关系抽取
找到一个人关系的demo
感觉人人之间的关系其实推广就是一般的实体之间的关系了?
unknown 0父母 1夫妻 2师生 3兄弟姐妹 4合作 5情侣 6祖孙 7好友 8亲戚 9同门 10上下级 11
使用BiLSTM+Attention模型
这个模型里和之前不同的就是他似乎把位置向量计入了模型运行
也就是不仅仅计算词向量,还有位置向量,初步看是直接拼接
#coding:utf8import torchimport torch.nn as nnimport torch.nn.functional as Ftorch.manual_seed(1)class BiLSTM_ATT(nn.Module):def __init__(self,config,embedding_pre):super(BiLSTM_ATT,self).__init__()self.batch = config['BATCH']self.embedding_size = config['EMBEDDING_SIZE']self.embedding_dim = config['EMBEDDING_DIM']self.hidden_dim = config['HIDDEN_DIM']self.tag_size = config['TAG_SIZE']self.pos_size = config['POS_SIZE']self.pos_dim = config['POS_DIM']self.pretrained = config['pretrained']if self.pretrained:#self.word_embeds.weight.data.copy_(torch.from_numpy(embedding_pre))self.word_embeds = nn.Embedding.from_pretrained(torch.FloatTensor(embedding_pre),freeze=False)else:self.word_embeds = nn.Embedding(self.embedding_size,self.embedding_dim)self.pos1_embeds = nn.Embedding(self.pos_size,self.pos_dim)self.pos2_embeds = nn.Embedding(self.pos_size,self.pos_dim)self.relation_embeds = nn.Embedding(self.tag_size,self.hidden_dim)self.lstm = nn.LSTM(input_size=self.embedding_dim+self.pos_dim*2,hidden_size=self.hidden_dim//2,num_layers=1, bidirectional=True)self.hidden2tag = nn.Linear(self.hidden_dim,self.tag_size)self.dropout_emb=nn.Dropout(p=0.5)self.dropout_lstm=nn.Dropout(p=0.5)self.dropout_att=nn.Dropout(p=0.5)self.hidden = self.init_hidden()self.att_weight = nn.Parameter(torch.randn(self.batch,1,self.hidden_dim))self.relation_bias = nn.Parameter(torch.randn(self.batch,self.tag_size,1))def init_hidden(self):return torch.randn(2, self.batch, self.hidden_dim // 2)def init_hidden_lstm(self):return (torch.randn(2, self.batch, self.hidden_dim // 2).cuda(),torch.randn(2, self.batch, self.hidden_dim // 2).cuda())def attention(self,H):M = F.tanh(H)a = F.softmax(torch.bmm(self.att_weight,M),2)a = torch.transpose(a,1,2)return torch.bmm(H,a)def forward(self,sentence,pos1,pos2):self.hidden = self.init_hidden_lstm()embeds = torch.cat((self.word_embeds(sentence),self.pos1_embeds(pos1),self.pos2_embeds(pos2)),2)embeds = torch.transpose(embeds,0,1)lstm_out, self.hidden = self.lstm(embeds, self.hidden)lstm_out = torch.transpose(lstm_out,0,1)lstm_out = torch.transpose(lstm_out,1,2)lstm_out = self.dropout_lstm(lstm_out)att_out = F.tanh(self.attention(lstm_out))#att_out = self.dropout_att(att_out)relation = torch.tensor([i for i in range(self.tag_size)],dtype = torch.long).repeat(self.batch, 1).cuda()relation = self.relation_embeds(relation)res = torch.add(torch.bmm(relation,att_out),self.relation_bias)res = F.softmax(res,1)return res.view(self.batch,-1)
