自定义持久层框架完成如下步骤
目录
任务一:自定义持久层框架
1、首先对jdbc的回顾,问题的分析,及给出解决方案。
2、自定义框架的设置思路
3、自定义持久成框架使用端代码的编写
4、自定义持久成框架编写
5、使用端对代码进行测试
接下来需要对其进行优化:
1、添加getMapper方法返回代理实现类
2、具体是如何实现其动态代理的invoke方法
1、首先对jdbc的回顾,问题的分析,及给出解决方案。
1、加载驱动
2、获取连接
3、创建预处理对象
4、执行sql等

原始jdbc开发存在的问题如下:
1、 数据库连接创建、释放频繁造成系统资源浪费,从二影响系统性能。
2、 Sql语句在代码中硬编码,造成代码不易维护,实际应用中sql变化的可能较大,sql变动需要改变 java代码。
3、 使用preparedStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一定,可能 多也可能少,修改sql还要修改代码,系统不易维护。
4、 对结果集解析存在硬编码(查询列名),sql变化导致解析代码变化,系统不易维护,如果能将数据 库 记录封装成pojo对象解析比较方便
问题解决思路
①使用数据库连接池初始化连接资源
②将sql语句抽取到xml配置文件中
③使用反射、内省等底层技术,自动将实体与表进行属性与字段的自动映射
其实在图片中已经比较详细了。
2、自定义框架的设置思路
自定义框架在本质上还是对jdbc的封装,只不过封装的过程中把对上面jdbc提出的存在的问题进行规避/解决而已。
当使用端调用自定义持久成框架完成与数据库的交互的时候,它的底层代码执行的还是jdbc,
一段jdbc代码要正常执行,有两部分是必须的。
1、数据库配置信息,(用户名、密码、驱动、url等)
2、sql配置信息,(SQL语句、参数类型,返回值类型)
而这两部分信息都是由使用端进行提供的,它要传递给持久层框架,
持久层框架就是对这两个配置文件进行解析,以及得到其里面的内容,然后就是进行jdbc的操作


到这来,可以具体先了解一下sqlSession,https://www.yuque.com/jixiangkuaile/kk8w4w/zaqnhm
3、使用端代码的编写
自定义持久成框架是要将使用端传递过来的配置文件解析后才能执行数据库操作的
1、先要引入持久成框架的jar。
2、创建两个配置文件sqlMapConfig.xml , Mapper.xml
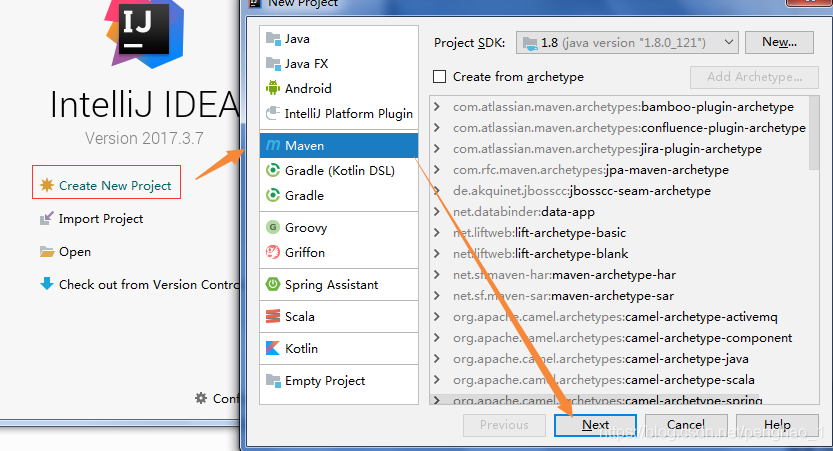
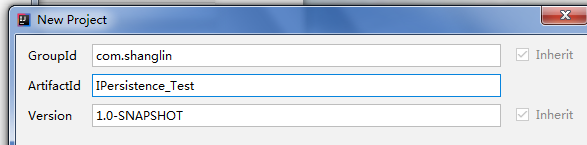
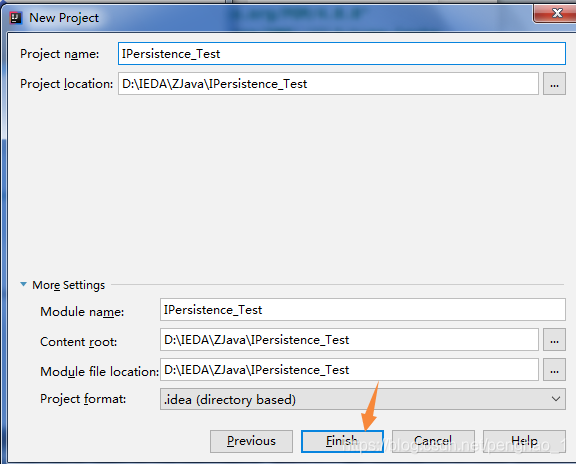
a、创建项目



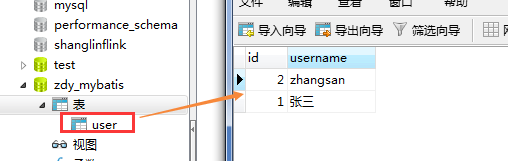
b、创建数据库信息

c、添加配置文件,并写配置信息
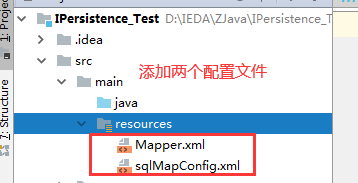

sqlMapConfig.xml的配置信息

Mapper.xml的配置信息
注意: 这里的Mapper是多个的,因为一个模块需要对应一个mapper配置信息,方便开发以及后期维护
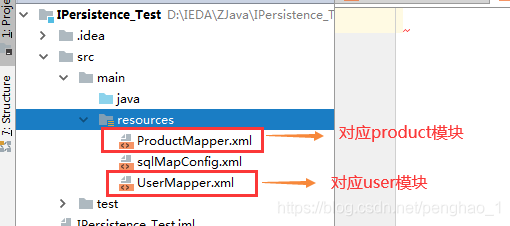

