MyBatis相关概念回顾
本质就是对JDBC底层代码的封装。使用mybatis一般是两种方式,一种是XML,一种是注解。
ORM:关系-对象映射,操作实体类就相当于操作表


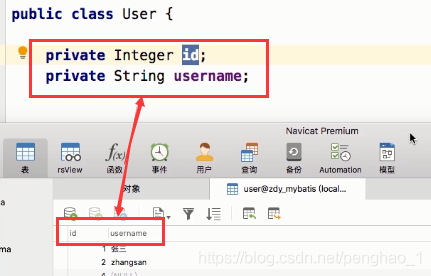
虽然是底层用到了反射,但是真正的原因是,当我们编写User实体的时候,要保证实体的字段名要和数据库的字段名要保持一致。他们保持一致后,执行完sql,拿到sql查询结果之后,则会根据id字段名,去找到User实体中,id这个属性。然后把查询的值赋过去,以此类推。(User实体的字段名和User表的字段名保持一致,就是一种映射关系,底层也是基于这种映射关系来完成结果集的封装)
注:个人理解: 根据底层源码而知,前提是属性名和字段名保持一致,当sql执行后得到结果集返回,就会对结果集进行遍历(也就是预处理对象集合进行遍历),遍历出每一个预处理对象对应的属性名和value值,因为字段名和属性名是一致的,那么此时就可以通过反射技术:根据返回值类型,查询出的字段名,通过反射里面的getDec。。。先得到字段的属性对象,开启对属性的暴力访问,然后对属性进行赋值,并封装到返回类型的对象中。

半自动:在mybatis中还需要手动编写sql,这样可以能够对sql一步优化。优化后的sql执行效率更高
轻量级:框架在启动的过程中,需要的资源比较少。
优势:MyBatis是一个半自动化的持久化层框架。对开发人员而言, 核心sql还是需要自己优化, sql和java编码分开,功能边界清晰,一个专注业务、一个专注数据。
MyBatis开发步骤:
①添加MyBatis的坐标,引入依赖
②创建user数据表
③编写User实体类(要和表的字段属性要对应)
④编写映射文件UserMapper.xml(在工程的resource文件夹下)
⑤编写核心文件SqlMapConfig.xml
⑥编写测试类
1、新建一个maven项目。

2、添加jar依赖
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.encoding>UTF-8</maven.compiler.encoding><java.version>1.8</java.version><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target></properties><!--引入依赖--><dependencies><!--mybatis坐标--><dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.4.5</version></dependency><!--mysql驱动坐标--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.6</version><scope>runtime</scope></dependency><!--单元测试坐标--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><!--⽇志坐标--><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.12</version></dependency></dependencies>
3、添加一个实体类,创建一个与实体类字段一样的表。
(因为只有当字段和属性名一致时,底层才可以通过反射给属性进行一一对应的映射赋值封装)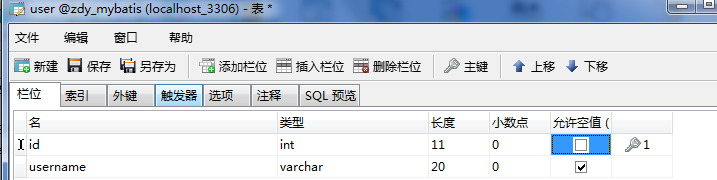



