写在前面
lab1
综合和分析DCT设计。利用来自设计分析的洞察力来应用优化,并判断优化的有效性。
示例用的时2-D DCT,2维-离散余弦变换
离散傅里叶变换的工程上的子集,输入信号为实偶函数
jpeg就是使用了DCT作为图像压缩算法
优化目标是interval间隔为125或更少
DCT的结构
C语言中给标号,可能是为了配合goto语句,更有可能是为了可读性
STEP3
未进行优化


现在Interval是2935,离125还有很长距离
据我观察,主要延时出现在top的block,延时为2644,占2644/2935=90.1%,读写没有被综合成模块。所以读写是内置在模块中的(inlined),这会影响流水。
High-level synthesis might automatically inline small functions to improve the quality of results (QoR). You can prevent this by adding the Inline directive with the -off option to any function being automatically inlined.
高级合成可以自动内联小函数以提高结果的质量。你可以通过将带有off选项的Inline指令添加到任何被自动内联的函数中来防止这种情况。
时钟频率meet
显然没有加pipeline流水是一个大问题。
RD_Lopp_Row的延时是可以计算的
每层Col循环延时为2
有8层Col循环28=16
进去Col和回到Row循环各需要1个延时16+1+1=18
有8层Row循环188=144(trip count=8)
总延时144
2935(总延时)=2644(dct_2d)+144(RD_Loop_Row)+144(WR_Loop_Row)+3(进入这些模块)
STEP4
调用Analysis透视图
Schedule Viewer中
子模块用蓝色
loop的结果是标记的和可展开的
标准操作同样得到展示
ug说加符号(+)代表有可展开的层次可能说的是(>)(个人理解)
这里是r被综合成加法器r,c被综合成加法器c
可以流水线循环以提高性能。 性能配置文件中的详细信息表明,大多数延迟是由循环Row_DCT_Loop和Col_DCT_Loop引起的。
STEP5
当对嵌套循环进行流水处理时,通常最好是流水最内部的循环。 在5个地方加上流水
在5个地方加上流水
使用compare reports的比较模式
在这个Lab上实验结果与ug非常吻合
加了流水后,144周期变成64周期,吞吐量增加了
为什么是这样子???
—原来的—
RD_Lopp_Row的延时是可以计算的
每层Col循环延时为2
有8层Col循环28=16
进去Col和回到Row循环各需要1个延时16+1+1=18
有8层Row循环188=144(trip count=8)
总延时144
—现在的—
164=64?不考虑Iteration Latency了吗?如果源源不断输入数据,不是零状态响应,确实可以忽略。
不要去理解,要去感受。
从上图可以看到
当Pipelined=no, Latency = Iteration Latency Trip count
当Pipelined=yes, Latency = Iteration Interval * Trip count
loop flattening循环扁平化,也就是把2层(或多层)循环变得只有1层。换句话说,两个for合成了一个for,内层的for通过流水,通过加寄存器,使得其可以不需要等待,一边给输入,一边拿输出。
要具体理解就要解答下面的问题。
一个for函数被高层次综合后得到什么东西?
比较器+多路选择器
两次比较之间,就是迭代器i在变化,这个中间状态是不被保留的,直到for的条件满足,才输出有效数据。内层for的数据有效,传递到外层for。
一个for函数加了流水线被高层次综合后得到什么东西?