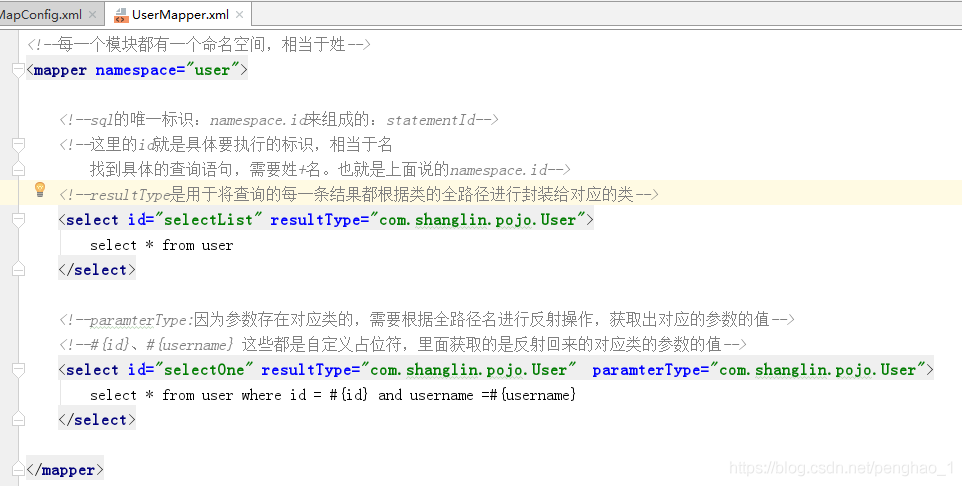

d、最后一步,将Mapper.xml的配置信息的全路径,存放到sqlMapConfig.xml文件中
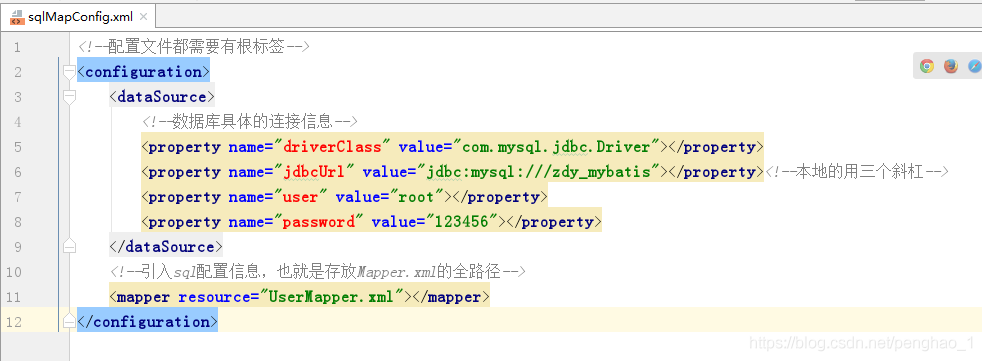

到此,使用端的配置信息才完成。
4、自定义持久成框架编写
先要明白,自定义持久成框架必不可少的两部分信息,
1、sqlMapConfig.xml数据库配置信息,
2、Mapper.xmlSql 配置信息
其实这两部分都是已经在使用端创建完成了。它只需要一个接口,将两部分信息传过来到自定义持久层框架中。
传递过来后,框架会将对其配置文件进行解析,封装,最后执行
在框架中大概需要完成6步。讲解之前,需要先创建一个项目
先创建一个项目


第一步
a、 先创建一个类,在类中创建一个方法,这个方法里面根据Path的路径解析信息。
也就是相当于一个框架给使用端提供的接口,将配置信息的路径传过去
根据path的路径,去加载对应的两个配置文件,转为字节输入流,然后存到内存中。(java的jvm中)

记住:类加器是类名.Class才能拿


类加载器负责加载 Java 类的字节代码到 Java 虚拟机中。
注意:可以先了解一下类加载器:https://www.yuque.com/jixiangkuaile/kk8w4w/ldsd2e
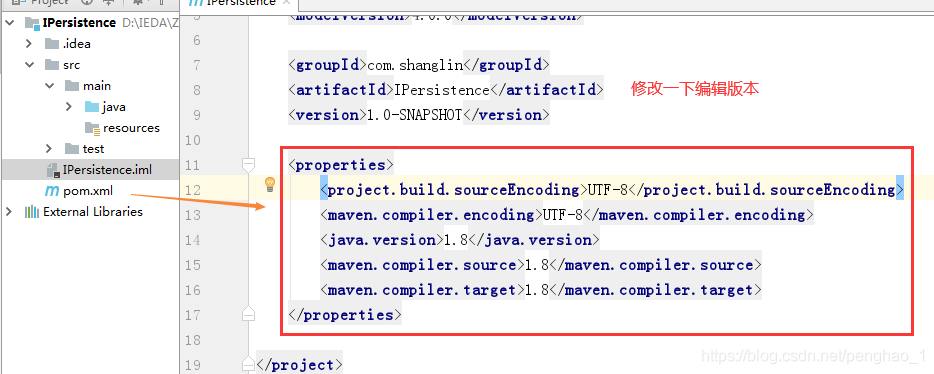
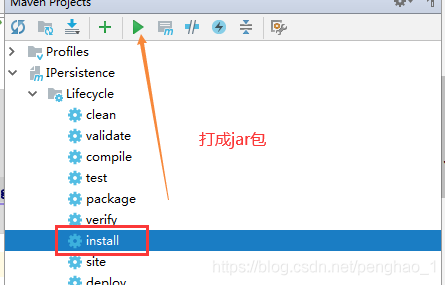
b、修改一下编辑版本,并打包自定义持久层框架


c、持久层的使用端要调用自定义持久层框架,那么先要引入自定义持久层框架的jar。
将刚刚打包好的自定义持久层框架引入到使用端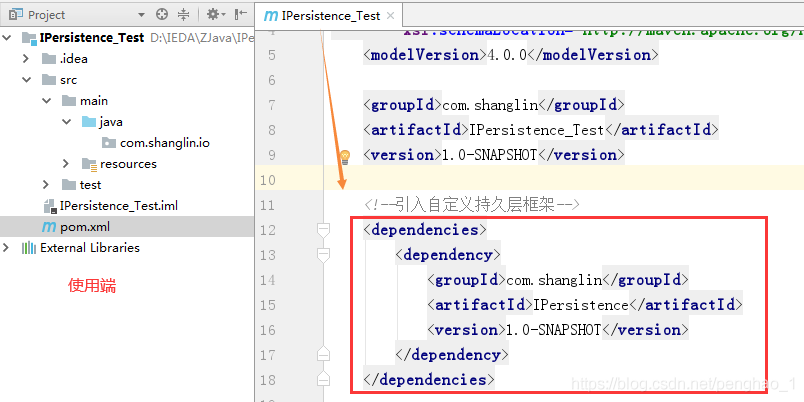
d、通过数据库使用端去调用自定义持久层框架,加载配置信息,返回字节输入流
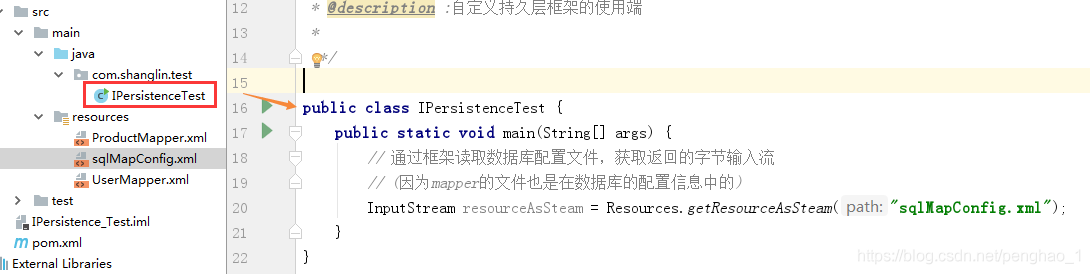

到此,第一步已经OK。
第二步
要创建两个容器(javaBean)用于存放解析出来的配置信息的内容
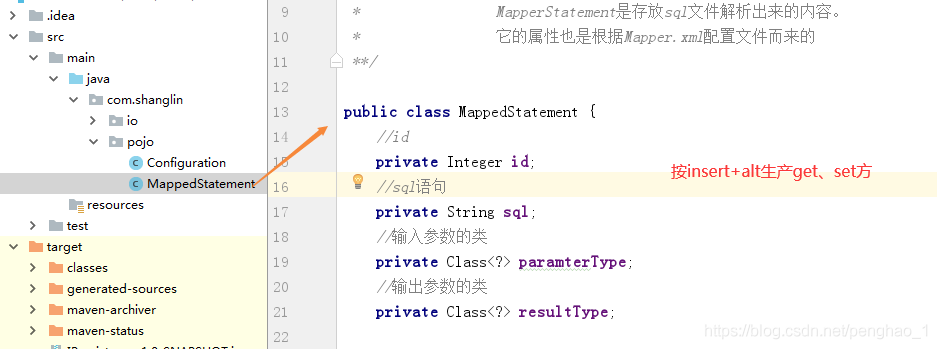
Configuration是存放数据库配置信息解析的内容,
MapperStatement是存放sql文件解析出来的内容。



