Insight & target problem
原始的评估手段都是有很大局限
- N-gram based
- EDIT-DISTANCE-BASED METRICS
- EMBEDDING-BASED METRICS
- LEARNED METRICS
Solution
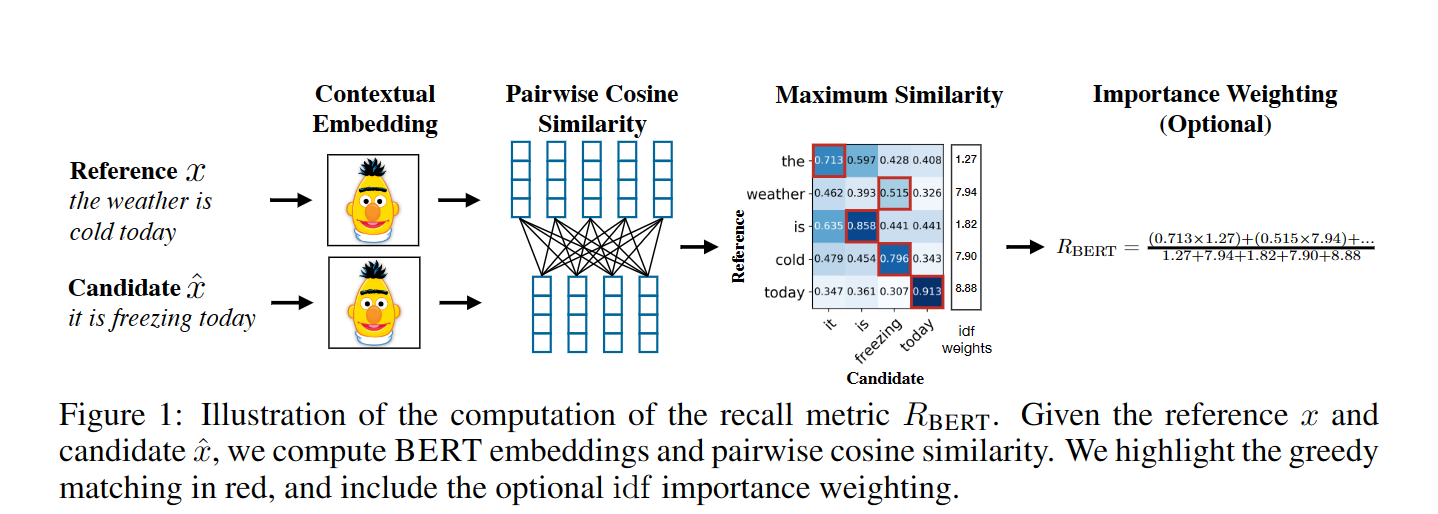
用BERT Roberta这种提供聚合了上下文的表示
进一步的,在N-gram Overlap里使用了词语或者是N-gram比较相等作为对齐
而BERTScore里用了最大概率作为对齐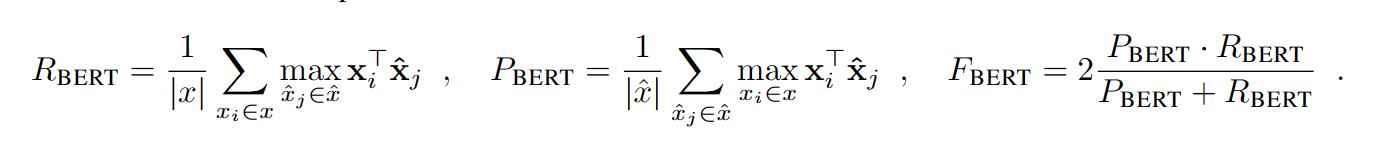
比如对于reference的当前词和summary的每一个词作相似度,然后最大的相似度保留,整个计算后取平均
相当于就是找对齐,最对齐的位置
后续使用了IDF来过滤词的重要性,一些词如停用词等等没那么大必要参与计算
Highlight
使用了一个相似度进行对齐
同时因为有BERT这种模型,可以实现较远距离的信息交流,进而包含上下文信息,匹配更加准确
Others

若有收获,就点个赞吧
0 人点赞
