hook函数概念
作用:特征图,非叶子节点的梯度在运算过程中会被自动释放。如果需要提取这些变量,就要用到hook函数。
机制:不改变主体,实现额外功能,像一个挂件,挂钩,hook。
张量的hook函数
Tensor.register_hook

功能:注册一个反向传播hook函数。
注意:
- Hook函数仅有一个输入参数:张量的梯度
- 返回值可以是Tensor或者None,当为Tensor时会修改原本的梯度值为Tensor
简单的说就是在提取梯度的时候,要自己定义个hook函数F,然后把这个F作为参数传入到register_hook**里面。这样网络在反向传播时就会额外地执行该hook函数定义的功能。
其中函数F的输入参数为梯度。
w = torch.tensor([1.], requires_grad=True)x = torch.tensor([2.], requires_grad=True)a = torch.add(w, x)b = torch.add(w, 1)y = torch.mul(a, b)a_grad = list()def grad_hook(grad):grad *= 2return grad*3 # 注意这里的returnhandle = w.register_hook(grad_hook)y.backward()# 查看梯度print("w.grad: ", w.grad)handle.remove()
hook中使用return修改了w的梯度。
Module的hook函数
Module.register_forward_hook

功能:注册module的前向传播hook函数,以此来获取卷积输出的特征图。
参数:
- module:当前网络层
- input:当前网络层输入数据
- output:当前网络层输出数据
Module.register_forward_pre_hook

功能:注册module前向传播前的hook函数,此时还没有输出,可以查看网络层
参数:
- module:当前网络层
- input:当前网络层输入数据
Module.register_backward_hook