第三步
创建SqlSessionFactoryBuilder类,并创建build方法,读取字节输入流
1、用dom4j解析配置文件,将解析内容存到容器中。
2、创建SqlSessionFactory对象生产SqlSession会话对象
a、先要创建SqlSessionFactoryBuilder类及build方法。
将加载进jvm中的字节输入流传给xml进行解析

b、在使用dom4j进行解析配置文件之前,需要引入依赖
<dependencies><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.17</version></dependency><dependency><groupId>c3p0</groupId><artifactId>c3p0</artifactId><version>0.9.1.2</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.12</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.10</version></dependency><dependency><groupId>dom4j</groupId><artifactId>dom4j</artifactId><version>1.6.1</version></dependency><dependency><groupId>jaxen</groupId><artifactId>jaxen</artifactId><version>1.1.6</version></dependency></dependencies>

c、在XMLConfigBuilder中使用dom4j进行解析配置文件
public class XMLConfigBuilder {
// 因为要将数据库的配置信息存放到Configuration中,所以要创建一个Configuration对象
private Configuration configuration;
// 然后给类一个无参构造,因为前面的SQLSession调用类的无参的时候,其实也就创建了一个Configuration
// 创建了Configuration,下面解析出来的参数信息存到Configuration中
public XMLConfigBuilder ()
{
this.configuration=new Configuration();
}
// 该方法就是通过dom4j将配置文件进行解析,封装到Configuration中
public Configuration parseConfig(InputStream inputStream) throws DocumentException, PropertyVetoException {
// 先用dom4j的SAXReader方法读取字节输入流
Document read = new SAXReader().read(inputStream);
//去拿到根对象<configuration>
Element rootElement = read.getRootElement();
// 通过根对象查找到需要的元素
List<Element> list = rootElement.selectNodes("//property");
// 创建一个能存key,value的容器
Properties properties = new Properties();
// 遍历拿到dataSource中的各个元素&值
for (Element element : list) {
String name = element.attributeValue("name");
String value = element.attributeValue("value");
// 将遍历的结果存到容器中
properties.setProperty(name,value);
}
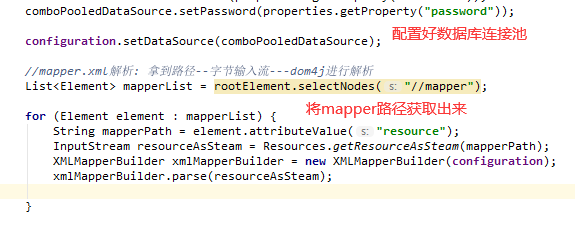
// 到此,数据库的配置信息都存到了Properties中
// new一个数据源对象,为了避免频繁创建、释放数据库连接,所以使用连接池
ComboPooledDataSource comboPooledDataSource = new ComboPooledDataSource();
comboPooledDataSource.setDriverClass(properties.getProperty("driverClass"));
comboPooledDataSource.setJdbcUrl(properties.getProperty("jdbcUrl"));
comboPooledDataSource.setUser(properties.getProperty("user"));
comboPooledDataSource.setPassword(properties.getProperty("password"));
// 当调用无参的时候,就可以进行赋值,将数据传给configuration
configuration.setDataSource(comboPooledDataSource);
return configuration;
// 到此,对configuration数据库配置文件的信息已经解析完成、
// 接下来是对Mapper.xml进行解析
}
}

d、对Mapper.xml进行解析
此段获取节点信息的代码,还是在XMLConfigBuilder中,因为其mapper的路径也是在里面的嘛
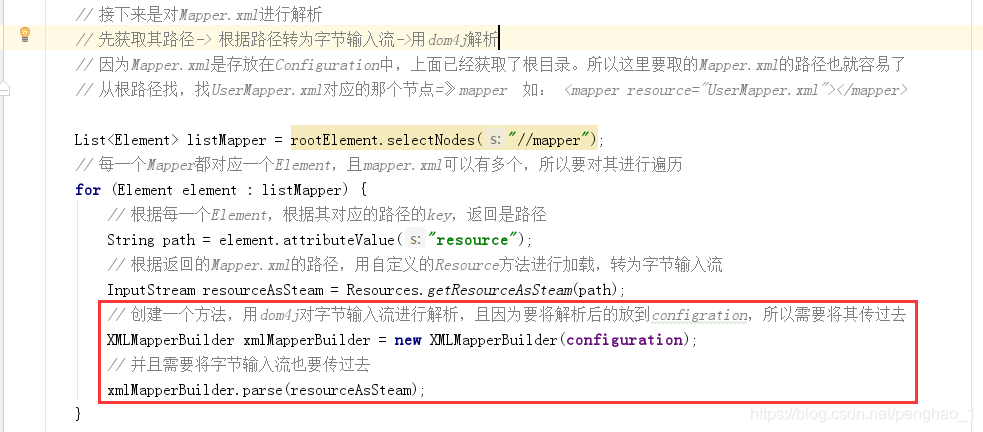
具体如图:
e、创建其对应的XMLMapperBuilde文件,对Mapper.xml进行解析
public class XMLMapperBuilder {
private Configuration configuration;
// 这里先进行赋值
public XMLMapperBuilder(Configuration configuration) {
this.configuration=configuration;
}
// 提供一个方法,把字节输入流传进来
public void parse(InputStream inputStream) throws DocumentException {
// 使用dom4j对字节输入流进行解析
Document read = new SAXReader().read(inputStream);
// 从解析出来的Document中获取根路径
Element rootElement = read.getRootElement();
// 从根路径中获取Mapper文件对应的命名空间的值 如:<mapper namespace="user">
String namespace = rootElement.attributeValue("namespace");
// 解析后的Mapper,里面有很多sql语句,每一条执行后对应的一个MappedStatement,
// 所以需要将其找出 如: <select id="selectList" ....
List<Element> list = rootElement.selectNodes("//select");
// 并对其进行遍历
for (Element element : list) {
// 根据其可以找出值
// 如:<select id="selectOne" resultType="com.shanglin.pojo.User" paramterType="com.shanglin.pojo.User">
String id = element.attributeValue("id");
String resultType = element.attributeValue("resultType");
String paramterType = element.attributeValue("paramterType");
String sqlText = element.getTextTrim();
// 每一个element返回就是对应一个MappedStatement对象,所以将他们封装
MappedStatement mappedStatement = new MappedStatement();
mappedStatement.setId(id);
mappedStatement.setResultType(resultType);
mappedStatement.setParamterType(paramterType);
mappedStatement.setSql(sqlText);
// 因为每一个MappedStatement都是对应唯一的sql,那么就需要一个唯一标识StatementId ,命名空间+Id
String key = namespace + id;
// 将封装好的mappedStatement装到Configration中
configuration.getMappedStatementMap().put(key,mappedStatement);
// 到此,对应的Mapper.xml解析已经OK。
}
}
}

