Regularization
Regularization:减小方差(防止过拟合)的策略。
下面来看下方差是什么东西。以下概念来自《西瓜书》:
误差可分解为:偏差,方差与噪声之和。即误差=偏差+方差+噪声之和
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界
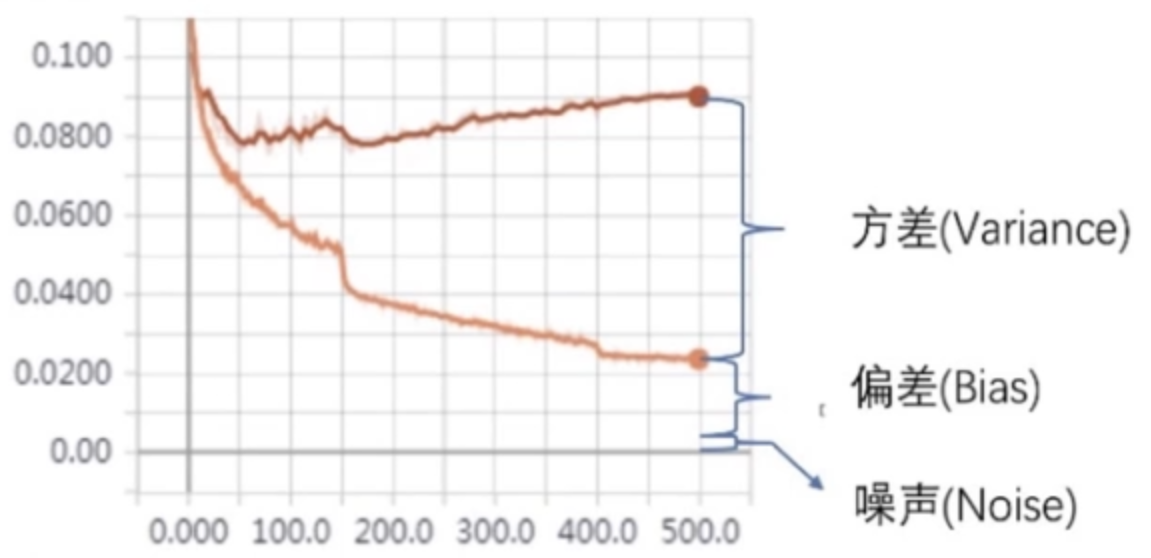
在机器学习中,我们认为训练集和验证集的差距就是方差,它刻画了数据扰动对模型造成的影响。
而Regularization就是为了解决方差过大的问题,也就是防止模型过拟合。
L1、L2正则化
首先我们知道目标函数为:
下面对Cost函数和正则化项绘制等高线图,这里我们假设Cost和正则项的等高线都是向外逐渐变小的,否则没有讨论的意义,直接取等高线中心就可以使Obj最小了: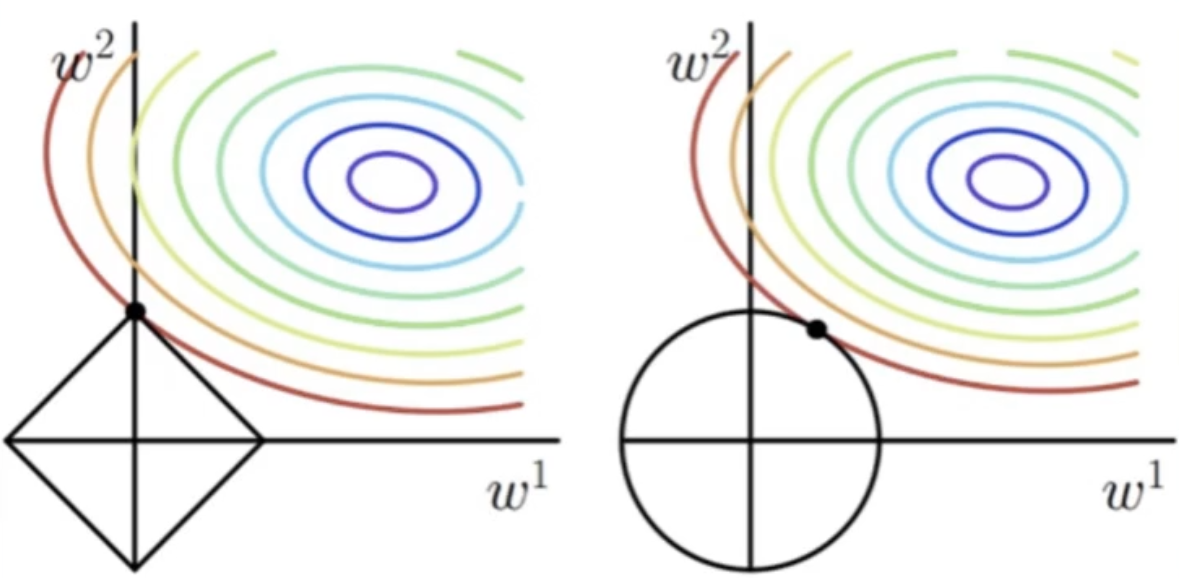
左边是L1,右边是L2对应的等高线图(假设只有 两个权重参数)
两个权重参数)
上图中,彩色的圈是Cost的等高线,黑色的圈是正则化项的等高线。
因为同一条等高线上的值都是相等的。所以我们要最小化目标函数,就意味着要在最小化Cost的同时最小化正则化项。
L1正则化
L1正则项为 。
。
所以此时,假设Cost已经优化到一个固定的值(例如在红线上),现在要确定的解,那么参数的解一般都会取到坐标轴上的交点(这样正则化项最小),如上图所示。
因此L1正则化会使某些w置0,得到稀疏解。比如上图中 。
。
L2正则化(权值衰减)
L2正则化也称作权值衰减,是较为常用的正则化方法。L2正则项为 。
。
同上面的推导一样,要使Loss和L1都尽量小,就会取到如上图所示的交点,这样会使w1、w2都较小,而不是某一个权值较大。控制权值的值较小可以防止模型变得复杂,从而预防过拟合。这也就是正则化的意义。
下面来看L2正则化为什么称作权值衰减,这里假设只看一个样本的一个权值w:
则计算目标函数有:
则此时w的权重更新公式为:
而我们知道如果没有正则项,权重更新公式为:
因为 ,所以我们知道L2正则化会使权重不断衰减。
,所以我们知道L2正则化会使权重不断衰减。
代码实现
Pytorch的优化器中提供了L2正则化(weight decay)的方法,只需要给定超参 :
:
set_seed(1) # 设置随机种子n_hidden = 200max_iter = 2000disp_interval = 200lr_init = 0.01# ============================ step 1/5 数据 ============================def gen_data(num_data=10, x_range=(-1, 1)):w = 1.5train_x = torch.linspace(*x_range, num_data).unsqueeze_(1) # 这里tuple前加*可以把tuple拆解开train_y = w*train_x + torch.normal(0, 0.5, size=train_x.size())test_x = torch.linspace(*x_range, num_data).unsqueeze_(1)test_y = w*test_x + torch.normal(0, 0.3, size=test_x.size())return train_x, train_y, test_x, test_ytrain_x, train_y, test_x, test_y = gen_data(x_range=(-1, 1))# ============================ step 2/5 模型 ============================class MLP(nn.Module):def __init__(self, neural_num):super(MLP, self).__init__()self.linears = nn.Sequential(nn.Linear(1, neural_num),nn.ReLU(inplace=True),nn.Linear(neural_num, neural_num),nn.ReLU(inplace=True),nn.Linear(neural_num, neural_num),nn.ReLU(inplace=True),nn.Linear(neural_num, 1),)def forward(self, x):return self.linears(x)net_normal = MLP(neural_num=n_hidden)net_weight_decay = MLP(neural_num=n_hidden)# ============================ step 3/5 优化器 ============================optim_normal = torch.optim.SGD(net_normal.parameters(), lr=lr_init, momentum=0.9)optim_wdecay = torch.optim.SGD(net_weight_decay.parameters(), lr=lr_init, momentum=0.9, weight_decay=1e-2)# ============================ step 4/5 损失函数 ============================loss_func = torch.nn.MSELoss()# ============================ step 5/5 迭代训练 ============================writer = SummaryWriter(comment='_test_tensorboard', filename_suffix="12345678")for epoch in range(max_iter):# forwardpred_normal, pred_wdecay = net_normal(train_x), net_weight_decay(train_x)loss_normal, loss_wdecay = loss_func(pred_normal, train_y), loss_func(pred_wdecay, train_y)optim_normal.zero_grad()optim_wdecay.zero_grad()loss_normal.backward()loss_wdecay.backward()optim_normal.step()optim_wdecay.step()if (epoch+1) % disp_interval == 0:# 可视化for name, layer in net_normal.named_parameters():writer.add_histogram(name + '_grad_normal', layer.grad, epoch)writer.add_histogram(name + '_data_normal', layer, epoch)for name, layer in net_weight_decay.named_parameters():writer.add_histogram(name + '_grad_weight_decay', layer.grad, epoch)writer.add_histogram(name + '_data_weight_decay', layer, epoch)test_pred_normal, test_pred_wdecay = net_normal(test_x), net_weight_decay(test_x)# 绘图plt.scatter(train_x.data.numpy(), train_y.data.numpy(), c='blue', s=50, alpha=0.3, label='train')plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='red', s=50, alpha=0.3, label='test')plt.plot(test_x.data.numpy(), test_pred_normal.data.numpy(), 'r-', lw=3, label='no weight decay')plt.plot(test_x.data.numpy(), test_pred_wdecay.data.numpy(), 'b--', lw=3, label='weight decay')plt.text(-0.25, -1.5, 'no weight decay loss={:.6f}'.format(loss_normal.item()), fontdict={'size': 15, 'color': 'red'})plt.text(-0.25, -2, 'weight decay loss={:.6f}'.format(loss_wdecay.item()), fontdict={'size': 15, 'color': 'red'})plt.ylim((-2.5, 2.5))plt.legend(loc='upper left')plt.title("Epoch: {}".format(epoch+1))plt.show()plt.close()
注意在第67行的
optim_wdecay.step()
