class _LRScheduler
Pytroch中提供了六种学习率调整策略,均继承自该基类。
主要属性:
- optimizer:关联的优化器,才能修改里面的学习率
- last_epoch:记录epoch数
- base_Irs:记录初始学习率
主要方法:
- step():更新下一个epoch的学习率。下一个epoch的学习率的获取就是通过下面函数get_lr()得到。注意这个函数要放在epoch循环中,不要错放到iteration循环里。
- get_lr():这是一个虚函数,被子类overwrite来计算下一个epoch的学习率。
下面介绍Pytroch中提供的六种学习率调整策略:
有序调整
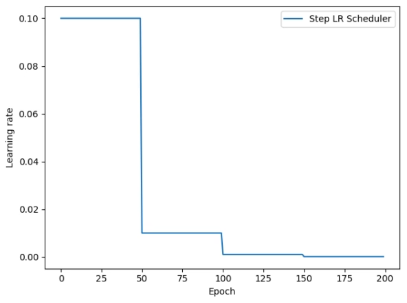
1. StepLR
功能:等间隔调整学习率
主要参数:
- step_size:调整间隔数。即每隔多少个epoch调整一次学习率
- gamma:调整系数
调整方式:Lr=Lr∗gamma
代码实现流程:
第一步 构建一个Scheduler**
scheduler_lr = optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1)# 设置学习率下降策略
1.1 进入StepLR的init函数,保存传入的参数,然后对其基类lr_scheduler初始化
1.2 进入lr_scheduler的init函数,对输入进行合法性判断,然后对lr_scheduler的3个重要属性赋值
class _LRScheduler(object):def __init__(self, optimizer, last_epoch=-1):# Attach optimizerif not isinstance(optimizer, Optimizer):raise TypeError('{} is not an Optimizer'.format(type(optimizer).__name__))self.optimizer = optimizer# Initialize epoch and base learning ratesif last_epoch == -1:for group in optimizer.param_groups:group.setdefault('initial_lr', group['lr'])else:for i, group in enumerate(optimizer.param_groups):if 'initial_lr' not in group:raise KeyError("param 'initial_lr' is not specified ""in param_groups[{}] when resuming an optimizer".format(i))self.base_lrs = list(map(lambda group: group['initial_lr'], optimizer.param_groups))self.last_epoch = last_epoch
其中将传入的optimizer参数赋值给self.optimizer;
然后将optimizer中每个参数组中的param_groups里的初始学习率提取出来赋值给base_lrs;
最后给self.last_epoch初始化为-1.
接着还会执行下面的初始化函数。
第二步 使用Scheduler,更新下一个epoch的学习率。
scheduler_lr.step() # 注意要放在epoch的循环中
2.1 在step函数中,先对last_epoch加一,然后执行get_lr()获取下一次epoch的学习率
values = self.get_lr()
2.2 在StepLR类的get_lr()函数中,该方法是overwrite基类的虚函数。在这个函数中就是遍历base_lrs中的每一个学习率,对其实现学习率调整的计算公式
if (self.last_epoch == 0) or (self.last_epoch % self.step_size != 0):return [group['lr'] for group in self.optimizer.param_groups]return [group['lr'] * self.gammafor group in self.optimizer.param_groups]
2.3 获取到下一个epoch更新的学习率后,修改optimizer.params_groups里保存的lr,这样之后optimizer更新可学习参数时就会使用新的学习率。
