
超参数数量
 直接拿到模型,甚至都不知道模型是什么类型的
直接拿到模型,甚至都不知道模型是什么类型的
交叉验证也不用做了,模型传参也不做了,只指定一个空荡荡的medel 类型即可
 模型训练的副产品 属性
模型训练的副产品 属性
最优参数 最优得分 最优模型
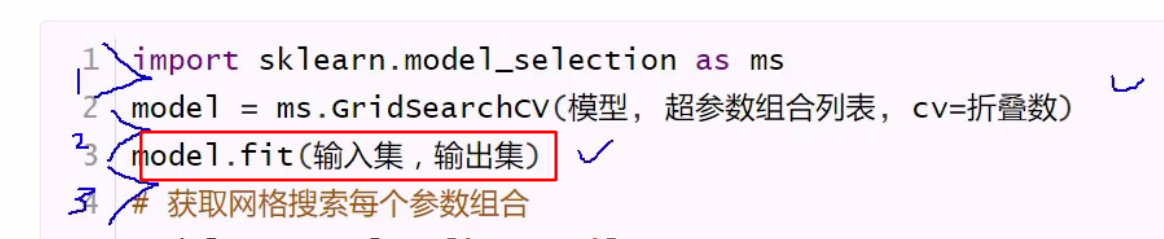 真正拿到模型还是在 fit 消耗时间最长 上面传参只是创建对象,等待对超参数列表进行筛选
真正拿到模型还是在 fit 消耗时间最长 上面传参只是创建对象,等待对超参数列表进行筛选
这里的fit 是多个任务一起完成了
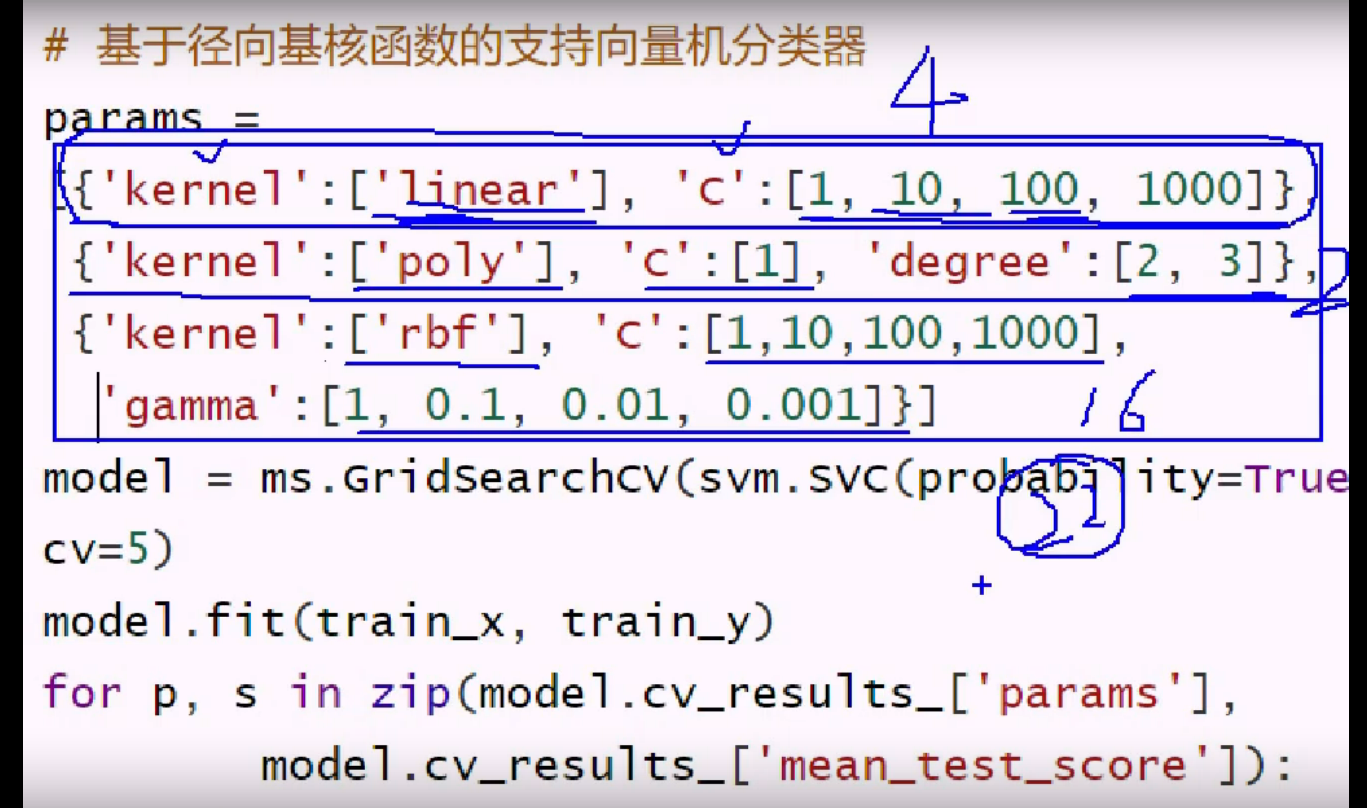
超参数列表的表达方式: 字典+列表 这样可以自由组合,而不是单纯排列组合
不同的组合,可能维度不同(特征个数),这就构成了每个字典
在字典内,特征的分布形成了列表