会进入SGD的step函数:
def step(self, closure=None):
"""Performs a single optimization step.
Arguments:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
if weight_decay != 0:
d_p.add_(weight_decay, p.data)
if momentum != 0:
param_state = self.state[p]
if 'momentum_buffer' not in param_state:
buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()
else:
buf = param_state['momentum_buffer']
buf.mul_(momentum).add_(1 - dampening, d_p)
if nesterov:
d_p = d_p.add(momentum, buf)
else:
d_p = buf
p.data.add_(-group['lr'], d_p)
return loss
在step函数中,判断是否使用weight_decay,有的话就对参数的梯度进行上述的数学公式计算:
d_p.add_(weight_decay, p.data) # d_p = d_p + weight_decay*p.data
也就是:
最后执行梯度更新
p.data.add_(-group['lr'], d_p)
也就是:
运行结果:使用权值衰减前后的变化如下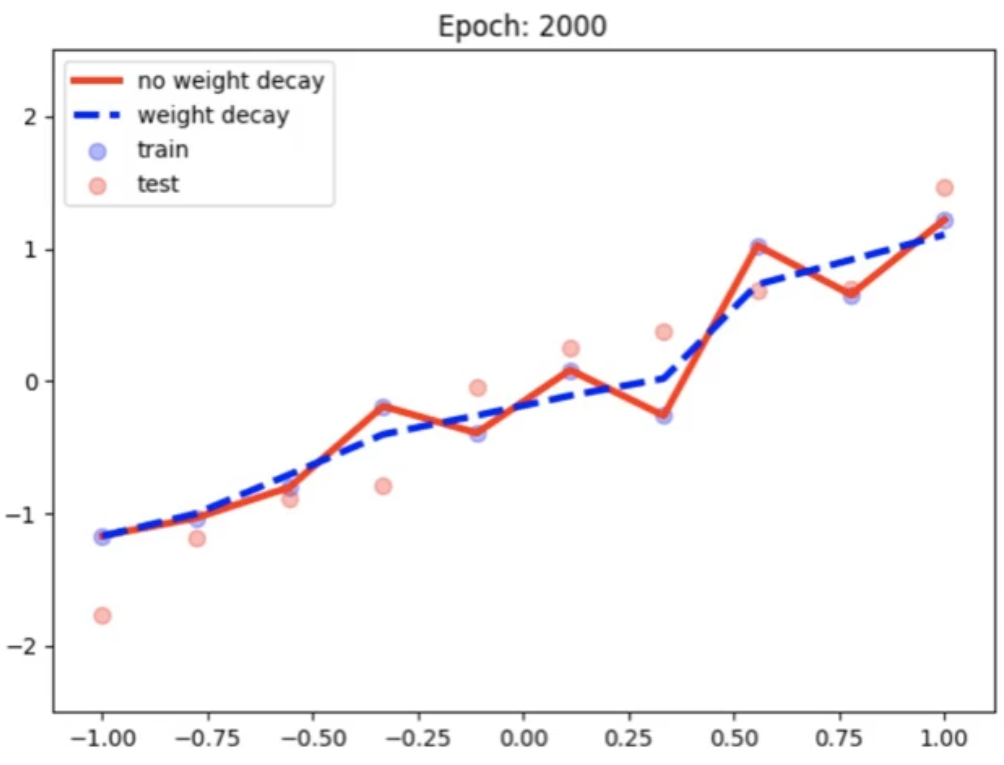
可以看到使用weight decay后有效地防止了模型的过拟合。
使用TensorBoard观察权重分布,这是没使用weight decay的: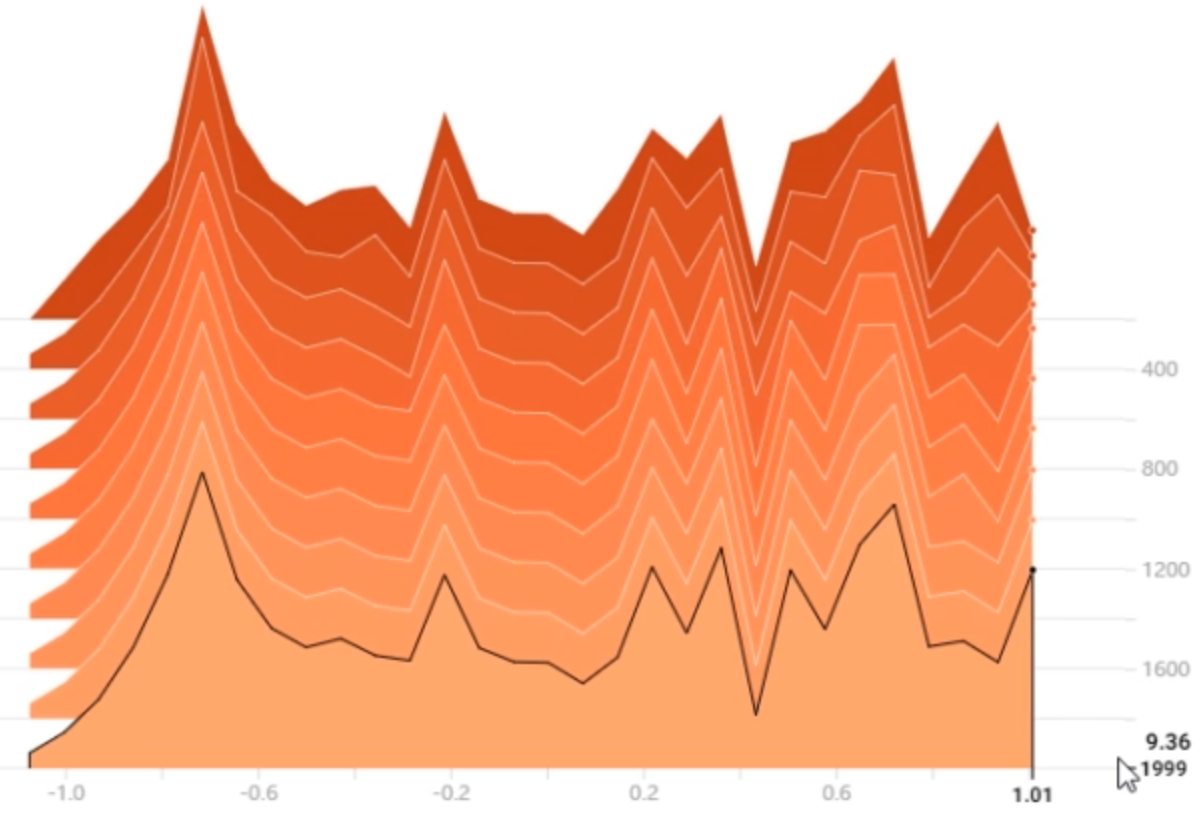
下面是使用了weight decay的权重分布
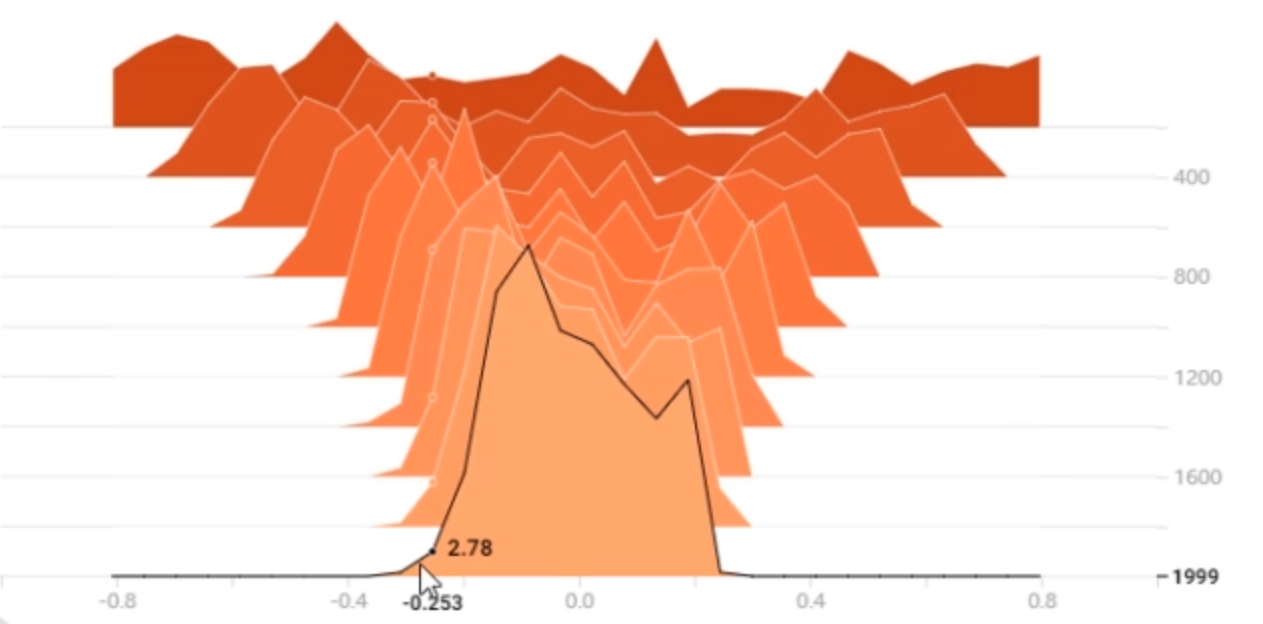
可以知道weight decay有效地限制了权重的尺度大小,防止模型变得复杂从而导致过拟合。
Dropout(随机失活)
简单又有效的正则化方法。
可以从两个角度理解其为何能有效防止过拟合:
- 根据概率让一定的神经元失活,让神经元学习到更鲁棒的特征,减轻对某个特征过度的依赖性。所以下一层神经元与上一层神经元连接的权重都相近并且较小,从而缓解过拟合(类似weight decay)。
- 这也相当于提供了一种廉价的Bagging集成近似方法:前向传播时随机部分神经元的输入,从而每次训练的网络都不同,得到各种子网络。
数据尺度变化
假设模型训练完成后,网络某一层有100个神经元,假设每个wx=1。
那么当模型在训练时因为有随机失活(假设失活率为0.3),则这一层只有70个神经元参与训练,数据尺度为
当模型在测试集测试时不再使用随机失活,则此时这一层的数据尺度为
所以数据尺度发生了变化,解决的办法是在测试时将所有权重乘以1-drop_prob。
在上述例子中drop_prob=0.3,则1-drop_prob=0.7.
