分表操作是水平分的。比如一个表记录超过100000,那么1-100000在第一个表,100000以上在另一个表。(而且这两个表的字段是一样的)
先根据company_id奇偶进行分库、再根据id的奇偶进行分表(比如奇数在0表,偶数就在1表)
1、在数据库创建真实表
在两个库中都创建表(b_order0、b_order1)
CREATE TABLE `b_order`(`id` bigint(20) NOT NULL AUTO_INCREMENT,`is_del` bit(1) NOT NULL DEFAULT 0 COMMENT '是否被删除',`company_id` int(11) NOT NULL COMMENT '公司ID',`position_id` bigint(11) NOT NULL COMMENT '职位ID',`user_id` int(11) NOT NULL COMMENT '用户id',`publish_user_id` int(11) NOT NULL COMMENT '职位发布者id',`resume_type` int(2) NOT NULL DEFAULT 0 COMMENT '简历类型:0 附件 1 在线',`status` varchar(256) NOT NULL COMMENT '投递状态 投递状态 WAIT-待处理 AUTO_FILTER-自动过滤 PREPARE_CONTACT-待沟通 REFUSE-拒绝 ARRANGE_INTERVIEW-通知面试',`create_time` datetime NOT NULL COMMENT '创建时间',`operate_time` datetime NOT NULL COMMENT '操作时间',`work_year` varchar(100) DEFAULT NULL COMMENT '工作年限',`name` varchar(256) DEFAULT NULL COMMENT '投递简历人名字',`position_name` varchar(256) DEFAULT NULL COMMENT '职位名称',`resume_id` int(10) DEFAULT NULL COMMENT '投递的简历id(在线和附件都记录,通过resumeType进行区别在线还是附件)',PRIMARY KEY (`id`),KEY `index_createTime` (`create_time`),KEY `index_companyId_status` (`company_id`, `status`(255), `is_del`),KEY `i_comId_pub_ctime` (`company_id`, `publish_user_id`, `create_time`),KEY `index_companyId_positionId` (`company_id`, `position_id`) USING BTREE) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;

2、创建实体类
package com.slin.entity;import javax.persistence.*;import java.io.Serializable;import java.util.Date;@Entity@Table(name = "b_order") // 用的是逻辑表名(真实表是b_order0、b_order1)public class BOrder implements Serializable {@Id@Column(name = "id")@GeneratedValue(strategy = GenerationType.IDENTITY)private long id;@Column(name = "is_del")private Boolean isDel;@Column(name = "company_id")private Integer companyId;@Column(name = "position_id")private long positionId;@Column(name = "user_id")private Integer userId;@Column(name = "publish_user_id")private Integer publishUserId;@Column(name = "resume_type")private Integer resumeType;@Column(name = "status")private String status;@Column(name = "create_time")private Date createTime;@Column(name = "operate_time")private Date operateTime;@Column(name = "work_year")private String workYear;@Column(name = "name")private String name;@Column(name = "position_name")private String positionName;@Column(name = "resume_id")private Integer resumeId;// get/set的方法}
3、创建repository
package com.slin.repository;import com.slin.entity.BOrder;import org.springframework.data.jpa.repository.JpaRepository;public interface BOrderRepository extends JpaRepository<BOrder,Long> {}
4、添加配置信息

