- 摘要 Abstract
- 关键词 Keywords
- 1 引言 Introduction
- 2 预备知识 Preliminaries
- 3 方法 Methodology
- 4 实验Experiment
- 5 相关工作 Related work
- 6 讨论 Conclusion
Knowledge Graph Contrastive Learning for Recommendation
- Yuhao Yang, Chao Huang, Lianghao Xia, et al. Knowledge Graph Contrastive Learning for Recommendation[C]. In SIGIR 2022.
香港大学 截稿日期2022-01-28 录用通知2022-04-15 会议日期2022-07-11
摘要 Abstract
知识图谱(KGs)被用作有用的辅助信息来提高推荐质量。在这些推荐系统中,知识图谱信息通常包含丰富的事实和项目之间内在的语义关联。然而,这种方法的成功依赖于高质量的知识图谱,并且可能不学习到高质量的表示,面临两个挑战:i)实体的长尾分布导致KG增强的项目表示的监督信号稀疏;ii)真实世界的知识图谱通常是含有噪声的,并且在项目和实体之间包含与主题无关的连接。这种KG稀疏性和噪声使得项目-实体依赖关系偏离反映它们的真实特征,这显著地放大了噪声效应并且阻碍了用户偏好的准确表示。<br /> 为了填补这一研究空白,我们设计了一个通用的知识图谱对比学习框架(KGCL)来缓解知识图谱增强推荐系统的信息噪声。具体地说,我们提出了一种知识图谱增强模式来抑制信息聚合中的KG噪声,并为项目导出更健壮的知识感知表示。此外,我们利用KG增强过程中的额外监督信号来指导跨视图对比学习范式,在梯度下降中赋予无偏用户-项目交互更大的作用,并进一步抑制噪声。在三个公共数据集上的大量实验表明,我们的KGCL始终优于最先进的技术。KGCL在稀疏用户-项目交互、长尾和噪声的KG实体的推荐场景中也取得了很好的性能。我们的代码实现在[https://github.com/yuh-yang/KGCL-SIGIR22](https://github.com/yuh-yang/KGCL-SIGIR22)
关键词 Keywords
1 引言 Introduction
推荐系统已日益成为向用户推荐感兴趣的项目和缓解从电子商务平台[38]、视频共享网站[20]到在线广告[9]等许多在线服务中信息过载的不可或缺的设备。在各种技术中,协同过滤(CF)框架成为预测用户偏好的有效解决方案,其基本原理是具有相似交互行为的用户可能对项目具有相似的兴趣[12,18,26]。<br /> 近年来,流行的协同过滤范例已经从矩阵分解(MF)发展到用于潜在用户和项目嵌入映射的基于神经网络的技术,例如基于自编码器的方法(例如,Autorec[28])、注意力CF机制(例如,ACF[4])以及最近开发的基于图卷积架构的CF模型(例如,LightGCN[11])。然而,即使在对复杂的用户-项目交互模式进行建模的情况下,大多数基于CF的推荐方法仍然受到尚未与足够项目交互的用户的数据稀缺问题的困扰[7,14,31]。为了克服这种的数据稀疏问题,知识图谱(KG)作为有用的外部资源被结合到推荐系统中,通过编码额外的项目语义相关度来增强用户和项目的表示过程[15,39,47]。<br /> 现有的KG增强方法大致可分为三类。