4、添加sql的映射文件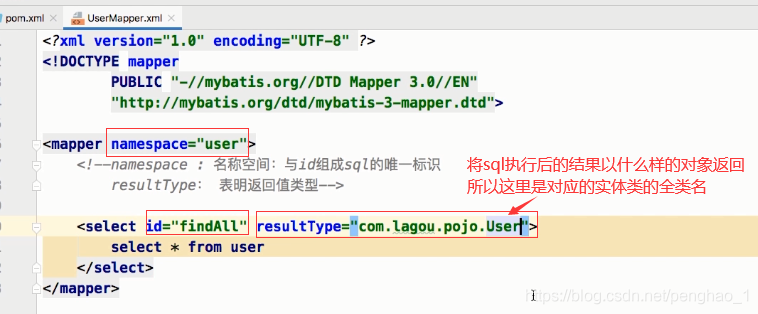

5、添加数据库的映射文件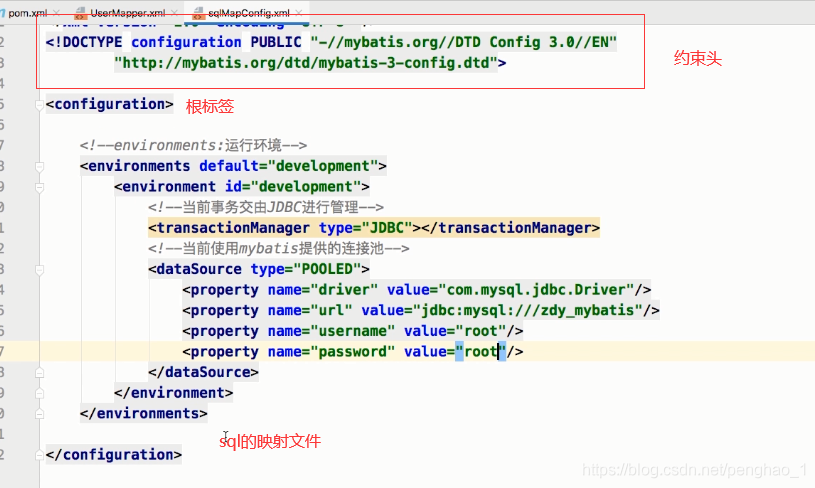

到此,已经完成了1-5,接下来就是第6步。
6、编写测试类。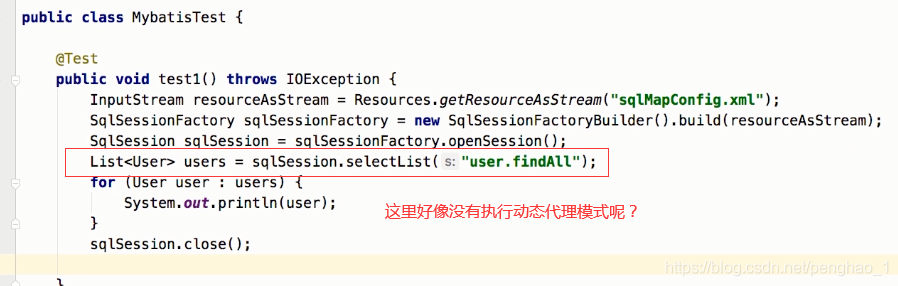


到此,入门案例已经OK。
MyBatis的CRUD回顾
对于mybatis的增删改查都是写在配置文件中的,下面是具体配置的过程
1、要有约束头
2、要有mapper标签
3、要有执行语句的标签 (标签里面有id,参数类型,返回类型,sql语句)
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><!--namespace : 名称空间:与id组成sql的唯一标识resultType: 表明返回值类型--><mapper namespace="user"><!---查询用户--><select id="findAll" resultType="com.shanglin.pojo.User" >select * from User</select><!--添加用户--><!--parameterType:参数类型(添加操作,那么里面要填什么值,需要传递参数过来) 传递过来的参数就是一个user对象那么#{}里面的值,应该与传递过来的类的属性名保持一致,这样就可用其属性的get方法取到值--><insert id="saveUser" parameterType="com.shanglin.pojo.User" >insert into user values(#{id},#{username})</insert><!--修改 需要参数的 获取到相应的属性值给占位符赋值--><update id="updateUser" parameterType="com.shanglin.pojo.User">update user set username = #{username} where id = #{id}</update><!--删除需要参数的 因为删除只需要传递一个id,所以只要添加一个相应的类型如果参数类型是基本数据类型,或者是基本数据类型的包装类,且只是一个的时候,#{}内的值随便写的--><delete id="deleteUser" parameterType="java.lang.Integer">delete from user where id = #{abc}</delete></mapper>
 4、编写测试类
4、编写测试类
@Test
public void test() throws Exception {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = build.openSession();
// 1、查询操作
List<User> objects = sqlSession.selectList("user.findAll");
// 设置实体对象传递的参数
User user = new User();
user.setId(3);
user.setUsername("tom");
// 2、增加
sqlSession.insert("user.saveUser",user);
// 3、修改
sqlSession.update("user.updateUser",user);
// 4、删除 只传id
sqlSession.update("user.deleteUser",3);
// 需要调用提交事物,否则不会入库
sqlSession.commit();
sqlSession.close();
}

映射配置文件分析


核心配置文件分析




//1.Resources工具类,配置文件的加载,把配置文件加载成字节输入流
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
//2.解析了配置文件,并创建了sqlSessionFactory工厂(工厂的作用是生产SqlSession)
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(resourceAsStream);
//3.生产sqlSession
// openSession是默认开启一个事务,但是该事务不会自动提交
//在进行增删改操作时,要手动提交事务
SqlSession sqlSession = build.openSession();
// 在sqlSession会话对象中封装了与数据库交互的方法。
//4.sqlSession调用方法:查询所有selectList 查询单个:selectOne 添加:insert 修改:update 删除:delete
List<User> objects = sqlSession.selectList("user.findAll");
// 如果改为自动提交,则在openSession();里面添加一个true

Mybatis中Dao层的实现(代理模式)
使用代理开发方式。因为这种方式只需要在持久层添加接口就可以,不需要像传统那样添加实现类
它的原理是在执行过程中,对接口使用JDK动态代理,产生一个代理对象,由这个代理对象去执行操作
但是使用代理对象时,
必须准守以下规范


具体用法
1、namespace必须是方法所在接口的全限定类名
2、id必须和方法名保持一致
3、返回类型、参数类型,是最终要分装到哪个类是全限定类名
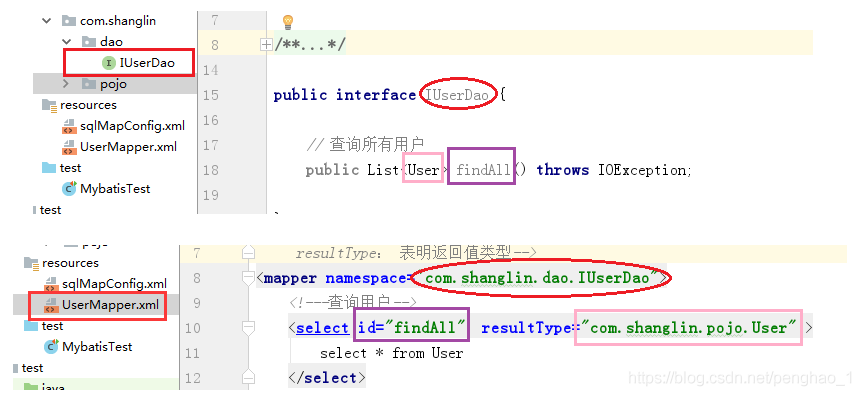

代理模式getMapper
只需要传递接口,然后通过代理对象调用接口方法
注意:如果不用代理对象,用其他的,则需要填写全路径,eg:如下


如果使用代理模式,就需要调用getMapper方法,获取动态代理对象,通过动态代理对象去调用要操作的方法。
//使用代理模式的时候,一定要namespace的名字和接口的路径名一致。否则找不到接口
@Test
public void test05() throws Exception {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = build.openSession();
// 通过getMapper去获取代理对象
IUserDao mapper = sqlSession.getMapper(IUserDao.class);
// 通过代理对象去调用接口的方法
List<User> all = mapper.findAll();
for (User user : all) {
System.out.println(user);
}
sqlSession.close();
}

