简介
TensorBoard是TensorFlow中强大的可视化工具。
支持标量、图像、文本、音频、视频和Eembedding等多种数据可视化。
运行机制
- 首先在Python脚本中记录要可视化的数据
- 上面的数据会以eventfile的形式存储在硬盘中
- 在终端使用TensorBoard读取eventfile这一数据类型,对其进行可视化
- 在web端打开可视化界面
代码实现
第一步 安装TensorBoard模块
pip install tensorboard
第二步 在Python脚本中记录要可视化的数据:
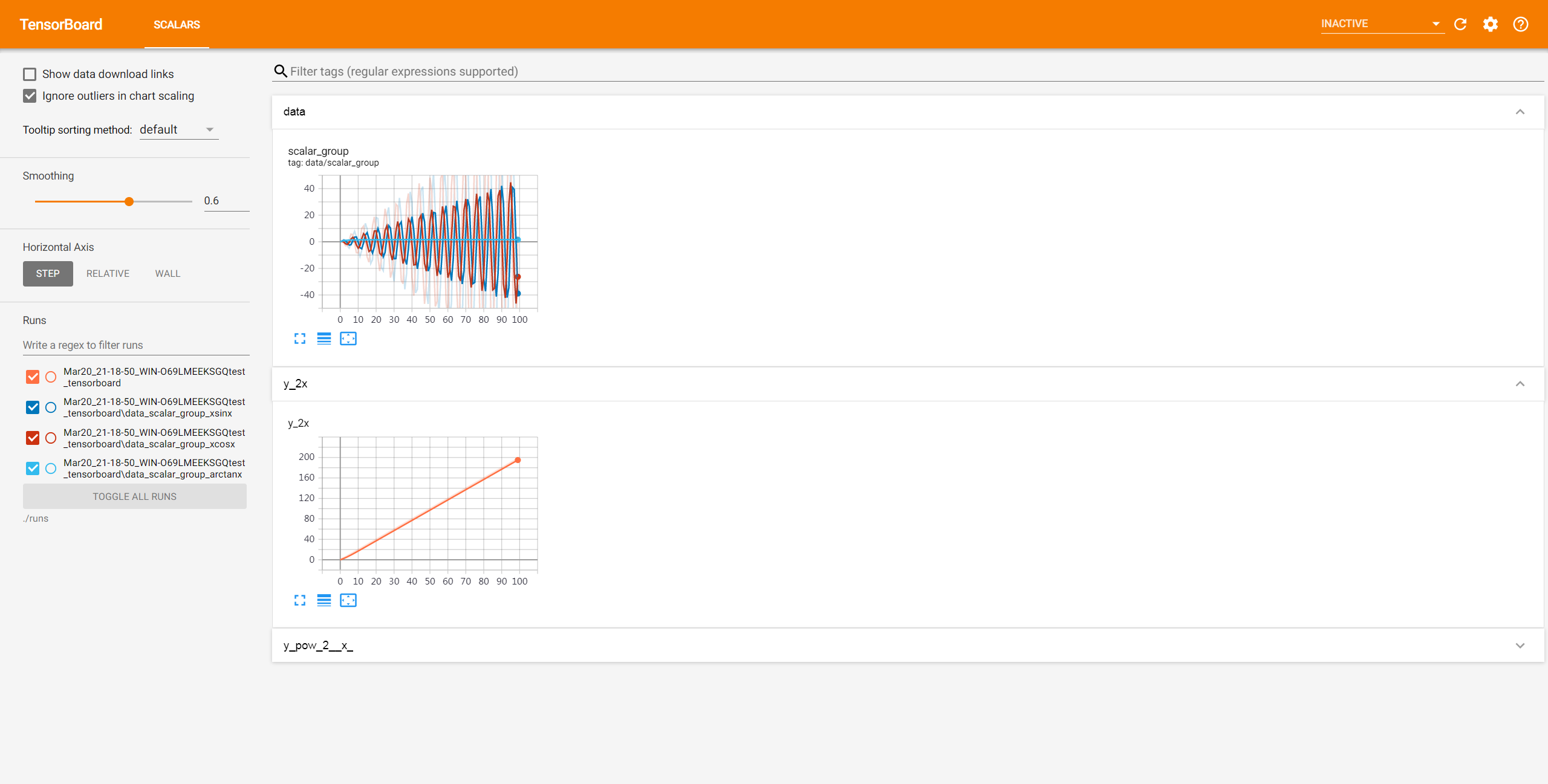
import numpy as npfrom torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter(comment='test_tensorboard')for x in range(100):writer.add_scalar('y=2x', x * 2, x)writer.add_scalar('y=pow(2, x)', 2 ** x, x)writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),"xcosx": x * np.cos(x),"arctanx": np.arctan(x)}, x)writer.close()
第三步 在终端内输入命令行,用TensorBoard读取eventfile
tensorboard --logdir=./runs
注意这里logdir填写的目录为要可视化的eventfile所在的文件夹。
运行结果:
**
第四步 打开链接进入可视化Web界面
SummaryWriter
功能:提供创建event file的高级接口
主要属性:
- log_dir:event file输出文件夹,默认是不指定。
- 如果不指定log_dir,就会在py文件的当前文件夹下面创建一个runs文件夹,在文件夹下面会有一系列文件夹XXX(时间、主机名等),然后再下面才是event file文件YYY;
- 如果指定log_dir,那么下面的comment参数就不会生效。并且eventfile就会出现在log_dir指定的目录里。
- 通常要设置log_dir的。把代码和数据分开可以便于管理。
- comment:不指定log_dir时,文件夹后缀,就是上面XXX的后缀
- filename_suffix:event file文件名后缀,就是上面YYY的后缀
logdir="./train_log/test_log dir"writer=Summarywriter(log dir=log dir, comment='_scalars', filename_suffix="12345678")
1. add_scalar()
功能:记录标量
- tag:图像的标签名,图的唯一标识。在图像title的位置
- scalar_value:要记录的标量,可以看作y轴
- global_step:x轴
2. add_scalars()
功能:绘制多条曲线,例如对比训练集和验证集上的Accuracy曲线
- main_tag:该图的标签,同上面的tag。
- tag_scalar_dict:用字典的形式来记录多条曲线
- 字典中的key是变量的tag,value是变量的值
- global_step:x轴
