Insight & target problem
- 很多生成类型的任务需要评估
- 用Pretrain model来评估是很不错的
- 类似于BERTScore这种的,Pretrain和Eval的类型有一定的差距,PLM的优势没用上
Solution
分数就是生成概率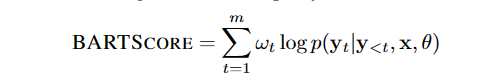
- Faithful : 输入Document,生成Hypo的概率
- Precision:输入Reference生成Hypo
- Recall:输入Hypo生成Refer的概率
- F1:上面二者的加权

变种
- 用基本的BART
- 用BART-CNN,在CNNDM上fine-tuing过的
- 用BART-CNN,在paraphrasing任务上再tuing
- 用BART + Prompt,在Decoder input prefix append

Highlight
- Prompt主要帮助的是语义上的评估,但是对于事实一致性评估的帮助很小
- 对Extractive的方法区分效果比较差,对Abstractive的区分较好
- 提升生成系统和提高评估方法是同一的,有更好的生成模型就可以作为这里的Backbone
Others
一个很大的问题,按照这么评估不会有Bias吗,比如说BART-CNN,按照模型的视角,假如用BART-CNN也生成了一个摘要,那这个摘要是不是默认的分数就是最高?假如有一个更好的摘要只不过可能风格不同,可能分数就被低估了。
BART本身就偏Copy,类似于BERTScore对ROUGE是保底的,至少可以做到Token级别的匹配

若有收获,就点个赞吧
0 人点赞
