PaddleSeg:华录杯·车道线检测
](https://aistudio.baidu.com/aistudio/projectdetail/1081298?channelType=0&channel=0)[PaddleSeg:华录杯·车道线检测(单卡、多卡训练) ](https://aistudio.baidu.com/aistudio/projectdetail/1081298?channelType=0&channel=0)
深度学习笔记(十二)车道线检测 LaneNet
目录
论文:Towards End-to-End Lane Detection: an Instance Segmentation Approach
代码:https://github.com/MaybeShewill-CV/lanenet-lane-detection
参考:车道线检测算法LaneNet + H-Net(论文解读)
数据集:Tusimple
回到顶部
Overview
本文提出一种端到端的车道线检测算法,包含 LanNet + H-Net 两个网络模型。其中 LanNet 是一种将语义分割和对像素进行向量表示结合起来的多任务模型,最后利用聚类完成对车道线的实例分割。H-Net 是有个小的网络结构,负责预测变换矩阵 H,使用转换矩阵 H 对同属一条车道线的所有像素点进行重新建模(使用 y 坐标来表示 x 坐标)。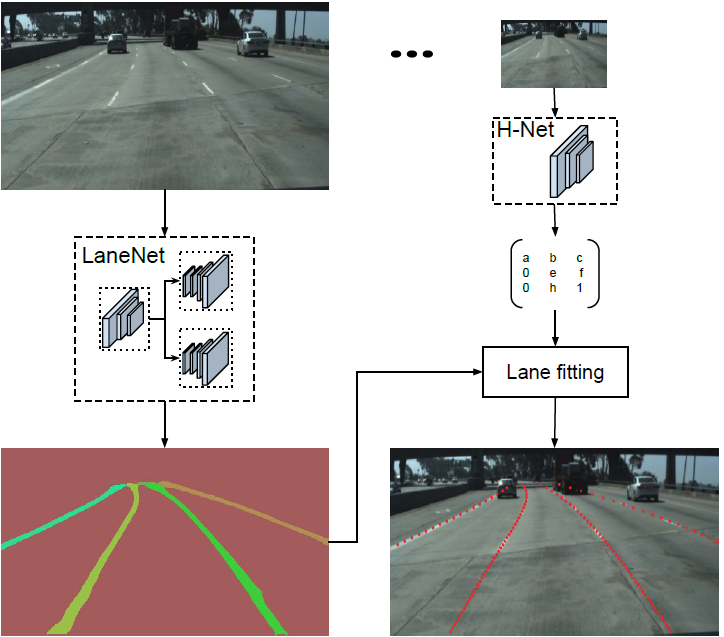
回到顶部
LaneNet
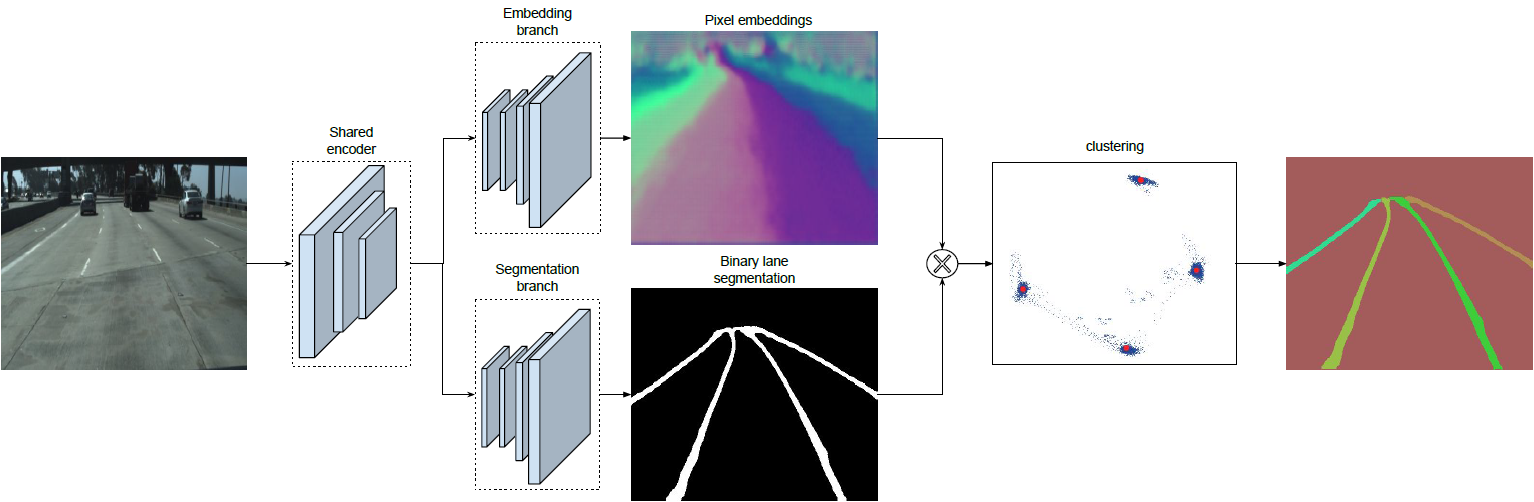
论文中将实例分割任务拆解成语义分割(LanNet 一个分支)和聚类(LanNet一个分支提取 embedding express, Mean-Shift 聚类)两部分。如上图所示,LanNet 有两个分支任务,分别为 a lane segmentation branch and a lane embedding branch。Segmentation branch 负责对输入图像进行语义分割(对像素进行二分类,判断像素属于车道线还是背景);Embedding branch 对像素进行嵌入式表示,训练得到的 embedding 向量用于聚类。最后将两个分支的结果进行结合利用 Mean-Shift 算法进行聚类,得到实例分割的结果。
语义分割
在设计语义分割模型时,论文主要考虑了以下两个方面:
1.在构建 label 时,为了处理遮挡问题,论文对被车辆遮挡的车道线和虚线进行了还原(估计);
2. Loss 使用 softmax_cross_entropy,为了解决样本分布不均衡的问题(属于车道线的像素远少于属于背景的像素),参考论文ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation ,使用了 bounded inverse class weight 对 loss 进行加权:
Wclass=1ln(c + p(class))Wclass=1ln(c + p(class))
其中,p 为对应类别在总体样本中出现的概率,c 是超参数(ENet论文中是1.02)。 View Code
View Code
像素 embedding
为了区分车道线上的像素属于哪条车道,embedding_branch 为每个像素初始化一个 embedding 向量,并且在设计 loss 时,使属同一条车道线的像素向量距离尽可能小,属不同车道线的像素向量距离尽可能大。
这部分的 loss 函数是由三部分组成:方差 loss(LvarLvar) 和距离 loss(LdistLdist):