Mybatis配置文件的深入
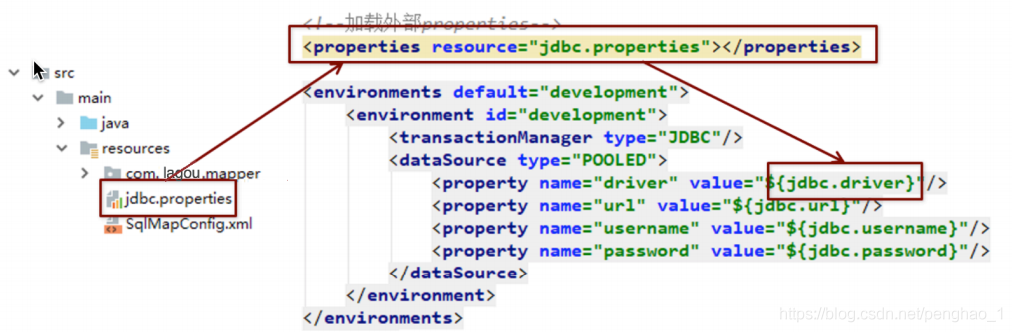
1、properties的配置文件使用
将数据源的配置信息单独的抽取成一个properties文件,然后将这个配置文件加载进到映射文件中进行引用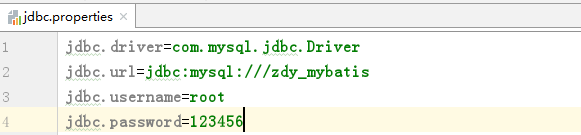


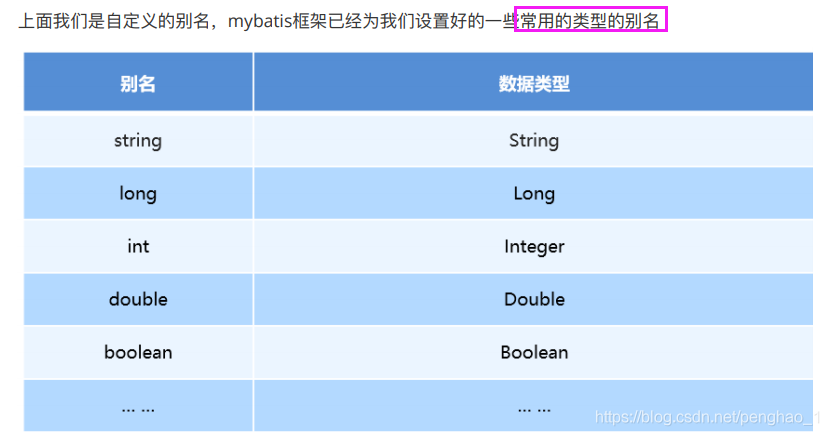
2、typeAliases标签的别名使用
a、单个的别名使用(typeAlias)
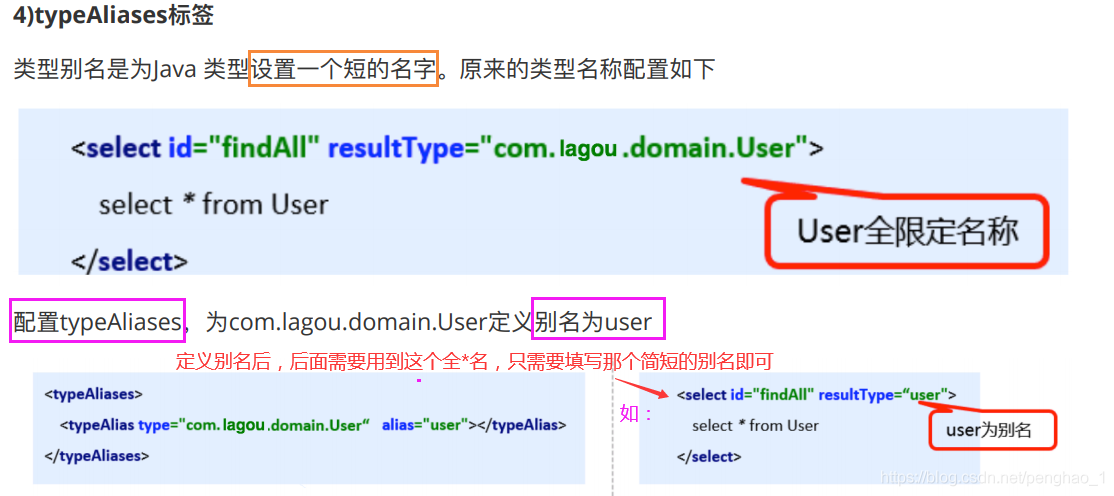

b、批量的别名使用(package)
批量就直接写实体类的包名即可,因为实体类都在一个包下,而且它不区分大小写嘛。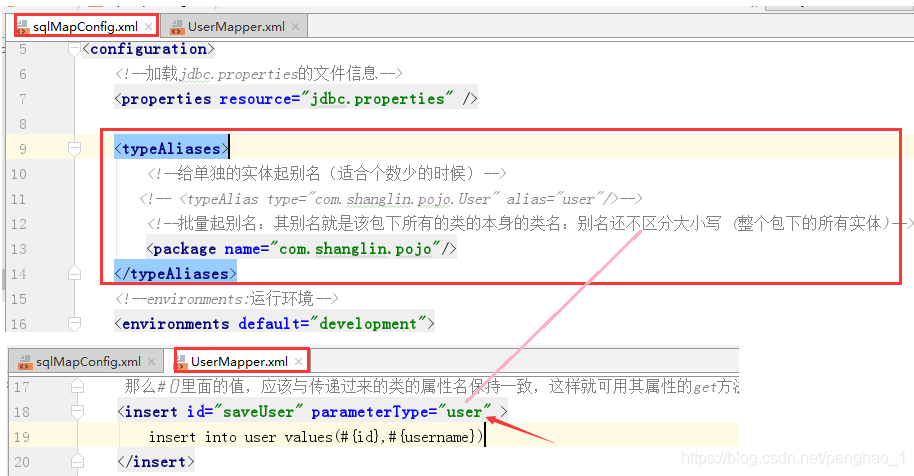




Mapper.xml的sql配置
根据实体类的不同取值, 使用不同的SQL语句来进行查询,SQL是动态变化的。
if条件一般是用于多条件组合查询中,一般先判读是否为空,若不为空则拼接下去