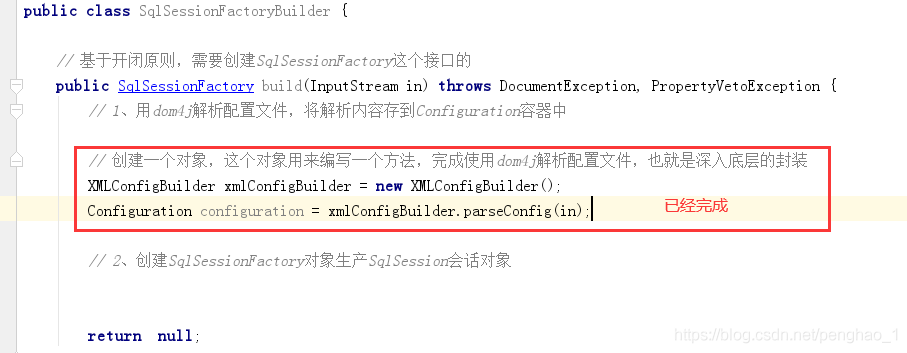

f、 然后创建会话对象
1、为什么需要创建工厂类?
因为通过工厂类生产SqlSession会话对象。
2、为什么需要生产SqlSession会话对象?
因为通过会话对象将与数据库进行交互的增删改查封装在它里面。(SqlSession就是一个门面,而具体执行的是executor,所以只有进入这个门面,才能进行具体的操作)
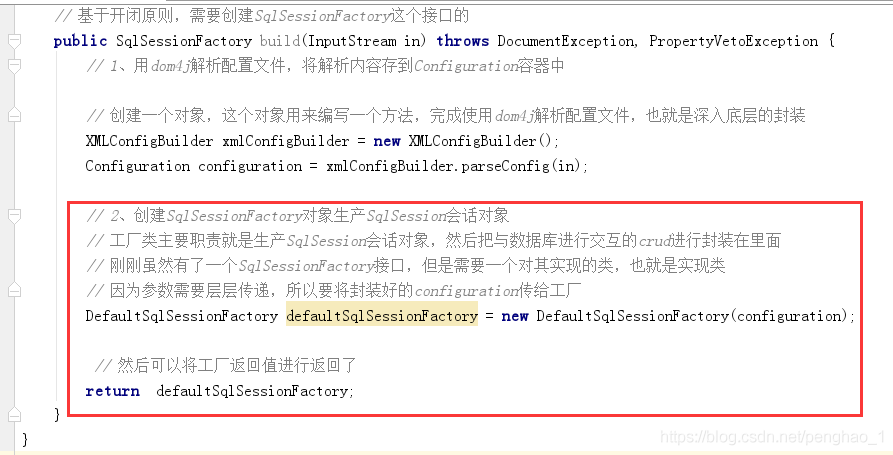



