核心思想: 相似的输入,必然有相似的输出
这种算法的实现: 查找数据库,找到所有相似的,做个平均
决策的问题: 没有某个特征的样本,丢掉特征,层层选取
可以回归,可以分类下 为连续数据设置阈值
几个特征拆几层
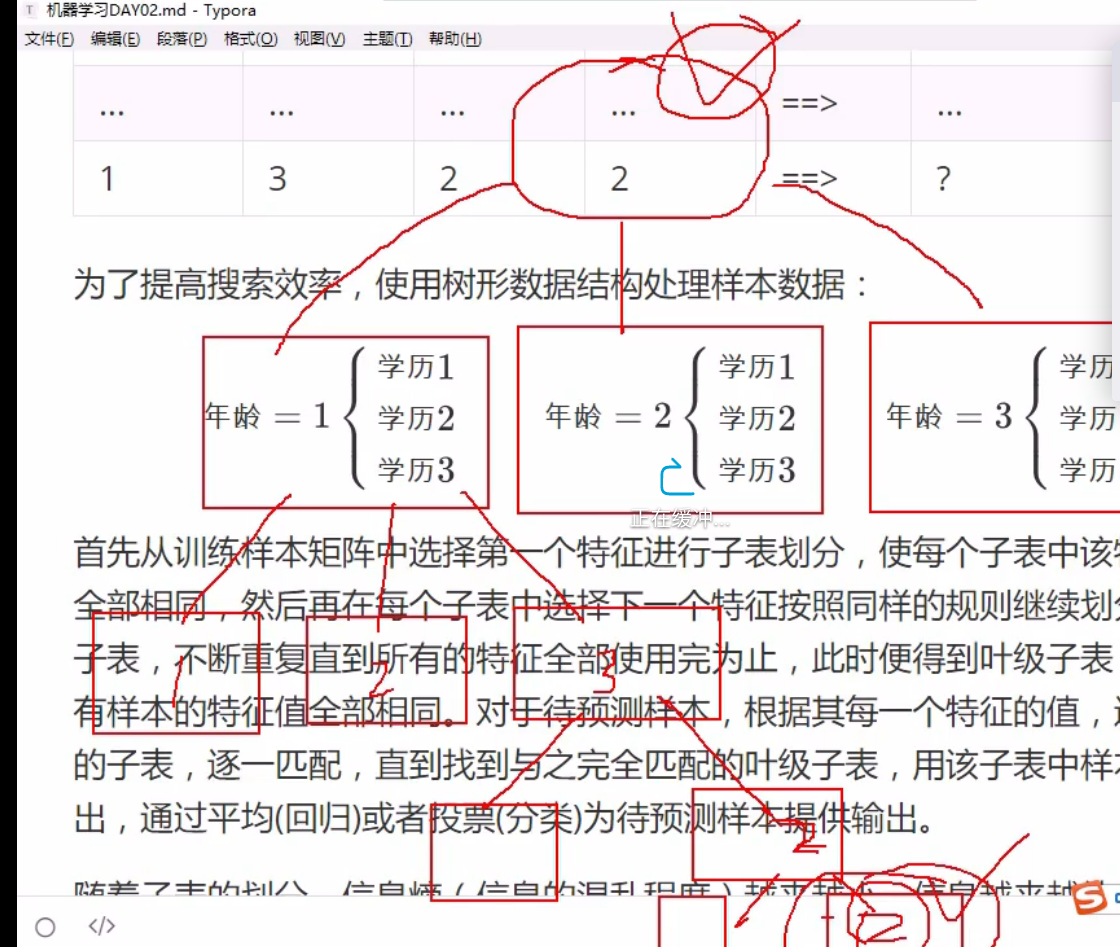
训练模型时,就要把树做好
没有微积分,纯粹概率的模型
调整层数: 设值最大深度

一眼看不出用任何公式的业务,使用树

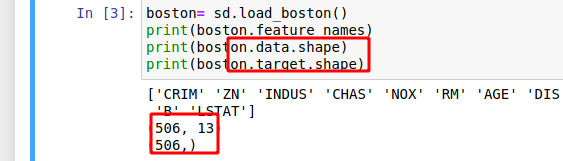 13 个展特征与506 个样本
13 个展特征与506 个样本
随机种子: 每次打乱都一样
 画图看不到: 图层覆盖问题,用zorder 设置大图层
画图看不到: 图层覆盖问题,用zorder 设置大图层
分类不能使用R2
用训练集和测试集的各自得分,判断过拟合
决策树分类器 决策树回归器: 是按预测结果分的,而不是特征
对于连续的年龄,决策树内部有自动的划分,26岁预测可能被划分到25-35 之间。不会对连续特征每个表现都产生一个分支
自己整理数据才最麻烦,可能你要公司就给你,也可能要自己查数据库,自己整理: 特征工程

若有收获,就点个赞吧
0 人点赞