max_epoch = 100writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")for x in range(max_epoch):writer.add_scalar('y=2x', x * 2, x)writer.add_scalar('y=pow_2_x', 2 ** x, x)writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),"xcosx": x * np.cos(x)}, x)writer.close()
3. add_histogram()
功能:绘制统计直方图与多分位数折线图
- tag:图像的标签名,图的唯一标识
- values:要统计的参数
- global_step: y轴。在可视化结果中表示的就是第几个epoch。
- bins:取直方图的bins
代码例子
结合上述三种方法,对训练集和验证集的Loss和Accuracy分别绘制曲线;对参数及其梯度绘制直方图:
# ============================ step 5/5 训练 ============================train_curve = list()valid_curve = list()iter_count = 0# 构建 SummaryWriterwriter = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")for epoch in range(MAX_EPOCH):loss_mean = 0.correct = 0.total = 0.net.train()for i, data in enumerate(train_loader):iter_count += 1# forwardinputs, labels = dataoutputs = net(inputs)# backwardoptimizer.zero_grad()loss = criterion(outputs, labels)loss.backward()# update weightsoptimizer.step()# 统计分类情况_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).squeeze().sum().numpy()# 打印训练信息loss_mean += loss.item()train_curve.append(loss.item())if (i+1) % log_interval == 0:loss_mean = loss_mean / log_intervalprint("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))loss_mean = 0.# 记录数据,保存于event filewriter.add_scalars("Loss", {"Train": loss.item()}, iter_count)writer.add_scalars("Accuracy", {"Train": correct / total}, iter_count)# 每个epoch,记录梯度,权值for name, param in net.named_parameters(): # 该方法可以读取模型的参数及其参数名writer.add_histogram(name + '_grad', param.grad, epoch)writer.add_histogram(name + '_data', param, epoch)scheduler.step() # 更新学习率# validate the modelif (epoch+1) % val_interval == 0:correct_val = 0.total_val = 0.loss_val = 0.net.eval()with