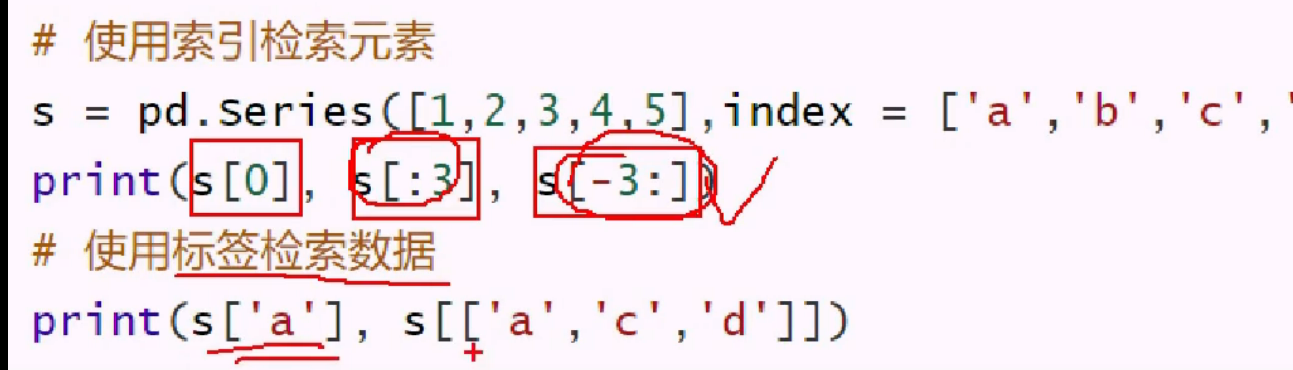 可以切片,可以指定key 切出来还是 series 指定key 也拿到 series
可以切片,可以指定key 切出来还是 series 指定key 也拿到 series
pandas 中,所用标签,少用索引
pandas 日期处理
numpy 只能识别一种日期:
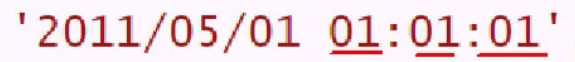
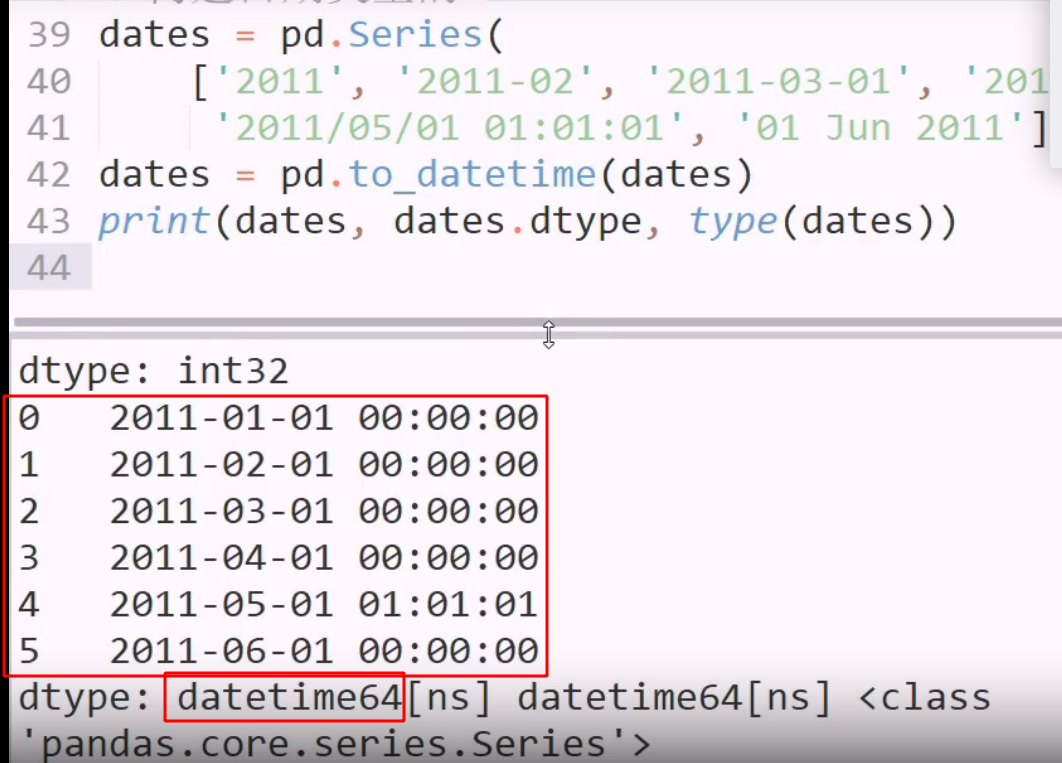