在使用端调用的,返回其实就是defaultSqlSessionFactory


到此,第三步已经OK
第四步




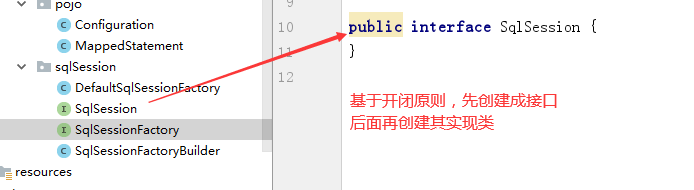

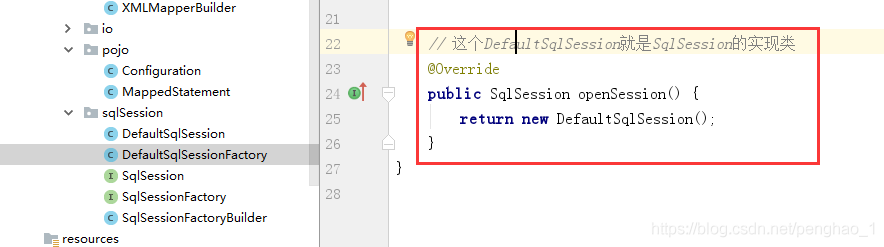





到此,第四步已经OK
第五步
编写sqlSession及实现类里面的方法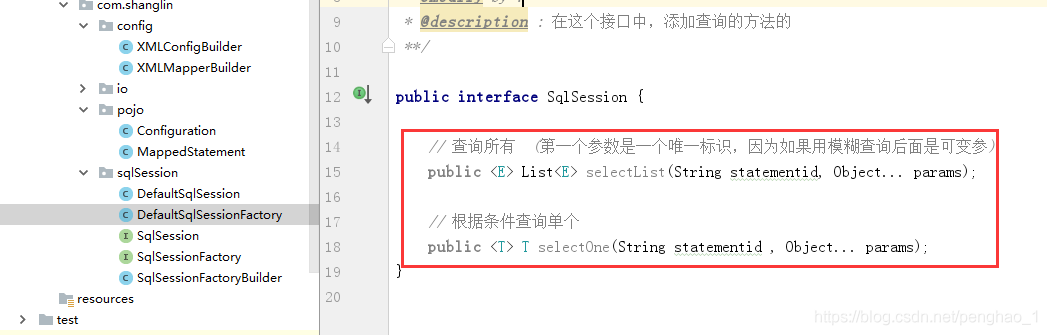

可以在测试端进行测试,查询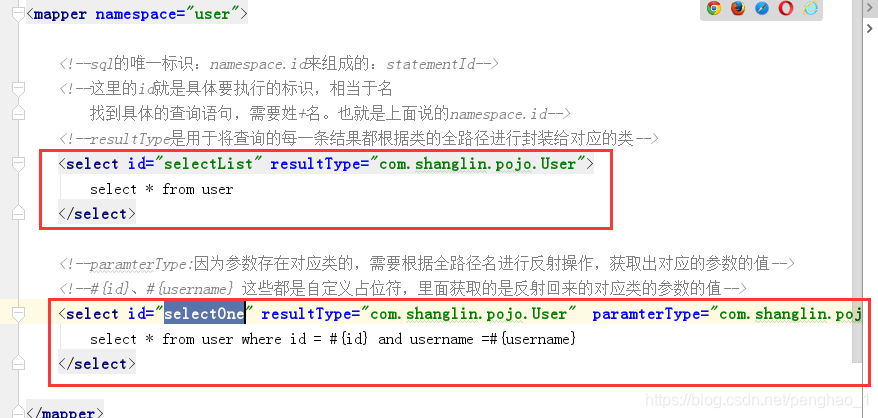

接口中的方法,就是对应配置文件的查询sql
具体实现如下: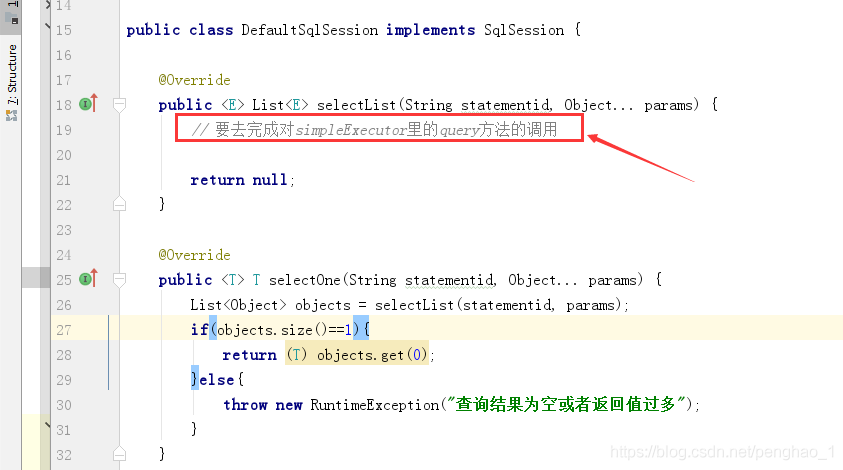

对第五步的 sqlSession继承那么多的接口还有存在一定疑问,不太清晰
第六步
创建一个执行器,并且写一个query方法。及其实现类



具体的实现如下: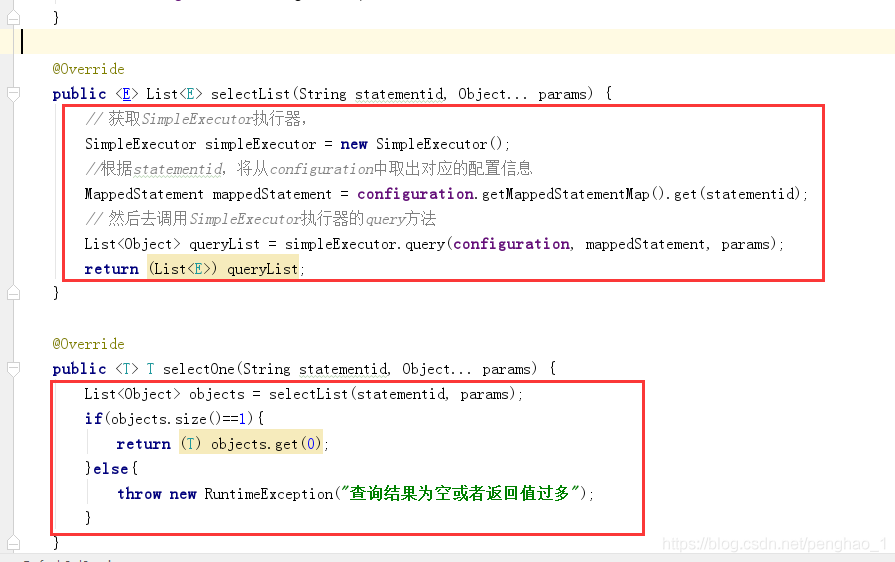

到此,第五步已经OK
然后实现第六步的代码
在query中如何去执行底层的jdbc代码,完成参数的设置以及对结果集的封装。

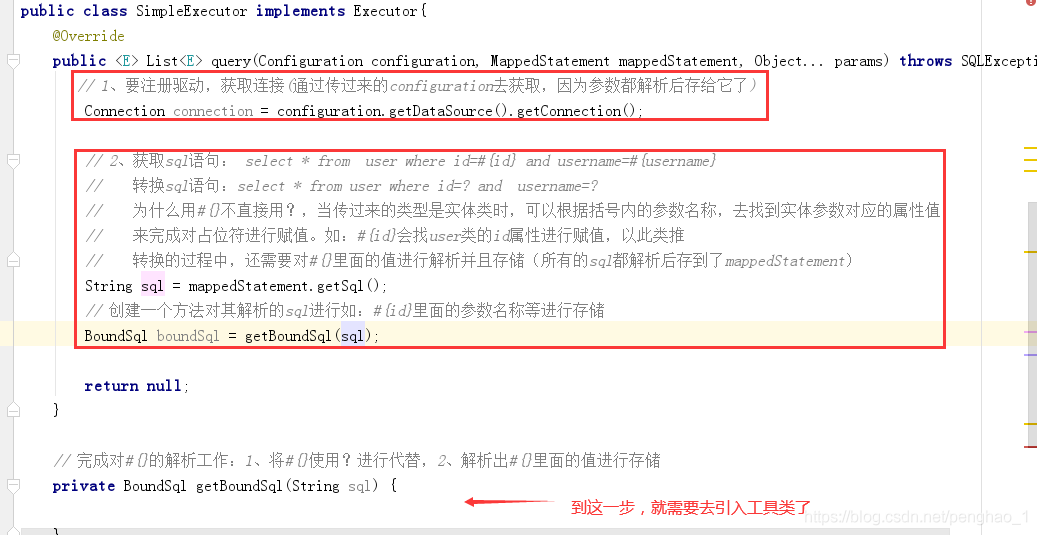

工具类是Mybaties从源码中过啦的、里面呢就是对#、$等进行转换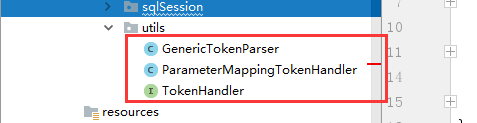



工具类如何对占位符进行解析

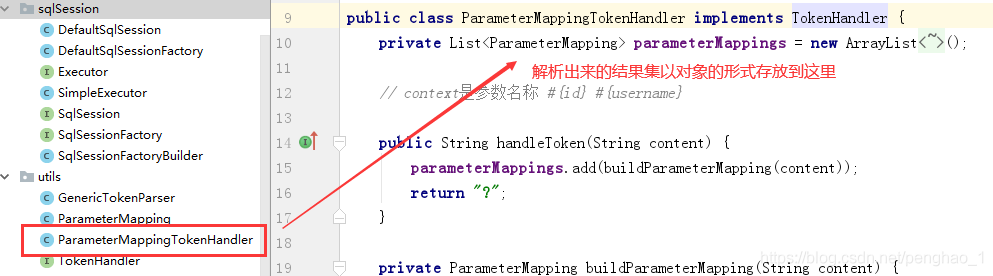



具体代码如下:
public class SimpleExecutor implements Executor{
@Override
public <E> List<E> query(Configuration configuration, MappedStatement mappedStatement, Object... params) throws Exception {
// 1、要注册驱动,获取连接(通过传过来的configuration去获取,因为参数解析后都存给它了)
Connection connection = configuration.getDataSource().getConnection();
// 2、获取sql语句: select * from user where id=#{id} and username=#{username}
// 转换sql语句:select * from user where id=? and username=?
// 为什么用#{}不直接用?,当传过来的类型是实体类时,可以根据括号内的参数名称,去找到实体参数对应的属性值
// 来完成对占位符进行赋值。如:#{id}会找user类的id属性进行赋值,以此类推
// 转换的过程中,还需要对#{}里面的值进行解析并且存储(所有的sql都解析后存到了mappedStatement)
String sql = mappedStatement.getSql();
// 先创建一个类BoundSql,用来存储(将上面2的sql转换后的sql),并存储#{id}里面的参数名称
// 创建一个方法getBoundSql进行执行真正的解析操作(先解析,后存储)
BoundSql boundSql = getBoundSql(sql);
// 3、获取预处理对象: preparedStatement
// 用的sql是对刚刚解析出来的sql作为参数。返回的就是预处理对象
PreparedStatement preparedStatement = connection.prepareStatement(boundSql.getSetSqlText());
// 4、设置参数,因为如果有占位符的要对占位符进行赋值
/** 传递过来如果是对象,那么要取出对象的属性值为占位符赋值
参数是由使用端调用某条sql时,传递过来的 如:...sqlSession.selectOne("user.selectOne", user); user就是参数
这里要取出参数的里面的属性值,为上面的占位符进行赋值*/
/**(4.3.1 先要获取到参数的全路径 ,(返回值参数一般是全限定类名如:com.slin.pojo.User)
有了类全路径,才能通过反射获取到实体的Class对象,从而获取其属性对象)
而这个类的全路径是在解析的时候封装到了(参数类型,返回值类型,执行的SQL)
是封装到了存储SQL的类里面,就是mappedStatement里面
**/
// 先要获取到参数的全路径 (其实也就是实体类的全限定类名)
String paramterType = mappedStatement.getParamterType();
// 把全路径(全限定类名)变成Class对象
Class<?> paramtertypeClass = getClassType(paramterType);
// 4.1因为刚刚对sql进行了解析并存到了list集合中并封装在BoundSql,所以先要取出集合
List<ParameterMapping> parameterMappingList = boundSql.getParameterMappingList();
// 4.2遍历集合,取出里面的每一个属性值(id,username...)
for (int i=0;i<parameterMappingList.size();i++) {
// 取出每一个parameterStatement
ParameterMapping parameterMapping = parameterMappingList.get(i);
// 获取出具体的内容,content对应的就是#{id}里面的值=》id
String content = parameterMapping.getContent();
/* 4.3思路:通过反射,根据得到的参数名称如id,获取到实体对象中的属性值。
然后根据这个属性值,获取当前传递过来的如user实体里面的id参数的属性值
拿到属性值后,借助parameter来进行参数的设置*/
// 4.3.2根据生成的class对象来获取某一个属性对象,那么要获取那个属性对象呢,就是content
// 根据content(如:id)这个属性去获取属性对象
Field declaredField = paramtertypeClass.getDeclaredField(content);
// 为了防止是私有的,所以要设置暴力访问,以便下面获取其值
