由于这个模型涉及到了很多的预训练策略以及很多个我不太了解的领域,所以其实没完全看懂,简单的记录一下
BART论文的主要核心内容可以分为:
- 模型结构
- 预训练策略
- 微调策略
模型基本概述
对于一般的Bert,Bert对部分的随机词进行Mask,然后双向编码文档,然后独立的预测被mask的词,因此相对而言Bert更加是独立的,不适合用于文本的生成。
对于GPT,GPT是用的自回归的从左到右的进行预测生成,所以更加适合在预测和文本生成任务上,但是问题就在于他的自回归就只会用到单向的信息,所以也有一定的局限性
于是BART相当于就是结合了二者,使用了一个Seq2Seq的模型,注意到这里的Seq2Seq二者合在一起才是一个Encoder,相当于是一个Bert。BART使用了一个双向的Encoder(类似于Bert),然后使用了一个自回归的Decoder(相当于是一个GPT),也就是说BART近似=BERT+GPT。
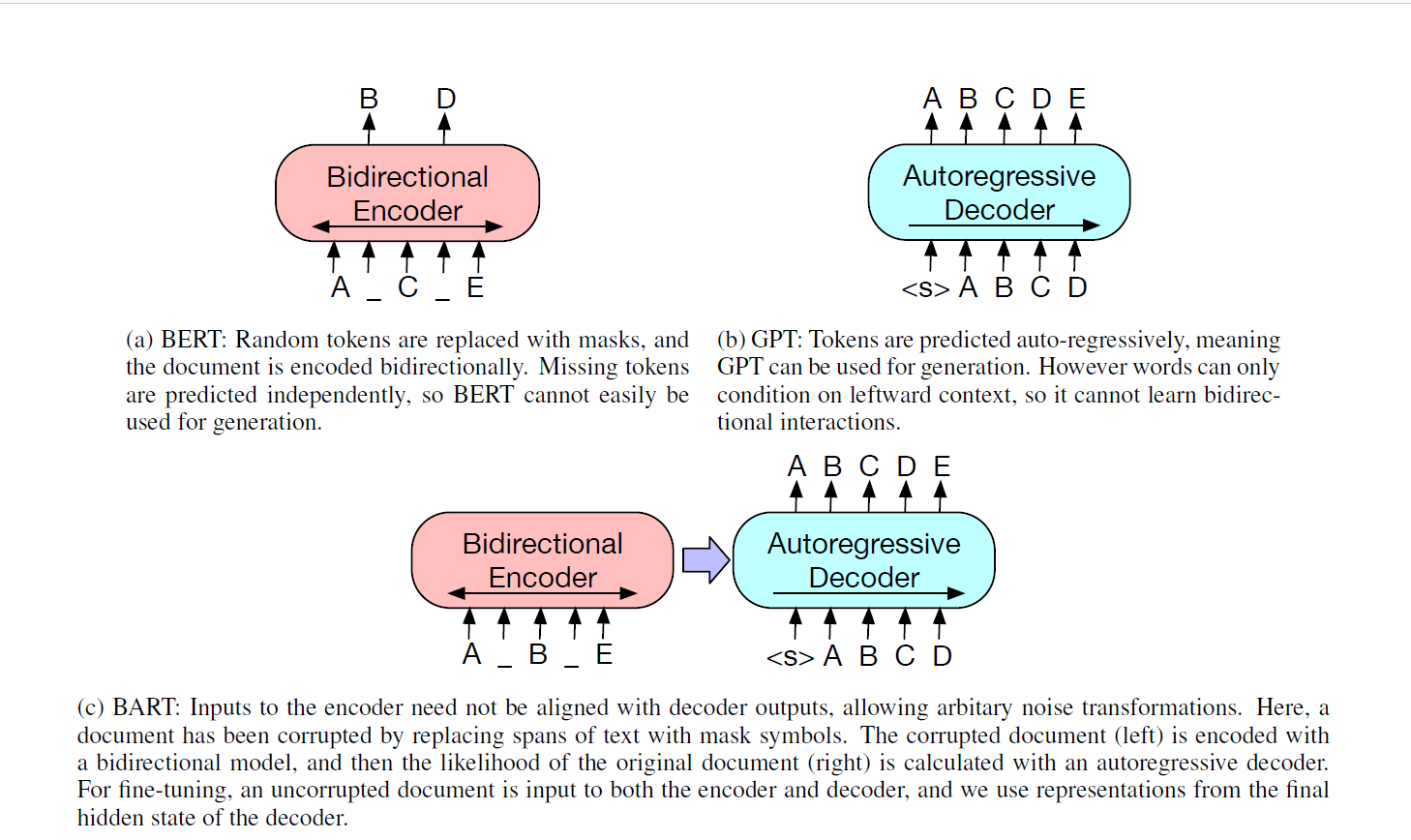
同时BART做了一些小的改动,但是我也不太了解相关的
- 把ReLU改为GeLUs,同时初始化正太分布
- 在Decoder层使用了Cross-Atten
- 移除了BERT里的FFN层
预训练策略
对于现有的预训练模型,一般就是MLM,做MASK
