网络结构
主干网络(backbone)
主干网络,用来做特征提取的网络,代表网络的一部分,一般是用于前端提取图片信息,生成特征图feature map,供后面的网络使用。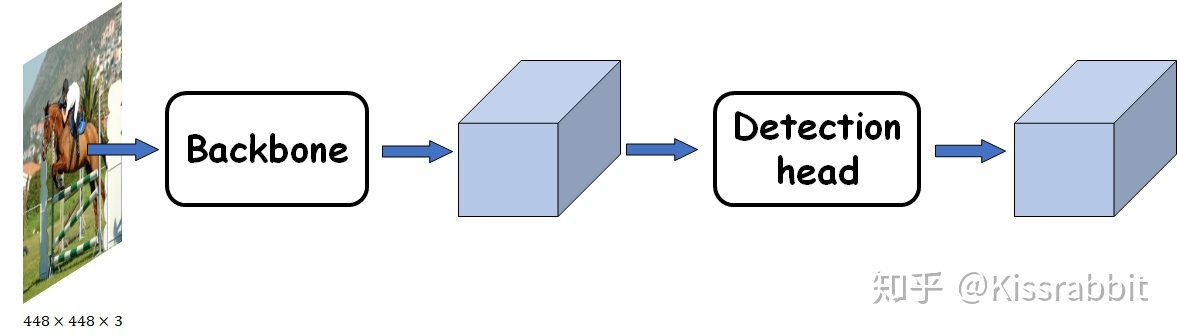
深度学习中常用的主干网络介绍
https://blog.csdn.net/weixin_39326879/article/details/106782668
https://zhuanlan.zhihu.com/p/162881214
LeNet
LeNet是最早的卷积神经网络之一。1998年,Yan LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征。
AlexNet
在2012年,Alex Krizhevsky等人提出的AlexNet以很大优势获得了ImageNet比赛的冠军。这一成果极大的激发了产业界对神经网络的兴趣,开创了使用深度神经网络解决图像问题的途径,随后也在这一领域涌现出越来越多的优秀成果。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
- 数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
- 使用Dropout抑制过拟合
- 使用ReLU激活函数减少梯度消失现
VGG
VGG是当前流行的CNN模型之一,2014年由Simonyan和Zisserman提出,其命名来源于论文作者所在的实验室Visual Geometry Group。AlexNet模型通过构造多层网络,取得了较好的效果,但是并没有给出深度神经网络设计的方向。VGG通过使用一系列大小为3x3的小尺寸卷积核和pooling层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。GoogLeNet
GoogLeNet是2014年ImageNet比赛的冠军,它的主要特点是网络不仅有深度,还在横向上具有“宽度”。
由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核大小来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征,而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为Inception模块的方案。ResNet
ResNet是2015年ImageNet比赛的冠军,将图像分类识别错误率降低到了3.6%,这个结果甚至超出了正常人眼识别的精度。
F(x)+x构成的block称之为Residual Block,即残差块,如下图所示,多个相似的Residual Block串联构成ResNet。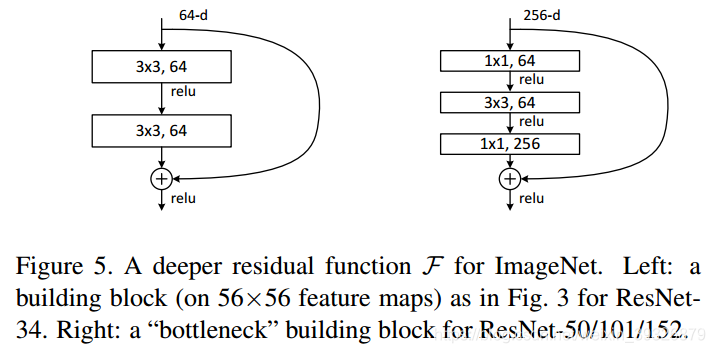
下图表示出了ResNet-50的结构,一共包含49层卷积和1层全连接,所以被称为ResNet-50。
BP
损失函数Loss
https://www.cnblogs.com/guoyaohua/p/8542554.html https://aistudio.baidu.com/aistudio/projectdetail/1507918
交叉熵cross_entropy
优化器
https://aistudio.baidu.com/aistudio/projectdetail/1507911
Adam
激活函数
https://blog.csdn.net/kangyi411/article/details/78969642
softmax
1. sigmod函数
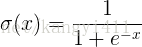
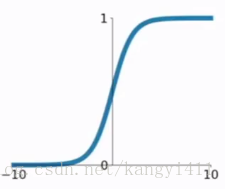
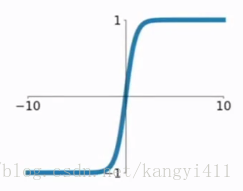
2.tanh函数
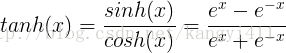
3.ReLU函数
ReLU函数公式和曲线如下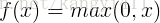
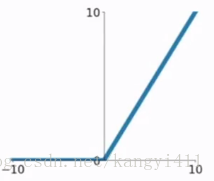
ReLU(Rectified Linear Unit)函数是目前比较火的一个激活函数,相比于sigmod函数和tanh函数,它有以下几个优点:
1) 在输入为正数的时候,不存在梯度饱和问题。
2) 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
当然,缺点也是有的:
1) 当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。这样在前向传播过程中,还不算什么问题,有的区域是敏感的,有的是不敏感的。但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和sigmod函数、tanh函数有一样的问题。
2) 我们发现ReLU函数的输出要么是0,要么是正数,这也就是说,ReLU函数也不是以0为中心的函数。
4.ELU函数
ELU函数公式和曲线如下图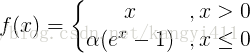
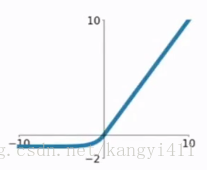
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
5.PReLU函数
PReLU函数公式和曲线如下图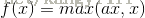
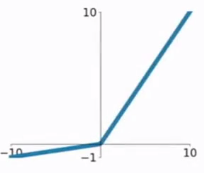
PReLU也是针对ReLU的一个改进型,在负数区域内,PReLU有一个很小的斜率,这样也可以避免ReLU死掉的问题。相比于ELU,PReLU在负数区域内是线性运算,斜率虽然小,但是不会趋于0,这算是一定的优势吧。
卷积(Convolution)与池化(Polling)
如何理解卷积神经网络(CNN)中的卷积和池化?:
https://www.zhihu.com/question/49376084(推荐阅读)
卷积:
通常,卷积有助于我们找到特定的局部图像特征(如边缘),用在后面的网络中。
池化:

若有收获,就点个赞吧
0 人点赞
