Bert魔改
阅读源码
初步对bert的态度是作为工具使用
暂时不关注内部的细节
看一看输出和输入即可
def __init__(self, config):super(BertForSequenceClassification, self).__init__(config)self.num_labels = config.num_labelsself.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)self.init_weights()def forward(self, input_ids=None, attention_mask=None, token_type_ids=None,position_ids=None, head_mask=None, inputs_embeds=None, labels=None):outputs = self.bert(input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,position_ids=position_ids,head_mask=head_mask,inputs_embeds=inputs_embeds)pooled_output = outputs[1]pooled_output = self.dropout(pooled_output)logits = self.classifier(pooled_output)outputs = (logits,) + outputs[2:] # add hidden states and attention if they are hereif labels is not None:if self.num_labels == 1:# We are doing regressionloss_fct = MSELoss()loss = loss_fct(logits.view(-1), labels.view(-1))else:loss_fct = CrossEntropyLoss()loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))outputs = (loss,) + outputsreturn outputs # (loss), logits, (hidden_states), (attentions)
不难发现本质就是bert的输出,加上了一个dropout层,最后用一个线性的层计算到label上
loss: (optional, returned when labels is provided) torch.FloatTensor of shape (1,): Classification (or regression if config.num_labels==1) loss.
logits: torch.FloatTensor of shape (batch_size, config.num_labels) Classification (or regression if config.num_labels==1) scores (before SoftMax).
原模型
class BertModel(BertPreTrainedModel):"""The model can behave as an encoder (with only self-attention) as wellas a decoder, in which case a layer of cross-attention is added betweenthe self-attention layers, following the architecture described in `Attention is all you need`_ by Ashish Vaswani,Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.To behave as an decoder the model needs to be initialized with the:obj:`is_decoder` argument of the configuration set to :obj:`True`; an:obj:`encoder_hidden_states` is expected as an input to the forward pass... _`Attention is all you need`:https://arxiv.org/abs/1706.03762"""def __init__(self, config):super().__init__(config)self.config = configself.embeddings = BertEmbeddings(config)self.encoder = BertEncoder(config)self.pooler = BertPooler(config)self.init_weights()[DOCS] def get_input_embeddings(self):return self.embeddings.word_embeddings[DOCS] def set_input_embeddings(self, value):self.embeddings.word_embeddings = valuedef _prune_heads(self, heads_to_prune):""" Prunes heads of the model.heads_to_prune: dict of {layer_num: list of heads to prune in this layer}See base class PreTrainedModel"""for layer, heads in heads_to_prune.items():self.encoder.layer[layer].attention.prune_heads(heads)[DOCS] @add_start_docstrings_to_callable(BERT_INPUTS_DOCSTRING)def forward(self,input_ids=None,attention_mask=None,token_type_ids=None,position_ids=None,head_mask=None,inputs_embeds=None,encoder_hidden_states=None,encoder_attention_mask=None,):r"""Return::obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):Sequence of hidden-states at the output of the last layer of the model.pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):Last layer hidden-state of the first token of the sequence (classification token)further processed by a Linear layer and a Tanh activation function. The Linearlayer weights are trained from the next sentence prediction (classification)objective during pre-training.This output is usually *not* a good summaryof the semantic content of the input, you're often better with averaging or poolingthe sequence of hidden-states for the whole input sequence.hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)of shape :obj:`(batch_size, sequence_length, hidden_size)`.Hidden-states of the model at the output of each layer plus the initial embedding outputs.attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.Attentions weights after the attention softmax, used to compute the weighted average in the self-attentionheads.Examples::from transformers import BertModel, BertTokenizerimport torchtokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertModel.from_pretrained('bert-base-uncased')input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1outputs = model(input_ids)last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple"""if input_ids is not None and inputs_embeds is not None:raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")elif input_ids is not None:input_shape = input_ids.size()elif inputs_embeds is not None:input_shape = inputs_embeds.size()[:-1]else:raise ValueError("You have to specify either input_ids or inputs_embeds")device = input_ids.device if input_ids is not None else inputs_embeds.deviceif attention_mask is None:attention_mask = torch.ones(input_shape, device=device)if token_type_ids is None:token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]# ourselves in which case we just need to make it broadcastable to all heads.if attention_mask.dim() == 3:extended_attention_mask = attention_mask[:, None, :, :]elif attention_mask.dim() == 2:# Provided a padding mask of dimensions [batch_size, seq_length]# - if the model is a decoder, apply a causal mask in addition to the padding mask# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]if self.config.is_decoder:batch_size, seq_length = input_shapeseq_ids = torch.arange(seq_length, device=device)causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]causal_mask = causal_mask.to(attention_mask.dtype) # causal and attention masks must have same type with pytorch version < 1.3extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]else:extended_attention_mask = attention_mask[:, None, None, :]else:raise ValueError("Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(input_shape, attention_mask.shape))# Since attention_mask is 1.0 for positions we want to attend and 0.0 for# masked positions, this operation will create a tensor which is 0.0 for# positions we want to attend and -10000.0 for masked positions.# Since we are adding it to the raw scores before the softmax, this is# effectively the same as removing these entirely.extended_attention_mask = extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibilityextended_attention_mask = (1.0 - extended_attention_mask) * -10000.0# If a 2D ou 3D attention mask is provided for the cross-attention# we need to make broadcastabe to [batch_size, num_heads, seq_length, seq_length]if self.config.is_decoder and encoder_hidden_states is not None:encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)if encoder_attention_mask is None:encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)if encoder_attention_mask.dim() == 3:encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]elif encoder_attention_mask.dim() == 2:encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]else:raise ValueError("Wrong shape for encoder_hidden_shape (shape {}) or encoder_attention_mask (shape {})".format(encoder_hidden_shape, encoder_attention_mask.shape))encoder_extended_attention_mask = encoder_extended_attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibilityencoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * -10000.0else:encoder_extended_attention_mask = None# Prepare head mask if needed# 1.0 in head_mask indicate we keep the head# attention_probs has shape bsz x n_heads x N x N# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]if head_mask is not None:if head_mask.dim() == 1:head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)head_mask = head_mask.expand(self.config.num_hidden_layers, -1, -1, -1, -1)elif head_mask.dim() == 2:head_mask = (head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1)) # We can specify head_mask for each layerhead_mask = head_mask.to(dtype=next(self.parameters()).dtype) # switch to fload if need + fp16 compatibilityelse:head_mask = [None] * self.config.num_hidden_layersembedding_output = self.embeddings(input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds)encoder_outputs = self.encoder(embedding_output,attention_mask=extended_attention_mask,head_mask=head_mask,encoder_hidden_states=encoder_hidden_states,encoder_attention_mask=encoder_extended_attention_mask,)sequence_output = encoder_outputs[0]pooled_output = self.pooler(sequence_output)outputs = (sequence_output, pooled_output,) + encoder_outputs[1:] # add hidden_states and attentions if they are herereturn outputs # sequence_output, pooled_output, (hidden_states), (attentions)[DOCS]@add_start_docstrings("""Bert Model with two heads on top as done during the pre-training: a `masked language modeling` head anda `next sentence prediction (classification)` head. """,BERT_START_DOCSTRING,)
from transformers import BertModel, BertTokenizerimport torchtokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertModel.from_pretrained('bert-base-chinese')input_ids = torch.tensor(tokenizer.encode("美国", add_special_tokens=True)).unsqueeze(0) # Batch size 1print(input_ids)print(input_ids.shape)outputs = model(input_ids)#print(outputs)last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tupleprint(last_hidden_states.shape)others = outputs[1]print(others.shape)
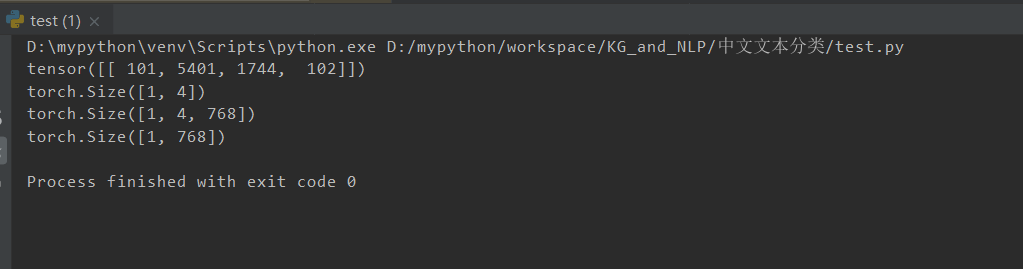
代码源头
https://github.com/huggingface/transformers/tree/master/examples/ner
利用pytorch实现的bert_ner
https://huggingface.co/transformers/_modules/transformers/modeling_bert.html#BertForSequenceClassification

若有收获,就点个赞吧
0 人点赞