declaredField.setAccessible(true);
/** 得到属性对象后,如何获取其属性的值呢,
获取它的值(它的值存在params的可变参中,可变参是一个list集合(可以多个参数的 嘛)。
所以取第一个就是得到user实体对象也就是params[0],
再根据得到的实体对象params[0]获取对应的属性值,也就是根据declaredField来判断取那个嘛*/
Object o = declaredField.get(params[0]);
// 借助preparedStatement去设置参数(i是0开始,而设置下标是1开始)
preparedStatement.setObject(i+1,o);
/**效果相当于
PreparedStatement pst =conn.prepareStatement(sql);
//为占位符设置具体内容("id","name")
pst.setString(1, id的值);
pst.setString(2, name的值);**/
}
// 5、执行sql (执行后的结果返回到resultSet中)
ResultSet resultSet = preparedStatement.executeQuery();
// 拿到返回结果的全路径
String resultType = mappedStatement.getResultType();
// 根据返回的全路径(全限定类名)获取class对象,
Class<?> resultTypeClass = getClassType(resultType);
// 获取到具体的对象(对类对象进行实例化)
Object o = resultTypeClass.newInstance();
// 因为返回的结果是一个list
ArrayList<Object> arrayList = new ArrayList<>();
// 6、封装返回结果集
// (就是对resultSet内的结果集进行遍历,查出字段值,按照映射关系封装成一个实体对象)
// 那么怎么知道封装都那个实体中呢
// 其实Mapper.xml的映射文件中,每条sql都有映射对应的实体(因为已经有了类的全路径)
while (resultSet.next()){
// 先获取到元数据(因为元数据里面含有查询结果的字段对应的名称)
ResultSetMetaData metaData = resultSet.getMetaData();
// 查询结果的总列数
for (int i = 1; i < metaData.getColumnCount(); i++) {
// 字段名
String columnName = metaData.getColumnName(i);
// 根据字段名获取其值
Object value = resultSet.getObject(columnName);
// 使用反射或内省,根据数据库表和实体的对应关系,完成封装
// PropertyDescriptor是内省库的一个类,调用它的有参时,
//会对resultTypeClass(User)类的columnName属性生产读写方法
PropertyDescriptor propertyDescriptor = new PropertyDescriptor(columnName,resultTypeClass);
// 获取其写方法
Method writeMethod = propertyDescriptor.getWriteMethod();
// 把具体的值 value 封装到 o对象中
// o的实例对象(User)是通过返回类型的全限定类名(com.slin.pojo.User)生成的
writeMethod.invoke(o,value);
// 到此,封装完成
}
// 将封装好的实体对象存到list中
arrayList.add(o);
}
return (List<E>) arrayList;
}
// 根据某一个类的全路径(全限定类名)来获取其Class对象
private Class<?> getClassType(String paramterType) throws ClassNotFoundException {
if(paramterType!=null){
Class<?> aClass = Class.forName(paramterType);
return aClass;
}
return null;
}
// 完成对#{}的解析工作:1、将#{}使用?进行代替,2、解析出#{}里面的值进行存储
private BoundSql getBoundSql(String sql) {
// 标记处理类:配置标记解析器来完成对占位符的解析处理工作(返回具体实现下面才能调用)
ParameterMappingTokenHandler paraMTH = new ParameterMappingTokenHandler();
// 提供一个开始标志、结束标志,标志处理器
GenericTokenParser genericTokenParser = new GenericTokenParser("#{", "}", paraMTH);
// parse实现对占位符的解析工作,这里返回的就是解析后的sql
String parseSql = genericTokenParser.parse(sql);
// parameterMappings存的就是#{}里面解析出来的参数的名称 #{id}就存id
List<ParameterMapping> parameterMappings = paraMTH.getParameterMappings();
// 基于面向对象的原因,将解析出的参数存到对象中封装
BoundSql boundSql = new BoundSql(parseSql,parameterMappings);
// 然后将封装好的sql进行返回
return boundSql;
}
}
可以先了解一下反射的作用、用法: https://www.yuque.com/jixiangkuaile/kk8w4w/gqb2ew
5、使用端对代码进行测试
通过测试来判断自定义的持久层框架能否与数据库进行交互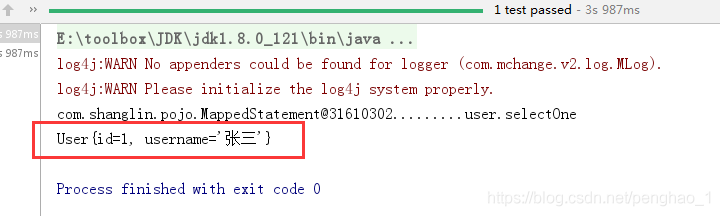

到此自定义的持久层框架已经OK。
接下来需要对其进行优化:
https://www.yuque.com/jixiangkuaile/kk8w4w/uvhyi8
1、添加getMapper方法返回代理实现类
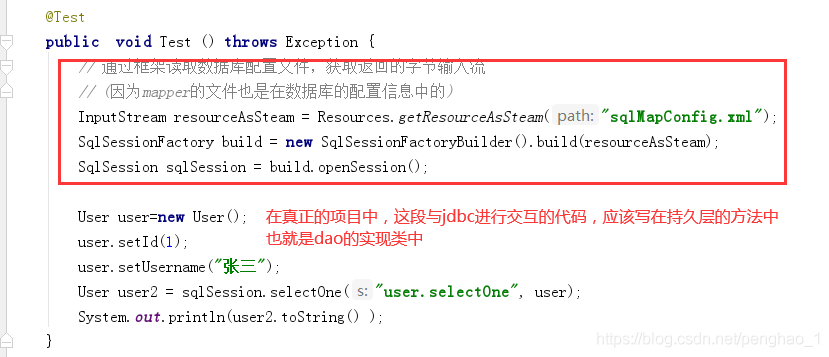

