- Adaptivity of deep reLU network for learning in besov and mixed smooth besov spaces: optimal rate and curse of dimensionality Taiji Suzuki iclr2018
- ">Relu deep neural networks and linear finite elements arXiv preprint arXiv:1807.03973,

- Efficient approximation of deep relu networks for functions on low dimensional manifolds Neurips2019
神经网络为什么可以(理论上)拟合任何函数? - 2prime的回答 - 知乎 https://www.zhihu.com/question/268384579/answer/1246730702
给大家一个简单答案吧
用一个fourier 变换
问题来了为啥要deep呢?
答案在这里 居然特别简单 deep了你有高频的震荡了你可以efficient 的locally逼近x^2 然后就有所有local的逼近多项式了
local polynomial在holder和sobolev space是optimal的 我们就扩大了空间了
【这篇paper发在很一般期刊上而且题目不吸引人我一直忘记 求好心人给reference
感谢评论区
Yarotsky D. Error bounds for approximations with deep ReLU networks[J]. Neural Networks, 2017, 94: 103-114.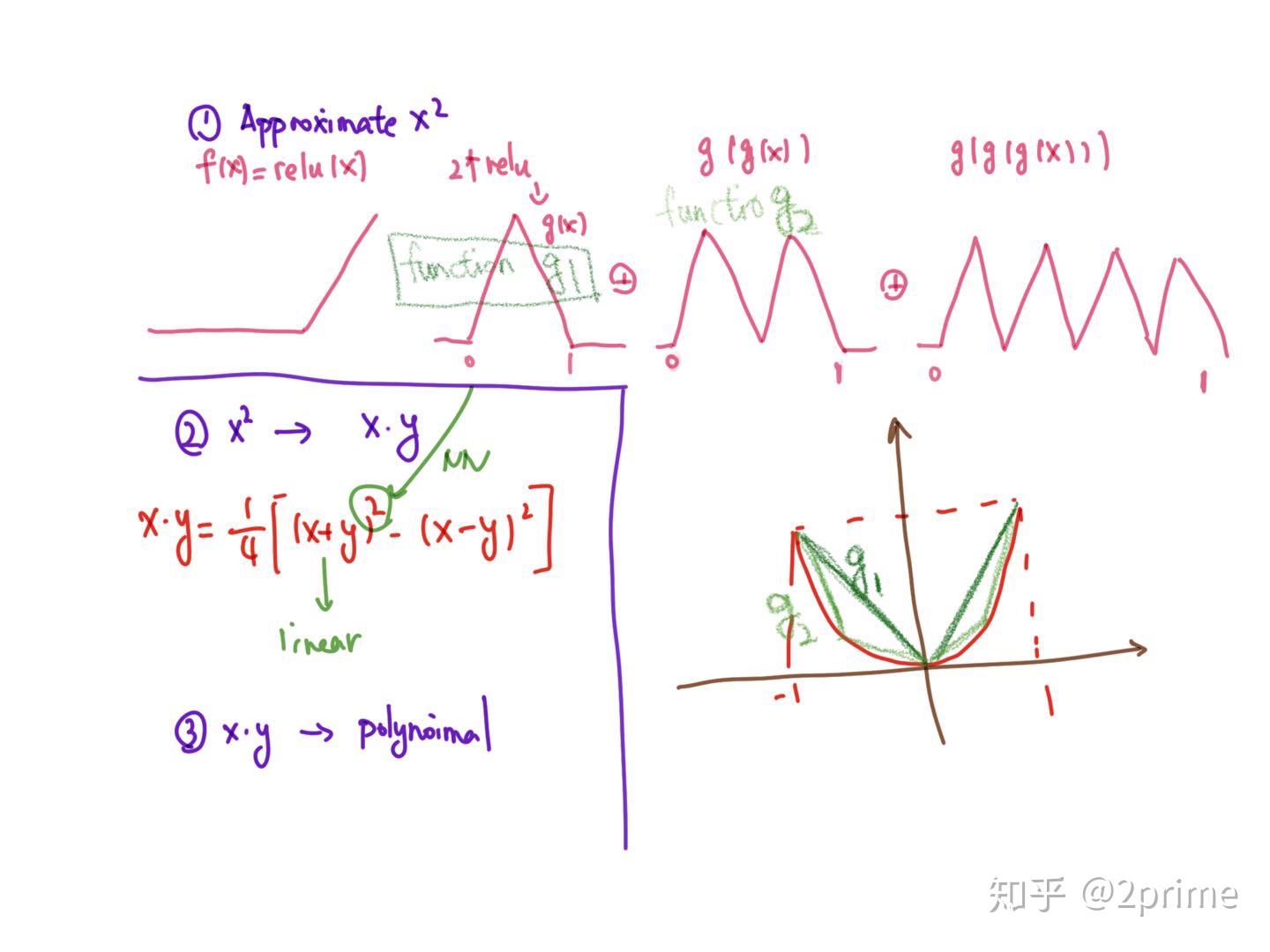
大家都知道fourier/polynomial 变化逼近非光滑函数非常的不efficient
【后面内容数学上就不trivial了
这时候我们应该用wavelet
所以后续有paper说你用四层nn 能表示出来一个wavelet变换
所以就能逼近不光滑函数,而且比起二层NN效率高很多【可以证明
【下面这篇加上了 estimation和2layer的lower bound,最早用wavelet的应该是Ronald coifman院士的paper……
Adaptivity of deep reLU network for learning in besov and mixed smooth besov spaces: optimal rate and curse of dimensionality Taiji Suzuki iclr2018
最后关于
@Lyken
提到神经网络=分片线性
篇数越来越多总能逼近
但是分的片之间有关系 而且你也只有一个片数upper bound
还是需要严格的分析
这篇想法是有限元也是分片线性 把有限元的bound涌过来证明了approximation theory
Relu deep neural networks and linear finite elements arXiv preprint arXiv:1807.03973,
@赵拓
老师有很有趣的工作 把approximation放到了manifold 上函数
大家感兴趣可以看看
Efficient approximation of deep relu networks for functions on low dimensional manifolds Neurips2019
最后为neural ode打一个广告
这个用neural ode可以转换成一个controllable的问题 也可以证明
- arXiv:1912.10382
 [pdf, ps, other]
[pdf, ps, other] - Deep Learning via Dynamical Systems: An Approximation Perspective
- Authors: Qianxiao Li, Ting Lin, Zuowei Shen
【很有趣 但我也不知道有啥好处 去问作者吧
但是我还不知道存在一个空间
NN可以逼近 传统的wavelet或者别的方法不能逼近的………

若有收获,就点个赞吧
0 人点赞