1、动态sql——if标签的使用
UserMapper.xml文件中。一定把参数的名字写对咯,不然报错就的debug源码了。
<!--多条件组合查询:演示if-->
<select id="findByCondition" parameterType="user" resultType="user">
select * from User
<where> <!--会自动拼接where,并去掉第一个and-->
<if test="id !=null">
and id = #{id}
</if>
<if test="username !=null">
and username = #{username}
</if>
</where>
</select>
2、动态sql——foreach标签的使用
<!--多值查询:演示foreach-->
<select id="findByIds" parameterType="list" resultType="user">
<!--如: select * from user where id in (id,id)-->
select * from user
<where>
<!--传过来是数组用array,是集合用List;open是where条件拼接的开始字段;item传递过来的数组正在遍历的值
用,进行分割-->
<foreach collection="array" open="id in (" close=")" item="id" separator=",">
#{id}
</foreach>
</where>
</select>

foreach测试代码(采用动态代理模式)
@Test
public void test07() throws Exception {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = build.openSession();
// 通过getMapper去获取代理对象
IUserDao mapper = sqlSession.getMapper(IUserDao.class);
int[] arr ={1,2};
// 通过代理对象去调用接口的方法
List<User> all = mapper.findByIds(arr);
for (User user : all) {
System.out.println(user);
}
sqlSession.close();
}
3、将共用的sql进行抽取出来(抽取sql)
将共用的sql抽取出来,给一个id标识。后续有用到这个sql查询的地方,直接引入id标识即可。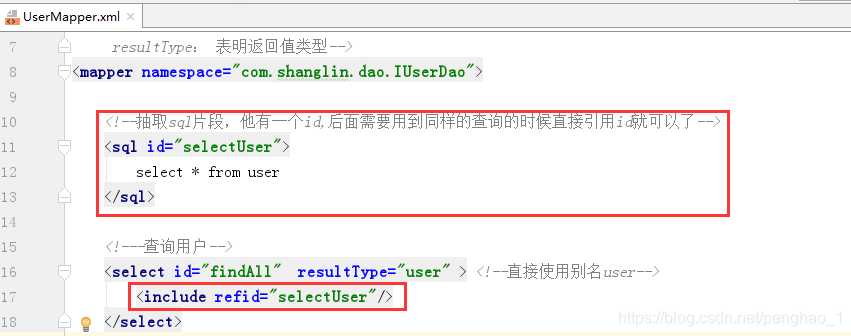

Mybatis复杂的映射开发
1、一对一查询
a、先创建一个user、order表,一个订单只属于一个用户


b、然后创建一个项目(进行多表操作)

c、然后和之前的项目一样,添加依赖。
d、然后创建User,Order实体类(实体类的属性要和表的字段对应 )
e、然后添加数据库的配置文件SqlMapConfig.xml
需要注意的地方: 1、使用的是mapper这个标签**(不用同包同名,只要放到resource包下就可以)**<br /> 2、使用的是package这个标签,也就是会加重包下的所有接口。那么就**需要将映射文件 要保**<br />** 持和接口所在的包必须同包同名**。就如下图的com.shanglin.mapper<br />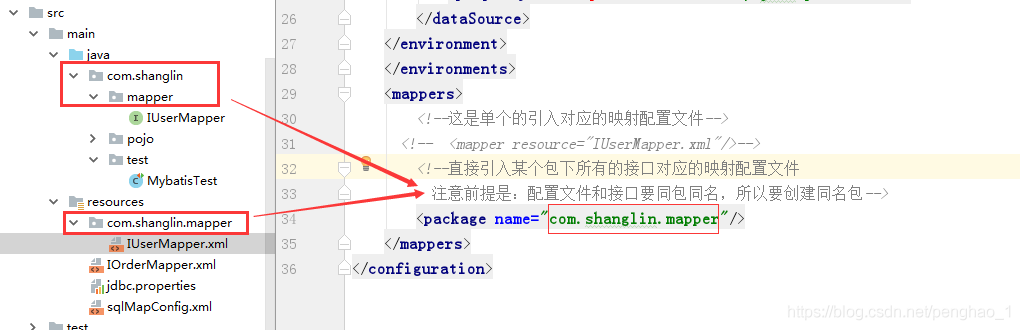
具体的配置文件
<!--根标签-->
<configuration>
<!--加载jdbc.properties的文件信息-->
<properties resource="jdbc.properties" />
<typeAliases>
<!--给单独的实体起别名(适合个数少的时候)-->
<!-- <typeAlias type="com.shanglin.pojo.User" alias="user"/>-->
<!--批量起别名:其别名就是该包下所有的类的本身的类名:别名还不区分大小写 (整个包下的所有实体)-->
<package name="com.shanglin.pojo"/>
</typeAliases>
<!--environments:运行环境-->
<environments default="development">
<environment id="development">
<!--当前失误交由JDBCj进行管理-->
<transactionManager type="JDBC"/>
<!--当前使用mybatis提供的连接池-->
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--这是单个的引入对应的映射配置文件-->
<!-- <mapper resource="IUserMapper.xml"/>-->
<!--直接引入某个包下所有的接口对应的映射配置文件
注意前提是:配置文件和接口要同包同名,所以要创建同名包-->
<package name="com.shanglin.mapper"/>
<!--如果是用注解的话,也是需要添加映射的。就是接口的全路径名。
但是如果是多个的时候,批量的,那还是要上面的导包形式-->
<!--<mapper class="com.shanglin.mapper.IUserMapper"/>-->
</mappers>
</configuration>

