1 基本思想
GAN全称对抗生成网络,顾名思义是生成模型的一种,而他的训练则是处于一种对抗博弈状态中的。下面举例来解释一下GAN的基本思想。
从前有一个臭造假钞的(生成),一开始,他的技术很烂,造的假钞跟彩色打印机印的似得,他拿着造的假钞去消费;结果被警察(鉴别)逮个正着,警察羞辱他说“你这假钞颜色都不对劲呀”。在局子里蹲了两周(损失);等他从局子里出来后,他痛定思痛,反思了自己为什么会被抓住,更新了自己的造价技术(颜色很像了),结果又被警察抓住,“你这纹理也不对呀”!结果又被抓了蹲了两年。最后他出狱,反思了自己的造价技术,最终…人民币出新版的啦!!!
其实这个比喻体现了臭造假钞的和警察之间的博弈,警察也需要不断的观察假钞和真钞的区别才能更好的辨别出来哪些是真的。
2 GAN浅析
2.1 GAN的基本结构
GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。
在上面的例子中的球员就相当于生成器,我们需要他在球场上能有好的表现。而球员一开始都是初学者,这个时候就需要一个教练员来指导他们训练,告诉他们训练得怎么样,直到真的能够达到上场的标准。而这个教练就相当于判别器。
下面我们举另外一个手写字的例子来进行进一步窥探GAN的结构。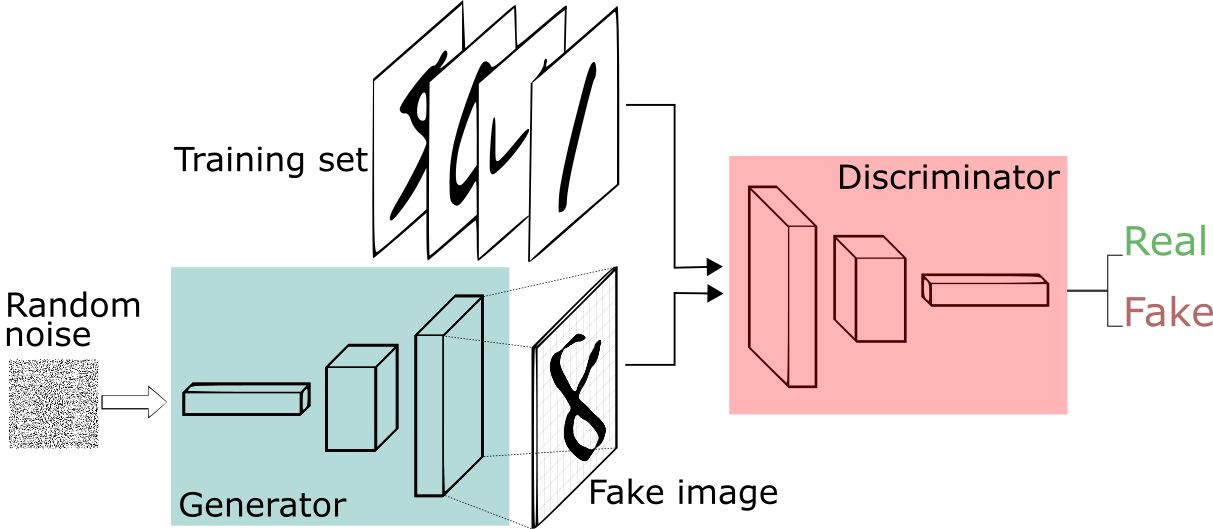
图三 GAN基本结构
我们现在拥有大量的手写数字的数据集,我们希望通过GAN生成一些能够以假乱真的手写字图片。主要由如下两个部分组成:
- 定义一个模型来作为生成器(图三中蓝色部分Generator),能够输入一个向量,输出手写数字大小的像素图像。
- 定义一个分类器来作为判别器(图三中红色部分Discriminator)用来判别图片是真的还是假的(或者说是来自数据集中的还是生成器中生成的),输入为手写图片,输出为判别图片的标签。
2.2 GAN的训练方式
前面已经定义了一个生成器(Generator)来生成手写数字,一个判别器(Discrimnator)来判别手写数字是否是真实的,和一些真实的手写数字数据集。那么我们怎样来进行训练呢?
