现有方法:
- 抽取式
- 生成式
现有衡量标准
- 人工衡量
- 自动评测
- BLEU
- MENTOR(low resource)
- Pyramid
- ROUGE
现有数据集
- DUC:English newspaper and newswire articles.数据较少,难以用作训练语料,多用于评测生成式算法
- Annotated English Gigaword,相对大一些,也用于生成式算法,千万文档。news。
- CNN/DM 和上面的相比文章更长,更难了。摘要的句子更长,有利于对长文档的多句翻译研究
- TAC 2010 没完全看懂,(Guided summarization)。似乎是根据不同的类别,概括抽取出不同的方面的内容(预设好的)
- AMI 似乎使用于会议纪要的,数据本身也来自于会议纪要
- 其他的数据:TIPSTER,IELTS(中文数据),IELTS分别是新闻,聊天和邮件数据
传统方法
早期方法
- 句子压缩
- 句子融合
- 句子修正
完全版本的生成式算法
- 信息抽取,抽取得到重要信息,根据一些语法词语等等
- 内容选择,从上面的结果里选择一些出来,用一些ILP方法,计算所谓的权重来选择
- 表层生成,根据上面的结果,组合在一起形成最后的结果
基于图的方法
- event semantic link networks ESLN把输入作为一个图,然后一个事件是一个节点,然后用ILP
- entailment graphs 移除有冗余的部分,保留包含信息较多的部分
- word graph 编码句子为一个有向带权图,相似的词被合并,摘要是图的一条最优路径
基于模板
- 人的摘要有一定格式特征
编码特征得到模板,摘要生成变成了填空题
一般都是用word级别(中文可能用的是字级别的,防止分词错误积累),进一步的使用一些预训练的wordvec
- 对于长文档的编码是一个挑战,有的是使用使用抽取模型选择有代表性的句子压缩,然后编码
- 有的是使用了背景知识,比如识别出实体,然后用外部的知识库指导decoder生成更好的摘要
select encoder
- CNN
- RNN
- LSTM
- GRU
decoder
- 接受前一个时间步产生的结构和enoder结果,产生一个prob distribute
- 这里出现了beam search策略
Improment
- Attention,句子和词语粒度的Attention
- Distraction/coverage
- distraction可以防止Attention过度的关注部分信息导致的过度的冗余
- coverage 看作是设置了对冗余的惩罚,算到原loss里
- Pointer networks/Copy mechanism 现有的模型缺少能够生成稀缺词以及OOV现象的能力
- pointer network 能够直接从原输入中拷贝词到生成结果
- copy机制和上面类似,只不过范围更大,不止仅考虑OOV和稀缺词,直接拷贝一段到结果里
- 如上的机制过度使用会导致生成式算法和抽取式算法就没有什么区别了。所以限制使用。
- 有的是结合了上面的机制和其他的语言学的方法,如copy一个词认为是重要的以及依存树的位置
强化学习方法
提出的原因:
- 最大似然的训练目的和ROUGE值提升不完全等价
- encoder-decoder训练的时候,decoder可以看到正确答案,test的时候看不到:“exposure bias”
使用了强化学习之后,可以不再使用ML目标,而是直接使用ROUGE作为奖赏利用到强化学习上训练模型,同时把模型的视野提高了,直接观察到ROUGE的变化,从Word-level到了sentence-level
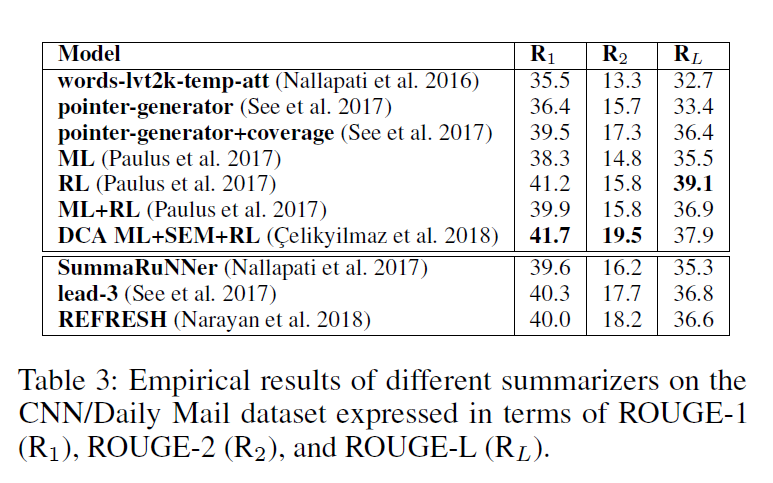
SOTA Model
Concluding Remarks
- Text simplification 长句编码仍有问题
- phrase-based model phrase-based能够捕获更多的上下文,woed and phrase based还能结合二者的优势,同时pointer方法也能够一次选择多个词(词连续出现,连贯性)
- 多文档摘要生成,压缩多文档,然后用单文档生成模型
- 评测种类:新闻的数据比较多,以及新闻的文本结构更规整,其他类领域的数据也有探究的必要
- beyond seq2seq:seq2seq模型可解释性差,可以研究更好的可解释的模型
- 评估策略:ROUGE用来评测本身还存疑(因为摘要表达可以不用相同的词语),可以考虑一些其他的方案,甚至是外部的评测策略,比如在下游任务上,比如问答。

若有收获,就点个赞吧
0 人点赞