f、然后编写对应的接口,与映射配置文件来实现一对一查询


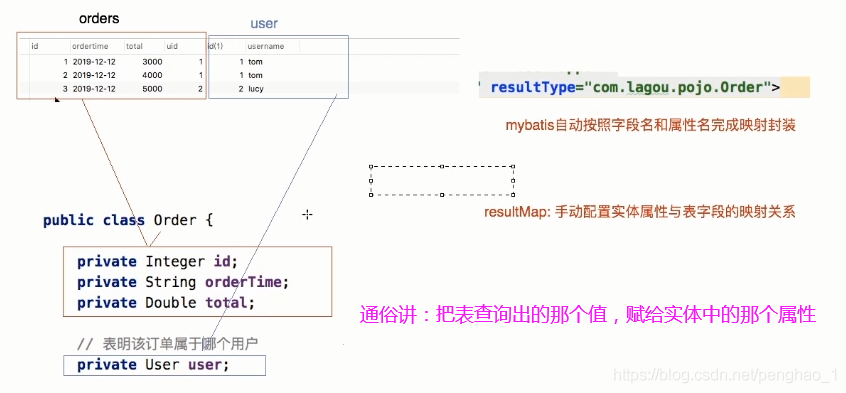

这样就可以将查询出user的字段这部分,赋给order的user属性上。
按上面的逻辑,使用resultType只能反射获对Order的属性进行封装,获取不能对user的属性进行封装。
所以resultType是不能满足现状的需求,需要改用resultMap来完成。(它可以手动配置封装逻辑)
g、resultMap、association等标签的使用(封装对象)
手动来配置实体属性与表字段的映射关系,的映射配置文件IOrderMapper.xml
//...约束头
<mapper namespace="com.shanglin.mapper.IOrderMapper">
<cache></cache>
<!--手动来配置实体属性与表字段的映射关系,它的id属性就是标识,后面直接用其标识即可
type: 表示当前需要封装到哪个实体对象当中 (当前需要封装到Order中)-->
<resultMap id="orderMap" type="com.shanglin.pojo.Order">
<!--这里配置的是Order这个属性,与sql查询出来的结果的映射关系
property是实体类的属性名,column是数据库表的元素名 -->
<result property="id" column="id"></result>
<result property="orderTime" column="orderTime"></result>
<result property="total" column="total"></result>
<!--如何把查询出的user信息配置到Order中的user属性中呢?
首先:user是Order类中的其中一个属性名,表示用来配置Order中user这个属性了
javaType来表示当前配置这个属性是什么类型,这里是User实体类-->
<association property="user" javaType="com.shanglin.pojo.User">
<!--uid,username是用sql查询出的结果的字段,前面是属性的字段-->
<result property="id" column="uid"></result>
<result property="username" column="username"></result>
</association>
</resultMap>
<!--这个查询结果,是按照上面id=orderMap的映射关系进行封装,因为调用了上面的标识userMap-->
<select id="findOrderAndUser" resultMap="orderMap">
select * from orders o,user u where o.uid=u.id
</select>
</mapper>

2、一对多查询
从用户的角度出发就是一对多(一个用户可以具有多个订单)
一对多的需求:查询所有用户,与此同时查询出该用户所具有的订单信息
那么不能用内连接了,需要用左外或者右外
a、一个用户可以有多个订单,订单用List装起来。


b、创建接口
public interface IUserMapper {
public List<TwoUser> findAll();
}
c、resultMap、collection标签的使用(封装集合)
一对多的配置文件
<mapper namespace="com.shanglin.mapper.IUserMapper">
<cache></cache>
<!--这里面是一对多的-->
<!--手动来配置实体属性与表字段的映射关系,它的id属性就是标识,后面直接用其标识即可
type: 表示当前需要封装到哪个实体对象当中 (当前需要封装到TwoUser中)-->
<resultMap id="userMap" type="com.shanglin.pojo.TwoUser">
<result property="id" column="uid"></result>
<result property="username" column="username"></result>
<!--这里对应的是多方,多方要用collection
property:是实体TwoUser中集合的名称orderList,
ofType:表示当前集合泛型的一个全路径,表示将查询结果封装成一个个的全路径里面的对象
(也就是封装成一个个TwoOrder对象)-->
<collection property="orderList" ofType="com.shanglin.pojo.TwoOrder">
<!--uid,username是用sql查询出的结果的字段,前面是属性的字段-->
<result property="id" column="id"></result>
<result property="orderTime" column="orderTime"></result>
<result property="total" column="total"></result>
</collection>
</resultMap>
<!--这个查询,是按照上面的映射关系进行封装,因为调用了上面的标识id=userMap-->
<select id="findAll" resultMap="userMap">
select * from user u left join orders o on u.id = o.uid
</select>
</mapper>
d、测试代码
@Test
public void test02() throws Exception {
InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");
SqlSessionFactory build = new SqlSessionFactoryBuilder().build(resourceAsStream);
SqlSession sqlSession = build.openSession();
IUserMapper mapper = sqlSession.getMapper(IUserMapper.class);
List<TwoUser> all = mapper.findAll();
for (TwoUser twoUser : all) {
System.out.println(twoUser);
}
}
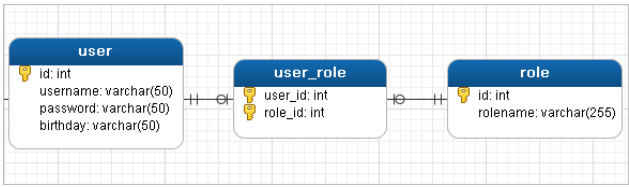
3、多对多查询
多对多表示一个用户可以有多个角色,一个角色可以被多个用户使用
所以用户和角色是多对多的关系(多对多其实就是两个一对多)
a、多对多的查询模型

b、创建实体类
一个用户可以有多个角色,所以角色就用roleList来装

c、创建接口


d、多对多的配置文件
<mapper namespace="com.shanglin.mapper.IUserMapper">
<cache></cache>
<!--这里面是多对多的-->
<resultMap id="userRoleMap" type="com.shanglin.pojo.ThreeUser">
<result property="id" column="userid"></result>
<result property="username" column="username"></result>
<!--这里对应的是ThreeUser下面的Role实体对应的集合。roleList就是集合的名字-->
<collection property="roleList" ofType="com.shanglin.pojo.Role">
<result property="id" column="roleid"></result>
<result property="roleName" column="roleName"></result>
<result property="roleDesc" column="roleDesc"></result>
</collection>
</resultMap>
<!-- 查询所有用户的同时查询出每一个用户所属角色-->
<select id="findAllUserAndRole" resultMap="userRoleMap">
select * from user u left join sys_user_role ur on u.id = ur.userid
left join sys_role r on r.id = ur.roleid
</select>
</mapper>