2.2.1 关于生成器
对于生成器,输入需要一个n维度向量,输出为图片像素大小的图片。因而首先我们需要得到输入的向量。
Tips: 这里的生成器可以是任意可以输出图片的模型,比如最简单的全连接神经网络,又或者是反卷积网络等。这里大家明白就好。
这里输入的向量我们将其视为携带输出的某些信息,比如说手写数字为数字几,手写的潦草程度等等。由于这里我们对于输出数字的具体信息不做要求,只要求其能够最大程度与真实手写数字相似(能骗过判别器)即可。所以我们使用随机生成的向量来作为输入即可,这里面的随机输入最好是满足常见分布比如均值分布,高斯分布等。
Tips: 假如我们后面需要获得具体的输出数字等信息的时候,我们可以对输入向量产生的输出进行分析,获取到哪些维度是用于控制数字编号等信息的即可以得到具体的输出。而在训练之前往往不会去规定它。
2.2.2 关于判别器
对于判别器不用多说,往往是常见的判别器,输入为图片,输出为图片的真伪标签。
Tips: 同理,判别器与生成器一样,可以是任意的判别器模型,比如全连接网络,或者是包含卷积的网络等等。
2.2.3 如何训练
上面进一步说明了生成器和判别器,接下来说明如何进行训练。
基本流程如下:
- 初始化判别器D的参数
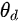 和生成器G的参数
和生成器G的参数 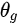 。
。 - 从真实样本中采样
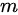 个样本 {
个样本 { 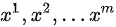 } ,从先验分布噪声中采样
} ,从先验分布噪声中采样 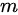 个噪声样本 {
个噪声样本 { 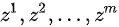 } 并通过生成器获取
} 并通过生成器获取 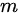 个生成样本 {
个生成样本 { 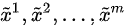 } 。固定生成器G,训练判别器D尽可能好地准确判别真实样本和生成样本,尽可能大地区分正确样本和生成的样本。
} 。固定生成器G,训练判别器D尽可能好地准确判别真实样本和生成样本,尽可能大地区分正确样本和生成的样本。 - 循环k次更新判别器之后,使用较小的学习率来更新一次生成器的参数,训练生成器使其尽可能能够减小生成样本与真实样本之间的差距,也相当于尽量使得判别器判别错误。
- 多次更新迭代之后,最终理想情况是使得判别器判别不出样本来自于生成器的输出还是真实的输出。亦即最终样本判别概率均为0.5。