Lvar=1C∑Cc=11Nc[∥μc−xi∥−δv]2+Lvar=1C∑c=1C1Nc[‖μc−xi‖−δv]+2
Ldist=1C(C−1)∑CcA=1∑CcB=1,cA≠CB[δd−∥μcA−μcB∥]2+Ldist=1C(C−1)∑cA=1C∑cB=1,cA≠CBC[δd−‖μcA−μcB‖]+2
Lreg=1C∑Cc=1∥μc∥Lreg=1C∑c=1C‖μc‖
其中,C 是车道线数量,NcNc 是属同一条车道线的像素点数量,μcμc 是车道线的均值向量,xixi 是像素向量(pixel embedding),[x]+=max(0,x)[x]+=max(0,x)。注意这里先执行 ++ 操作,再执行 22 操作。
该 loss 函数源自于论文 《Semantic Instance Segmentation with a Discriminative loss function》
同一车道线的像素向量,距离车道线均值向量 μcμc 超过 δvδv 时, pull force(LvarLvar) 才有意义,使得 xixi 靠近 δdδd; 不同车道线的均值向量 μcAμcA 和 μcBμcB 之间距离小于 δdδd 时,push force(LdistLdist) 才有意义,使得 μcAμcA 和 μcBμcB 彼此远离。
 View Code
View Code
聚类
注意,聚类可以看做是个后处理,上一步里 embedding_branch 已经为聚类提供好的特征向量了,利用这些特征向量我们可以利用任意聚类算法来完成实例分割的目标。
为了方便聚类,论文中设定 δd>6δvδd>6δv。
在进行聚类时,首先使用 mean shift 聚类,使得簇中心沿着密度上升的方向移动,防止将离群点选入相同的簇中;之后对像素向量进行划分:以簇中心为圆心,以 2δv2δv 为半径,选取圆中所有的像素归为同一车道线。重复该步骤,直到将所有的车道线像素分配给对应的车道。
网络结构
LaneNet是基于ENet 的encoder-decoder模型,如图5所示,ENet由5个stage组成,其中stage2和stage3基本相同,stage1,2,3属于encoder,stage4,5属于decoder。
如上图所示,在LaneNet 中,语义分割和实例分割两个任务共享 stage1 和 stage2,并将 stage3 和后面的 decoder 层作为各自的分支(branch)进行训练;其中,语义分割分支(branch)的输出 shape 为WH2,实例分割分支(branch)的输出 shape 为WHN,W,H分别为原图宽和高,N 为 embedding vector 的维度;两个分支的loss权重相同。
ENet 实现中有一些 block 可以借鉴:
回到顶部
H-Net
LaneNet的输出是每条车道线的像素集合,还需要根据这些像素点回归出一条车道线。传统的做法是将图片投影到 bird’s-eye view 中,然后使用 2 阶或者 3 阶多项式进行拟合。在这种方法中,变换矩阵 H 只被计算一次,所有的图片使用的是相同的变换矩阵,这会导致地平面(山地,丘陵)变化下的误差。
为了解决这个问题,论文训练了一个可以预测变换矩阵 H 的神经网络 H-Net,网络的输入是图片,输出是变换矩阵 H: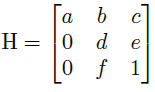
通过置 0 对转置矩阵进行约束,即水平线在变换下保持水平。(即坐标 y 的变换不受坐标 x 的影响)
由上式可以看出,转置矩阵 H 只有6个参数,因此H-Net的输出是一个 6 维的向量。H-Net 由 6 层普通卷积网络和一层全连接网络构成,其网络结构如图所示: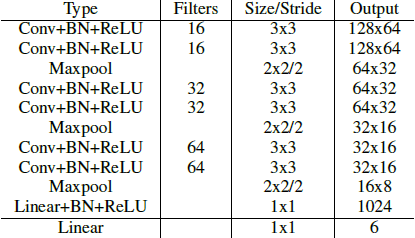
