大致的看了一下,这一篇论文是在讲推出一个新的评测模型
之所以看这篇论文是因为
- 评测主要的模型,某种意义上是一种综述
- 另一个方面是可以看看在他的评测指标,反过来其实就是提高的突破口(能够提高的方面)
概述
抽取式摘要生成
之前都是分类任务,20年开始有人从摘要级别来考虑了(说的就是MatchSum)
生成式摘要
BERT,seq2seq模型大胜利,以及提到了一些很成功的技术
- AMR parsing
- copy
- coverage
- smoothing
- pre-training
近些年开始有人质疑ROUGE的评测到底能不能和人工评测的结果一致
以及现有的人工评测都是在几个方面(流畅性,事实)展开评测
作者用了8个error metrics
评测对象
Extractive
- Lead-3
- TextRank 2004
- SummaRuNNer 2017
-
Abstractive
Seq2Seq with Attention 2015
- Pointer-Generator 2017 (能够解决信息提取不准确,同时从原文和encoder结果生成)
- Pointer-Generator-with-Coverage 2017 使用一个额外的覆盖向量作为额外的输入
- Bottom-Up 2018 先抽取候选词,然后用生成式,被认为是两种的结合
- BertSumExtAbs 2019
- BART 2019 这个模型倒是没有遇到过,不过似乎也SOTA,融合了pretrain和自回归的decoder(原来的只会pretrain encoder)
作者提出了评测模型
PolyTope is an error-oriented fine-grained human evaluation method based on Multidimensional Quality Metric (MQM)
准确指标要求
- Addition,摘要了无关和不相关信息
- Omission 丢失关键信息
- Inaccuracy instrinsic 错误表达原文
- Inaccuracy Extrinsic 原文没说的,摘要里却说了
- Positive-Negative Aspect 摘要的倾向主题完全相反
流畅指标要求
- Duplication,不必要的重复了词语
- Word Form
- Word Order
结果评估
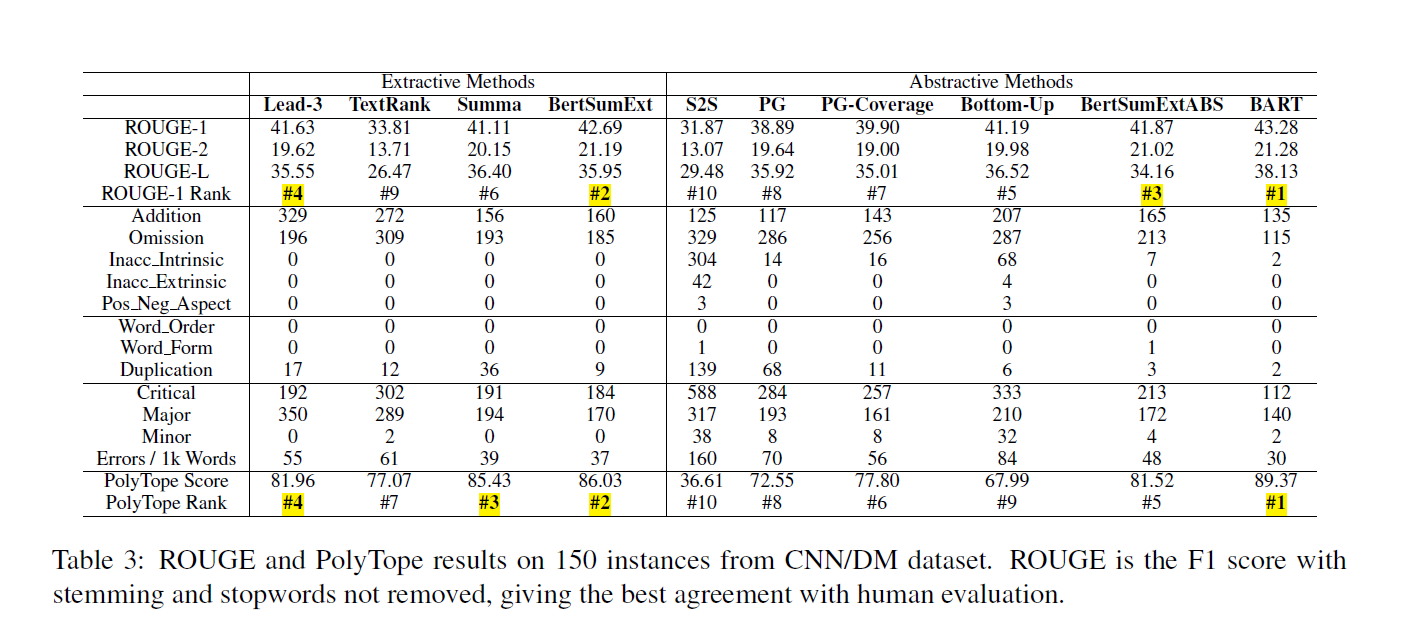
结果分析
神经网络VS非神经网络
Lead3这种Baseline很简单,但是很强,但是显然看到在Addition Error上很高,可以认为这种无监督模型在识别和移除冗余的实力较弱
抽取式VS生成式
除了巨猛的BART,抽取式模型普遍outperform生成式模型
抽取式模型的错误主要集中在addition, Omission, Duplication,对应的生成式犯的错就更多了(流畅性)
在Inacc Intrinsic and Extrinsic这一项上,抽取式模型暴打生成式(原文直接拷贝的句子)
在Addition和Omiision上抽取式摘要没有特别高(拷贝带来的丢失和附加)
抽取式内部对比
把BERTSUMExt和SummarRuNNer对比,BERT只在Duplication上有优势,可能是BERT带来的上下文建模优势
生成式内部对比
COPY机制有效的减少了Inacc-Intrinsic,这个是极度有效的,同时还减少了冗余的问题。但是这个减少是在word层面的,在句子层面的重复减少几乎为0。对于seq2seq模型,极度的依赖短期的已经解码的历史信息,对长期的历史信息的利用很不充分,copy机制复制概率加入词级别的概率。相对的在Addition Error上更高了,因为自回归的模型更加倾向于复制很长的一段
Coverage:为了减少重复问题,,减少了Duplication,Ommision,但是增加了Addtion和Inacc Intrinsic,coverage机制缺少推理能力,更加容易把一些没用的信息粘到摘要里(Coverage强制Attention value在encoder-decoder之间向右单调移动,打乱了原来的解码节奏)
混合型模型
混合型的模型ROUGE高,但是评测模型分数低:由于混合模型的特性Recall高,ROUGE吃香,但是连贯性等等的的问题还是存在
Pretrain
先前的实验说明了LSTM和Transformer之间其实没有很大的性能差异,之所以BERTSUM和BART能够成功是因为pretrain,同时这里也提到了一个新的名词“Leading bias”,也是之前由看到的,摘要多在前几句(lead3强的原因),导致了很多模型就只会选前几句,想要超过lead就要拜托这种依赖,在更广的范围选择。
其他有意思的
作者把Golden-summary也丢进去评分,并不是满分
- 原文和摘要之间存在等价,但是表达不同的部分
- 摘要利用了外部的信息,

若有收获,就点个赞吧
0 人点赞
