Bert NER
初试
利用上周运行成功的模型
稍微的阅读了代码和样例文件
发现源代码提供了predict接口于是构造相同结构的数据输入
直接使用学生手册。每一行作为一个句子进行输入
"D:\Python_plus\data_set\data\student\1.txt"import jsondata=[]def get_train(filepath):try:with open(filepath, "r",encoding='utf-8') as f:lines = f.readlines()except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')id=0for i in lines:i=i.replace("\n","")if i == "":continuetemp={}temp["id"]=idtemp["text"]=iid+=1data.append(temp)path="D:\\Python_plus\\data_set\\data\\student\\1.txt"get_train(path)print(data)print(data[0])try:with open("test.json", "w", encoding='utf-8') as f:for i in data:a=json.dumps(i,ensure_ascii=False)f.write(a)f.write("\n")except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')
处理后的文本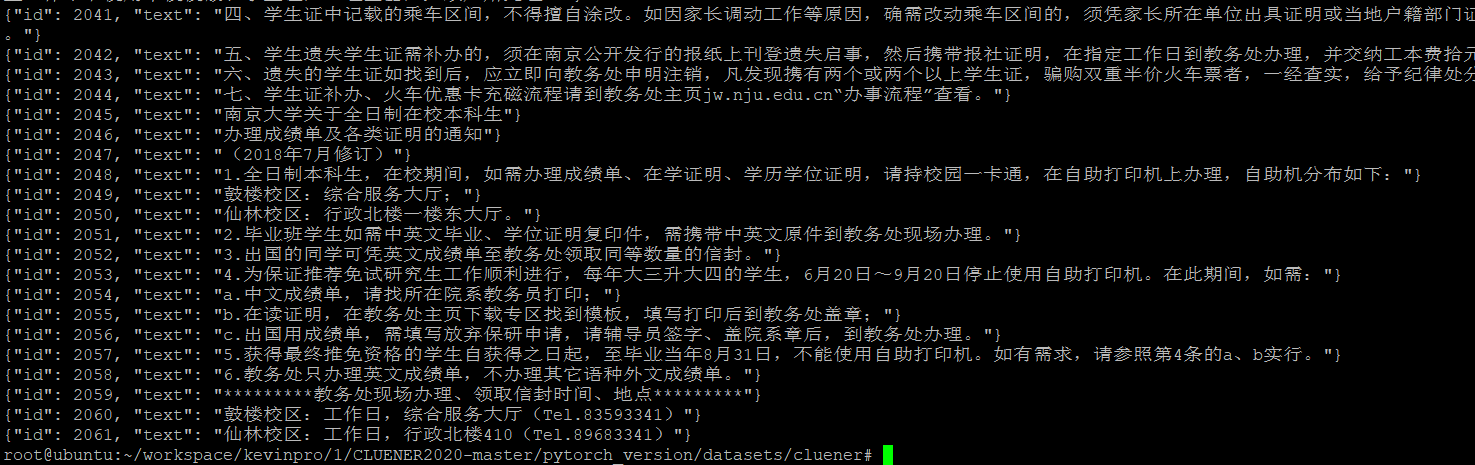
结果不理想,可能和文本本身缺乏实体以及文本的类型不一致导致,也可能这么处理过于粗糙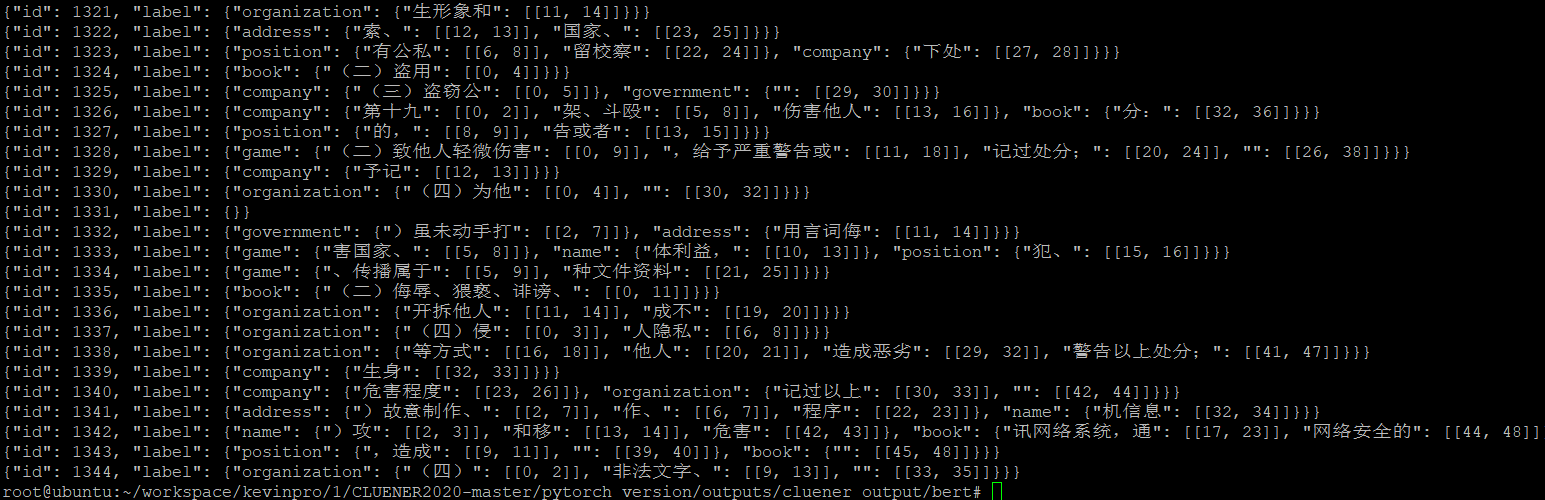
阅读代码
一直对NER任务有两种解决方案的猜想
- 做两次训练,类似于CV的目标检测,先找实体后做分类(CV也是先框出物体,再做分类)
- 直接理解为一段序列标注,不是实体的字也有一个标注,然后就是一个序列到另一个序列的转化工作,一个方法就是用字向量加全连接加Softmax
阅读了实现代码之后(没太看懂)
我个人感觉是第一种
def bert_extract_item(start_logits, end_logits):S = []start_pred = torch.argmax(start_logits, -1).cpu().numpy()[0][1:-1]end_pred = torch.argmax(end_logits, -1).cpu().numpy()[0][1:-1]for i, s_l in enumerate(start_pred):if s_l == 0:continuefor j, e_l in enumerate(end_pred[i:]):if s_l == e_l:S.append((s_l, i, i + j))breakreturn S
