学习链接:
https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
https://www.bilibili.com/video/BV1Wv411h7kN?p=7
例子描述:
Author: Heng-Jui Chang
Slides: https://github.com/ga642381/ML2021-Spring/blob/main/HW01/HW01.pdf
Video: TBA
Objectives:
- Solve a regression problem with deep neural networks (DNN).
- Understand basic DNN training tips.
- Get familiar with PyTorch.
If any questions, please contact the TAs via TA hours, NTU COOL, or email.
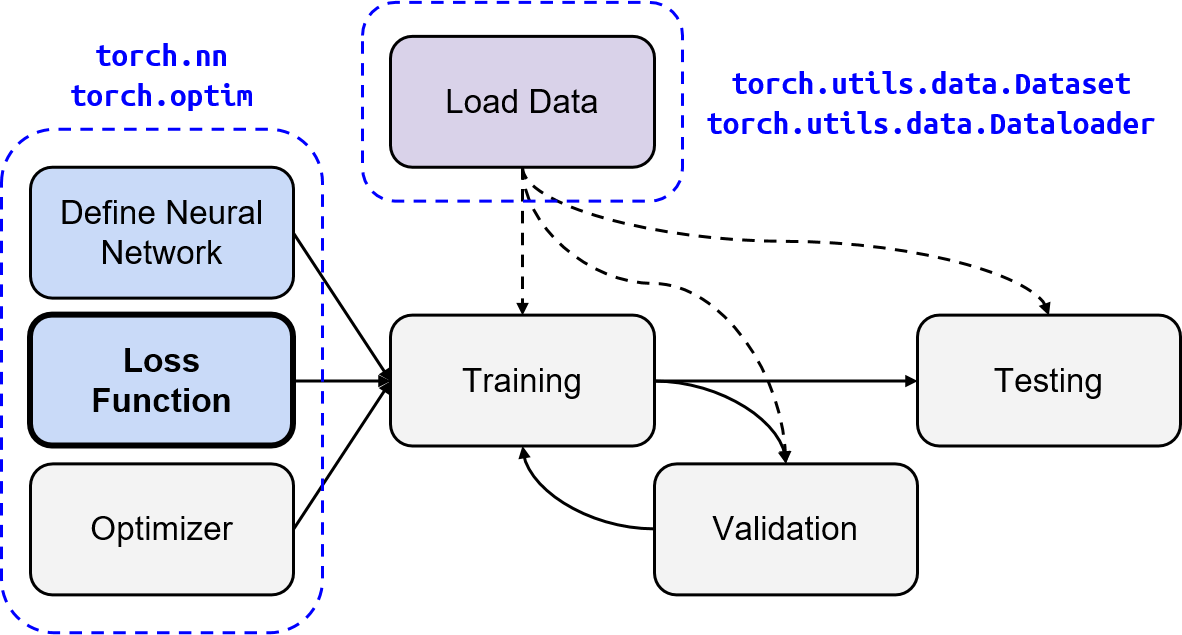
Preprocess
We have three kinds of datasets:
train: for trainingdev: for validationtest: for testing (w/o target value)
Dataset
The COVID19Dataset below does:
- read
.csvfiles - extract features
- split
covid.train.csvinto train/dev sets - normalize features
Finishing TODO below might make you pass medium baseline.
0.设置seed
myseed = 42069 # set a random seed for reproducibilitytorch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falsenp.random.seed(myseed)torch.manual_seed(myseed)if torch.cuda.is_available():torch.cuda.manual_seed_all(myseed)
1.载入数据
tr_path = 'covid.train.csv' # path to training datatt_path = 'covid.test.csv' # path to testing data
2.处理数据
输入参数:
init(self,path,mode =’train’,target_only = ‘False’):
处理流程:
- read .csv files
- extract features
- split covid.train.csv into train/dev sets
- normalize features
- Generates a dataset, then is put into a dataloader.