结果
并没有复现出原文的结果
下面的是没有使用他提供的预训练词向量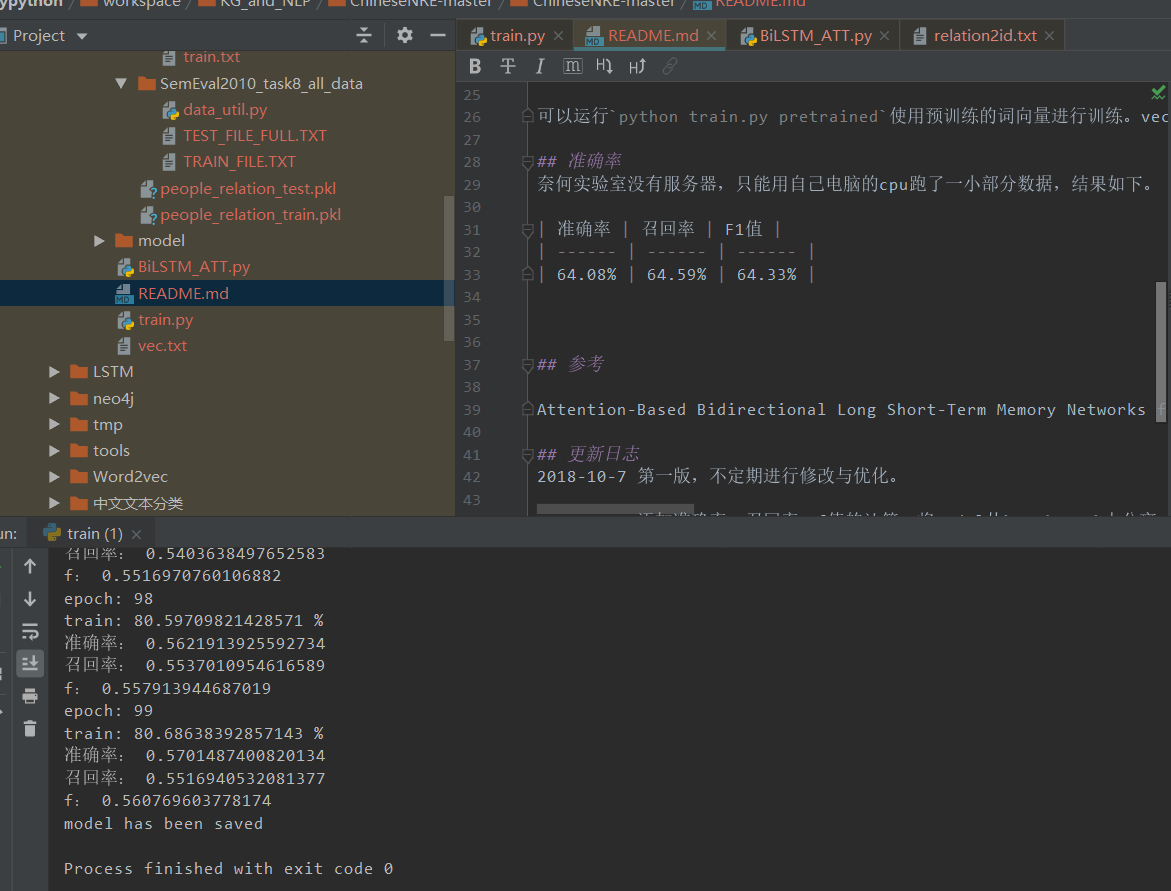
加上了预训练词向量后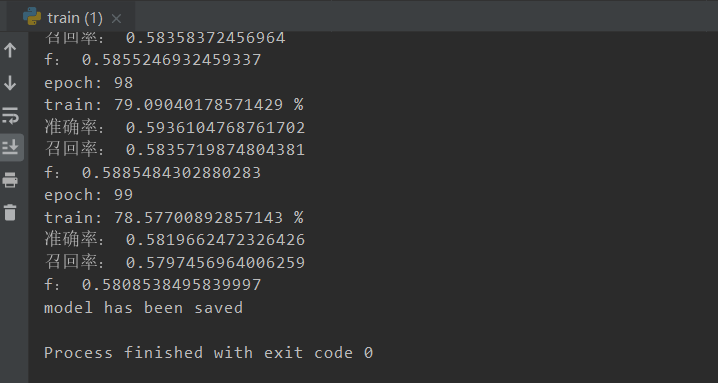
踩坑
问题1
RuntimeError: DataLoader worker (pid(s) 7836, 11392) exited unexpectedly
在Window里试图使用多线程加载导致
解决办法:num_workers=2, # subprocesses for loading data
注释子进程即可# num_workers=2
问题2
codecs不可用
可能是python3里没有这个?安装不成功。
原先的是codecs.open,直接替换为open即可(参数遵循open的规则)
问题3
RuntimeError: Expected object of backend CUDA but got backend CPU for argument .。。。
这个问题是部分的数据没有完全拷贝上cuda导致的
这里一直卡住是因为有一部分的数据是在forward的时候才创建的并参与计算
我猜想model.cuda的拷贝只是把init的时候创建的数据拷贝
所以在所有能加上cuda的地方全部加上即可
问题4
AttributeError: ‘dict’ object has no attribute ‘has_key’
对于这个只要换成 word in dict即可
下一步
- 看看有没有更好的demo可用
- 重新阅读一下之前ner的框架,完全看懂怎么用bert做提取文本的特征的工作
数据
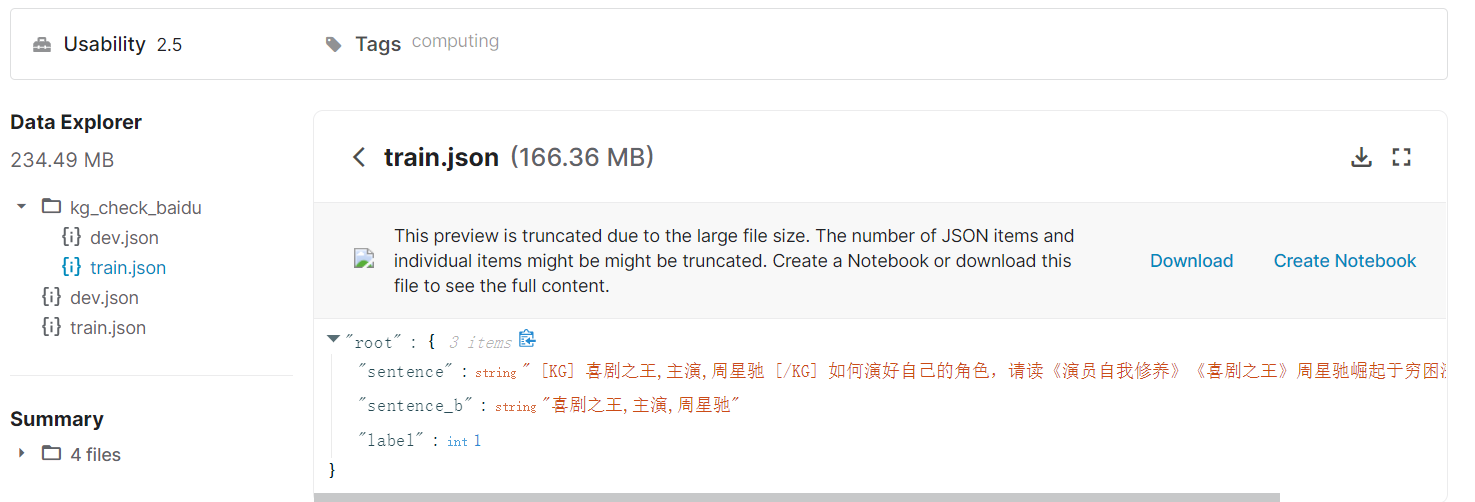
Kaggle数据
https://www.kaggle.com/freeappfans/entityrelationextraction?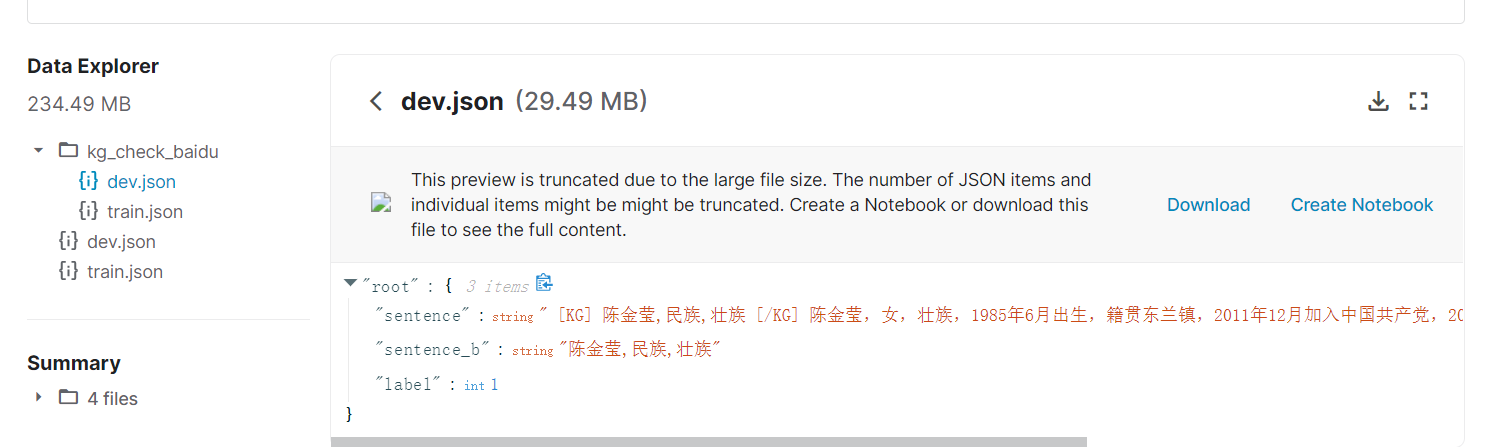
模型
https://zhpmatrix.github.io/2019/06/30/neural-relation-extraction/
前面的好理解,最后一层的Sigmiod到HeadRelation并没有看懂。。。
那么,看了上述三篇文章需要预先给定entity,实际上我们更希望直接从句子中抽取关系而非预先给定entity,同时也是个人更加喜欢的一个思路。这里的一个代表是《Joint entity recognition and relation extraction as a multi-head selection problem》,看下图:


若有收获,就点个赞吧
0 人点赞