Tips: 之所以要训练k次判别器,再训练生成器,是因为要先拥有一个好的判别器,使得能够教好地区分出真实样本和生成样本之后,才好更为准确地对生成器进行更新。更直观的理解可以参考下图: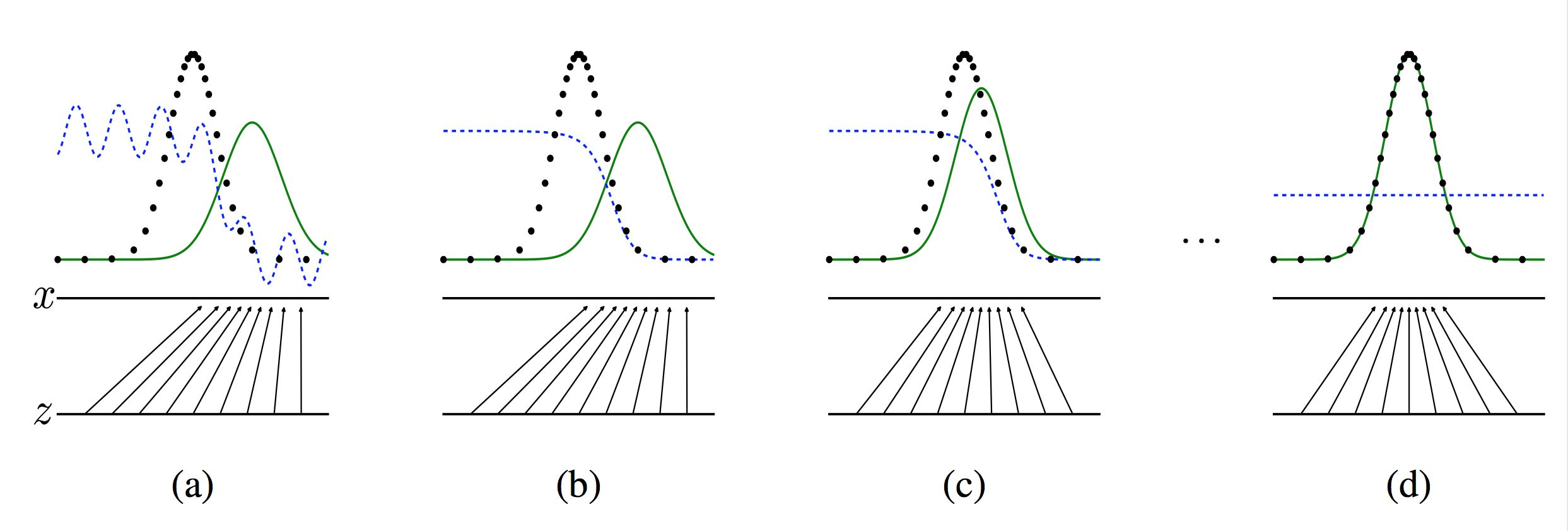
图四 生成器判别器与样本示意图
注:图中的黑色虚线表示真实的样本的分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。 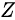 表示噪声,
表示噪声, 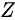 到
到 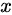 表示通过生成器之后的分布的映射情况。
表示通过生成器之后的分布的映射情况。
我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的。
可以看到在(a)状态处于最初始的状态的时候,生成器生成的分布和真实分布区别较大,并且判别器判别出样本的概率不是很稳定,因此会先训练判别器来更好地分辨样本。
通过多次训练判别器来达到(b)样本状态,此时判别样本区分得非常显著和良好。然后再对生成器进行训练。
训练生成器之后达到(c)样本状态,此时生成器分布相比之前,逼近了真实样本分布。
经过多次反复训练迭代之后,最终希望能够达到(d)状态,生成样本分布拟合于真实样本分布,并且判别器分辨不出样本是生成的还是真实的(判别概率均为0.5)。也就是说我们这个时候就可以生成出非常真实的样本啦,目的达到。
3. 训练相关理论基础
前面用了大白话来说明了训练的大致流程,下面会从交叉熵开始说起,一步步说明损失函数的相关理论,尤其是论文中包含min,max的公式如下图5形式: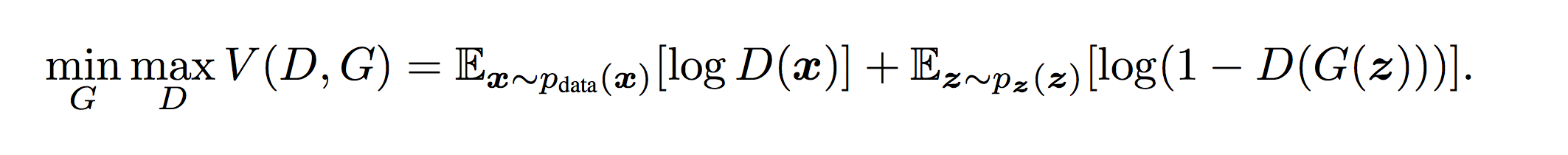
图5 minmax公式
判别器在这里是一种分类器,用于区分样本的真伪,因此我们常常使用交叉熵(cross entropy)来进行判别分布的相似性,交叉熵公式如下图6所示: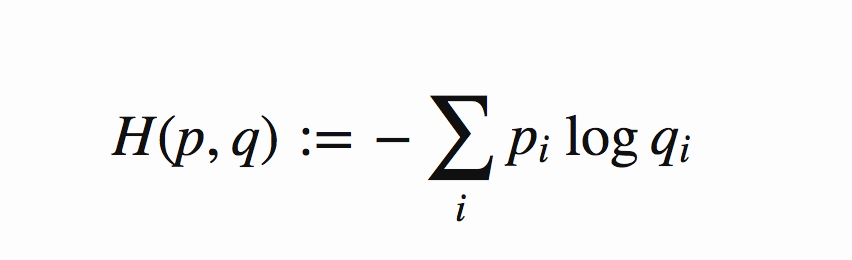
图6 交叉熵公式
Tips: 公式中 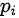 和
和 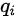 为真实的样本分布和生成器的生成分布。由于交叉熵是非常常见的损失函数,这里默认大家都较为熟悉,就不进行赘述了。
为真实的样本分布和生成器的生成分布。由于交叉熵是非常常见的损失函数,这里默认大家都较为熟悉,就不进行赘述了。
在当前模型的情况下,判别器为一个二分类问题,因此可以对基本交叉熵进行更具体地展开如下图7所示: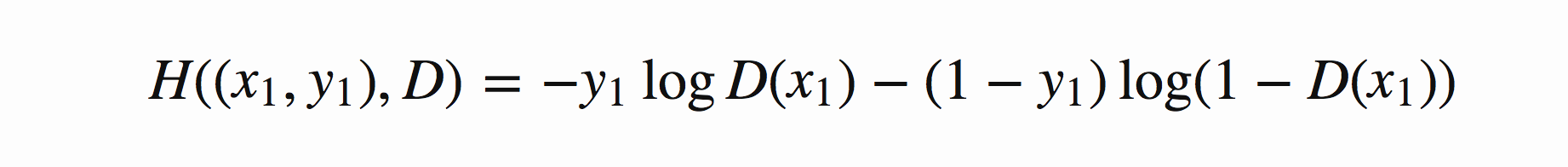
图7 二分类交叉熵
Tips: 其中,假定 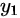 为正确样本分布,那么对应的(