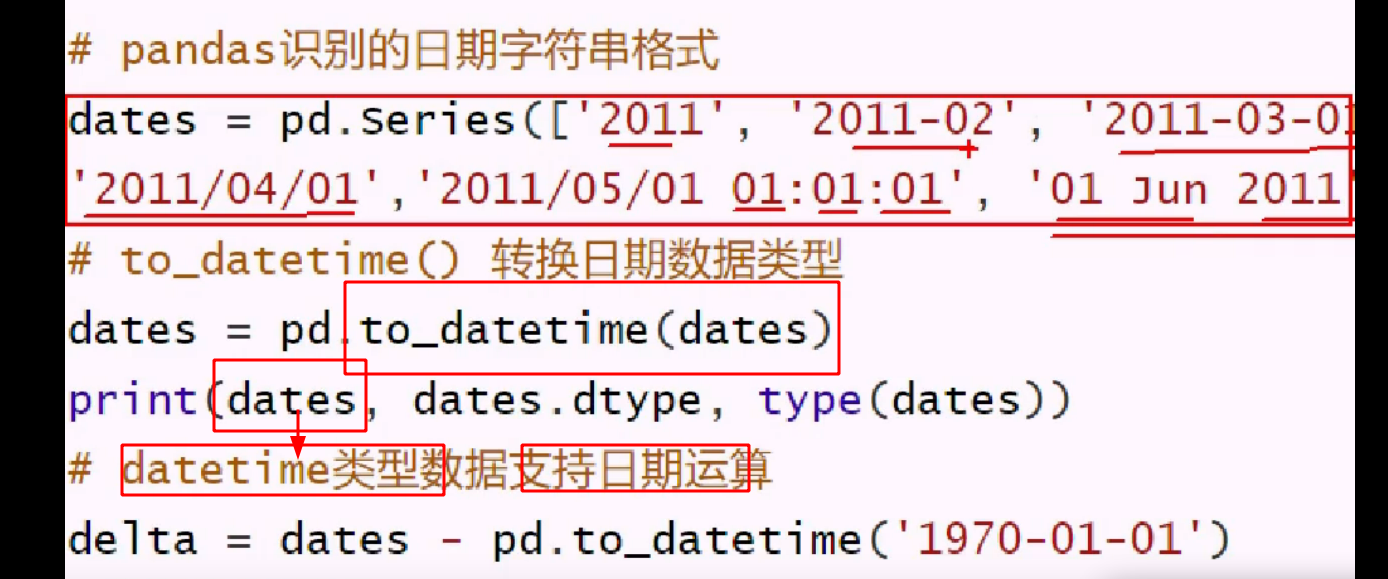 识别,并同一转为 datetime 类型
识别,并同一转为 datetime 类型

 用一个 series 减去一个值,则广播
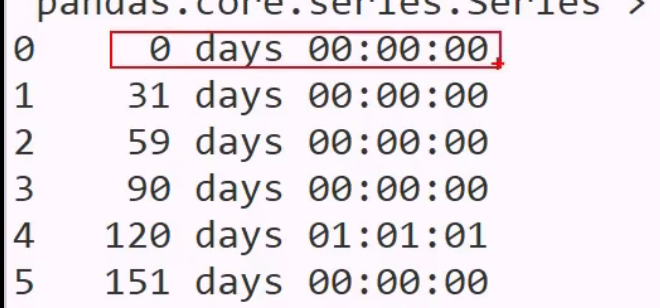
用一个 series 减去一个值,则广播
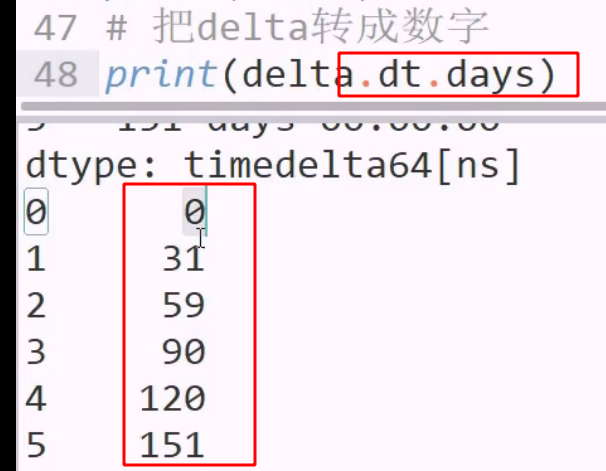
时间转数值:
