简介
交叉验证(Cross-validation)用于建模时,不同种类模型的横向比较。
交叉验证是一种分割数据的方法,涉及到训练集(train set),评估集(valid set),测试集(test set)
从训练集和测试集开始说起
我们希望 generalization error(也就是 test error) 很低。所以需要在训练集上分出 test set 来测试性能,以评估泛化能力。
大多数机器学习算法都有超参数,原因是:
- 太难优化了。
- 不适合在训练集上学习,例如正则化的参数总是会被优化为0,因为这时在训练集上的拟合最好。
所以需要有个训练算法观测不到的 validation set
最常用的80/20法
数据集中,选取80%作为train set,剩下20%作为test set
原因
原理
用train set来训练模型,用test set来验证训练的模型是否能够预测新问题。如果test set预测能力优秀,那么有理由相信模型对未来的数据预测能力也会优秀。
假设
- 未知数据的内部特征,与train set,test set相似。
-
做法
train set 80%
test set 20% train set效果良好,test set 效果良好
这是我们追求的- train set 效果良好,test set 效果不好
有可能过拟合了 - train set 效果不好,test set 效果良好
这种情况不常见。要具体分析。
例如,考虑集合划分是否有问题。train set 中的样本太相似,信息量不高。train set 中有离群值。
例如100人,90男,10女。(或者肿瘤案例,肿瘤本就少)
用train set,可能全部抽出男
按照分层抽样,而不是简单随机抽样。保证每个样本都抽到。
验证集
有时,除了训练集和测试集,还有个验证集的概念。
验证集用于调整模型参数,防止模型过拟合
valid set 20%
train set 60%
test set 20%
缺点
- 如果数据做了train set,就不能做 test set了,浪费了20%的数据
- 有可能某一条数据包含信息很多,但被划分到了test set
举例来说,做有监督学习时,某数据集100条数据,y值90条是1,10条是0,那么有可能10条全部进入test set,当然不能得出正确结果。
解决方法:
- 每类数据做80/20, 这在SVM的一个案例中有用到
-
留1法
假设有n条数据,那么:
step1:选取n-1条作为train set,剩下1条作为test set
step2:做n次模型,这样可以保证每个数据都作为test set和train set
缺点: 虽然保证每个数据都作为test set和train set,但是需要运行n次模型,当n较大时,计算量几乎无法实现。
K折交叉验证
step1:把data set 分为5份:1,2,3,4,5
step2:每份分别作为test set,运行5次模型
(这个也叫5倍交叉验证法)
一个数据集一共有1,2,3三个部分,以model0为初始化参数 第一波迭代:model0为初始化参数,1,2做训练集,3做测试集,得到参数模型model1,测试精度为pres1; 第二波迭代:model1为初始化参数,2,3做训练集,1做测试集,得到参数模型model2,测试精度为pres2; 第三波迭代:model2为初始化参数,3,1做训练集,2做测试集,得到参数模型model3,测试精度为pres3; 最终的测试结果为(pres1+pres2+pres3)/3
K折交叉验证图: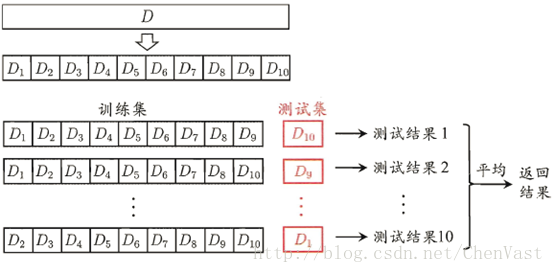

结果判断
留1法有n个模型,n个结果。5倍交叉验证有5个模型5个结果。
step1:多种模型横向比较时,取误差平均值。看哪个模型的平均误差小
step2:选定模型后,在5个模型中选一个误差最小的
理论上,5倍交叉验证法的误差均值,一般比80/20法大很多。
代码实现
80/20法
from sklearn import model_selectiontrain_data,test_data,train_target,test_target=model_selection.train_test_split(data,target,test_size=0.2,train_size=0.8,random_state=12345)#划分训练集和测试集
留1法
交叉验证
lr = linear_model.LogisticRegression()lr_scores = cross_validation.cross_val_score(lr, train_data, train_target, cv=5)#cv=5:5倍交叉验证print("logistic regression accuracy:")print(lr_scores)clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=8, min_samples_split=5)clf_scores = cross_validation.cross_val_score(clf, train_data, train_target, cv=5)print("decision tree accuracy:")print(clf_scores)svc_scores = cross_validation.cross_val_score(svc, train_data, train_target, cv=5)print("svm classifier accuracy:")print(svc_scores)abc_scores = cross_validation.cross_val_score(abc, train_data, train_target, cv=5)print("abc classifier accuracy:")print(abc_scores)rfc_scores = cross_validation.cross_val_score(rfc, train_data, train_target, cv=5)print("random forest accuracy:")print(rfc_scores)
输出:
logistic regression accuracy:[ 0.67142857 0.66607143 0.6625 0.65357143 0.65119048]decision tree accuracy:[ 0.73809524 0.75654762 0.74047619 0.73214286 0.7375 ]svm classifier accuracy:[ 0.50297619 0.50595238 0.50654762 0.50297619 0.50297619]abc classifier accuracy:[ 0.76190476 0.76488095 0.76785714 0.75238095 0.75 ]random forest accuracy:[ 0.7202381 0.73035714 0.70714286 0.71488095 0.70416667]

若有收获,就点个赞吧
0 人点赞