参考文献:《Dropout:A simple way to prevent neural networks from overfitting》
nn.Dropout
功能:Pytorch提供的Dropout层
参数:
- p:被舍弃概率,失活概率
实现细节
- 将Dropout层放在要使用Dropout的网络层的前面。
- 在Pytorch中,为了测试时更加方便,在训练时将权重均乘以
 ,抵消随机失活的数据尺度变化。这样在测试时就不用做改变,加快了测试的速度。
,抵消随机失活的数据尺度变化。这样在测试时就不用做改变,加快了测试的速度。
代码实现
set_seed(1) # 设置随机种子
n_hidden = 200
max_iter = 2000
disp_interval = 400
lr_init = 0.01
# ============================ step 1/5 数据 ============================
def gen_data(num_data=10, x_range=(-1, 1)):
w = 1.5
train_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
train_y = w*train_x + torch.normal(0, 0.5, size=train_x.size())
test_x = torch.linspace(*x_range, num_data).unsqueeze_(1)
test_y = w*test_x + torch.normal(0, 0.3, size=test_x.size())
return train_x, train_y, test_x, test_y
train_x, train_y, test_x, test_y = gen_data(x_range=(-1, 1))
# ============================ step 2/5 模型 ============================
class MLP(nn.Module):
def __init__(self, neural_num, d_prob=0.5):
super(MLP, self).__init__()
self.linears = nn.Sequential(
nn.Linear(1, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob), # 注意将Dropout层放在要使用Dropout的网络层的前面
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, neural_num),
nn.ReLU(inplace=True),
nn.Dropout(d_prob),
nn.Linear(neural_num, 1),
)
def forward(self, x):
return self.linears(x)
net_prob_0 = MLP(neural_num=n_hidden, d_prob=0.)
