简单的句子分类
之前的代码随便改一下就行
本次亮点有
- 正负情感评论,分别读取后Random处理是本次的亮点
- 使用了下载后的数据集,之前都是默认位置(服务器网速太慢)https://zhuanlan.zhihu.com/p/147144376
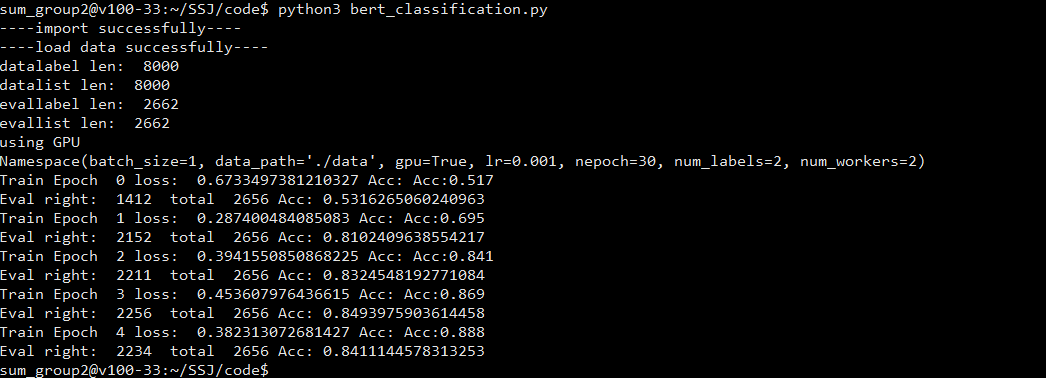
对于数据处理的还是有点随便,可能影响了最后的最优解
最后正确率85%左右
import numpy as npimport timeimport copyimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torch.autograd as autogradimport torch.nn.functionalfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsimport warningsimport torchimport timeimport argparseimport osfrom transformers import BertTokenizerfrom transformers import BertForSequenceClassificationfrom transformers import BertConfig#from transformers import BertPreTrainedModelfrom transformers import BertModelprint("----import successfully----")USE_CUDA = torch.cuda.is_available()#USE_CUDA=Falsetokenizer = BertTokenizer.from_pretrained("../../pretrain_model")pos_lines = open('../../data/classification/rt-polarity.pos', encoding='gb18030', errors='ignore').read().strip().split('\n')neg_lines = open('../../data/classification/rt-polarity.neg', encoding='gb18030', errors='ignore').read().strip().split('\n')print("----load data successfully----")train_data={}train_data['label']=[]train_data['text'] =[]class mydata:def __init__(self,data,label):self.data=dataself.label=labeldata=[]for i in pos_lines:data.append(mydata(i,1))for i in neg_lines:data.append(mydata(i,0))#input_ids = torch.tensor(tokenizer.encode("美国", add_special_tokens=True)).unsqueeze(0) # Batch size 1import randomrandom.shuffle(data)for i in data:train_data['text'].append(tokenizer.encode(i.data, add_special_tokens=False))train_data['label'].append(i.label)data_list=[]max_len=40for x in train_data['text']:if len(x)>=max_len:x=x[0:39]while len(x)<max_len:x.append(0)x.append(102)l = xx = [101]x.extend(l)#x=torch.tensor(x)data_list.append(x)eval_list=data_list[8000:]eval_label=train_data['label'][8000:]data_list=data_list[0:8000]train_label=train_data['label'][0:8000]print("datalabel len: ",len(data_list))print("datalist len: ",len(train_label))print("evallabel len: ",len(eval_label))print("evallist len: ",len(eval_list))train_label=torch.tensor(train_label)traindata_tensor = torch.Tensor(data_list)eval_label=torch.tensor(eval_label)eval_tensor = torch.Tensor(eval_list)#USE_CUDA=Falseif USE_CUDA:print("using GPU")traindata_tensor =traindata_tensor.cuda()train_label = train_label.cuda()eval_tensor=eval_tensor.cuda()eval_label = eval_label.cuda()def get_train_args():parser=argparse.ArgumentParser()parser.add_argument('--batch_size',type=int,default=1,help = '每批数据的数量')parser.add_argument('--nepoch',type=int,default=30,help = '训练的轮次')parser.add_argument('--lr',type=float,default=0.001,help = '学习率')parser.add_argument('--gpu',type=bool,default=True,help = '是否使用gpu')parser.add_argument('--num_workers',type=int,default=2,help='dataloader使用的线程数量')parser.add_argument('--num_labels',type=int,default=2,help='分类类数')parser.add_argument('--data_path',type=str,default='./data',help='数据路径')opt=parser.parse_args()print(opt)return optdef get_model(opt):model = BertForSequenceClassification.from_pretrained("../../pretrain_model",num_labels=opt.num_labels)#model = bert_.BertForSequenceClassification.from_pretrained('bert-base-cased', num_labels=opt.num_labels)#model = bert_LSTM.Net()return modeldef out_put(net,batchsize):test_list = []test_data['text'] = [(tokenizer.encode(x, add_special_tokens=False)) for x in test_data.text]max_len = 40i=0for x in test_data.text:i+=1if len(x) >= max_len:x = x[0:39]while len(x) < max_len:x.append(0)x.append(102)l = xx = [101]x.extend(l)# x=torch.tensor(x)test_list.append(x)print(i)test_data_tensor = torch.Tensor(test_list)if USE_CUDA:print("using GPU to out")test_data_tensor = test_data_tensor.cuda()result=[]with torch.no_grad():result_dataset = torch.utils.data.TensorDataset(test_data_tensor)result_dataloader = torch.utils.data.DataLoader(result_dataset, batch_size=batchsize, shuffle=False)index=0for X in result_dataloader:X=X[0]#print(type(X))#print(X.shape)if X.shape[0]!=batchsize:breakX = X.long()outputs = net(X)logits = outputs[:2]_, predicted = torch.max(logits[0].data, 1)#print("predicttype",type(predicted))#print(predicted)for i in range(len(predicted)):result.append(i)print(len(result))while len(result)<3263:result.append(0)df_output = pd.DataFrame()aux = pd.read_csv(base_path + 'test.csv')df_output['id'] = aux['id']df_output['target'] = resultdf_output[['id', 'target']].to_csv(base_path + 's1mple.csv', index=False)print("reset the result csv")def eval(net,eval_data, eval_label,batch_size,pre):net.eval()#print("enter",net.state_dict()["classifier.bias"])dataset = torch.utils.data.TensorDataset(eval_data, eval_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=False)total=0correct=0with torch.no_grad():index = 0for X, y in train_iter:X = X.long()if X.size(0)!= batch_size:breakoutputs= net(X, labels=y)#print("enter2", net.state_dict()["classifier.bias"])loss, logits = outputs[:2]_, predicted = torch.max(logits.data, 1)total += X.size(0)correct += predicted.data.eq(y.data).cpu().sum()s = (((1.0*correct.numpy())/total))print("Eval right: ",correct.item()," total ",total,"Acc:",s)return sdef train(net, train_data, train_label,eval_tensor,eval_label,num_epochs, learning_rate, batch_size):net.train()optimizer = optim.SGD(net.parameters(), lr=learning_rate,weight_decay=0)dataset = torch.utils.data.TensorDataset(train_data, train_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)pre=0for epoch in range(num_epochs):correct = 0total=0iter = 0for X, y in train_iter:iter += 1X = X.long()if X.size(0)!= batch_size:breakoptimizer.zero_grad()#print(type(y))#print(y)outputs= net(X, labels=y)#print(y)loss, logits = outputs[0],outputs[1]_, predicted = torch.max(logits.data, 1)#print("predicted",predicted)#print("answer", y)loss.backward()optimizer.step()#print(outputs[1].shape)#print(output)#print(outputs[1])total += X.size(0)correct += predicted.data.eq(y.data).cpu().sum()s = ("Acc:%.3f" %((1.0*correct.numpy())/total))print("Train Epoch ", str(epoch),"loss: ", loss.mean().item(),"Acc:", s)torch.save(net.state_dict(), 'model.pth')pre=eval(net,eval_tensor, eval_label,batch_size,pre)returnopt = get_train_args()model=get_model(opt)#print(model)if USE_CUDA:model=model.cuda()#model.load_state_dict(torch.load('model.pkl'))train(model,traindata_tensor,train_label,eval_tensor,eval_label,5,0.0008,16)#model = torch.load('model.pkl')

若有收获,就点个赞吧
0 人点赞