将日期作为行级索引:date 做key, 交易量做 values
是datetimeindex 数组类型
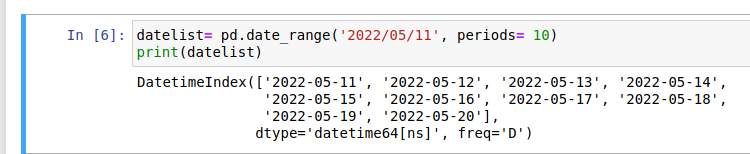 构建日期数组 也可以说是列表
构建日期数组 也可以说是列表
 按月生成
按月生成
生成时间序列 工作日序列 自动跳过周末
 也可以用 date range 来做,指定B即可
也可以用 date range 来做,指定B即可
dataframe
有行级索引和列级索引 的二维数组 但是大小可变 可追加行列
numpy 的切片过于费劲
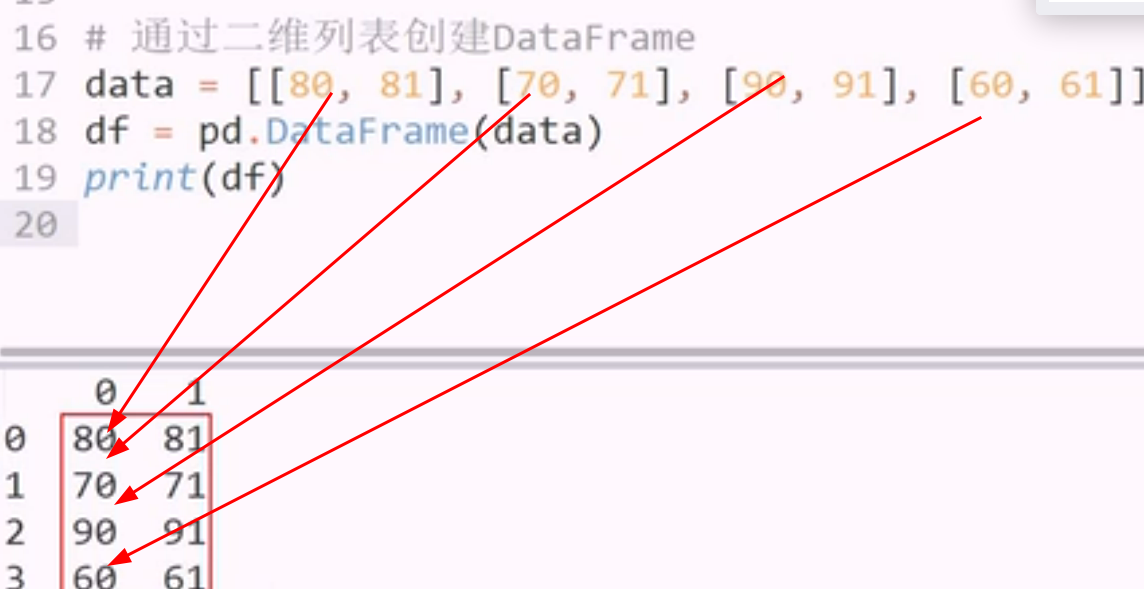
用列表创建 dataframe
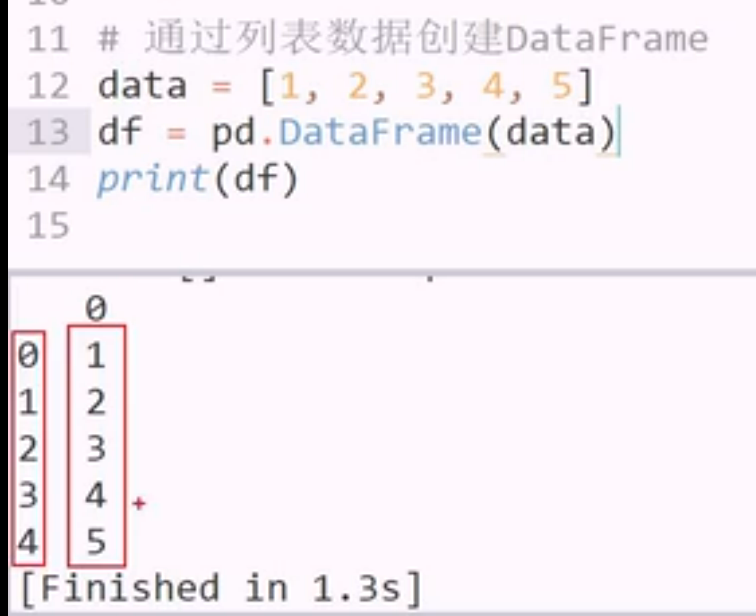 一维数组 作为一列
一维数组 作为一列
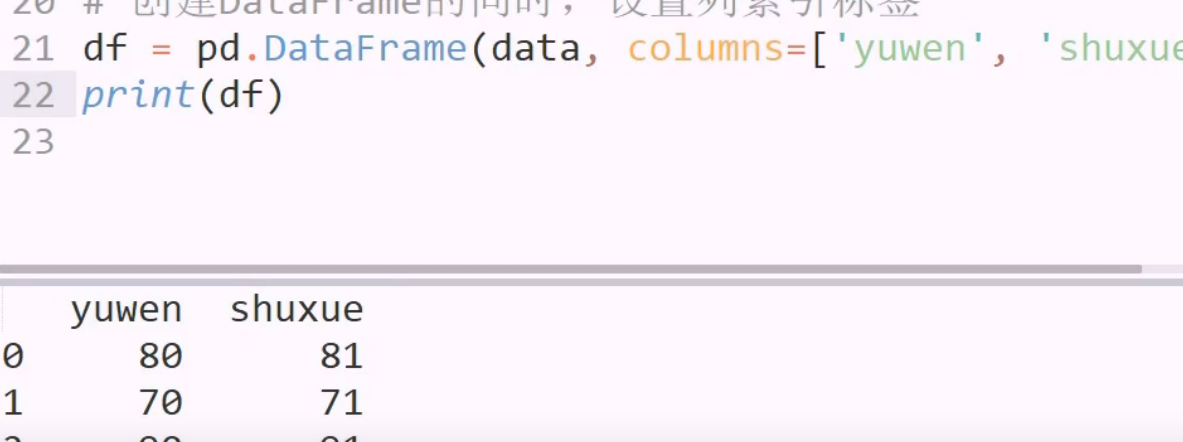 修改标签
修改标签
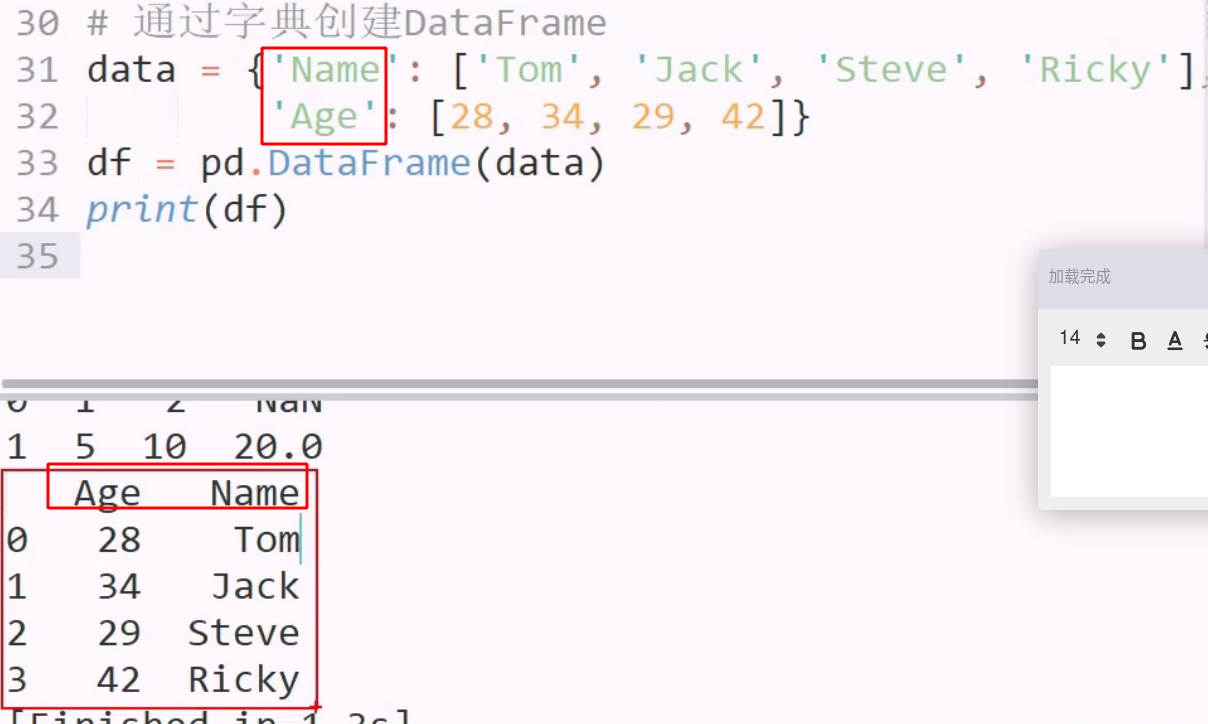