功能:注册module反向传播的hook函数
参数:
- module:当前网络层
- grad_input:当前网络层输入梯度数据
- grad_output:当前网络层输出梯度数据
代码实现
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
return x
def forward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
def forward_pre_hook(module, data_input):
print("forward_pre_hook input:{}".format(data_input))
def backward_hook(module, grad_input, grad_output):
print("backward hook input:{}".format(grad_input))
print("backward hook output:{}".format(grad_output))
# 初始化网络
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# 注册hook
fmap_block = list()
input_block = list()
net.conv1.register_forward_hook(forward_hook)
net.conv1.register_forward_pre_hook(forward_pre_hook)
net.conv1.register_backward_hook(backward_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
loss_fnc = nn.L1Loss()
target = torch.randn_like(output)
loss = loss_fnc(target, output)
loss.backward()
实现流程分析
第一步 定义hook函数
def forward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
def forward_pre_hook(module, data_input):
print("forward_pre_hook input:{}".format(data_input))
def backward_hook(module, grad_input, grad_output):
print("backward hook input:{}".format(grad_input))
print("backward hook output:{}".format(grad_output))
第二步 给网络层注册hook
fmap_block = list()
input_block = list()
net.conv1.register_forward_hook(forward_hook)
net.conv1.register_forward_pre_hook(forward_pre_hook)
net.conv1.register_backward_hook(backward_hook)
第三步 前向传播
output = net(fake_img)
3.1 因为net继承自Module基类,所以进入Module的call函数,执行net的forward函数
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
return x
3.2 因为Conv1继承自Module基类,所以进入Module的call函数:
Module类的call函数分为四部分:
3.2.1 第一个是检测是否有注册_forward_pre_hooks,
for hook in self._forward_pre_hooks.values():
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
有的话就会进入自定义的hook函数执行:
def forward_pre_hook(module, data_input):
print("forward_pre_hook input:{}".format(data_input))
3.2.2 第二个是执行_slow_forward或forward函数
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
3.2.3 第三个是检测是否有注册_forward_hooks
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
有的话就会进入自定义的hook函数执行:
def forward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
3.2.4 第四个是检测是否有注册_backward_hooks
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
有的话就会进入自定义的hook函数执行:
def backward_hook(module, grad_input, grad_output):
print("backward hook input:{}".format(grad_input))
