微服务监控之分布式链路追踪技术
分布式链路追踪技术核心思想
本质:记录日志,作为一个完整的技术,分布式链路追踪也有自己的理论和概念
为了追踪整个调用链路,肯定需要记录日志,日志记录是基础 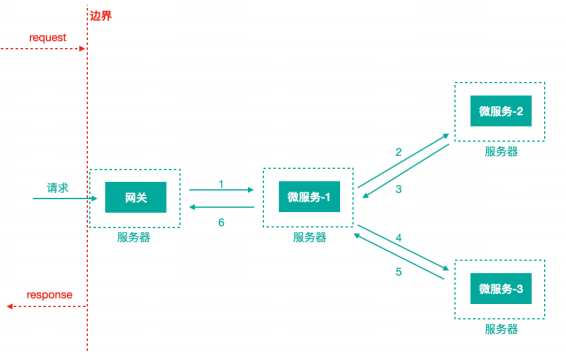
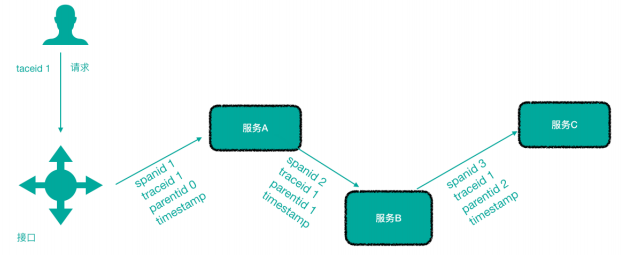
上图标识请求链路,一条链路通过TraceId唯一标识,span标识发起的请求信息,各span通过 parrentId关联起来。
Trace:服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程
Trace ID:为了实现请求跟踪,当请求发送到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识Trace ID,同时在分布式系统内部流转的时候,框架失踪保持该唯一标识,直到返回给请求方,一个Trace由一个或者多个Span组成,每一个Span都有一个SpanId,Span中会记录 TraceId,同时还有一个叫做ParentId,指向了另外一个Span的SpanId,表明父子关系,其实本质表达了依赖关系
Span ID:为了统计各处理单元的时间延迟,当请求到达各个服务组件时,也是通过一个唯一标识Span ID来标记它的开始,具体过程以及结束。对每一个Span来说, 它必须有开始和结束两个节点,通过记录开始Span和结束Span的时间戳,就能统计出该Span的时间延迟,除了时间戳记录之外,它还可以包含一些其他元数据,比如时间名称、请求信息等。 每一个Span都会有一个唯一跟踪标识 Span ID,若一个有序的 span 就组成了一个 trace。
Span可以认为是一个日志数据结构,在一些特殊的时机点会记录了一些日志信息, 比如有时间戳、spanId、TraceId,parentIde等,Span中也抽象出了另外一个概 念,叫做事件,核心事件如下

耗时分析:通过 Sleuth 了解采样请求的耗时,分析服务性能问题(哪些服务调用比较耗时)
链路优化:发现频繁调用的服务,针对性优化等 Sleuth就是通过记录日志的方式来记录踪迹数据的
注意:把Spring Cloud Sleuth 和 Zipkin 一起使用,把Sleuth的数据信息发送给Zipkin进行聚合,利用 Zipkin 存储并展示数据。
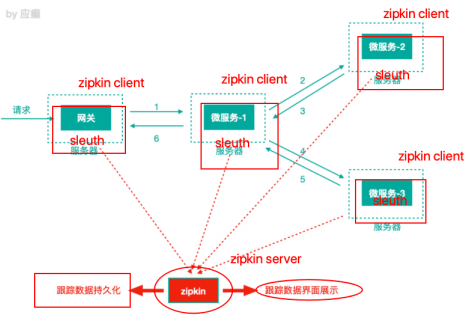
Sleuth + Zipkin 的使用
1、需要追踪的服务引入依赖(Sleuth)
每一个需要被追踪踪迹的微服务工程都引入依赖坐标
<!--链路追踪--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId></dependency>
2、服务配置文件需增加日志级别
在控制台可以观察到 Sleuth 输出的日志(全局 TraceId、SpanId 等),但是不容易阅读观察,另外⽇志分散在各个微服务服务器上
logging:level:# Feign日志只会对日志级别为debug的做出响应com.lagou.edu.controller.service.ResumeServiceFeignClient: debugorg.springframework.web.servlet.DispatcherServlet: debugorg.springframework.cloud.sleuth: debug
3、结合 Zipkin 展示追踪数
Zipkin 包括Zipkin Server和 Zipkin Client两部分,Zipkin Server是一个单独的服务,Zipkin Client就是具体的微服务。(要求被追踪的各个微服务都需要添加Zipkin Client)
Zipkin Server 构建(S)
<!--zipkin-server的依赖坐标--><dependency><groupId>io.zipkin.java</groupId><artifactId>zipkin-server</artifactId><version>2.12.3</version><exclusions><!--排除掉log4j2的传递依赖,避免和springboot依赖的日志组件冲突--><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId></exclusion></exclusions></dependency><!--zipkin-server ui界面依赖坐标--><dependency><groupId>io.zipkin.java</groupId><artifactId>zipkin-autoconfigure-ui</artifactId><version>2.12.3</version></dependency>
启动类开启Zipkin Server功能 (S)
@SpringBootApplication@EnableZipkinServer // 开启Zipkin 服务器功能public class ZipkinServerApplication9411 {public static void main(String[] args) {SpringApplication.run(ZipkinServerApplication9411.class,args);}}
添加配置文件application.yml(S)
server:port: 9411management:metrics:web:server:auto-time-requests: false # 关闭自动检测