Mybatis的注解开发
1、常用的注解
@Insert:实现新增
@Update:实现更新
@Delete:实现删除
@Select:实现查询
@Result:实现结果集封装
@Results:可以与@Result一起使用, 封装多个结果集
@One:实现一对一结果集封装
@Many:实现一对多结果集封装
2、用注解进行CRUD操作
a、在接口中添加注解
//添加用户 #{}里面的值要和实体中的属性一致,才可以通过get拿到值
@Insert("insert into user values(#{id},#{username})")
public void addUser(User user);
//更新用户
@Update("update user set username = #{username} where id = #{id}")
public void updateUser(User user);
//查询用户
@Select("select * from user")
public List<User> selectUser();
//删除用户
@Delete("delete from user where id = #{id}")
public void deleteUser(Integer id);
b、动态代理来调用方法进行测试
其他的测试代码以此类推
@Test
public void test04(){
IUserMapper mapper = sqlSession.getMapper(IUserMapper.class);
User user = new User();
user.setId(4);
user.setUsername("测试数据");
mapper.addUser(user);
sqlSession.commit();
}
c、注解的加载与配置文件加载的异同
sql的核心配置文件中,如果是配置文件,用到resource,或者加载执行方法所在包的全路径
如果是注解,用到class,或者加载执行方法所在包的全路径。如下所示:
<!--直接引入某个包下所有的接口对应的映射配置文件
注意前提是:配置文件和接口要同包同名,所以要创建同名包-->
<package name="com.shanglin.mapper"/>
<!--如果是用注解的话,也是需要添加映射的。就是接口的全路径名。
但是如果是多个的时候,批量的,那还是要上面的导包形式-->
<!--<mapper class="com.shanglin.mapper.IUserMapper"/>-->
3、用注解进行复杂映射开发
注解开发也是需要添加映射的,值不过直接添加其注解接口下的包名即可
先看一下配置文件,如同在配置文件的基础上进行转换为注解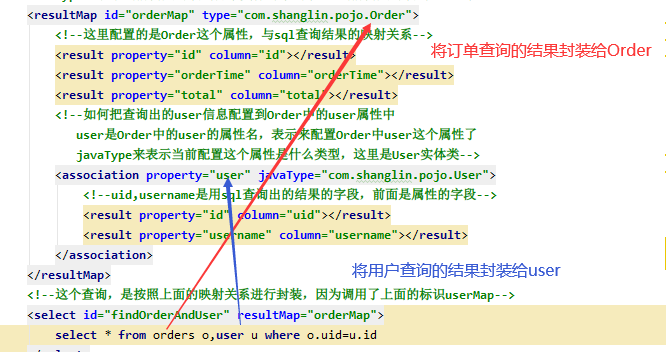

resultMap可用@Results替换
result可用@Result替换
association可用@one替换。
collection可用@Many替换

4、一对一的注解

如何用@one进行封装单个对象
public interface IOrderMapper {
// 查询订单的同时,还需查询订单所属的用户
// 先查询出订单的uid,然后再发起查询,查询订单关联的用户
//javaType表示Order实体中 user这个类型是什么
@Results({
@Result(property = "id",column = "id"),
@Result(property = "orderTime",column = "orderTime"),
@Result(property = "total",column = "total"),
@Result(property = "user",column = "uid",javaType = User.class,
// 这个sql是根据当前查询结果uid的值,再次查询下面那个订单关联的用户
// one这个是对一方的查询。select里面就是一个namespace.id=>接口全路径.方法名
one=@One(select = "com.shanglin.mapper.IUserMapper.findUserById"))
})
@Select("select * from orders") // 先执行这条查询
public List<Order> findOrderAndUser();
}

public interface IUserMapper {
//根据id查询用户
@Options(useCache = true)
@Select({"select * from user where id = #{id}"})
public User findUserById(Integer id);
}
调用方法测试
@Test
public void ontToOne(){
IOrderMapper mapper = sqlSession.getMapper(IOrderMapper.class);
List<Order> orderAndUser = mapper.findOrderAndUser();
for (Order order : orderAndUser) {
System.out.println(order);
}
}

5、一对多的注解
a、定义好实体类
一个用户多个订单,那么就需要在user实体类中,添加List

b、如何使用many进行封装集合
public interface IUserMapper
// 查询所有用户,同时查询每个用户关联的订单信息(一对多)
@Select("select * from user")
@Results({
@Result(property = "id",column = "id"),
@Result(property = "username",column = "username"),
// 第三个property是从user实体中,找到Order集合的属性名orderList
// javaType指明当前property属性的类型,当前是list集合类型的
@Result(property = "orderList",column = "id",javaType = List.class,
// 这个list是一对多的,是根据用户的id进行查询
many=@Many(select = "com.shanglin.mapper.IOrderMapper.findOrderByUid"))
})
public List<TwoUser> findAll();
}

public interface IOrderMapper {
@Select("select * from orders where uid = #{uid}")
public List<Order> findOrderByUid(Integer uid);
}
c、测试
@Test
public void ontToMany(){
IUserMapper mapper = sqlSession.getMapper(IUserMapper.class);
List<TwoUser> all = mapper.findAll();
for (TwoUser twoUser : all) {
System.out.println(twoUser);
}
}

6、多对多的注解开发
a、创建实体类
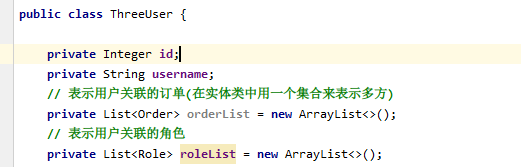
b、 @Many如何实现多对多
//查询所用用户,同时查询每个用户关联的角色信息(多对多)
// 先查询出这个sql,因为用户表和角色表有关联关系,这个关系由中间表来维护
// 第一个sql执行后,有了角色id,然后根据角色id值进行查询,查出该用户的角色信息
@Select("select * from user")
@Results({
@Result(property = "id",column = "id"),
@Result(property = "username",column = "username"),
@Result(property = "roleList",column = "id",javaType = List.class,
many = @Many(select = "com.shanglin.mapper.IRoleMapper.findRoleByUid"))
})
public List<ThreeUser> findAllUserAndRole();

public interface IRoleMapper {
// 根据用户的id进行关联查询,把用户的角色信息查出也是第二次查询
@Select("select * from sys_role r,sys_user_role ur where r.id = ur.roleid and ur.userid = #{uid}")
public List<Role> findRoleByUid(Integer uid);
}

c、测试
@Test
public void ManyToMany(){
IUserMapper mapper = sqlSession.getMapper(IUserMapper.class);
List<ThreeUser> allUserAndRole = mapper.findAllUserAndRole();
for (ThreeUser tUser : allUserAndRole) {
System.out.println(tUser);
}
}