字典创建 dataframe,每个字典都是一个记录
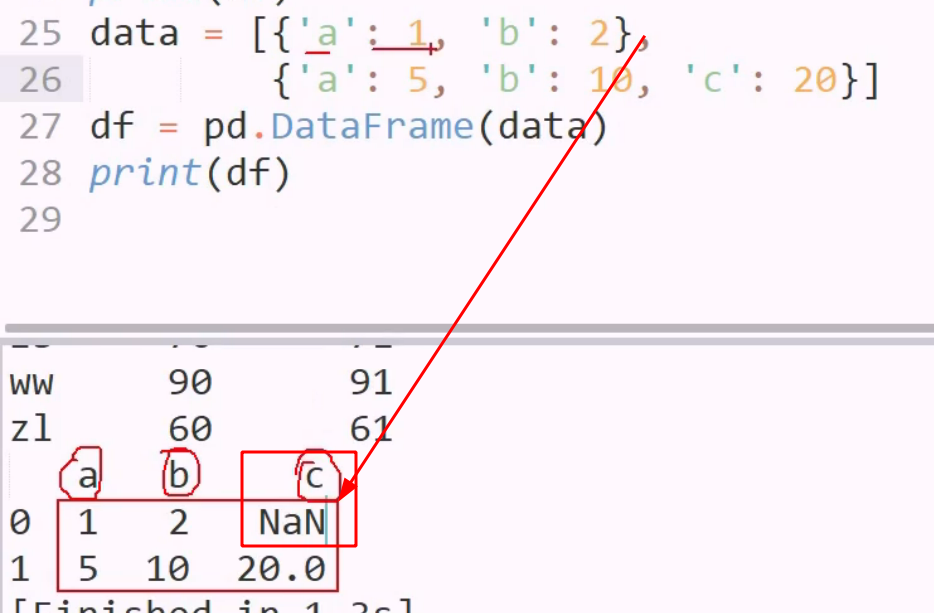
用字典构建时, key 做列名,列表仍然当一列数据
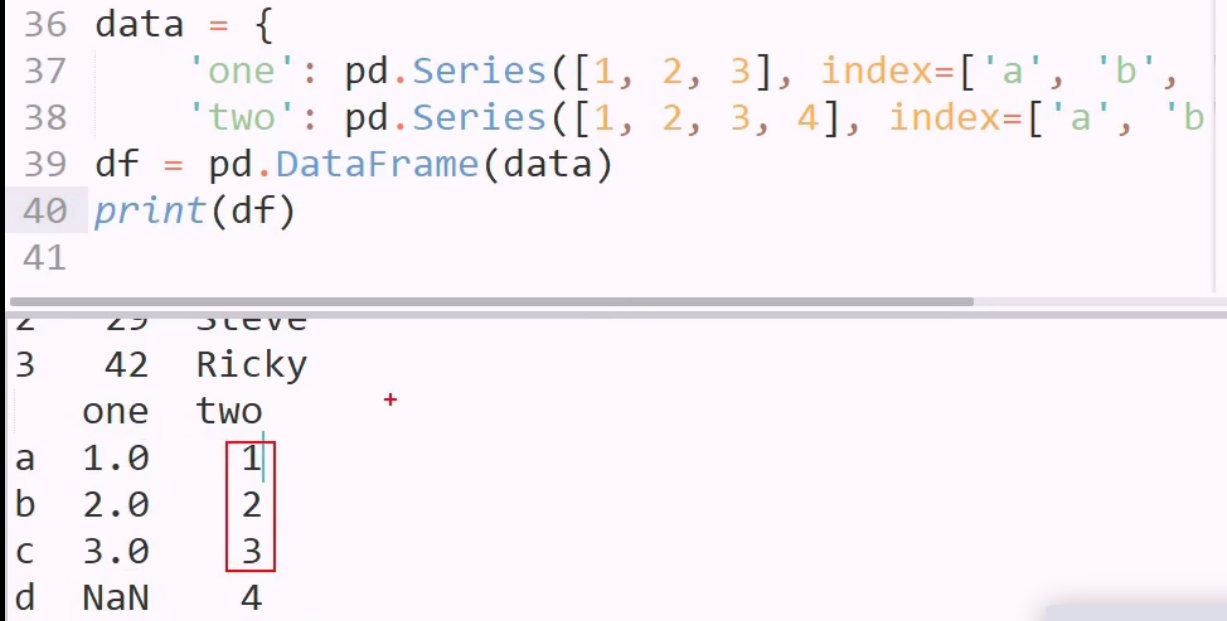 字典的value 不是列表,而是series 的情况 相当于为其又指定了行索引
字典的value 不是列表,而是series 的情况 相当于为其又指定了行索引
比二维数组细节麻烦多了
列访问 访问series