所以接下来给项目添加持久层的接口及接口方法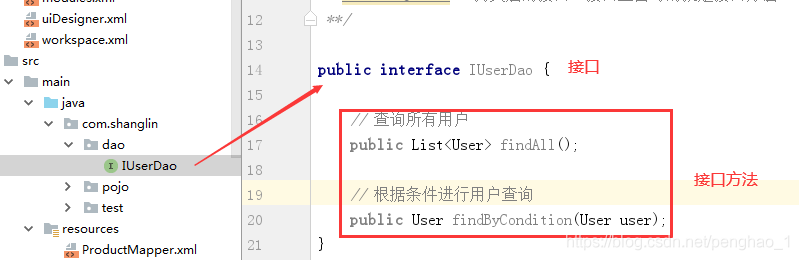

基于开闭原则,有接口,必有其实现类。但是实现类里面存在什么问题呢
存在硬编码的问题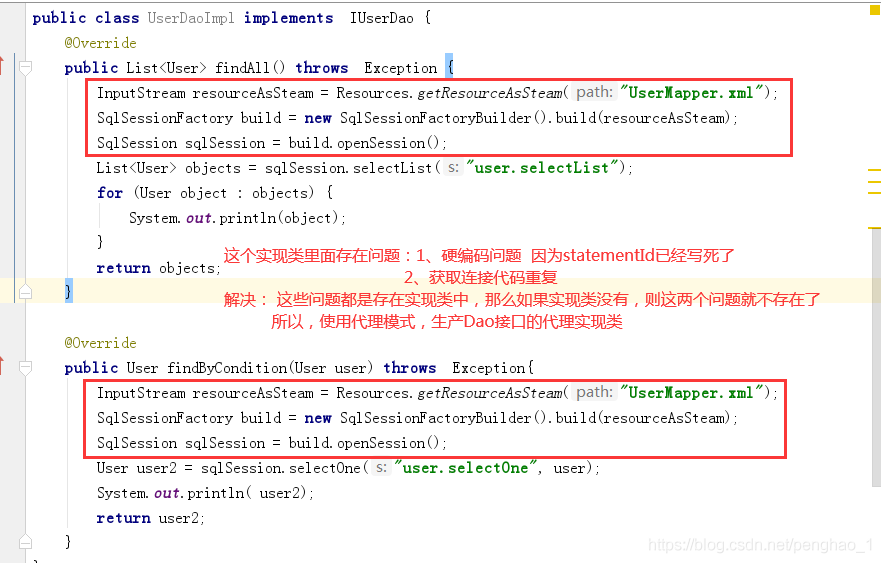

使用代理模式,来生成Dao层接口的代理实现类,将底层的调用都交给代理实现类来完成。
具体代码如下:
要在自定义的持久层框架的接口中,增加一个方法。(用于为Dao接口生成代理实现类)

有了接口方法,根据开闭原则,必须要取实现其实现类。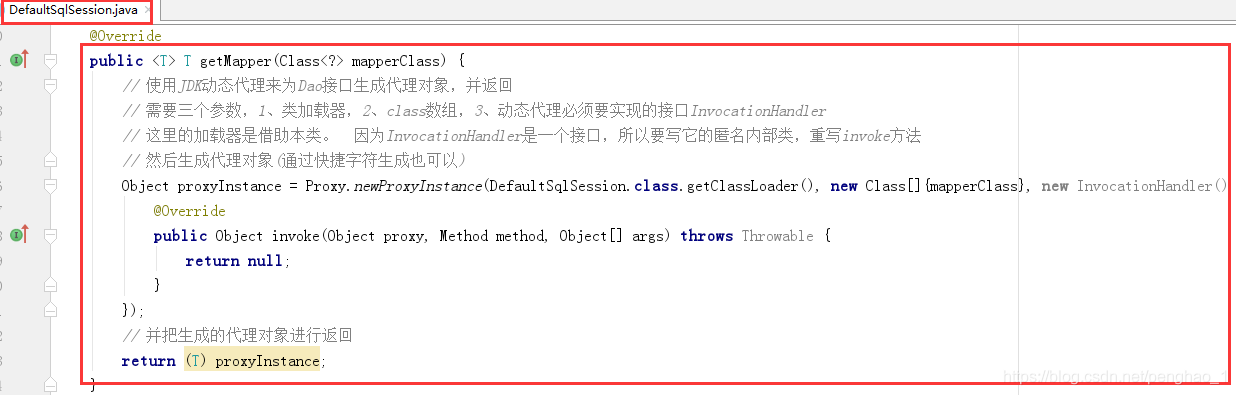

使用端是如何使用代理对象,是通过:接口的代理对象.接口的任意方法

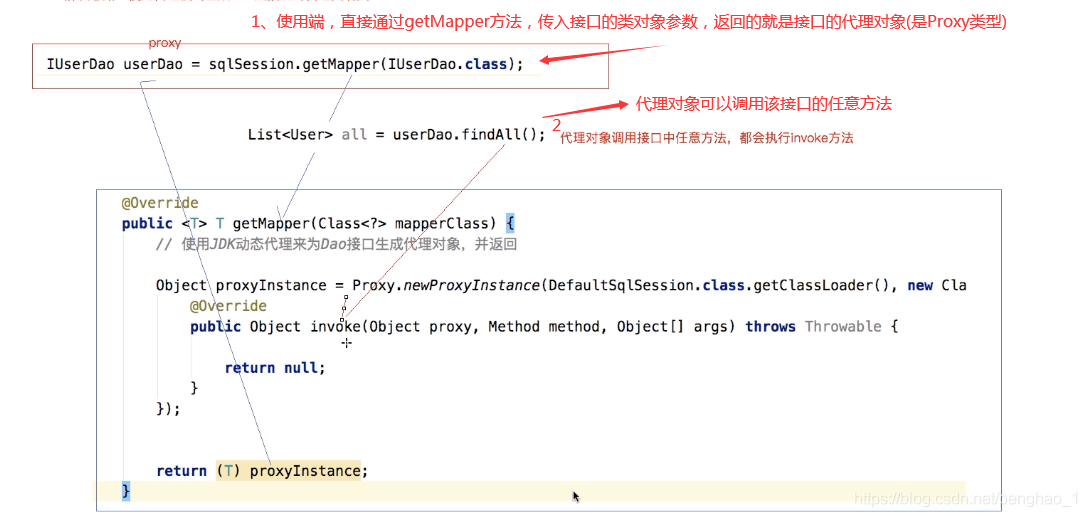

2、具体是如何实现其动态代理的invoke方法
先要理解invoke三个参数:
proxy当前代理对象的应用,
method被调用方法的引用,
args传递的参数
如上面代理对象userDao调用findAll()方法,这个method方法其实就是findAll()的一个引用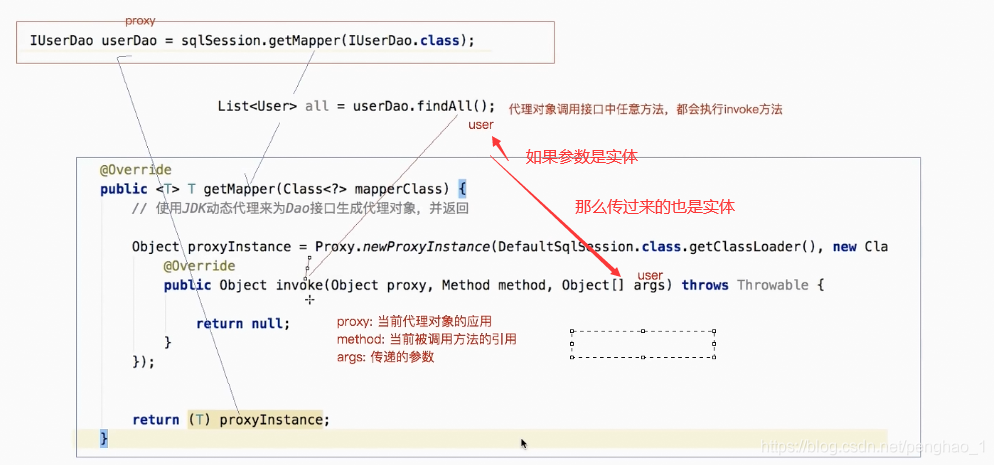