BART其实大致也不例外,不过作者的描述是对一个”污染,腐蚀“的文档做重构的工作,然后优化交叉熵。
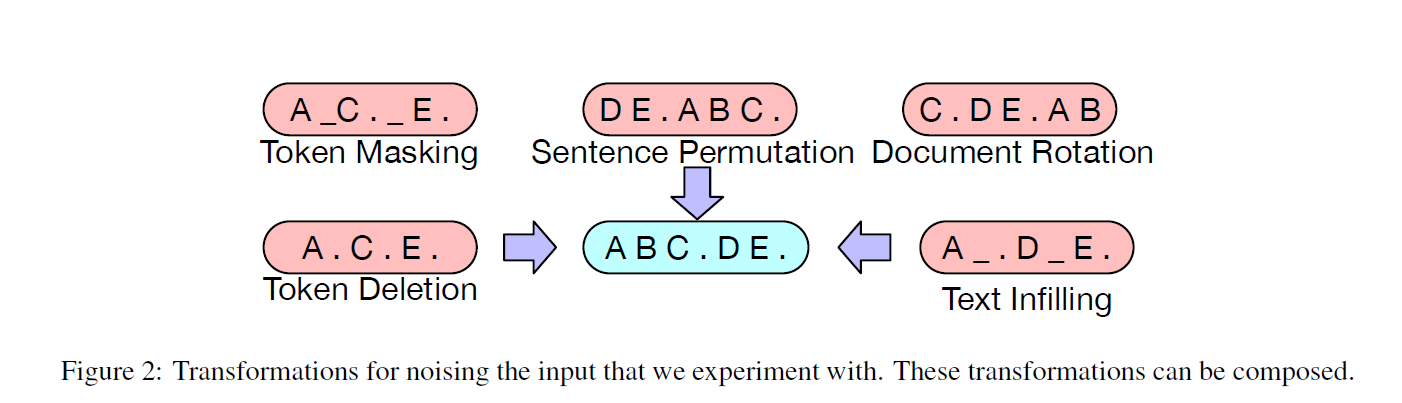
只不过BART设计了很多种的策略
- Token Masking,Mask一些字词然后用【MASK】替代
- Token Deletion 直接删除了一部分的词语,对应的就会考验模型识别丢失部分的能力(有文档生成那味道)
- Text Infilling 把一段文字只用一个MASK代替,对应考验模型预测多少Token丢失的能力
- Sentence Permutation 打乱句子的顺序
- Document Rotation 用一个词打头,前面的部分接到后面。考验模型识别文档开头的能力
微调策略
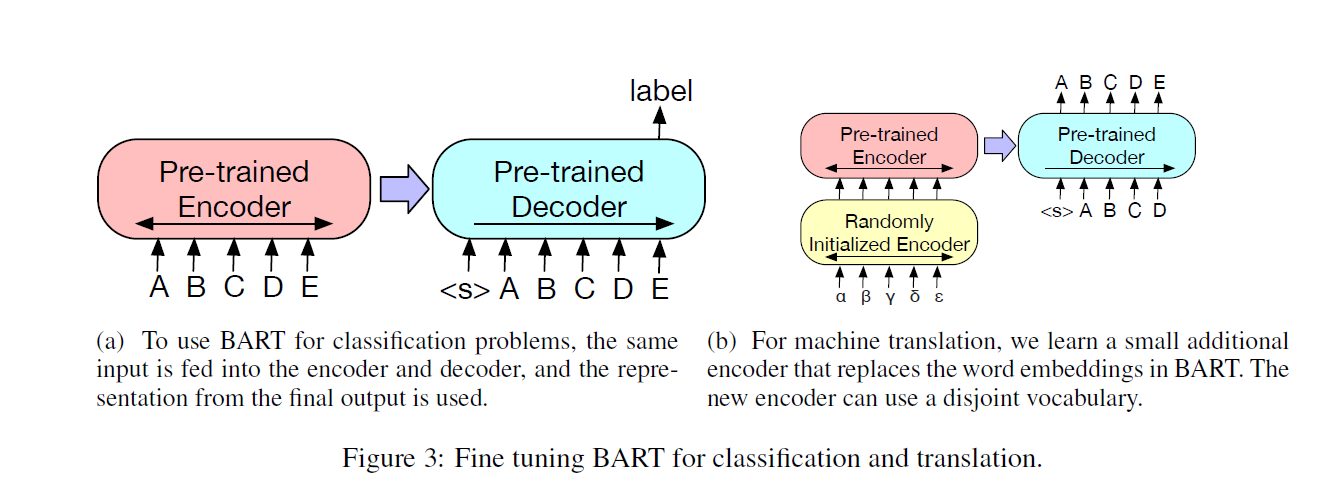
- Sequence Classification Tasks 直接把同样的input输入encoder和decoder,然后类似CLS策略
- Token Classification Tasks 同样的输入整个文档,然后用decoder最顶层的状态作为最后的每一个token的表示
- Sequence Generation Tasks BART本身就是自回归的,所以可以直接用在生成任务上