想象把一个i=8的单元复制8份,每一步迭代器i的状态被保留,8个状态同步移动,时钟周期被进一步划分。此时,中间状态的数据得到利用,吞吐量变大。
气泡排掉之后(初始化完成),一边给输入,一边拿输出,间隔Interval为1,不需要等待内层操作一步步完成。(因为内层函数利用率高、资源比外层少,所以更值得优化)
现在的情况是上一周期,外层给内层数据;这一周期,内层给外层数据(算完了)。间隔Interval为1。
但是 是内层运行完一轮后tmp有效,k是当前的k,tmp是8周期的temp,他们总有周期差。因为不是同一周期下的,等tmp到位的时候k早就变了,流水线的作用体现不出来了。这个时候就没办法扁平化,也没必要(增加资源却不改善延时)扁平化。
是内层运行完一轮后tmp有效,k是当前的k,tmp是8周期的temp,他们总有周期差。因为不是同一周期下的,等tmp到位的时候k早就变了,流水线的作用体现不出来了。这个时候就没办法扁平化,也没必要(增加资源却不改善延时)扁平化。
解决方式是给外层加流水,把k保留下来。这样子问题就解决了,代价是资源消耗。
截止目前,主要延时还是dct_1d2
这个loop并没有展平,5个地方加流水线,4个成功flatterning a loop nest
这个循环没有被扁平化,因为在DCT_Inner_Loop之外的额外操作,在DCT_Outer_Loop的水平上,阻止了循环扁平化。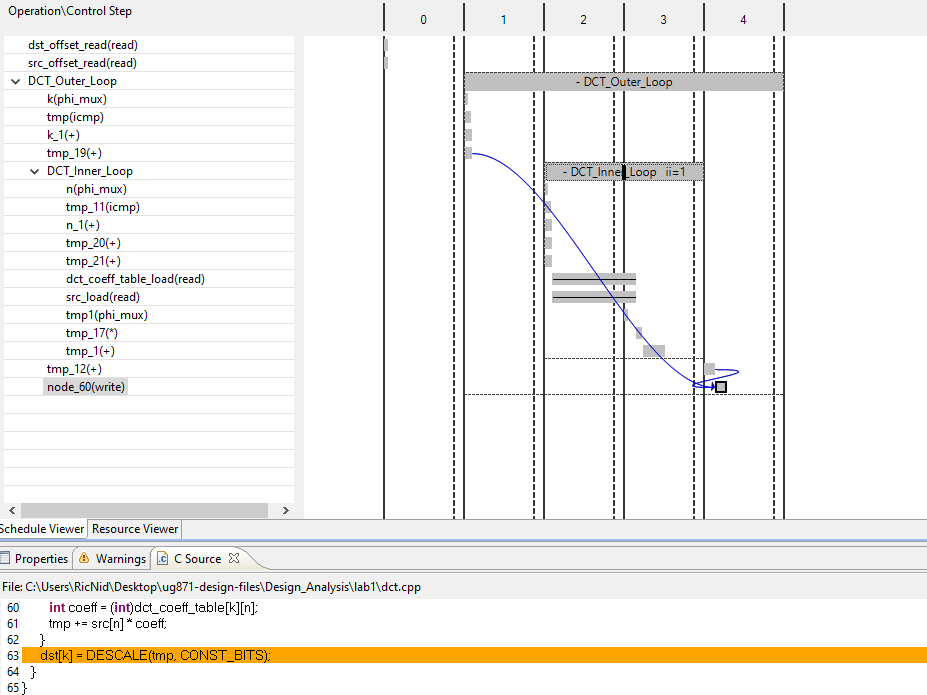
有一个descale的缩放会造成耦合,因为这是与Outer Loop有关的,与tmp19的结果有关。要在DCT外环上实现1的间隔,需要流水线输出回路-简单地流水线内回路本身是没有好处的。
简而言之,两者耦合了,流水流外层/两者都要流水。
STEP6
只优化DCT_Outer_Loop,我觉得应该两层都优化(可能资源开销会很大,也不值得)。
比较2和3的solution,延时缩短1半。
由于设计中的多个循环多次调用dct_1d函数,因此实现了显著的延迟效益。 在这个块中保存延迟是成倍的,因为这个函数在许多循环中使用。
时钟周期变长了。
继续找瓶颈。瓶颈可能来源于数据流的限制(可能是IO或RAM的端口),可能来源于代码中的数据依赖。
按照步骤进行操作
箭头从循环开始的模块指向循环结束的模块。P123中箭头几乎是垂直的(所有的事情都发生在两个时钟周期),这个循环在延迟方面得到了很好的实现。说明了这个优化做的很好。
像下图的优化就不是很好。通常有两件事导致了这种类型的时序:源代码中的数据依赖和I/O或块RAM的限制。 您现在将检查此块中的资源共享。
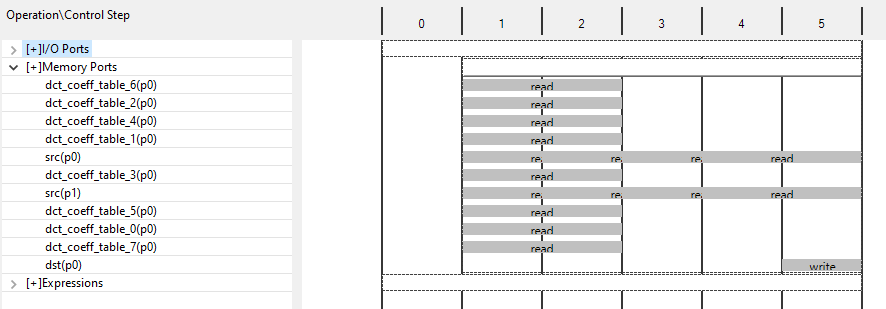
/??the memory resources are expanded
上图显示了block RAM src上的内存访问在每个时钟周期中被使用到最大值。 (最多,block RAM可以是双端口,两个端口都在使用)。 这是一个很好的指示,设计可能受到内存资源的带宽限制。 要确定是否真的是这样,您可以进一步检查。 中有明显数据依赖。