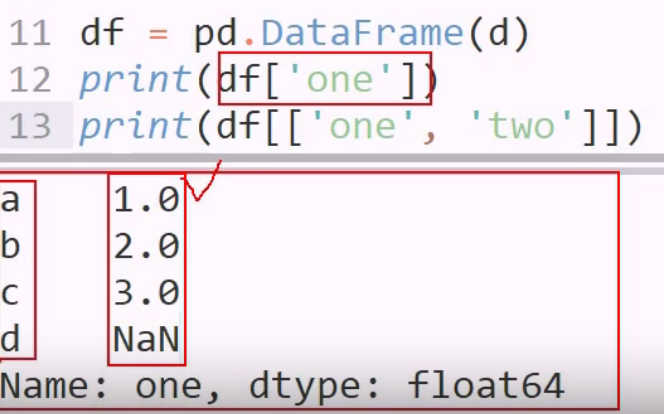 只访问一列,则按series 返回
只访问一列,则按series 返回
列添加 相当于给 字典加一个key
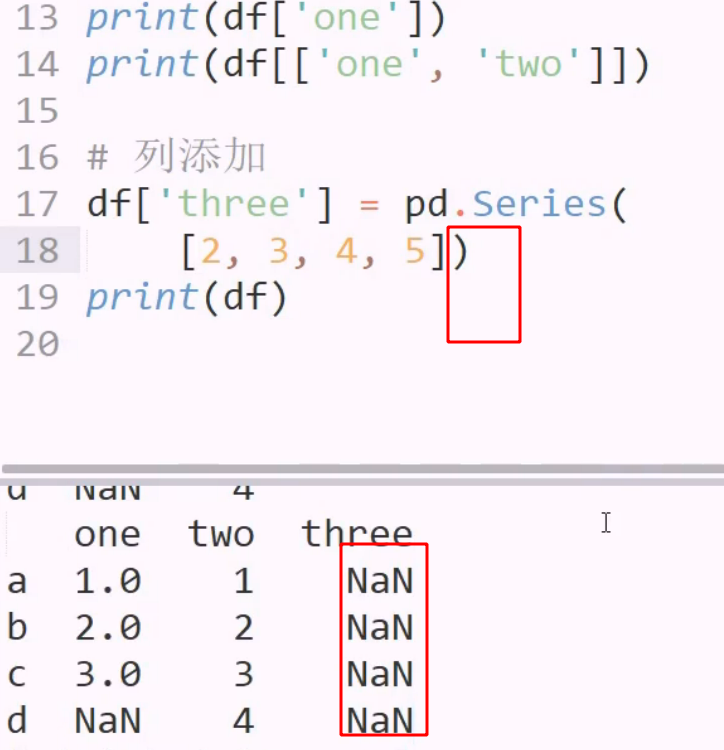 若创新新列时, 不指定index,则添加进去空,因为默认index 0123 与当前不匹配
若创新新列时, 不指定index,则添加进去空,因为默认index 0123 与当前不匹配

若有收获,就点个赞吧
0 人点赞