torch.no_grad():for j, data in enumerate(valid_loader):inputs, labels = dataoutputs = net(inputs)loss = criterion(outputs, labels)_, predicted = torch.max(outputs.data, 1)total_val += labels.size(0)correct_val += (predicted == labels).squeeze().sum().numpy()loss_val += loss.item()valid_curve.append(loss.item())print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val, correct / total))# 记录数据,保存于event filewriter.add_scalars("Loss", {"Valid": np.mean(valid_curve)}, iter_count)writer.add_scalars("Accuracy", {"Valid": correct / total}, iter_count)train_x = range(len(train_curve))train_y = train_curvetrain_iters = len(train_loader)valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterationsvalid_y = valid_curveplt.plot(train_x, train_y, label='Train')plt.plot(valid_x, valid_y, label='Valid')plt.legend(loc='upper right')plt.ylabel('loss value')plt.xlabel('Iteration')plt.show()
在训练时对Accuracy、loss、参数进行可视化,可以在Accuracy不上升或者loss不下降时分析问题所在。
例如上面实验结果中,第一层weight的梯度在最后几个epoch中变得非常小: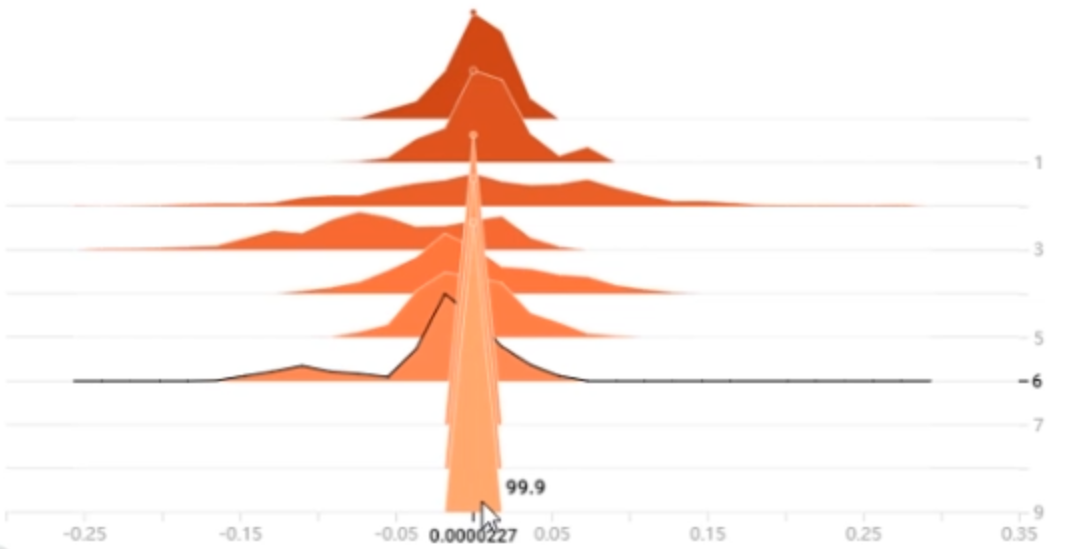
这有可能是产生了梯度消失,那么我们就去观察一下最后一层的参数梯度可视化结果: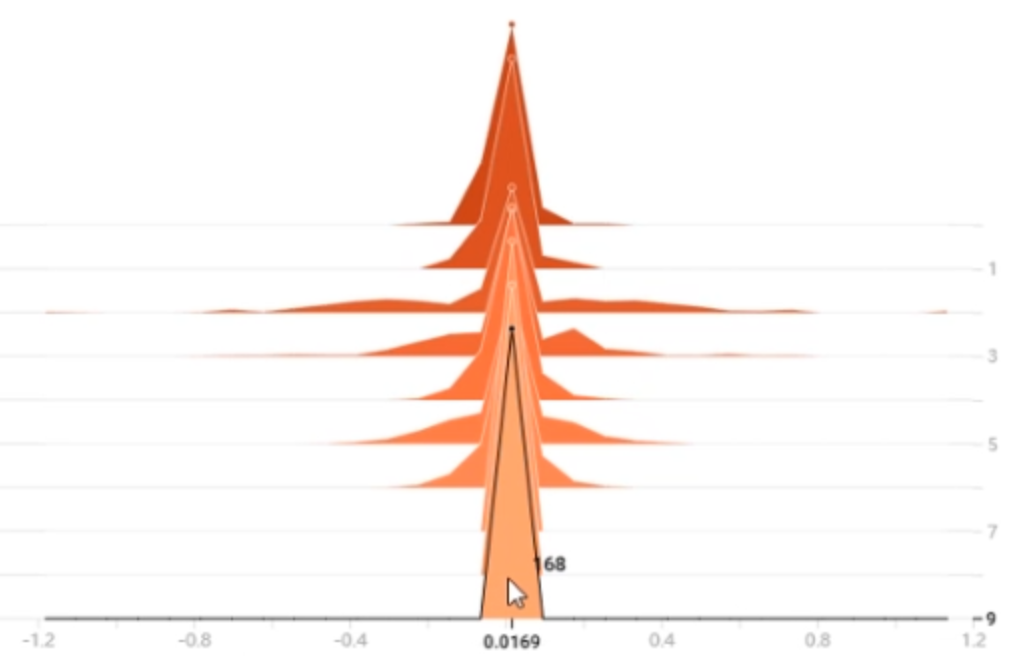
发现最后一层的参数梯度也很小,那么就不是梯度消失的问题。再观察Loss变化曲线: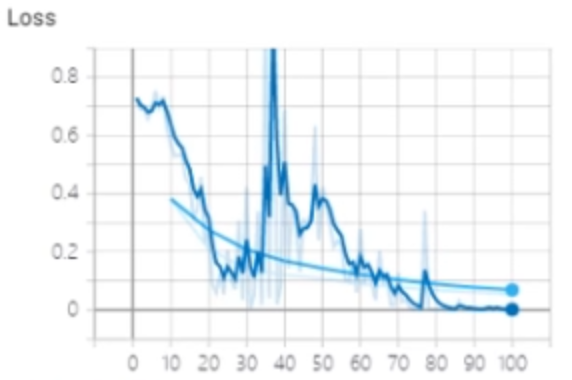
因此我们知道最后几个epoch时参数梯度很小的原因是此时loss变得很小,所以计算出来的梯度自然也很小。
这里注意,如果上面观察最后一层的参数梯度时发现尺度还很大,那么就是发生了梯度消失:反向传播时链式法则求导使得梯度传到最前面变得很小了。
所以当参数的分布或者参数的梯度尺度变得不正常,且模型的性能指标不再上升时,我们就可以分析是训练中出现了什么问题所导致的。
4. add_image()

功能:记录图像
主要参数:
- tag:图像的标签名,图的唯一标识
- img_tensor:图像数据,注意尺度。
- 因为图像输入网络要转化为torch.float类型的张量,所以尺度可能是0~1的。
- 当输入的数据都是0~1区间,则会把数据都乘以255,将尺度变为0~255区间。
- 如果数据区间超过了0~1,那么就默认把其当作是0~255区间。
- global_step:x轴
