Batch Normalization
概念
Batch Normalization:批标准化
批:一批数据,通常为mini-batch
标准化:0均值,1方差
参考文献:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
文中提出了BN的五个优点:
- 可以用更大学习率,加速模型收敛
- 可以不用精心设计权值初始化
- 可以不用dropout或较小的dropout
- 可以不用L2或者较小的weight decay
- 可以不用LRN(local response normalization)
计算方式

注意该算法最后一步,被称作affine transform:它可以让模型更灵活地调整数据的分布。如何调整分布的超参数 都是通过模型学习得到的。这样就增强了模型的Capacity。
都是通过模型学习得到的。这样就增强了模型的Capacity。
然而如此简单的BN算法能有上述那么多的优点,其实是无心插柳柳成荫。BN最先被提出来是为了解决Internal Covariate Shift(ICS,数据尺度变化)。
Internal Covariate Shift
该问题在权重初始化章节介绍过,其实就是当权重的方差如果有增大或者缩小的趋势,那么当网络层层数增多时,就会造成梯度爆炸或者梯度消失的问题。
而BN算法一开始就是解决这个问题,只是后面发现它还能带来一系列的好处。
_BatchNorm(基类)

- nn.BatchNorm1d
- nn.BatchNorm2d
-
基类的参数
num_features:一个样本特征数量(最重要)
- eps:分母修正项,一般是1e-5
- momentum:指数加权平均估计当前mean/var
- affine:是否需要affine transform,默认是true
- track_running_stats:是训练状态,还是测试状态
- 如果是训练状态,会根据每个batch的data采用加权平均计算mean和std
- 如果是测试状态,则会根据当前的统计信息,固定mean和std
主要属性
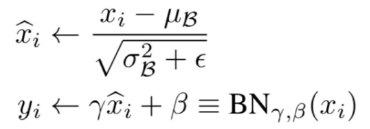
- running_mean:均值μ。
- 计算公式为:running_mean=(1-momentum) pre_running_mean + momentum mean_t
- running_Var:方差σ
- 计算公式为:running_var=(1-momentum) pre_running_var + momentum var_t
- weight:affine transform中的γ(可学习)
- bias:affine transform中的β(可学习)
注意:这里running_mean和running_Var都是在特征数量的维度上进行计算。即一个特征有多少个特征数量num_features,最后running_mean和running_Var的长度就有多少。
举个例子理解running_mean和running_Var的加权平均计算:
构造数据tensor([[[1.], [2.], [3.], [4.], [5.]],
[[1.], [2.], [3.], [4.], [5.]],
[[1.], [2.], [3.], [4.], [5.]]])
假设初始化时参数是0均值1标准差,
则在iteration0时,第2个特征的running_mean = (1-0.3)0+0.32=0.6
running_Var = (1-0.3)1+0.30=0.7
在iteration1时,第2个特征的running_mean = (1-0.3)0.6+0.32=1.02
running_Var = (1-0.3)0.7+0.30=0.49
running_Var同理。
代码实现
class MLP(nn.Module):def __init__(self, neural_num, layers=100):super(MLP, self).__init__()self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])self.bns = nn.ModuleList([nn.BatchNorm1d(neural_num) for i in range(layers)])self.neural_num = neural_numdef forward(self, x):for (i, linear), bn in zip(enumerate(self.linears), self.bns):x = linear(x)x = bn(x)x = torch.relu(x)if torch.isnan(x.std()):print("output is nan in {} layers".format(i))breakprint("layers:{}, std:{}".format(i, x.std().item()))return xdef initialize(self):for m in self.modules():if isinstance(m, nn.Linear):# method 1# nn.init.normal_(m.weight.data, std=1) # normal: mean=0, std=1# method 2 kaimingnn.init.kaiming_normal_(m.weight.data)neural_nums = 256layer_nums = 100batch_size = 16net = MLP(neural_nums, layer_nums)# net.initialize()inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1output = net(inputs)print(output)
通过实验发现:当单独使用BN时,参数就能保持在很好的尺度,所以不需要精心设计权重初始化,例如使用Kaiming初始化等方法。
nn.BatchNorm1d
input = Bs 特征数 1d特征
nn.BatchNorm2d
nn.BatchNorm3d
代码示例
batch_size = 3num_features = 4momentum = 0.3features_shape = (2, 2, 3)feature = torch.ones(features_shape) # 3Dfeature_map = torch.stack([feature * (i + 1) for i in range(num_features)], dim=0) # 4Dfeature_maps = torch.stack([feature_map for i in range(batch_size)], dim=0) # 5Dprint("input data:\n{} shape is {}".format(feature_maps, feature_maps.shape))bn = nn.BatchNorm3d(num_features=num_features, momentum=momentum)running_mean, running_var = 0, 1for i in range(2):outputs = bn(feature_maps)print("\niter:{}, running_mean.shape: {}".format(i, bn.running_mean.shape))print("iter:{}, running_var.shape: {}".format(i, bn.running_var.shape))print("iter:{}, weight.shape: {}".format(i, bn.weight.shape))print("iter:{}, bias.shape: {}".format(i, bn.bias.shape))
这里构造了一个shape为torch.size([3,4,3,2,2])的input,运行结果为:
即对数据的特征维度,每个特征分别计算一组running_mean,running_Var,weight和bias。
Layer Normalization(LN)
起因:BN不适用于变长的网络,如RNN,网络层神经元个数每次不一样。
思路:逐层计算均值和方差
注意事项:
- 不再有running_mean和running_var
- gamma和beta为逐元素计算的,即每个神经元都计算一组
nn.LayerNorm