for param_group, lr in zip(self.optimizer.param_groups, values):param_group['lr'] = lr
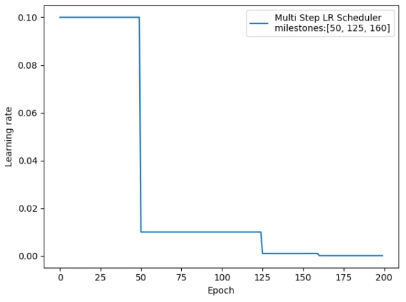
2. MultiStepLR
功能:按给定间隔调整学习率
主要参数:
- milestones:设定调整时刻数,例如:milestones=[50, 125, 160]表示第50,125,160个epoch的时候调整
- gamma:调整系数
调整方式:Lr=Lr*gamma
milestones = [50, 125, 160]scheduler_lr = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.1)lr_list, epoch_list = list(), list()for epoch in range(max_epoch):lr_list.append(scheduler_lr.get_lr())epoch_list.append(epoch)for i in range(iteration):loss = torch.pow((weights - target), 2)loss.backward()optimizer.step()optimizer.zero_grad()scheduler_lr.step()plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler\nmilestones:{}".format(milestones))plt.xlabel("Epoch")plt.ylabel("Learning rate")plt.legend()plt.show()
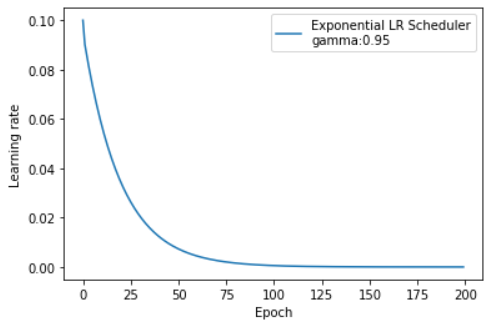
3. ExponentialLR
功能:按指数衰减调整学习率
主要参数:
- gamma:指数的底
调整方式:Lr=Lr ∗ gamma ∗∗ epoch
有点类似动量加权平均的调整方式,学习率呈指数衰减
gamma = 0.95scheduler_lr = optim.lr_scheduler.ExponentialLR(optimizer, gamma=gamma)
4. CosineAnnealingLR
功能:余弦周期调整学习率
主要参数:
- T_max:下降周期,表示需要多少个epoch从cos的最大变到最小
- eta_min:学习率下限,通常为0
调整方式: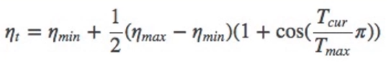
t_max = 50scheduler_lr = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=t_max, eta_min=0.)

自适应调整
5.ReduceLRonPlateau(很实用)
功能:监控指标,当指标不再变化则调整
主要参数:
- mode:min/max两种模式
- min:当监控指标不再减小时调整Lr,通常监控Loss
- max:当监控指标不再增大时调整Lr,通常监控Accuracy
- factor:调整系数
- patience:“耐心”,接受几次不变化
- cooldown:“冷却时间”,停止监控一段时间
- verbose:是否打印日志
- min_lr:学习率下限
- eps:学习率衰减最小值
loss_value = 0.5accuray = 0.9factor = 0.1mode = "min"patience = 10cooldown = 10min_lr = 1e-4verbose = Truescheduler_lr = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=factor, mode=mode, patience=patience,cooldown=cooldown, min_lr=min_lr, verbose=verbose)for epoch in range(max_epoch):for i in range(iteration):# train(...)optimizer.step()optimizer.zero_grad()if epoch == 5:loss_value = 0.4scheduler_lr.step(loss_value) ## 注意这里要将监控指标作为参数传入!!