为正确样本分布,那么对应的( 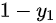 )就是生成样本的分布。
)就是生成样本的分布。 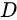 表示判别器,则
表示判别器,则 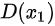 表示判别样本为正确的概率,
表示判别样本为正确的概率, 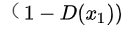 则对应着判别为错误样本的概率。这里仅仅是对当前情况下的交叉熵损失的具体化。相信大家也还是比较熟悉。
则对应着判别为错误样本的概率。这里仅仅是对当前情况下的交叉熵损失的具体化。相信大家也还是比较熟悉。
将上式推广到N个样本后,将N个样本相加得到对应的公式如下: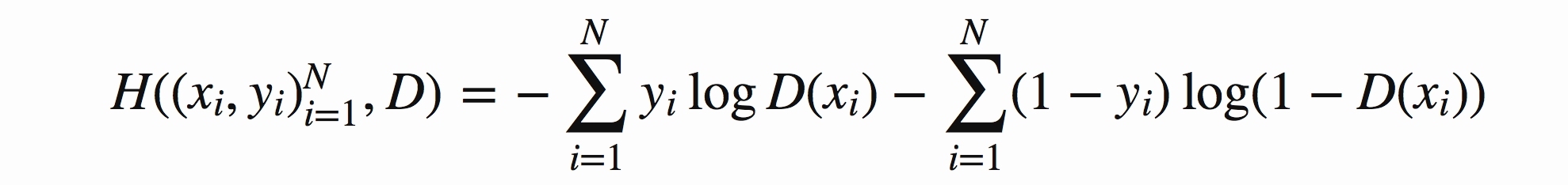
图8 N个样本的情况时
OK,到目前为止还是基本的二分类,下面加入GAN中特殊的地方。
对于GAN中的样本点 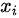 ,对应于两个出处,要么来自于真实样本,要么来自于生成器生成的样本
,对应于两个出处,要么来自于真实样本,要么来自于生成器生成的样本 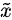 ~
~ 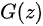 ( 这里的
( 这里的 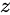 是服从于投到生成器中噪声的分布)。
是服从于投到生成器中噪声的分布)。
其中,对于来自于真实的样本,我们要判别为正确的分布 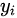 。来自于生成的样本我们要判别其为错误分布(
。来自于生成的样本我们要判别其为错误分布( 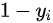 )。将上面式子进一步使用概率分布的期望形式写出(为了表达无限的样本情况,相当于无限样本求和情况),并且让
)。将上面式子进一步使用概率分布的期望形式写出(为了表达无限的样本情况,相当于无限样本求和情况),并且让 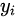 为 1/2 且使用
为 1/2 且使用 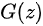 表示生成样本可以得到如下图8的公式:
表示生成样本可以得到如下图8的公式: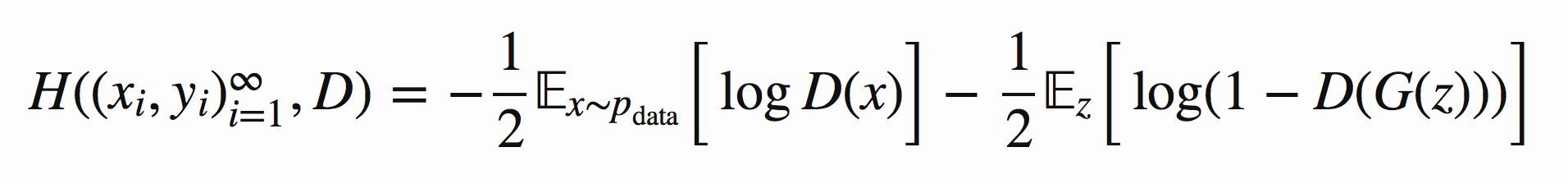
图8 GAN损失函数期望形式表达
OK,现在我们再回过头来对比原本的的 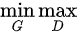 公式,发现他们是不是其实就是同一个东西呢!:-D