- dataformats:数据形式,包括CHW,HWC,HW(灰度图),默认为CHW。
5.torchvision.vutils.make_grid
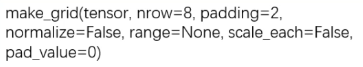
功能:制作网格图像(就是一个坐标轴里面显示多个图片)
主要参数:
- tensor:图像数据,BCHW形式,其中B是batchsize
- nrow:行数(列数会自动计算)
- padding:网格图像之间的间距(像素单位)
- normalize:是否将像素值标准化(根据数据的区间来设置)
- range:标准化范围
- scale_each:是否单张图维度标准化
- pad_value:padding的像素值
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
# train_dir = "path to your training data"
transform_compose = transforms.Compose([transforms.Resize((32, 64)), transforms.ToTensor()])
train_data = RMBDataset(data_dir=train_dir, transform=transform_compose)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
data_batch, label_batch = next(iter(train_loader))
# img_grid = vutils.make_grid(data_batch, nrow=4, normalize=True, scale_each=True)
img_grid = vutils.make_grid(data_batch, nrow=4, normalize=False, scale_each=False)
writer.add_image("input img", img_grid, 0)
writer.close()
6. add_graph()

功能:可视化模型计算图
- model:模型,必须是nn.Module
- input_to_model:输入给模型的数据
- verbose:是否打印计算图结构信息。
注意:这个功能Pytorch1.2版本有bug,1.3版本才能用。可以用conda额外配置一个Pytorch1.3的虚拟环境。
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 模型
fake_img = torch.randn(1, 3, 32, 32)
lenet = LeNet(classes=2)
writer.add_graph(lenet, fake_img)
writer.close()
可视化结果: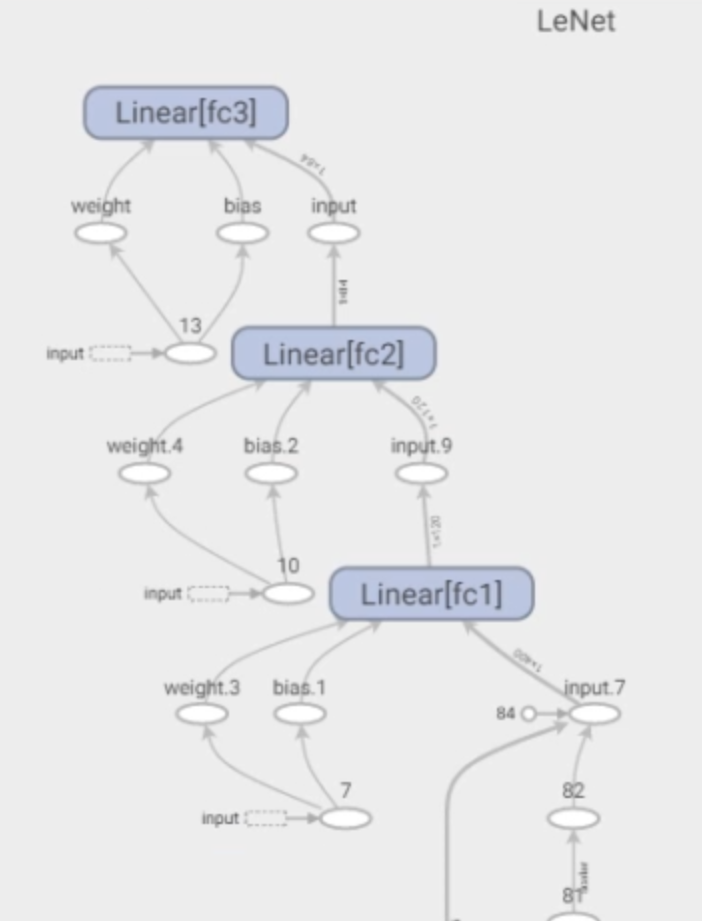
通常我们对计算图并不是很关心,只有在深入Debug时才会需要。我们更多关心模型的输入和参数等信息,那么就需要用到下面的工具:
7. torchsummary

功能:查看模型信息,便于调试
- model:pytorch模型
- input_size:模型输入size
- batch_size:batch size。可以用默认的-1.
- device:“cuda”or“cpu”
注意:torchsummary是github上的一个工具包,需要pip额外安装。
github地址:https://github.com/sksq96/pytorch-summary
lenet = LeNet(classes=2)
from torchsummary import summary