- Machine Translation 先前就已经证明了使用pretrain的encoder的收益较大,对应使用pretrain的decoder的收益比较有限。于是他的做法比较有意思:
- 先使用一个随机初始化的encoder先把文章编译到一个hidden-state,然后在使用encoder-decoder的BART进行任务,新的encoder可以使用不一样的词表。
- 另一个比较有意思的点就是他用了类似我之前说的一个思路:先Fix住BART的部分参数,对随机初始化的encoder进行训练,然后解封一起训练少数的几个步数
模型分析
BART的最大贡献就是提出了一个新的框架,以及新的一些pretrain策略,于是作者在分析里进行了比较
比较的对象:
- Language Model 就是类似于GPT的最简单的从左向右的Transformer
- Permuted Language Model 类似于XLNet的,采样,然后随机顺序的自回归预测
- Masked Language Model 类似于BERT的,对15%使用MASK,然后独立预测Token
- Multitask Masked Language Model 类似于UniLM,上述的强化,使用了很多种的MASK策略
- Masked Seq-to-Seq 类似于MASS,直接MASK一个含50%的span,然后用seq2seq预测
对于Permuted LM, Masked LM and Multitask Masked LM使用了一个two-stream attention(没听说过)
实验主要是两个部分
- 标准的Seq2Seq任务,输入input人,然后output结果
- 直接把原文作为前缀加到Target上,损失就是只有序列Target的部分
前者BART更好,后者其他模型更好
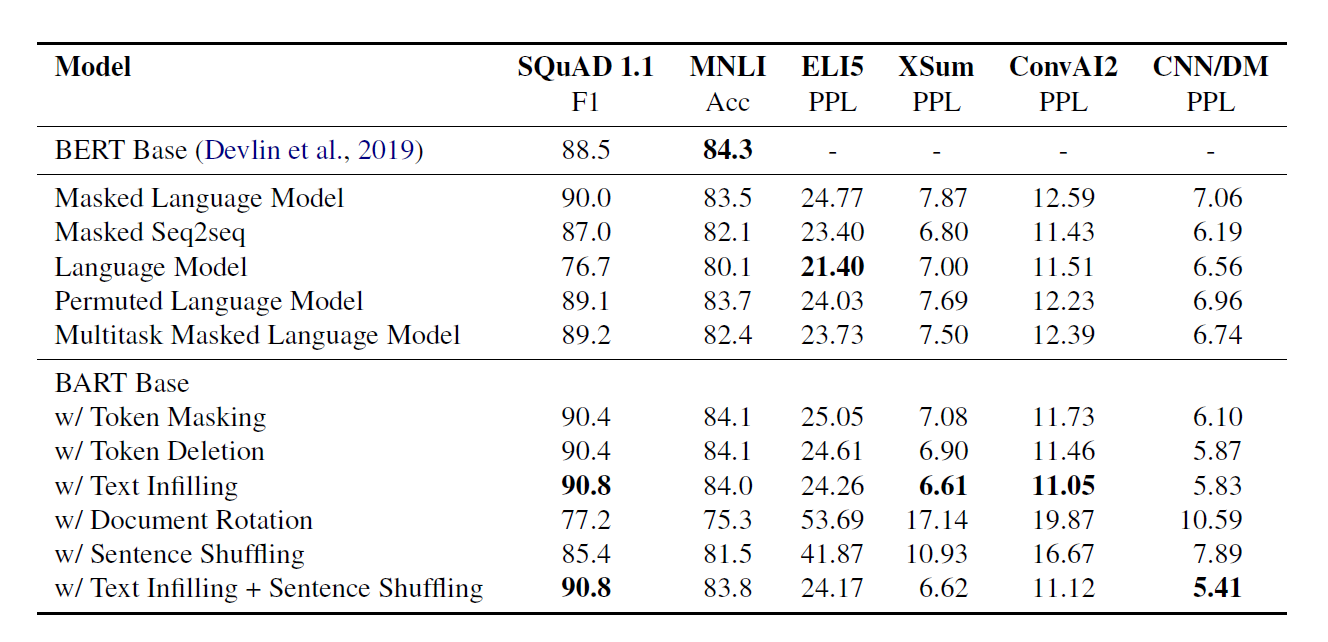
测试
- SQUAD QA数据
- MNLI 句子分类任务
- ELI5 一个长抽象问答数据
- XSUM 比较适合生成式摘要的一个数据集
- CNN/DM 一个摘要和原文比较接近的数据集
结论
- 模型在任务间的表现差距很大(没有一个模型样样都好)、
- Token masking is crucial 对于使用MASK策略模型表现都不错,调整语序的相对差
- 从左到右的pretrain对生成任务效果好
- 双向的encoder对SQUAD很重要,因为需要未来的信息
- pretrain不是唯一的决定因素,其他的一些模型结构和参数也很重要
实验二