要点:
- 注意数据规范化,减均值除方差即可;
- 训练时划分训练和测试集;
- train的时候需要shuffle,测试的时候不需要(保证测试结果可复现);
- dataloader相当于一个“字典”,包括数据集合一些参数;
```python
PyTorch
import torch from torch.utils.data import Dataset, DataLoader
For data preprocess
import numpy as np import csv
class COVID19Dataset(Dataset): ‘’’ read .csv files extract features split covid.train.csv into train/dev sets normalize features ‘’’ ‘’’ Dataset for loading and preprocessing the COVID19 dataset ‘’’ def init(self,path,mode =’train’,target_only = ‘False’): self.mode =mode
with open(path,'r') as fp:data = list(csv.reader(fp))data = np.array(data[1:])[:,1:].astype(float)'''data.shape = 2700*94'''if not target_only:feats = list(range(93))else:# TODO: Using 40 states & 2 tested_positive features (indices = 57 & 75)passif mode =='test':# Testing data# data: 893 x 93 (40 states + day 1 (18) + day 2 (18) + day 3 (17))data = data[:,feats]self.data = torch.FloatTensor(data)else:# Training data (train/dev sets)# data: 2700 x 94 (40 states + day 1 (18) + day 2 (18) + day 3 (18))target = data[:,-1]data = data[:,feats]# Splitting training data into train & dev setsif mode == 'train':indices = [i for i in range(len(data)) if i % 10 != 0]elif mode == 'dev':indices = [i for i in range(len(data)) if i % 10 == 0]# Convert data into PyTorch tensorsself.data = torch.FloatTensor(data[indices])self.target = torch.FloatTensor(target[indices])# Normalize features (you may remove this part to see what will happen)self.data[:,40:] = \(self.data[:, 40:] - self.data[:, 40:].mean(dim=0, keepdim=True)) \/ self.data[:, 40:].std(dim=0, keepdim=True)self.dim = self.data.shape[1]print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'.format(mode, len(self.data), self.dim))def __getitem__(self, index):# Returns one sample at a timeif self.mode in ['train', 'dev']:# For trainingreturn self.data[index], self.target[index]else:# For testing (no target)return self.data[index]def __len__(self):# Returns the size of the datasetreturn len(self.data)
def prep_dataloader(path, mode, batch_size, n_jobs=0, target_only=False): ‘’’ Generates a dataset, then is put into a dataloader. ‘’’ dataset = COVID19Dataset(path, mode=mode, target_only=target_only) # Construct dataset dataloader = DataLoader( dataset, batch_size, shuffle=(mode == ‘train’), drop_last=False, num_workers=n_jobs, pin_memory=True) # Construct dataloader return dataloader
<a name="OXhl4"></a>## 3.建立模型<a name="T9gb9"></a>### 输入参数:input_dim<a name="WPeII"></a>### 网络层:在init中定义网络层;<a name="LJ8Kb"></a>### Loss在init中定义loss;<a name="xhwAn"></a>### forward矩阵相乘<a name="hIyy5"></a>### 注意事项:- BatchNorm1d可以省略正则化和dropout```python# PyTorchimport torch.nn as nnclass NeuralNet(nn.Module):''' A simple fully-connected deep neural network '''def __init__(self, input_dim):super(NeuralNet, self).__init__()self.net = nn.Sequential(nn.Linear(input_dim, 128),nn.BatchNorm1d(128),nn.ReLU(),nn.Linear(128, 256),nn.BatchNorm1d(256),nn.ReLU(),nn.Linear(256, 512),nn.BatchNorm1d(512),nn.ReLU(),nn.Linear(512, 256),nn.BatchNorm1d(256),nn.ReLU(),nn.Linear(256, 128),nn.BatchNorm1d(128),nn.ReLU(),nn.Linear(128, 64),nn.BatchNorm1d(64),nn.ReLU(),nn.Linear(64, 1),)# Mean squared error lossself.criterion = nn.MSELoss(reduction='mean')def forward(self, x):''' Given input of size (batch_size x input_dim), compute output of the network '''# print(np.shape(self.net(x))) #[270*1]# print(self.net(x))# print(np.shape(self.net(x).squeeze(1)))# print(self.net(x).squeeze(1))#[270]return self.net(x).squeeze(1)def cal_loss(self, pred, target):''' Calculate loss '''# TODO: you may implement L2 regularization herereturn self.criterion(pred, target)
4.训练并保存参数
训练的一些参数,可以用args
config = {'n_epochs': 3000, # maximum number of epochs'batch_size': 270, # mini-batch size for dataloader'optimizer': 'SGD', # optimization algorithm (optimizer in torch.optim)'optim_hparas': { # hyper-parameters for the optimizer (depends on which optimizer you are using)'lr': 0.001, # learning rate of SGD'momentum': 0.9 # momentum for SGD},'early_stop': 200, # early stopping epochs (the number epochs since your model's last improvement)'save_path': 'models/model.pth' # your model will be saved here}
设置优化器
开始训练
def train(tr_set, dv_set, model, config, device):''' DNN training '''n_epochs = config['n_epochs'] # Maximum number of epochs# Setup optimizeroptimizer = getattr(torch.optim, config['optimizer'])(model.parameters(), **config['optim_hparas'])min_mse = 1000.loss_record = {'train': [], 'dev': []} # for recording training lossearly_stop_cnt = 0epoch = 0while epoch < n_epochs:model.train() # set model to training modefor x, y in tr_set: # iterate through the dataloaderoptimizer.zero_grad() # set gradient to zerox, y = x.to(device), y.to(device) # move data to device (cpu/cuda)pred = model(x) # forward pass (compute output)mse_loss = model.cal_loss(pred, y) # compute lossmse_loss.backward() # compute gradient (backpropagation)optimizer.step() # update model with optimizerloss_record['train'].append(mse_loss.detach().cpu().item())# After each epoch, test your model on the validation (development) set.dev_mse = dev(dv_set, model, device)if dev_mse < min_mse:# Save model if your model improvedmin_mse = dev_mseprint('Saving model (epoch = {:4d}, loss = {:.4f})'.format(epoch + 1, min_mse))torch.save(model.state_dict(), config['save_path']) # Save model to specified pathearly_stop_cnt = 0else:early_stop_cnt += 1epoch += 1loss_record['dev'].append(dev_mse)if early_stop_cnt > config['early_stop']:# Stop training if your model stops improving for "config['early_stop']" epochs.breakprint('Finished training after {} epochs'.format(epoch))return min_mse, loss_record
验证并保存模型
covid-19.zip

若有收获,就点个赞吧
0 人点赞
