写在前面
要想用好高层次综合,必须要能对C代码进行优化。
高层次综合尽可能减少循环和函数的延时,尽可能使得循环和函数中的操作并行化。
除了综合器自动优化,还有三种优化方法。
法一:并行执行多个任务。流水线。
法二:划分物理实现,提高数据可用性。
法三:提供关于数据依赖项的信息,或省略它,允许执行更多的优化。
法三要去修改C代码,删除代码中可能限制硬件性能的意外依赖项。
Lab1
对比循环和函数流水线,分析两个最常见的设计失败因素:循环依赖、数据流限制或瓶颈。
优化矩阵乘法器。矩阵乘法器每周期处理一个新样本,接口为流数据接口。
分析比较顶层优化和函数层优化。
STEP1

顺便加深对矩阵乘法的理解。本实验为两个33的矩阵相乘,得到33的矩阵。char是8-bit,short是16-bit,8-bit是0到255,8-bit8-bit是255255=65025,最多是16bit(16-bit是0到65535)。
不过,考虑是还有累加,用short存结果还是可能溢出的。
分析一下溢出情况
无符号数

195075=650253>65535有溢出
有符号数
char是8-bit,0到127
short是16-bit,0到32767

48387=161293>32767
综上,均有可能溢出。本实验中暂时忽略溢出。
STEP2
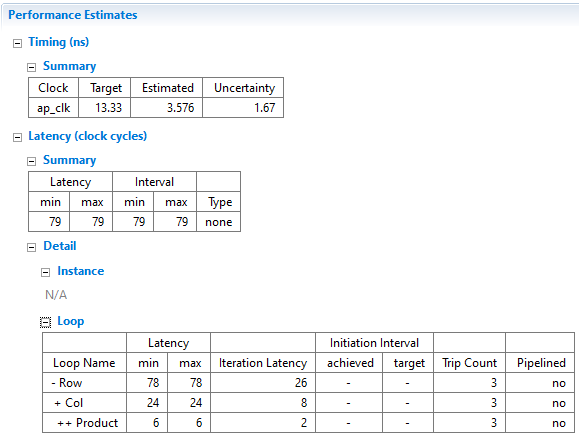

因为有非常标准的乘加运算AB+C,所以综合出DSP。
因为不需要存系数,所以没有综合出Memory。
延时分析
乘法LatencyTrip Count=23=6
考虑进入离开6+1+1=8
Col中LatencyTrip Count=83=24
考虑进入离开24+1+1=26
Row中LatencyTrip Count=26*3=78
总延时是76
优化方式还是给循环或者整个函数加流水pipeline。Initiation interval是函数中包含的循环完成所有数据处理所需的时间,与优化程度无关。
STEP3
When pipelining nested loops, you realize the greatest benefit by pipelining the inner-most loop, which processes a sample of data. High-Level Synthesis automatically applies loop flattening, collapsing the nested loops, removing the loop transitions (essentially creating a single loop with more iterations but overall fewer clock cycles).
当流水线嵌套循环时,通过流水线最内部的循环来实现最大的好处,该循环处理数据样本。 高级综合自动应用循环扁平化,折叠嵌套循环,删除循环转换(本质上创建一个具有更多迭代但总体上较少时钟周期的单一循环)。
注意,更多迭代,但总体上较少时钟周期
由于数据依赖,无法展平顶层循环,只展平了Row_Col。下图红字说明,没有实现目标。

