Heterogeneous Graph Neural Networks for Extractive Document Summarization
模型
初始化策略
word node就是单纯的word embedded
sentence node使用CNN捕捉n-gram,LSTM捕捉序列信息,拼接作为sentence node initial hidden state
edge weight用TF-IDF初始化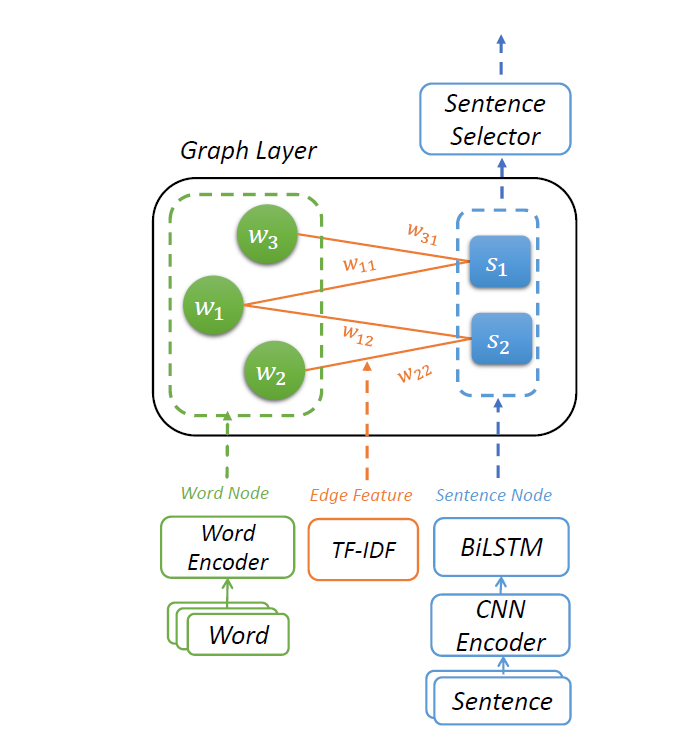
训练策略
如上所述,所有的边也就是信息的传递方向就是word和sentence的边
在边上运用Multi-Head Attention也就是GAT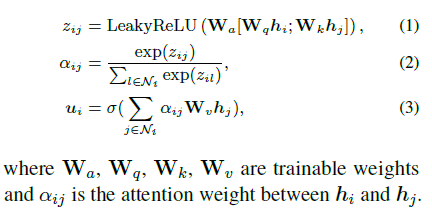
两个状态为句子状态和点状态,在边上Attention,然后FFN链接。
计算Attention分数的时候用到了
- 类似的QKV三个可学习矩阵
- 用到了edge weight映射的embedding值
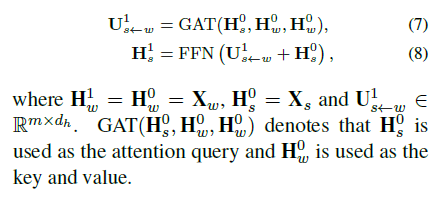
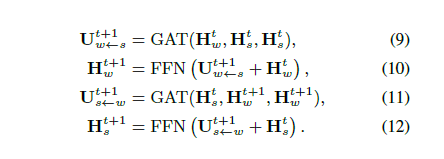
多文档模型
原理类似,增加了document level的node,初始化用句子state做pooling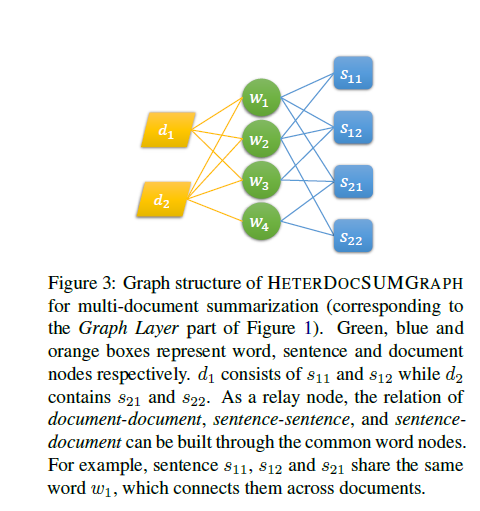
HighLight
个人总结一下亮点
- 在词和句子之间链接
- 部分词在多个句子中出现,作为一个句子之间交互的桥梁
- 上述的多次出现的词也可以看作是句子的冗余成分,被考虑在了摘要部分里
- 词里有句子信息,句子有词的信息,同时句子之间和词之间通过桥梁链接
- 利用TF-IDF初始化边权值的确有效
- 预处理的时候用TF-IDF清理了低值词
- 提升了ROUGE1和ROUGE-L,降低了ROUGE-2。提升了性能但是丢了信息
- 在原状态和传递的信息之间使用相加的ResNet
- 后面的实验证明Concatenate的效果不如相加
- 最后的数据分析里,使用Word Node 的出度入度作为冗余度的表现,得出结论对于冗余度高的数据,模型给出更好的表现,这一部分的词也能够更好的聚合句子的信息
- 利用源文档数目形容摘要复杂度,并说明多文档摘要引入Document-Level的Node的确有效

若有收获,就点个赞吧
0 人点赞