Mybatis的缓存
缓存就是内存中的数据,常常来自对数据库查询结果的保存,使用缓存,我们可以避免频繁的与数据库进行交互,进而提高响应速度
mybatis也提供了对缓存的支持, 分为一级缓存和二级缓存, 可以通过下图来理解:
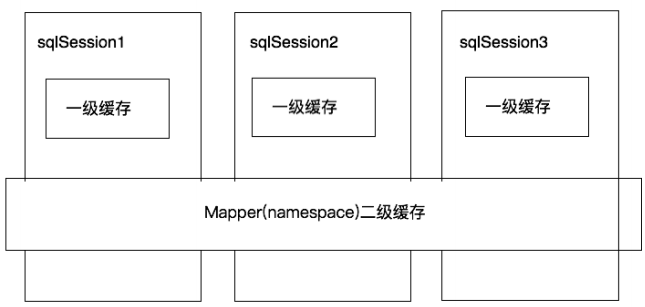

①、一级缓存是Sql Session级别的缓存。在操作数据库时需要构造sql Session对象, 在对象中有一个数据结构(HashMap) 用于存储缓存数据。不同的sql Session之间的缓存数据区域(HashMap) 是互相不影响的。
②、二级缓存是mapper级别的缓存, 多个SqlSession去操作同一个Mapper的sql语句, 多个SqlSession可以共用二级缓存, 二级缓存是跨Sql Session的

一级缓存
通过会话对象SQLSession去查询验证缓存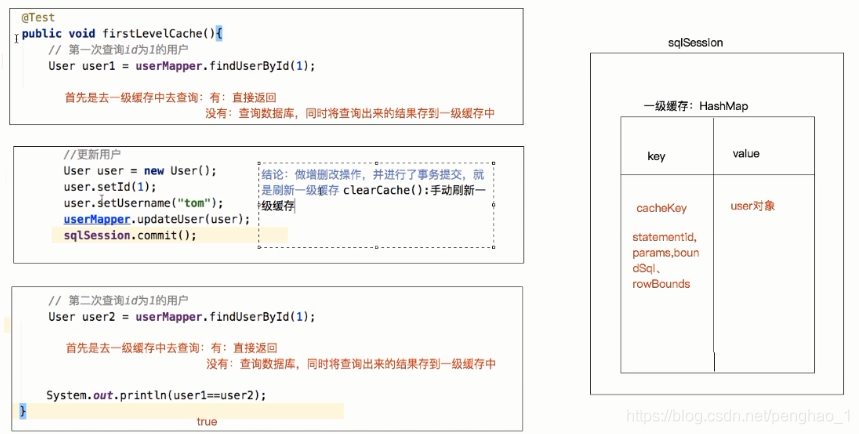

③、总结
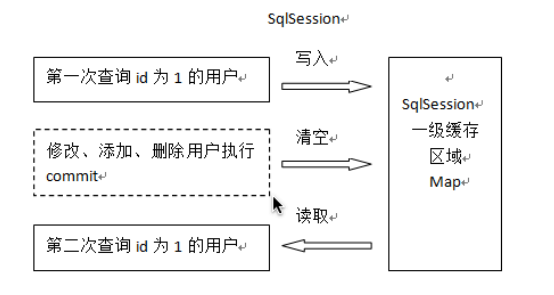
1、第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
2、如果中间sq Session去执行commit操作(执行插入、更新、删除) , 则会清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
3、第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息
一级缓存原理探究与源码分析
一级缓存到底是什么?一级缓存什么时候被创建?一级缓存的工作流程是怎样的?
上面的一级缓存,都绕不开SqlSession。所以从SqlSession开始找
多看一下代码,点进去。
1、一级缓存就是一个hashMap
2、
二级缓存
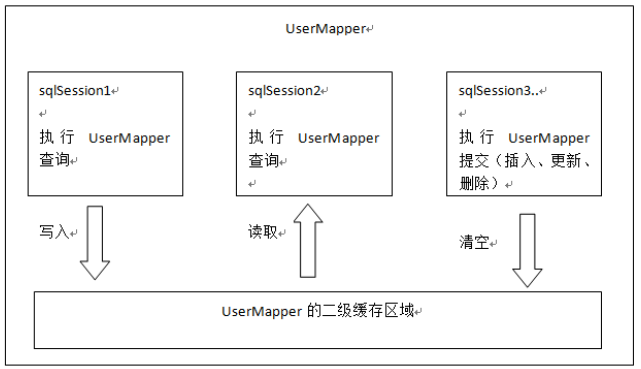
二级缓存缓存的是数据,不是对象,因为缓存是数据,当第二次查询时候,如果是相同的,则重新创建一个对象,将数据赋值给它,然后返回。
二级缓存的原理和一级缓存原理一样,第一次查询,会将数据放入缓存中,然后第二次查询则会直接去缓存中取。但是一级缓存是基于sqlSession的, 而二级缓存是基于mapper文件的namespace的, 也就是说多个sqlSession可以共享一个mapper中的二级缓存区域, 并且如果两个mapper的namespace相同, 即使是两个mapper, 那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中
二级缓存的使用
1、添加二级缓存标签
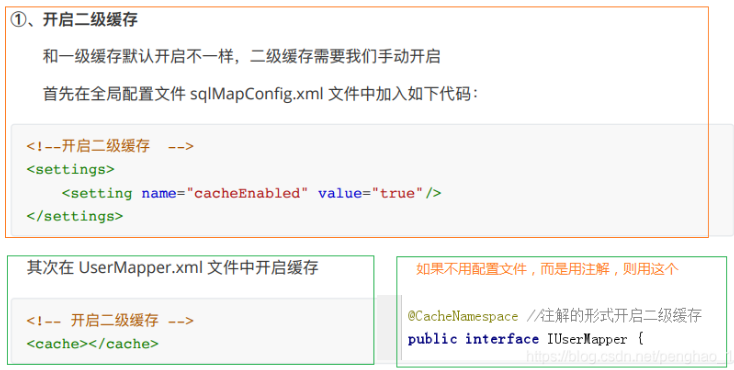