R = bert_extract_item(start_logits, end_logits)if R:label_entities = [[args.id2label[x[0]],x[1],x[2]] for x in R]else:label_entities = []
问题发现
上次实验的结果奇差
于是尝试更换文本实验
随便找了一篇新闻
结果还是很差
原标题:美国拟恢复资助世卫,但摊派费用要比照中国观察者网讯)据福克斯新闻5月16日报道,一份草拟的信函显示,白宫正准备恢复对世卫组织的部分资助。福克斯新闻主持人塔克·卡尔森15日表示,他得到了一份致世卫总干事谭德塞的白宫信函草稿的信息,这份5页的草稿显示,美国政府“同意支付和中国相同的摊派费用”。卡尔森还称,一名政府高级官员透露,总统特朗普已经被说服,同意签署这封信函。福克斯的报道透露了信函的一部分内容。草稿的开头写道,美国对世卫组织应对疫情的评估“证实了我(特朗普)上个月提出的担忧,并指出一些其他问题。”接着信函写道:“尽管世卫组织仍有缺陷,但我相信它仍有巨大的潜力。我希望世卫组织能够发挥这一潜力,尤其是在当下的全球疫情之中……这就是为什么我决定美国将继续和世卫组织合作。”福克斯新闻认为,这些文字显然是特朗普的口吻。在资金援助方面,美国一直是世卫组织最大的资金来源国,比尔和梅琳达·盖茨基金会则是世卫的第二大供资方。在评定会费的摊派比例上,美国最近几年的分摊比例一直为22%,而中国2020-2021双年度分摊比例为12%,这是按照各国的经济和人口状况计算出的。但截止今年3月底,美国还欠着2亿美元的会费没交。福克斯披露的信函中则这么写道,“如果中国增加了资助费用,那我们也会考虑跟着增加。”不过从报道透露的内容来看,这份信函还致力于“甩锅”:它先是写道“中国欠了世界一大笔,他们可以从向世卫组织支付合理的资助开始补偿。”接着又称,世卫组织必须隔绝“政治压力”的影响,并再次鼓吹“对病毒的起源和世卫组织的应对措施进行独立评估”。这封信函最终以要求“对世卫组织进行常识性改革”、“建立一个普遍的审查机制,公开报告会员国对国际卫生条例的遵守情况”为结尾。4月14日,特朗普曾在白宫记者会上宣布停止资助世卫组织,批评世卫组织“未能及时分享信息”、“抗疫不力”。世卫组织总干事谭德塞在4月8日就曾呼吁,不要将疫情政治化,要团结起来抗击疫情。4月22日他在回应美国停止资助时表示,他对此感到遗憾,并将寻求与其他合作伙伴一同解决资金问题

后来阅读代码,发现是源代码里对每一次的读文件运行模型都保存了缓存
也就是不管是train还是test还是predict,全都会在运行的过程中保存一个缓存
(可能是怕文件过大,可以断点继续运行?)
可能因此在预测的时候读入的是第一次的缓存文件(另一个数据文件),然后把对应的标注信息标注在了新文件上,于是直接导致了乱七八糟的标注
随后重新删除缓存,重新运行
结果显著提高
同时重新运行学生手册
似乎也不那么差(感觉对国家和组织分不太清)大体上划分还行,分类不太满意
还有切出了一堆空的是什么鬼。。。

若有收获,就点个赞吧
0 人点赞