因为调用selectList或selectOne方法都行需要参数的,所以先要准备参数,这个参数在invoke中不能直接拿得到namespace.id。所以需要接口方法里面的名字,和配置文件sql的唯一标识的id的值要一致。
这样通过获取方法名也就相当于获取了id
具体如下图所示: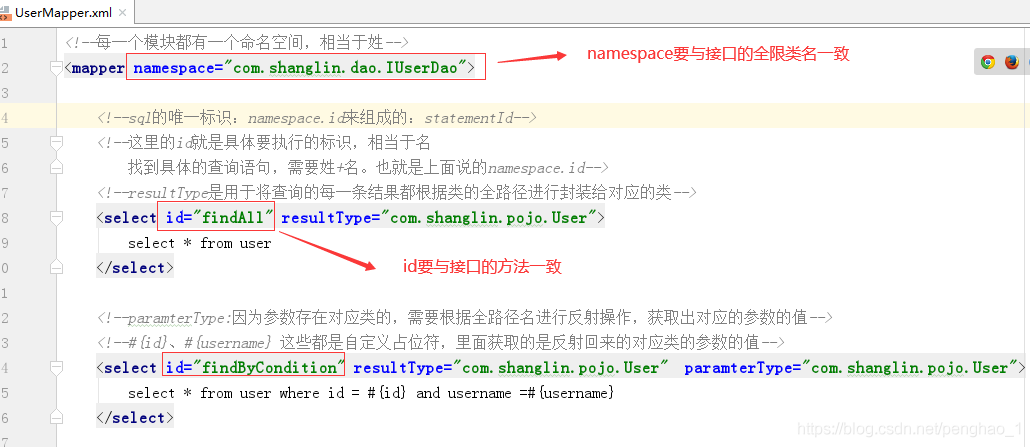


完整的自定义DefaultSqlSession类
public class DefaultSqlSession implements SqlSession {
private Configuration configuration;
public DefaultSqlSession(Configuration configuration){
this.configuration=configuration;
}
@Override
public <E> List<E> selectList(String statementid, Object... params) throws Exception {
// 获取SimpleExecutor执行器,
SimpleExecutor simpleExecutor = new SimpleExecutor();
//根据statementid,将从configuration中取出对应的配置信息
//这里已经取出关于这个方法的具体SQL信息(mapper解析得到的具体信息)
MappedStatement mappedStatement = configuration.getMappedStatementMap().get(statementid);
System.out.println( mappedStatement+"........."+statementid);
// 然后去调用SimpleExecutor执行器的query方法
List<Object> queryList = simpleExecutor.query(configuration, mappedStatement, params);
return (List<E>) queryList;
}
@Override
public <T> T selectOne(String statementid, Object... params) throws Exception {
List<Object> objects = selectList(statementid, params);
if(objects.size()==1){
return (T) objects.get(0);
}else{
throw new RuntimeException("查询结果为空或者返回值过多");
}
}
@Override
public <T> T getMapper(Class<?> mapperClass) {
// 使用JDK动态代理来为Dao接口生成代理对象,并返回
// 需要三个参数,1、类加载器,2、class数组,3、动态代理必须要实现的接口InvocationHandler
// 这里的加载器是借助本类。 因为InvocationHandler是一个接口,所以要写它的匿名内部类,
// 重写invoke方法,然后生成代理对象(通过快捷字符生成也可以)
Object proxyInstance = Proxy.newProxyInstance(
DefaultSqlSession.class.getClassLoader(),
new Class[]{mapperClass},
new InvocationHandler() {
// proxy当前代理对象的应用,
// method被调用方法的引用
// args传递的参数
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 其实底层里面还是要去执行jdbc代码,最终还是执行SimpleExecutor内的query方法。
// 但是为了不用直接去调用query方法。而是根据不同情况,调用其selectList或selectOne方法
// 因为调用selectList或selectOne方法都行需要参数的,所以先要准备参数
// 为什么要将sql配置文件的id和接口的方法保持一致呢,
// 是因为invoke不能获取映射文件的namespace.id但可以借助method的对象获取其当前执行的方法名,
//和当前方法所在类的其权限类名
//需要的参数:=》sql语句的唯一标识,namespace.id= 接口全限定名.方法名。所以先要去拿这两个名
// 拿到方法名 findAll
String name = method.getName();
// 拿接口的全限类名,(获取该方法所在的类一个源码对象)
String className = method.getDeclaringClass().getName();
// 根据接口名 ,方法名 转为namespace.id (第一个参数OK)
String statementId = className+"."+name;
// 准备参数2 params 其参数会被args参数接收到
// 那么具体该调用那个方法呢,所以要先获取被调用方法的返回值类型
Type genericReturnType = method.getGenericReturnType();
// 对这个类型进行判断,判断是否进行泛型类型参数化
//(也就是判断当前取的值是否有返回值泛型。有则为集合,无则为单个对象)
if(genericReturnType instanceof ParameterizedType){
// 有泛型则为有集合,则用list查询
List<Object> objects = selectList(statementId, args);
return objects;
}
//若无泛型,则为一个实体,则返回selectOne
return selectOne(statementId,args);
}
});
// 并把生成的代理对象进行返回
return (T) proxyInstance;
}
}
测试类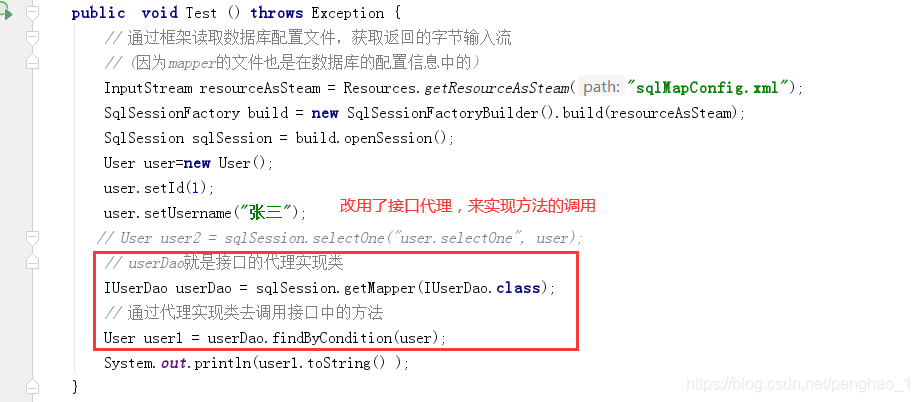

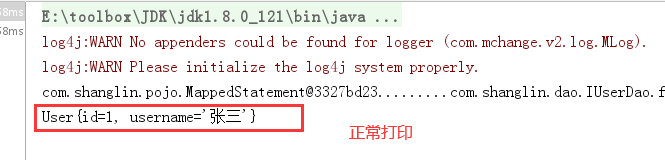

到此,优化完成。

若有收获,就点个赞吧
0 人点赞