主要参数:
- normalized_shape:该层特征形状(最重要)
- eps:分母修正项(公式里面的ϵ)
- elementwise_affine:是否需要逐元素的affine transform
参考文献:《Layer Normalization》
代码实现
batch_size = 2num_features = 3features_shape = (2, 2)feature_map = torch.ones(features_shape) # 2Dfeature_maps = torch.stack([feature_map * (i + 1) for i in range(num_features)], dim=0) # 3Dfeature_maps_bs = torch.stack([feature_maps for i in range(batch_size)], dim=0) # 4D# feature_maps_bs shape is [2, 3, 2, 2], B * C * H * Wln = nn.LayerNorm(feature_maps_bs.size()[1:], elementwise_affine=True)# ln = nn.LayerNorm(feature_maps_bs.size()[1:], elementwise_affine=False)# ln = nn.LayerNorm([3, 2, 2])output = ln(feature_maps_bs)print("Layer Normalization")print(ln.weight.shape)print(feature_maps_bs[0, ...])print(output[0, ...])
注意在输入LayerNorm的参数normalized_shape时,可以用input.size()[1: ]来取,得到C H W
Instance Normalization
起因:在图像生成任务中(如下图),每个batch的风格是不一样的,把不同batch的特征来求均值明显是不好的。所以BN在图像生成(lmage Generation)中不适用。
思路:我们认为数据的每个channel的风格是不同的,所以这里逐Instance(channel)计算均值和方差
参考文献:
- 《Instance Normalization:The Missing Ingredient for Fast Stylization》
- 《Image Style Transfer Using Convolutional Neural Networks》
nn.InstanceNorm

主要参数:(和bn一样,InstanceNorm也有1d,2d,3d,这里就不赘述了):
- num_features:一个样本特征数量(最重要)
- eps:分母修正项
- momentum:指数加权平均估计当前mean/var
- affine:是否需要affine transform
- track_running_stats:是训练状态,还是测试状态
代码实现
batch_size = 3num_features = 3momentum = 0.3features_shape = (2, 2)feature_map = torch.ones(features_shape) # 2Dfeature_maps = torch.stack([feature_map * (i + 1) for i in range(num_features)], dim=0) # 3Dfeature_maps_bs = torch.stack([feature_maps for i in range(batch_size)], dim=0) # 4Dprint("Instance Normalization")print("input data:\n{} shape is {}".format(feature_maps_bs, feature_maps_bs.shape))instance_n = nn.InstanceNorm2d(num_features=num_features, momentum=momentum)for i in range(1):outputs = instance_n(feature_maps_bs)print(outputs)
Group Normalization
起因:大模型在训练时会占用很多内存,这时batchsize只能设置很小。然而在小batch样本中,BN估计的值不准。
思路:数据不够,通道来凑。
例如,假设特征数有256个,就将一个样本的256个feature map分为两组,每组128个feature map。然后对每组计算一个均值和标准差。
注意事项(与LN类似):
- 不再有running_mean和running_var
- gamma和beta为逐通道(channel)的
应用场景:大模型(小batch size)任务
参考文献:《Group Normalization》
nn.GroupNorm

主要参数:
- num_groups:分组数,通常为2.4.8.16.32
- num_channels:通道数(特征数),如果通道数(特征数)为256,分组数为4,那么每组的通道数为:64
- eps:分母修正项
- affine:是否需要affine transform
代码实现
batch_size = 2num_features = 4num_groups = 3 # 3 Expected number of channels in input to be divisible by num_groupsfeatures_shape = (2, 2)feature_map = torch.ones(features_shape) # 2Dfeature_maps = torch.stack([feature_map * (i + 1) for i in range(num_features)], dim=0) # 3Dfeature_maps_bs = torch.stack([feature_maps * (i + 1) for i in range(batch_size)], dim=0) # 4Dgn = nn.GroupNorm(num_groups, num_features)outputs = gn(feature_maps_bs)print("Group Normalization")print(gn.weight.shape)print(outputs[0])

若有收获,就点个赞吧
0 人点赞