中有明显数据依赖。
Figure 6-24 shows this read on the src variable is from the read operation inside loop DCT_Inner_Loop. This loop was automatically unrolled when DCT_Outer_Loop was pipelined and all operations in this loop can occur in parallel (if data dependencies allow).
前提是数据依赖允许。
读操作需要两个时钟周期,一个周期生成地址,一个周期读取数据。显然不是单周期返回。
数组是DCT_SIZE DCT_SIZE
由于数组是以逐行列的形式在代码中配置的,所以我们可以对第二个维度进行分区,并创建八个单独的BlockRAM:每行一个,允许并行访问行数据。
我的理解, int coeff = (int)dct_coeff_table[k][n];每个tmp要用到8个coeff,而且是可以通过外层循环的k确定的。这样子,我们可以把原来存coeff的88的bram,拆开为8个8的bram,每个内层循环使用1个,互不影响。
STEP7
把部分内存拆成两个维度。


注意观察修改MEMORY带来的改变
大小大于1024bits会被综合成LUTRAM
到目前为止,您一直专注于改进设计中每个单独循环和函数的延迟和间隔。 现在必须应用dataflow优化,使各个循环和函数能够并行执行,从而改善总体设计间隔。
STEP8
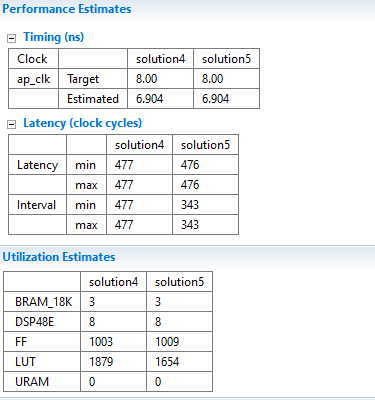
Latency没什么变化,Interval明显减小,LUT资源的使用还变少了
还要继续优化。我觉得这会是一个很好的例子,用于充分使用各种优化方法。
在这里,您可以看到两件事:
DCT块的间隔小于个体延迟之和(对于read_data、dct_2d和write_data)。 这意味着块是并行工作的。
DCT的间隔与子块dct_2d的间隔几乎相同。 因此,dct_2d块是限制因素。
此处,Interval为间隔,Latency为延迟。
现在问题变成优化dct_2d,注意这可能带来面积剧增,目前
方法1要给dct_2d加dataflow
方法2要使用一种不太明显的技术:将这些循环提升到层次结构的顶层,其中它们将包含在已经应用于顶层的数据流优化中。 这可以通过使用优化指令来删除dct_2d层次结构来实现:内联dct_2d函数。
说人话,方法2是使dct_2d跑到顶层,进入数据流的优化。
STEP9

总结
本章介绍了analysis perspective的使用,分析窗口和C代码的交叉链接,优化操作的分析判断方法,以及如何一步步满足设计目标。
directive-指令,指示

若有收获,就点个赞吧
0 人点赞