2、对实体类进行序列化
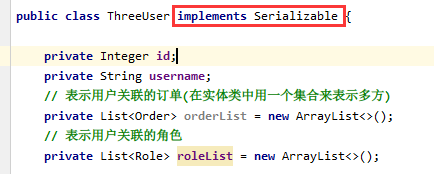
开启了二级缓存后, 还需要将要缓存的pojo实现Serializable接口, 为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话, 就需要反序列化了。所以mybatis中的pojo都去实现Serializable接口
3、测试
@Test
public void secondCatch() {
//根据sqlSessionFactory 生产session 会话对象
SqlSession sqlSession1 = sessionFactory.openSession();
SqlSession sqlSession2 = sessionFactory.openSession();
SqlSession sqlSession3 = sessionFactory.openSession();
// String statement = "com.lagou.pojo.UserMapper.selectUserByUserId" ;
IUserMapper userMapper1 = sqlSession1.getMapper(IUserMapper.class );
IUserMapper userMapper2 = sqlSession2.getMapper(IUserMapper.class );
IUserMapper userMapper3 = sqlSession2.getMapper(IUserMapper.class );
//第一次查询,命中率为0,会发出sql,将查询结果放到缓冲中
User u1 = userMapper1.findUserById(1);
System.out.println(u1);
sqlSession1.close(); //清空一级缓存
User user = new User();
user.setId(1);
user.setUsername( "aaa" );
userMapper3.updateUser(user);
sqlSession3.commit(); // 这步提交后,缓存会被清空
User u2 = userMapper2.findUserById(1); // 第二次也需要发送sql
}
4、分析命中率
第一次命中率是0,就是缓存中没有<br /> 第二次命中率是0.5,也就是缓存中有了,两次,命中一次,概率就是50%<br /> 如果期间进行了更改操作,会清空二级缓存,再次查询还需要从数据库查询。
5、useCache的使用(默认是true)
userCache默认是开启的,默认值是true。
userCache是用来设置是否禁用二级缓存的, 在statement中设置useCache=false可以禁用当前select语句的二级缓存, 即每次查询都会发出sql去查询, 默认情况是true, 即该sql默认去使用二级缓存。
如果将设置成useCache=false, 表示禁用二级缓存, 直接从数据库中获取。
配置文件则如下设置禁用:
<select id="select User By UserId" useCache="false"
resultType="com.shanglin.pojo.User" parameterType="int">
select * from user where id=#{id}
</select>
注解的按如下设置禁用: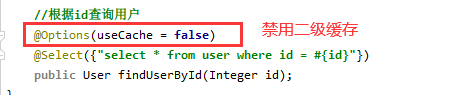
6、flushCache的使用(默认是true)
在mapper的同一个namespace中, 如果有其它insert、update、delete操作数据后需要刷新缓
存,如果不执行刷新缓存会出现脏读。
也就是增删改后是需要刷新缓存的,而配置中flushCache=”true”属性, 默认情况下为true, 即刷新缓存, 如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。所以呢,这个值一般是不修改的,默认让他刷新缓存
分布式二级缓存整合redis


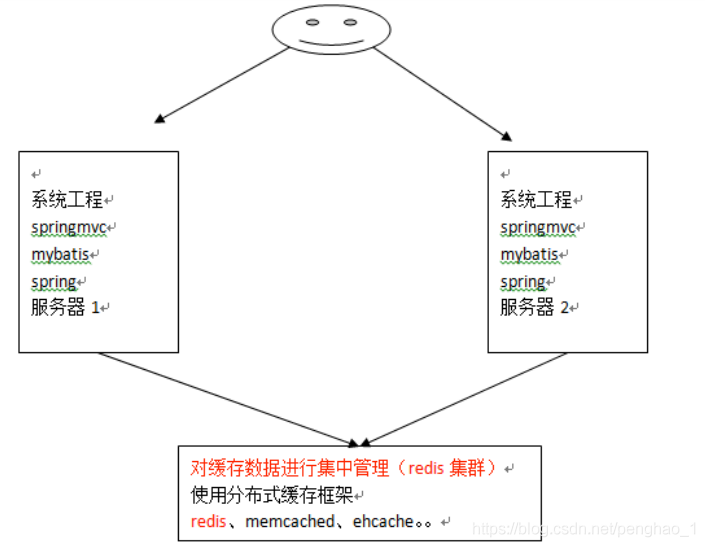



a、mybatis与redis的整合
刚刚提到过, mybatis提供了一个cache接口, 如果要实现自己的缓存逻辑, 实现cache接口开发即可。
mybatis本身默认实现了一个, 但是这个缓存的实现无法实现分布式缓存, 所以我们要自己来实现。
redis分布式缓存就可以, mybatis提供了一个针对cache接口的redis实现类, 该类存在mybatis-redis包中
b、在pom.xml中添加jar包
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
c、基于redis实现二级缓存
1、配置文件的实现
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.shanglin.mapper.IUserMapper">
<cache type="org.mybatis.caches.redis.RedisCache" /><!--基于redis实现二级缓存-->
<select id="findAll" resultType="com.shanglin.pojo.User" useCache="true">
select * from user
</select>

d、在Resource下面创建redis.properties
redis.host=localhost
redis.port=6379
redis.connectionTimeout=5000
redis.password=
redis.database=0
e、代码测试


@Test
public void SecondLevelCache(){
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
SqlSession sqlSession3 = sqlSessionFactory.openSession();
IUserMapper mapper1 = sqlSession1.getMapper(IUserMapper.class);
IUserMapper mapper2 = sqlSession2.getMapper(IUserMapper.class);
IUserMapper mapper3 = sqlSession3.getMapper(IUserMapper.class);
User user1 = mapper1.findUserById(1);
sqlSession1.close(); //清空一级缓存
User user = new User();
user.setId(1);
user.setUsername("lisi");
mapper3.updateUser(user);
sqlSession3.commit();
User user2 = mapper2.findUserById(1);
System.out.println(user1==user2);
}

执行后,出现一次查询,第二次没有查询,而是命中率为0.5。也就是使用redis作为二级缓存已经OK。
mybatis执行器1

若有收获,就点个赞吧
0 人点赞