延时特性变得更差了。
数据依赖见图。状态C1中的写操作是由于在Product循环之前将res设置为零的代码。 因为res是一个顶级函数参数,所以它是对RTL中端口的写入:这个操作必须在执行循环产品中的操作之前发生。 由于它不是内部操作,但对I/O行为有影响,因此不能移动或优化此操作。 这防止产品循环被扁平到Row_Col循环中。
更重要的是,为什么乘法循环的初始化间隔是2就是有可能的?
这是一个循环的一次迭代与同一循环的不同迭代之间的依赖,即下一次循环需要读出本次循环将写入的结果。本实验中是“+=”,因为一方面读RES,另一方面写RES,这不可能在一个周期内完成。
The first iteration of the loop shows the states in which the operations occur. The read in states 2 and 3, and the write in state 3. The operation in the next iteration must start 1 cycle after this, because the 2nd read cannot occur until the 1st write has finished: the operations in each iteration of the loop are to a different address and only 1 address can be applied at the same time.
循环的第一次迭代显示操作发生的状态。 读在状态2和3,写在状态3。 在下一次迭代中的操作必须在此之后开始1个周期,因为第二次读取不能发生,直到第一次写入完成:循环的每次迭代中的操作都是到不同的地址,并且只能同时应用一个地址。
重点在右上角选择II Violation。其实,选择product部分也能看到高亮。
STEP4
Pipeline the Col Loop。

看起来是快了。但是还是有红字。
Arrays are implemented as block RAMs and arrays which are arguments to the function are implemented as block RAM ports. In both cases a block RAM can only have a maximum of two ports (for dual-port block RAM). By accessing array a through a single block RAM interface, there are not enough ports to be able to read all three values in one clock cycle.
在Col加流水,需要1行1行算,也就是3个3个算,而Block RAMs只有两个端口,所以C1到C3,每个周期都需要读。
2-cycle read operations in state C1 overlap with those starting in state C2 and so only a single cycle is visible: however, it is clear that this resource is used in multiple states.
读操作持续2周期,当周期送地址,下周期取数据。
C1送地址,C2取数据
C2送地址,C3取数据
显然在C2重叠了,显然只能做单次读操作。可以看出来,BRAM资源被用于不同的状态。
即使解决了端口A,端口B还是有同样的问题。
KEY POINT
High-Level Synthesis can only report one schedule error or warning at a time, because, as soon as the first issue occurs, the actions to create an achievable schedule invalidates any other infeasible schedules.
高级别综合一次只能报告一个时间表错误或警告,因为一旦出现第一个问题,创建可实现的时间表的行动就会使任何其他不可行的时间表无效。
也就是说,问题只能一个一个解决。没有报错的地方不代表没有错,但凡有红字,结果均不可用。
STEP5
Reshape the Arrays。数组重新分区映射。
设计需要在每个时钟周期中访问k的两个以上的值。
对于数组A,是维度2;对于数组B,是维度1。
注意是reshape而不是Chapter 6中的partition
Partitioning these arrays creates MAT_A_COLS arrays - in this case, MAT_A_COLS number ports. Alternatively, we can use re-shape instead of partition allowing one wide array (port) to be created instead of k ports.
对这些数组进行分区将创建MAT_A_COLS数组-在这种情况下,MAT_A_COLS数字端口。 或者,我们可以使用re-shape而不是分区,允许创建一个宽的数组(端口)而不是k端口。(此处的k端口,指的是特定输出端口)。
分区是分成两块,端口是一样的。
reshape是调整端口,产生一个宽的数组(24bit)作为输出端口,dim=1说明用1维索引,dim=2说明用2维索引。这里使用complete的模式。
数组的ARRAY_RESHAPE
ARRAY_RESHAPE:将数组的Partition与纵向的MAP结合在一起。换句话说,就是横向打碎,纵向黏合。
原理如下:
complete代表把Block或Cyclic中的Factor=1,也就是弄成竖直的一条
dim=1代表沿着第一个维度展开
dim=2代表沿着第二个维度展开
 PARTITION分区。把大的数组分成小的数组。
PARTITION分区。把大的数组分成小的数组。
MAP映射、重组。把小的数组映射成一个数组。
可以看出MAP可以获得资源的节省,ARRAY_RESHAPE可以获得吞吐率的提高。
成功做到Interval=1
11=2+9*1
此时可以同时read出多个值,或者说一次read24位。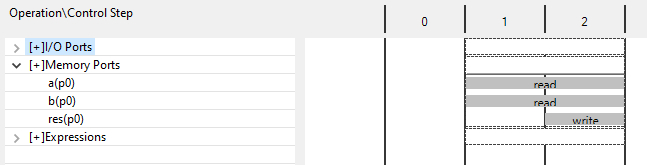
之前
地址位有4位,2^4=16>9
之后
地址位有2位,2^2=4>3
一次出24bits,3个数据
看出来只有一次READ,没有冲突。
STEP6