检查副产品:

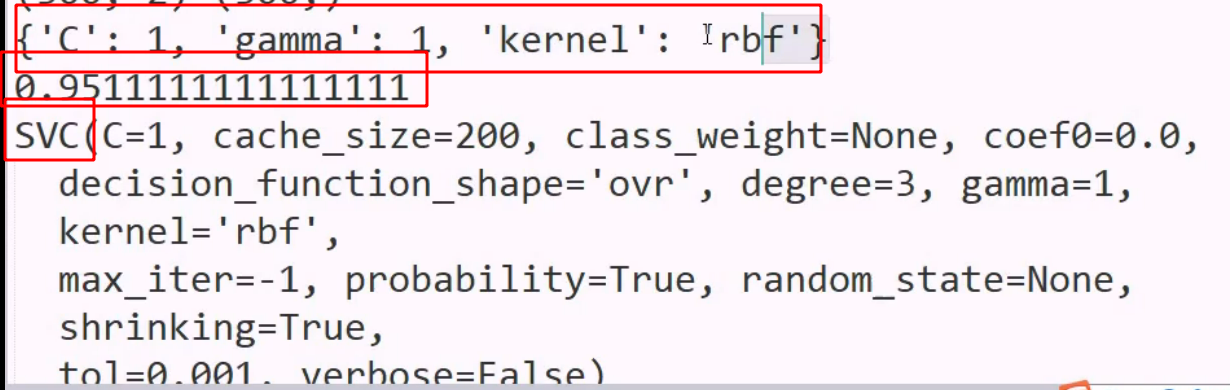
 使用zip 同时遍历两个列表
使用zip 同时遍历两个列表
超参数也有顺序,简单的超参数写在前面,使得优先选择简单模型
demo 事件预测
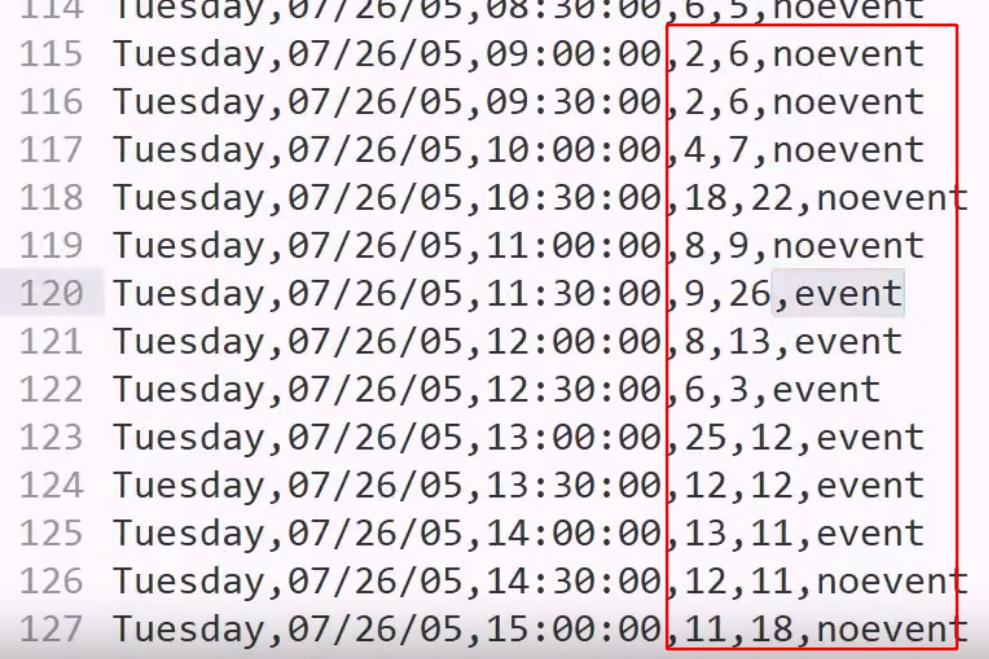 一组监控拍下的记录,预测是否有事件发生
一组监控拍下的记录,预测是否有事件发生
字符串要标签化
那些列不要: 星期几可以复现,要
但是日期月份不可复现,不要
时间段,进出门人数都要
时间段是在循环,看作离散的,要编码
进出门人数是连续数据
如果y是离散的,决定这是个分类问题: 森林/beiyesi
编码的工作量还是很大的,该删的,该编码的