print("backward hook output:{}".format(grad_output))
AlexNet特征图可视化
writer = SummaryWriter(comment='test_your_comment',
filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "./lena.png" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
alexnet = models.alexnet(pretrained=True)
# 注册hook
fmap_dict = dict()
for name, sub_module in alexnet.named_modules():
if isinstance(sub_module, nn.Conv2d):
key_name = str(sub_module.weight.shape)
fmap_dict.setdefault(key_name, list())
n1, n2 = name.split(".")
def hook_func(m, i, o):
key_name = str(m.weight.shape)
fmap_dict[key_name].append(o)
alexnet._modules[n1]._modules[n2].register_forward_hook(hook_func)
# forward
output = alexnet(img_tensor)
# add image
for layer_name, fmap_list in fmap_dict.items():
fmap = fmap_list[0]
fmap.transpose_(0, 1) # 1*C*H*W -> C*1*H*W
nrow = int(np.sqrt(fmap.shape[0]))
fmap_grid = vutils.make_grid(fmap, normalize=True, scale_each=True, nrow=nrow)
writer.add_image('feature map in {}'.format(layer_name), fmap_grid, global_step=322)
第一层的feature map可视化如下:
发现使用hook获得的特征图与上一节单独取出网络层输出的特征图可视化效果不一样,这是由于这里有激活函数。
注意力可视化
CAM(class activation map,类激活图)
CAM文献:《Learning Deep Features for Discriminative Localization》
功能:通过可视化,分析卷积神经网络做出分类判断的依据是什么。
例如下图将图片输入网络进行分类。我们想知道网络是从图像中的哪些信息从而将其归类为Australian terrier,就可以用CAM进行可视化: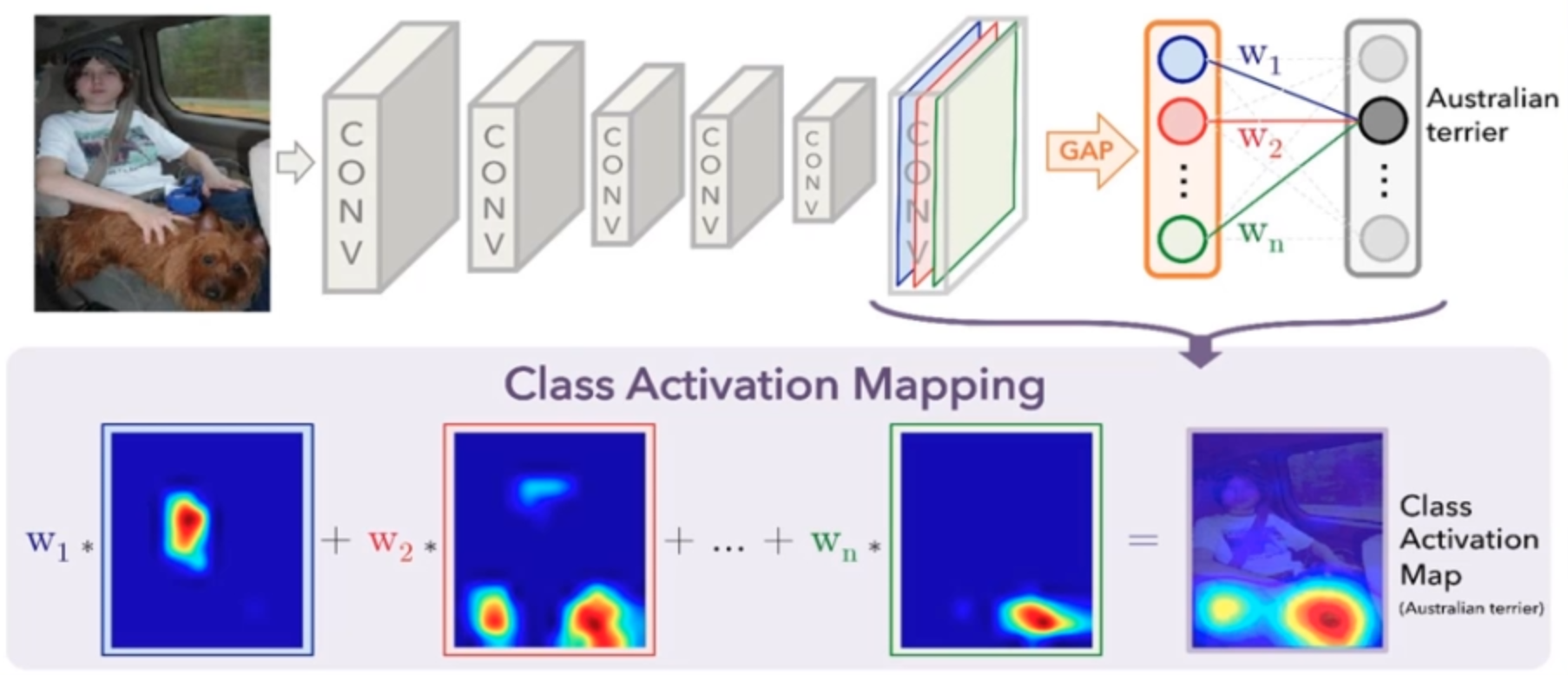
算法思想
CAM的思想就是对模型的最后一层特征图进行加权求和,类似注意力机制,从而观察模型更关注图像的哪个位置。
如何获得上述 就是该算法的关键:先对最后一层的特征图进行GAP(global average pooling,全局平均池化),将每张图转化为一个神经元,最后连接一个FC层进行分类。这里最后分类结果为Australian terrier,那么与该神经元连接的权重就是加权求和的。
就是该算法的关键:先对最后一层的特征图进行GAP(global average pooling,全局平均池化),将每张图转化为一个神经元,最后连接一个FC层进行分类。这里最后分类结果为Australian terrier,那么与该神经元连接的权重就是加权求和的。
缺点
我们在分析网络的时候,如果要使用CAM可视化,就必须在网络最后输出部分接上一个GAP操作,再重新进行训练。
针对上面的缺点,有一个新的解决方案:
Grad-CAM
是CAM的改进版,利用梯度作为特征图权重,无需改动和重新训练网络模型
参考文献:Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization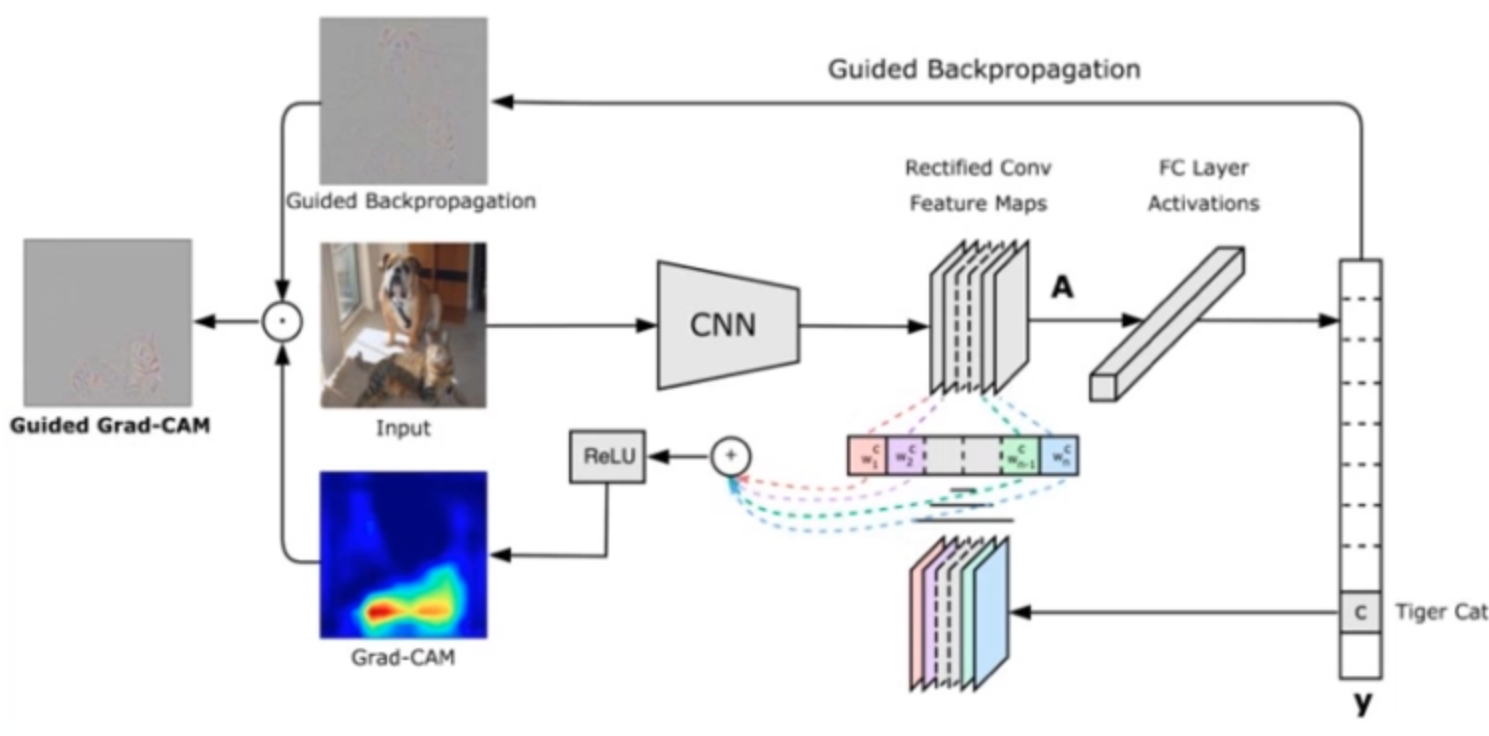
算法思想
上图中间部分就是原网络模型结构。y是模型的分类向量[0,0,…,1,0],然后对y这个向量进行backward,也就是对特征图A求梯度,得到一个梯度的feature map(图中彩色部分),其中每个像素对应原特征图每个像素的梯度。接着对这个feature map求平均值,也就是这个梯度的feature map中的一张图得到一个平均的权重。最后就得到了原feature map的权重。
拿到权重后,就跟CAM一样对feature map进行加权平均,再经过一个ReLU函数,就得到了Grad-CAM的类激活图。
优点
具有普适性,只要模型可以输出分类向量或概率向量就可以使用。而不用修改网络,也不用重新训练网络。
分析与代码
https://zhuanlan.zhihu.com/p/75894080
总结:Grad-CAM可以让我们知道模型是否正确的学习到具体对象的特征。显然从上面的实验可以看出该模型只是学到了汽车、飞机、船的背景信息从而做出分类的判断。

若有收获,就点个赞吧
0 人点赞