print(summary(lenet, (3, 32, 32), device="cpu"))
运行结果:
AlexNet卷积核与特征图可视化
卷积核可视化
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
alexnet = models.alexnet(pretrained=True)
kernel_num = -1
vis_max = 1
for sub_module in alexnet.modules():
if isinstance(sub_module, nn.Conv2d):
kernel_num += 1
if kernel_num > vis_max:
break
kernels = sub_module.weight
c_out, c_int, k_w, k_h = tuple(kernels.shape)
# 将一个卷积核的3个channel分开展示
for o_idx in range(c_out):
kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1)
# make_grid需要 BCHW,这里拓展C维度,变成C*1*H*W
kernel_grid = vutils.make_grid(kernel_idx, normalize=True, scale_each=True, nrow=c_int)
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)
# 对卷积核总体展示
kernel_all = kernels.view(-1, 3, k_h, k_w) # 3, h, w
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, w
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=322)
print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))
writer.close()
特征图可视化
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 数据
path_img = "./lena.png" # your path to image
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
if img_transforms is not None:
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 模型
alexnet = models.alexnet(pretrained=True)
# forward
convlayer1 = alexnet.features[0]
fmap_1 = convlayer1(img_tensor)
# 预处理
fmap_1.transpose_(0, 1) # bchw=(1, 64, 55, 55) --> (64, 1, 55, 55)
# 因为下面要对每个channel可视化,所以把C换到第0维
fmap_1_grid = vutils.make_grid(fmap_1, normalize=True, scale_each=True, nrow=8)
writer.add_image('feature map in conv1', fmap_1_grid, global_step=322)
writer.close()

若有收获,就点个赞吧
0 人点赞