自己做 label encoder 有时用得到,设计码表,不同字符串赋予有意义的编码
而默认的encoder 只是做了映射

样本均化 特征类别的均衡化

为了弥补带有某特征的样本 数量过低,提高这些样本的权重
典型的例子就是癌症筛查
但数据量小是最大的缺陷,均衡化只能提高一点贡献
实际上我们做的是对y 标签更改权重

 无法区分边界
无法区分边界
这就是线性不可分,要第三个特征升维
背景只有一个颜色,也就是说,当前所有样本都被分成了一个类别
绿色样本过多,所以全部预测为绿色,准确率很高

1:5 的样本比例已经效果很差了

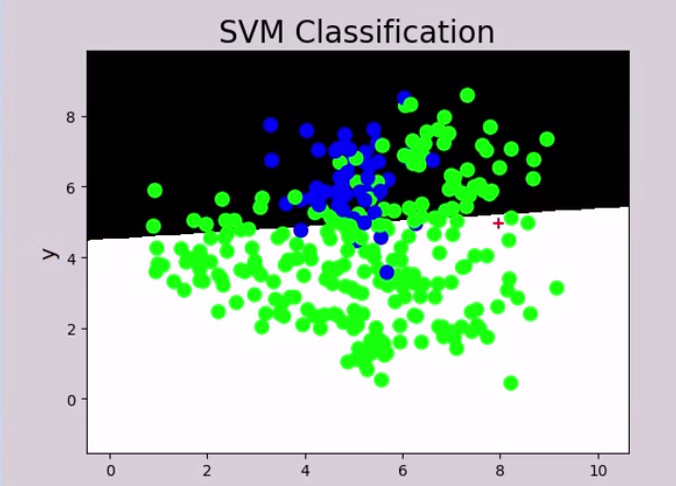

召回率: 黑色域那边的绿色使得召回率下降

高斯分布 + 均衡化
只有svm 这一个分类器有均衡化