第二次实验的对照目标更多的是RoBerta,因为一些pretrain的设置和他相似
在分类任务上(SQUAD等等)并没有看到显著优势
生成任务上优势显著,生成式的任务包括摘要,对话,抽象QA(上面的QA是从原文找答案的QA所以说是分类,这里的QA类似生成式摘要的手法),翻译。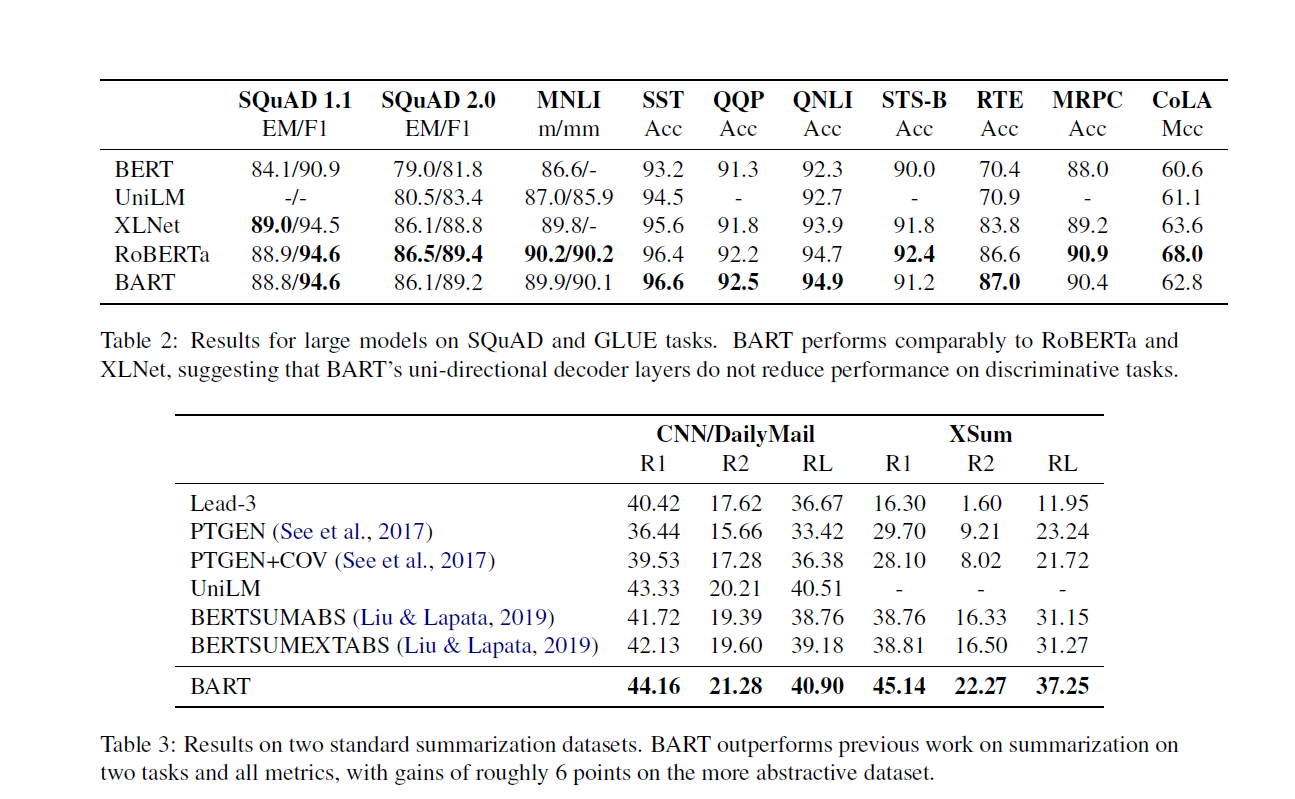
总结
- GPT:只用了右边的信息
- ELMo:只是简单的拼接左右边的信息,没有充分利用feature
- BERT:用到了左右边的信息,很强,但是应用到生成式任务里不是回归式的,还是有一点问题
- UniLM:使用了多种MASK,同时只允许一个方向的解码,和BART有点像,但是预测还是有点独立(不太懂这个模型,原话:”UniLM predictions are conditionally independent, whereas BART’s are autoregressive.”
- MASS:和BART最像的模型。但是送进encoder和decoder的token不连续,减低了性能
- XLNet:乱序回归预测MASK Token,但是BART是Decoder由左到右的回归预测,和生成过程完全一致
BART在分类上不错,生成上暴打其他模型

若有收获,就点个赞吧
0 人点赞