######datasource(数据源,有两个库)#######
spring.shardingsphere.datasource.names=ds0,ds1
######配置第一个库#######
#使用连接池
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
#使用驱动
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
#数据库连接(如果是服务器的就只需要把localhost改为服务器的ip即可)
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/lagou1
#数据库用户和密码
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=root
######配置第二个库#######
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/lagou2
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=root
###########sharding-database-strategy实现分库规则#####
#对b_order实现分库的操作(根据企业id进行分的)----是实体类中的逻辑表名b_order
spring.shardingsphere.sharding.tables.b_order.database-strategy.inline.sharding-column=company_id
#如何定位呢,是根据ds$->{company_id % 2}来定位
spring.shardingsphere.sharding.tables.b_order.database-strategy.inline.algorithm-expression=ds$->{company_id % 2}
###########sharding-database-strategy实现分表规则#####
#对Border实现分表的操作(根据id进行分)
spring.shardingsphere.sharding.tables.b_order.table-strategy.inline.sharding-column=id
#如何定位呢,是根据ds$->{id % 2}来定位
spring.shardingsphere.sharding.tables.b_order.table-strategy.inline.algorithm-expression=b_order$->{id % 2}
#####目前配置的是逻辑表,那么要分配到那个库那个真实表上呢,这个就涉及到数据节点的问题
spring.shardingsphere.sharding.tables.b_order.actual-data-nodes=ds${0..1}.b_order${0..1}
#id的主键生成器(配置之后就会采用系统内置的雪花算法)
spring.shardingsphere.sharding.tables.b_order.key-generator.column=id
spring.shardingsphere.sharding.tables.b_order.key-generator.type=SNOWFLAKE
5、添加测试类
@Resource
private BOrderRepository bOrderRepository;
@Test
@Repeat(100)// 重复100次·
public void testShardingBOrder(){
Random random = new Random();
int companyId = random.nextInt(10);
BOrder order = new BOrder();
order.setDel(false);
order.setCompanyId(companyId);
order.setPositionId(3242342);
order.setUserId(2222);
order.setPublishUserId(1111);
order.setResumeType(1);
order.setStatus("AUTO");
order.setCreateTime(new Date());
order.setOperateTime(new Date());
order.setWorkYear("2");
order.setName("lagou");
order.setPositionName("Java");
order.setResumeId(23233);
bOrderRepository.save(order);
}
6、效果展示
company_id为偶数的在lagou1库中,而且根据id信息再进一步分表
lagou1库中b_order0表的结果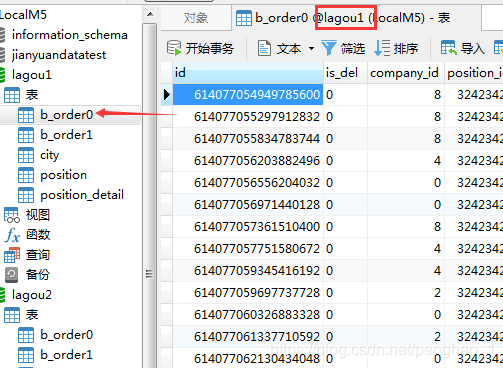
lagou1库中b_order1表的结果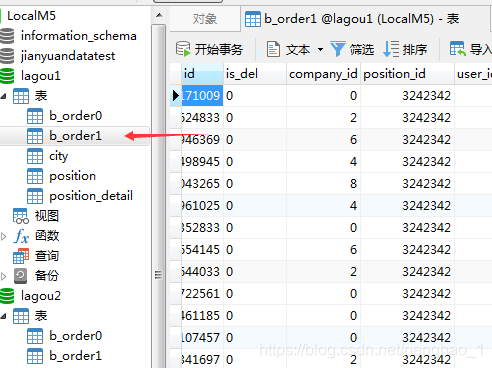
company_id为奇数的在lagou2库中,而且根据id信息再进一步分表
奇数的 company_id又根据id信息分到b_order0或是b_order1中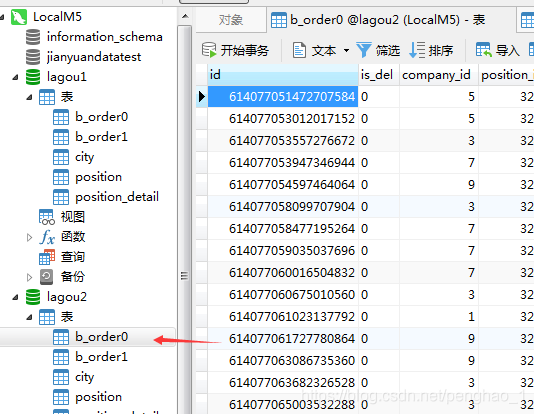

若有收获,就点个赞吧
0 人点赞