net_prob_05 = MLP(neural_num=n_hidden, d_prob=0.5)
# ============================ step 3/5 优化器 ============================
optim_normal = torch.optim.SGD(net_prob_0.parameters(), lr=lr_init, momentum=0.9)
optim_reglar = torch.optim.SGD(net_prob_05.parameters(), lr=lr_init, momentum=0.9)
# ============================ step 4/5 损失函数 ============================
loss_func = torch.nn.MSELoss()
# ============================ step 5/5 迭代训练 ============================
writer = SummaryWriter(comment='_test_tensorboard', filename_suffix="12345678")
for epoch in range(max_iter):
pred_normal, pred_wdecay = net_prob_0(train_x), net_prob_05(train_x)
loss_normal, loss_wdecay = loss_func(pred_normal, train_y), loss_func(pred_wdecay, train_y)
optim_normal.zero_grad()
optim_reglar.zero_grad()
loss_normal.backward()
loss_wdecay.backward()
optim_normal.step()
optim_reglar.step()
if (epoch+1) % disp_interval == 0:
net_prob_0.eval()
net_prob_05.eval()
# 可视化
for name, layer in net_prob_0.named_parameters():
writer.add_histogram(name + '_grad_normal', layer.grad, epoch)
writer.add_histogram(name + '_data_normal', layer, epoch)
for name, layer in net_prob_05.named_parameters():
writer.add_histogram(name + '_grad_regularization', layer.grad, epoch)
writer.add_histogram(name + '_data_regularization', layer, epoch)
test_pred_prob_0, test_pred_prob_05 = net_prob_0(test_x), net_prob_05(test_x)
# 绘图
plt.scatter(train_x.data.numpy(), train_y.data.numpy(), c='blue', s=50, alpha=0.3, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='red', s=50, alpha=0.3, label='test')
plt.plot(test_x.data.numpy(), test_pred_prob_0.data.numpy(), 'r-', lw=3, label='d_prob_0')
plt.plot(test_x.data.numpy(), test_pred_prob_05.data.numpy(), 'b--', lw=3, label='d_prob_05')
plt.text(-0.25, -1.5, 'd_prob_0 loss={:.8f}'.format(loss_normal.item()), fontdict={'size': 15, 'color': 'red'})
plt.text(-0.25, -2, 'd_prob_05 loss={:.6f}'.format(loss_wdecay.item()), fontdict={'size': 15, 'color': 'red'})
plt.ylim((-2.5, 2.5))
plt.legend(loc='upper left')
plt.title("Epoch: {}".format(epoch+1))
plt.show()
plt.close()
net_prob_0.train()
net_prob_05.train()
代码过程
注意:上面代码运行到第75行,会将模型切换到测试模式:
net_prob_05.eval()
此时进入Module的eval函数:
def eval(self):
return self.train(False)
该函数中执行train函数:
def train(self, mode=True):
self.training = mode
for module in self.children():
module.train(mode)
return self
可以看到在该函数中,mode传入False,将模型及其所有子模块的training属性都设置为False,从而将其切换到测试模式。
**
实验结果
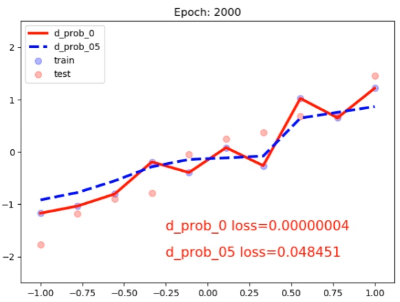
使用TensorBoard对权重的分布可视化,未使用Dropout时权重分布如下:
使用Dropout时权重分布如下: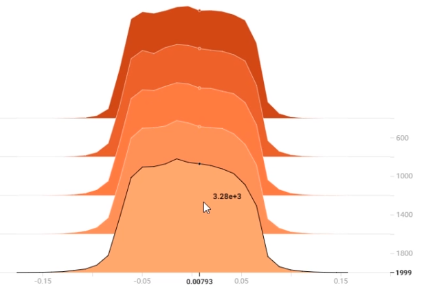
可以发现Dropout不仅可以防止过拟合,还可以类似L2正则化收缩权重。

若有收获,就点个赞吧
0 人点赞
