ChineseBertNer
GermEval 2014
本来是计划使用之前运行成功的实例 GermEval 2014 (German NER)(英文)
观察到数据集的格式是每一行一个单词然后一个词性
原本以为自己手里是有人民日报的数据可以试一试(改一改数据格式就塞进去跑)
认真看了一下发现数据不对
这个不像是训练集(对不太上)
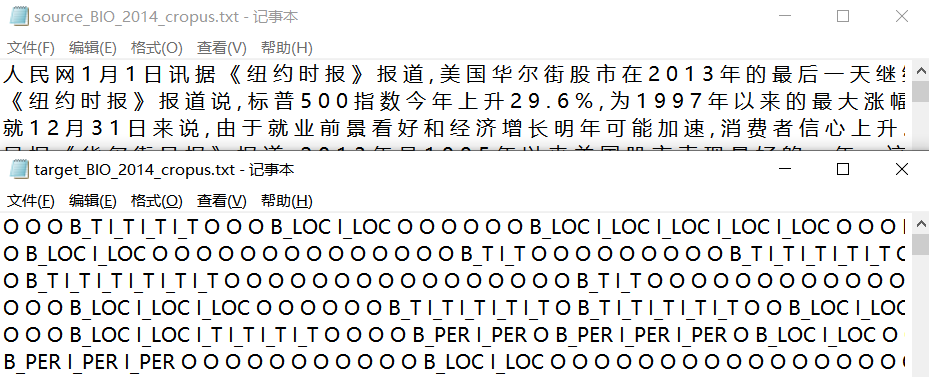
索性重新直接找一个中文的实例
CLUENER2020
https://github.com/CLUEbenchmark/CLUENER2020/tree/master/pytorch_version
我们(CLUE)基于清华大学开源的文本分类数据集THUCNEWS,选出部分数据进行细粒度命名实体标注,并对数据进行清洗,得到一个细粒度的NER数据集。 CLUENER2020 共有 10 个不同的类别,包括: 组织 > (organization)> 人名 > (name)> 地址 > (a> ddress)> 公司 > (company)> 政府 (government)> 书籍 > (book)> 游戏 > (game)> 电影 > (movie)> 职位 > (position)> 景点 > (scene)
运行参数
4 epoch 很快
CURRENT_DIR=`pwd`export BERT_BASE_DIR=bert-base-chineseexport GLUE_DIR=$CURRENT_DIR/datasetsexport OUTPUR_DIR=$CURRENT_DIR/outputsTASK_NAME="cluener"python3 run_ner_span.py \--model_type=bert \--model_name_or_path=$BERT_BASE_DIR \--task_name=$TASK_NAME \--do_train \--do_eval \--do_lower_case \--loss_type=ce \--data_dir=$GLUE_DIR/${TASK_NAME}/ \--train_max_seq_length=128 \--eval_max_seq_length=512 \--per_gpu_train_batch_size=24 \--per_gpu_eval_batch_size=24 \--learning_rate=3e-5 \--num_train_epochs=4.0 \--logging_steps=224 \--save_steps=224 \--output_dir=$OUTPUR_DIR/${TASK_NAME}_output/ \--overwrite_output_dir \--seed=42
结果
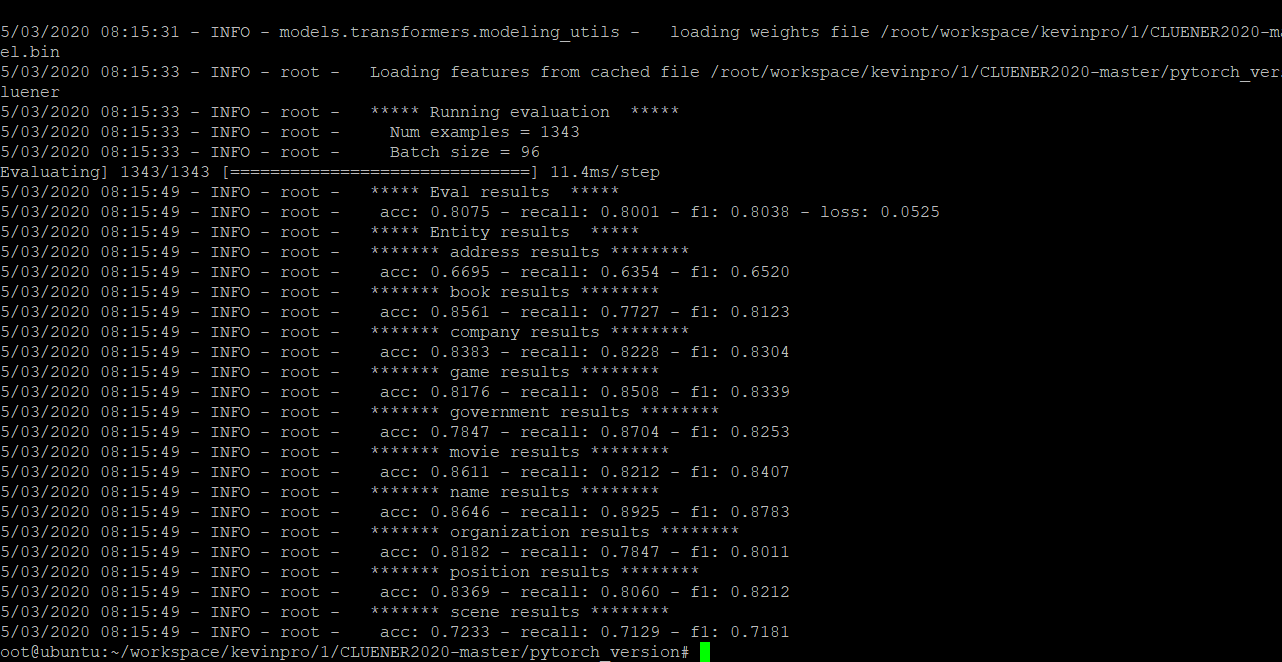
若干问题
- 运行脚本需要指定python3,否则会在f”string”的新用法上报错
 运行参数里多了一个max_len,不知道为什么设置了这个以及为什么出错,找到先前出现的位置直接注释max_len这个键值对的生成代码就可以。
运行参数里多了一个max_len,不知道为什么设置了这个以及为什么出错,找到先前出现的位置直接注释max_len这个键值对的生成代码就可以。
下一步
读读代码,看看他是怎么处理数据以及数据格式,还需要看看怎么用训练结果做预测,以及看看实战的效果
中文ner部分资料

若有收获,就点个赞吧
0 人点赞