公式,发现他们是不是其实就是同一个东西呢!:-D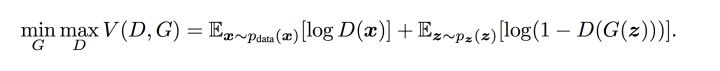
图9 损失函数的min max表达
我们回忆一下上面2.2.3中介绍的流程理解一下这里的 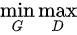 。
。
- 这里的
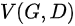 相当于表示真实样本和生成样本的差异程度。
相当于表示真实样本和生成样本的差异程度。 - 先看
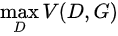 。这里的意思是固定生成器G,尽可能地让判别器能够最大化地判别出样本来自于真实数据还是生成的数据。
。这里的意思是固定生成器G,尽可能地让判别器能够最大化地判别出样本来自于真实数据还是生成的数据。 - 再将后面部分看成一个整体令
 =
= 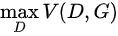 ,看
,看 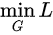 ,这里是在固定判别器D的条件下得到生成器G,这个G要求能够最小化真实样本与生成样本的差异。
,这里是在固定判别器D的条件下得到生成器G,这个G要求能够最小化真实样本与生成样本的差异。 - 通过上述min max的博弈过程,理想情况下会收敛于生成分布拟合于真实分布。
4. 总结
本文大致介绍了GAN的整体情况。但是对于GAN实际上还有更多更完善的理论相关描述,进一步了解可以看相关的论文。并且在GAN一开始提出来的时候,实际上针对于不同的情况也有存在着一些不足,后面也陆续提出了不同的GAN的变体来完善GAN。
通过一个判别器而不是直接使用损失函数来进行逼近,更能够自顶向下地把握全局的信息。比如在图片中,虽然都是相差几像素点,但是这个像素点的位置如果在不同地方,那么他们之间的差别可能就非常之大。
图10 不同像素位置的差别
比如上图10中的两组生成样本,对应的目标为字体2,但是图中上面的两个样本虽然只相差一个像素点,但是这个像素点对于全局的影响是比较大的,但是单纯地去使用使用损失函数来判断,那么他们的误差都是相差一个像素点,而下面的两个虽然相差了六个像素点的差距(粉色部分的像素点为误差),但是实际上对于整体的判断来说,是没有太大影响的。但是直接使用损失函数的话,却会得到6个像素点的差距,比上面的两幅图差别更大。而如果使用判别器,则可以更好地判别出这种情况(不会拘束于具体像素的差距)。
总之GAN是一个非常有意思的东西,现在也有很多相关的利用GAN的应用,比如利用GAN来生成人物头像,用GAN来进行文字的图片说明等等。后面我也会使用GAN来做一些简单的实验来帮助进一步理解GAN。
最后附上论文中的GAN算法流程,通过上面的介绍,这里应该非常好理解了。
图11 论文中的GAN算法流程

若有收获,就点个赞吧
0 人点赞