Zipkin Client 构建(C)
( 在具体微服务中修改, 在pom中添加 zipkin 依赖 )
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId></dependency>
配置文件添加对zipkin server的引用(C)
改客户端微服务是lagou-service-autodeliver-8096,对应的服务名称是lagou-service-autodeliver
spring:application:name: lagou-service-autodeliverzipkin:base-url: http://127.0.0.1:9411 # zipkin server的请求地址sender:# web 客户端将踪迹日志数据通过网络请求的方式传送到服务端,另外还有配置# kafka/rabbit 客户端将踪迹日志数据传递到mq进行中转type: websleuth:sampler:# 采样率 1 代表100%全部采集 ,默认0.1 代表10% 的请求踪迹数据会被采集# 生产环境下,请求量非常大,没有必要所有请求的踪迹数据都采集分析,对于网络包括server端压力都是比较大的,可以配置采样率采集一定比例的请求的踪迹数据进行分析即可probability: 1
另外,对于log日志,依然保持开启debug状态
Zipkin server 页面方便我们查看服务调用依赖关系及一些性能指标和异常信息
追踪数据Zipkin持久化到mysql (S)
mysql中创建名称为zipkin的数据库,并执行如下sql语句(官方提供)
需要创建zipkin的数据库
pom中引入相关依赖
<!--zipkin针对mysql持久化的依赖--><dependency><groupId>io.zipkin.java</groupId><artifactId>zipkin-autoconfigure-storage-mysql</artifactId><version>2.12.3</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.10</version></dependency><!--操作数据库需要事务控制--><dependency><groupId>org.springframework</groupId><artifactId>spring-tx</artifactId></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId></dependency>
ZipkinServer配置文件添加数据连接(S)
添加链接数据库的配置信息
spring:datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/zipkin?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowMultiQueries=trueusername: rootpassword: 123456druid:initialSize: 10minIdle: 10maxActive: 30maxWait: 50000# 指定zipkin持久化介质为mysqlzipkin:storage:type: mysql
启动类中注入事务管理器(S)
// 注入事务控制器@Beanpublic PlatformTransactionManager transactionManager(DataSource dataSource) {return new DataSourceTransactionManager(dataSource);}
zipkin-server 完整的配置信息
server:port: 9411management:metrics:web:server:auto-time-requests: false # 关闭自动检测spring:datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/zipkin?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowMultiQueries=trueusername: rootpassword: 123456druid:initialSize: 10minIdle: 10maxActive: 30maxWait: 50000# 指定zipkin持久化介质为mysqlzipkin:storage:type: mysql
zipkin-server 完整的启动类信息
@SpringBootApplication@EnableZipkinServer // 开启Zipkin 服务器功能public class ZipkinServerApplication9411 {public static void main(String[] args) {SpringApplication.run(ZipkinServerApplication9411.class,args);}// 注入事务控制器@Beanpublic PlatformTransactionManager transactionManager(DataSource dataSource) {return new DataSourceTransactionManager(dataSource);}}
完整的思路是:引入坐标、开启功能、添加事物、添加数据连接等。

若有收获,就点个赞吧
0 人点赞