因为这里将loss_value设置为固定值不会降低,所以结果为分别在第16,37,58个epoch中调整学习率。
自定义调整
6.LambdaLR(最灵活)
功能:自定义调整策略
主要参数:
- Ir_lambda: function or list
注意这里即使是list,list中的元素也必须为function
可以用来对多个参数组的lr进行不同调整策略:
lr_init = 0.1weights_1 = torch.randn((6, 3, 5, 5))weights_2 = torch.ones((5, 5))optimizer = optim.SGD([{'params': [weights_1]},{'params': [weights_2]}], lr=lr_init)lambda1 = lambda epoch: 0.1 ** (epoch // 20)lambda2 = lambda epoch: 0.95 ** epochscheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])lr_list, epoch_list = list(), list()for epoch in range(max_epoch):for i in range(iteration):# train(...)optimizer.step()optimizer.zero_grad()scheduler.step()lr_list.append(scheduler.get_lr())epoch_list.append(epoch)print('epoch:{:5d}, lr:{}'.format(epoch, scheduler.get_lr()))
学习率初始化
- 设置较小数:0.01、0.001、0.0001
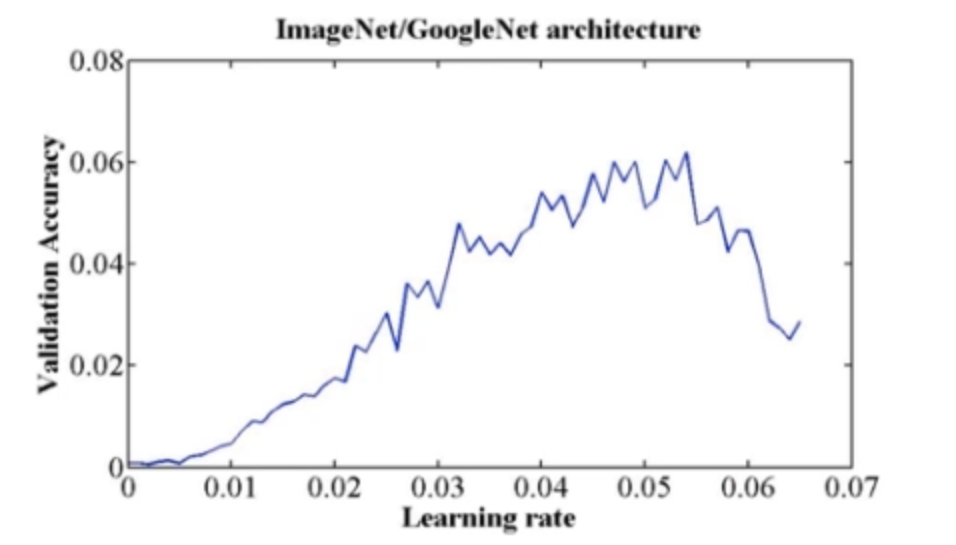
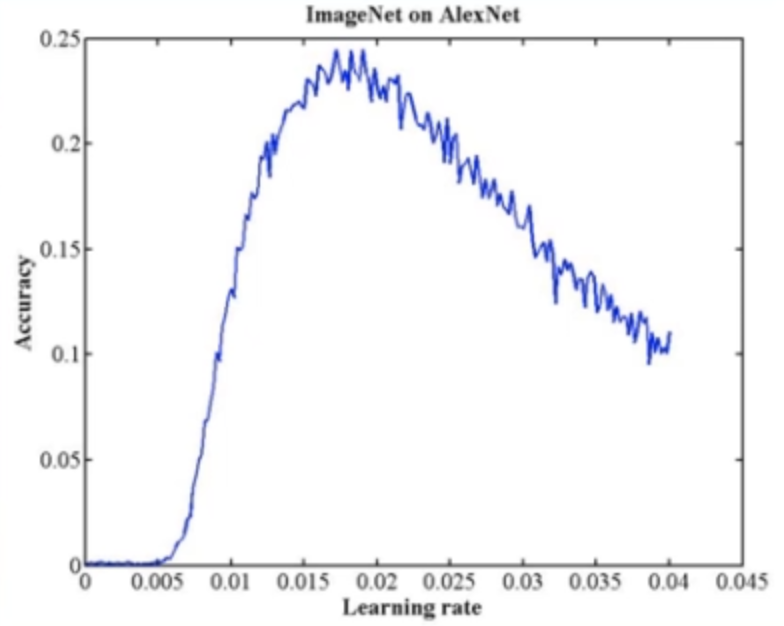
- 搜索最大学习率:参考文献《Cyclical Learning Rates for Training Neural Networks》
该paper的主要思想就是以Accuracy为评判标准,从lr为0开始往上搜索,一直增大到Accuracy开始下降时,就是最大的 初始化学习率。如下图:

若有收获,就点个赞吧
0 人点赞