对应其他模型,不均衡问题解决方案

下采样: 将多的截断成少的,直接干掉样本
上采样: 将少的扩充为多的,图像常用 要更多的图片,就模糊处理,亮度调整,旋转图片等
也叫图像增强
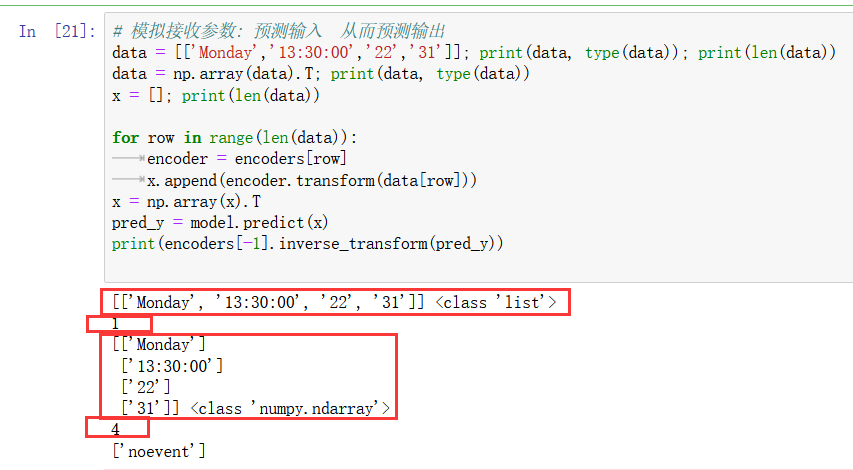


假装重写: digit encoder 也写了 和 label encoder 一样的 transform 名称,实现了伪装多态
rbf 和 poly 用哪个? 哪个效果好,用哪个
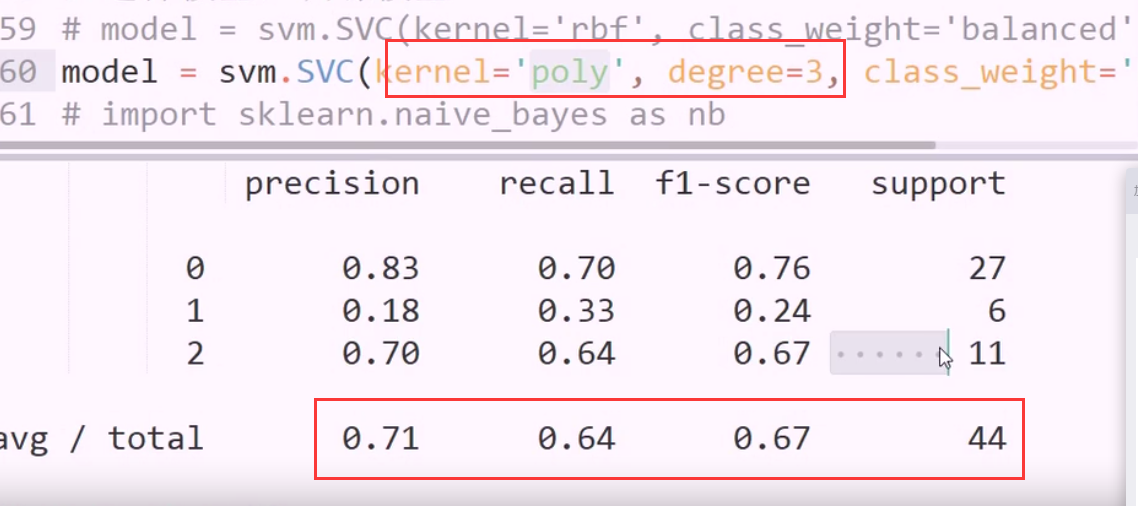
这个是三个y类别的分类
多元分类也可以用 svm做 也是用多个二元分类器去做的
传进去的样本集有多个y,则自动为你创建多元分类器

若有收获,就点个赞吧
0 人点赞