Curve Fitting
Curve fitting的过程就是通过坐标 y 去重新预测坐标 x 的过程:
对于包含 N 个像素点的车道线,每个像素点 pi=[xi,yi,1]T∈Ppi=[xi,yi,1]T∈P, 首先使用 H-Net 的预测输出 H 对其进行坐标变换:
P′=HPP′=HP
随后使用 最小二乘法对 3d 多项式的参数进行拟合:
w=(YTY)−1YTx′w=(YTY)−1YTx′根据拟合出的参数 w=[α,β,γ]Tw=[α,β,γ]T 预测出 x′∗ixi′∗
x′∗i=αy′2+βy′+γxi′∗=αy′2+βy′+γ最后将 x′∗ixi′∗ 投影回去:
p∗i=H−1p′∗ipi∗=H−1pi′∗Loss function
Loss=1N∑Ni=1(x∗i−xi)2Loss=1N∑i=1N(xi∗−xi)2
回到顶部实验参数
LanNet
Dataset : Tusimple Embedding dimension = 4 δ_v=0.5 δ_d=3 Image size = 512*256 Adam optimizer Learning rate = 5e-4 Batch size = 8
H-Net
Dataset : Tusimple 3rd-orderpolynomial Image size =128*64 Adam optimizer Learning rate = 5e-5 Batch size = 10
评价标准
语义分割部分
第三方
accuracy=21/recall+1/precisionaccuracy=21/recall+1/precision
recall=|P1∩G1||G1|recall=|P1∩G1||G1| # 统计GT中车道线分对的概率
precision=|P0∩G0||G0|precision=|P0∩G0||G0| # 统计GT中背景分对的概率
设定 G1G1 代表 GT二值图里像素值为 1 部分的集合,P1P1 表示检测结果为 1 的集合。 View Code
View Code
简单示例: View Code
View Code
官方
accuracy=|P1∩G1||G1|accuracy=|P1∩G1||G1| # 统计GT中车道线分对的概率 View Code
View Code
fp=|P1|−|P1∩G1||P1|fp=|P1|−|P1∩G1||P1| # 统计Pre中的车道线误检率 View Code
View Code
fn=|G1|−|P1∩G1||G1|fn=|G1|−|P1∩G1||G1| # 统计GT车道线中漏检率 View Code
View Code
简单示例: View Code
View Code
回到顶部
相关实验
- 替换 backbone 为 mobilenet_v2
2. 调整 embedding dim
3. 预处理方式调整
4. 上采样方式替换
5. 学习率衰减方式
6. 反卷积卷积核尺寸调整
回到顶部代码结构

lanenet-lane-detection
├── config //配置文件
├── data //一些样例图片和曲线拟合参数文件
├── dataprovider // 用于加载数据以及制作 tfrecords
├── lanenetmodel
│ ├── lanenet.py //网络布局 inference/compute_loss/compute_acc
│ ├── lanenet_front_end.py // backbone 布局
│ ├── lanenet_back_end.py // 网络任务和Loss计算 inference/compute_loss