从C代码可以看出,四个连续写入地址[0][0]不构成流访问模式;这是随机访问。
像这样的代码,不可能使用流式的FIFO接口。这个时候优化指令是不够用的,必须重写代码。
但是,在修改代码之前,应该先流水线函数,而不是流水线循环,以对比这两种方法的差异。(只是为了对比,不代表某种通用范式)
STEP7


该设计现在以较少的时钟完成,并且可以每5个时钟周期启动一个新事务。 然而,面积和资源大幅增加,因为设计中的所有循环都是展开的。
Pipelining loops allows the loops to remain rolled, thus providing a good means of controlling the area. When pipelining a function, all loops contained in the function are unrolled, which is a requirement for pipelining. The pipelined function design can process a new set of 9 samples every 5 clock cycles. This exceeds the requirement of 1 sample per clock because the default behavior of High-Level Synthesis is to produce a design with the highest performance.
在头顶加PIPELINE意味着所有循环都展开。在顶层函数加PIPELINE意味着不计成本,只在乎速度。而优化不应该是无止境的。
流水线函数导致最佳性能。 但是,如果它超过了所需的性能,可能需要多个附加指令来劣化设计。 流水线循环为您提供了一种控制资源的简单方法,可以选择部分展开设计以满足性能。
Lab2
通过修改C代码,改善Lab1。
HLS不能简单地决定改变算法的特定结构。有时候修改C代码是必要的。
Lab1代码直观地捕获了矩阵乘法的行为,但它阻止了硬件中所需的行为:流访问。
上图为Lab1中的I/O访问模式。
此外,每个乘法循环开始,res都需要置零。
要具有具有顺序流访问的硬件设计,端口访问只能是以红色突出显示的端口访问。 (只访问最后一个,即只访问有效结果)
对于读取端口,必须在内部缓存数据,以确保设计不必重新读取端口。
对于写端口RES,数据必须保存到一个临时变量中,并且只在红色显示的循环中写入端口。
(使用暂存来避免读写,使得流式端口成为可能)
STEP1
该代码中把优化指令使用pragma表示,但是Directive窗口并未因此不显示。
pragma-编译指示
在C代码中的#pragma前面加入注释符,保存,右边Directive窗口会随之变化。这说明Directive会根据#pragma中内容进行实时调整。
这一代码中保留了Lab1中的FIFO端口,在Col中流水线循环。
此外,加入了Cache来缓存行和列读取,临时变量用于累积。由于用于缓存行和列的for-loops需要多个周期来执行读取,因此管道指令已应用于Col for-loop,确保这些缓存for-loops自动展开。
代码有问题,Cache_Row: for(int k = 0; k < MAT_A_ROWS; k++)
应该改为Cache_Row: for(int k = 0; k < MAT_A_COLS; k++)
矩阵乘法中MAT_A_COLS=MAT_B_ROWS满足,两个矩阵才能相乘。使用MAT_A_ROWS,在Product中长度是匹配不上的。至于例子中使用MAT_A_ROWS完全是因为粗心,且矩阵的行列相同才能够通过。
STEP2
非常得直接干脆,不一步步优化,直接把优化好的代码给出来了。从Interface窗口中可以看出,综合出了FIFO接口。

提了一下使用Run C/RTL CoSimulation,其目的是确认可行性?
总结
本章讲了:
如何分析流水线循环,并确切了解哪些限制阻止优化目标的实现。
函数与循环流水线的优缺点。
代码中的意外依赖如何能够阻止硬件设计目标的实现,以及如何通过修改源代码来克服它们。具体是使用缓存和临时变量。
~~
multiple-数量多的;多种多样的
multiplexer-多路选择器
multiplier-乘法器

若有收获,就点个赞吧
0 人点赞