│ ├── lanenet_discriminative_loss.py //discriminative_loss实现
│ ├── lanenet_postprocess.py // 后处理操作,包括聚类和曲线拟合
├── model //保存模型的目录semantic_segmentation_zoo
├── semantic_segmentation_zoo // backbone 网络定义
│ ├── __init.py
│ ├── vgg16_based_fcn.py //VGG backbone
│ └─+ mobilenet_v2_based_fcn.py //mobilenet_v2 backbone
│ └── cnn_basenet.py // 基础 block
├── tools //训练、测试主函数
│ ├── train_lanenet.py //训练
│ ├── test_lanenet.py //测试
│ └──+ evaluate_dataset.py // 数据集评测 accuracy
│ └── evaluate_lanenet_on_tusimple.py // 数据集检测结果保存
│ └── evaluate_model_utils.py // 评测相关函数 calculate_model_precision/calculate_model_fp/calculate_model_fn
│ └── generate_tusimple_dataset.py // 原始数据转换格式
├─+ showname.py //模型变量名查看
├─+ change_name.py //模型变量名修改
├─+ freeze_graph.py//生成pb文件
├─+ convert_weights.py//对权重进行转换,为了模型的预训练
└─+ convert_pb.py //生成pb文
回到顶部数据准备
- 首先按照链接下载 Tusimple 数据集:train_set.zip test_set.zip test_label.json
2. 调用 tools/generate_tusimple_dataset.py 将原始数据转换格式
这里会生成 train.txt 和 val.txt,调整格式如下:
testing/gt_image/0000.png testing/gt_binary_image/0000.png testing/gt_instance_image/0000.png
testing/gt_image/0001.png testing/gt_binary_image/0001.png testing/gt_instance_image/0001.png
testing/gt_image/0002.png testing/gt_binary_image/0002.png testing/gt_instance_image/0002.png
3. 调用 data_provider/lanenet_data_feed_pipline.py 转换标注成 TFRecord 格式
回到顶部相关文献
LaneNet: Towards End-to-End Lane Detection: an Instance Segmentation Approach
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
Discriminative Loss: Semantic Instance Segmentation with a Discriminative loss function

若有收获,就点个赞吧
0 人点赞