特别是,一些研究[3,51]通过采用基于transition的实体嵌入方案(例如,TransE[2],TransR[19])来生成先验项目嵌入,从而将知识图谱学习与用户-项目交互建模联系起来。为了在捕获高阶KG连通性方面改进KG增强推荐系统,一些基于路径的模型[35,41,52]旨在构建具有合并的KG实体的路径引导的用户项目连接。然而,这些基于路径的方法大多涉及用于生成实体依赖关系的元路径的设计,这需要特定领域的知识和劳动密集型的人力来进行精确的路径构建。受图神经网络的强大功能的启发,最近一个有前途的研究路线在于递归地执行多跳节点之间的信息传播和注入远程关系结构,如KGAT[39]、MVIN[29]、KHGT[45]和KGIN[40]。<br /> 尽管它们在某些场景中是有效的,但我们认为现有的KG-aware推荐方法的有效性在很大程度上依赖于高质量的输入知识图谱,并且容易受到噪声的干扰。然而,在实际场景中,知识图谱通常是稀疏和含有噪声的,呈现出长尾实体分布,并包含项目和实体之间与主题无关的联系[24,34]。<br />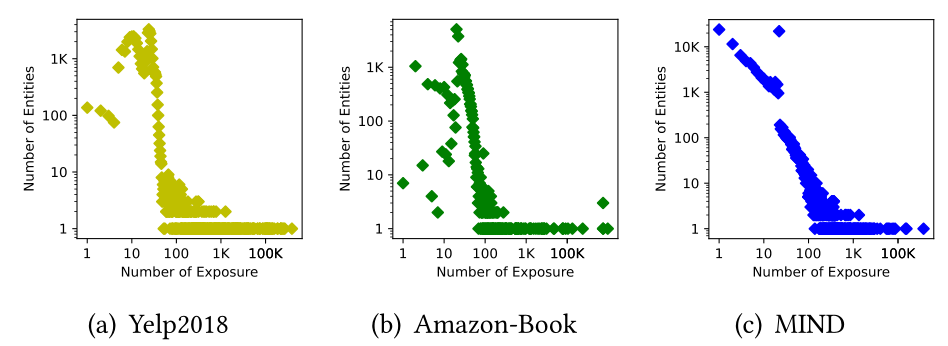<br />**图1 真实世界KG中的长尾实体分布**<br /> 我们从图1中报告了的三个真实世界数据集中收集的KG实体的分布,以说明KG中的长尾问题。在该图中,y轴表示对应于x轴曝光计数的实体数量。显然,来自不同平台的数据集,即食品、书籍和新闻,大多数知识实体都表现出长尾现象。因为它需要足够的三元组链接到一个实体,以通过使用转换算法准确地模拟KG中的语义转换[2,19],这为准确捕捉项目相关度带来了挑战。此外,与主题无关的实体连接在KGs中普遍存在。我们提供了一个激励性的新闻推荐示例,如图2所示,从新闻item中提取的关键实体Zack Wheeler是美国职业棒球大联盟(MLB)中费城人队的一名著名棒球投手。然而,我们可以注意到Zack Wheeler与两个语义不相关的“噪声”实体联系在一起,即Smyrna、GA和UCL Reconstruction。虽然Zack Wheeler出生于Smyrna,并且他之前接受过Ulnar Collateral Ligament (UCL)重建手术,但这两个实体与本新闻的主要话题不太相关,重点是最近的体育新闻。<br /><br />**图2 从MIND数据集的知识图谱中提取新闻主题无关实体的示例**<br /> 我们将上述问题统一为KG噪声问题。这样的数据噪声问题将从两个方面损害项目表示的质量:i)从局部角度来看,直接聚合来自那些低质量实体的信息会在保留来自相邻实体的项的关键语义方面带来噪声。Ii)从全局角度来看,知识图谱上的信息聚合容易过平滑,因为压倒性的信息可以通过一些流行的实体(例如,位置名称)传播到目标节点。例如,同样出生在Smyrna的其他人可以与职业棒球投手Zack Wheeler联系在一起。因此,有必要赋予知识图谱增强的CF范式有效的连接去噪能力,以提取目标用户真实的潜在偏好,使其具有对噪声干扰不变的表征。<br />** 贡献Contribution。**鉴于上述局限性和挑战,我们提出了一种通用知识图谱对比学习框架(KGCL)来进行推荐。具体地说,针对知识图谱中的关系异构性,我们首先提出了一个关系感知的知识聚合机制来捕获第一阶段项目表示的实体和关系相关的上下文信号。然后,我们开发了一种跨视图对比学习模式,该模式将知识图谱去噪与用户-项目交互建模联系起来,从而可以利用外部项目语义相关性来指导具有跨视图自监督信号的数据增强。所设计的跨视图对比学习模式通过进行KG对比学习来抑制KG噪声,并利用来自该过程的外部信号来测量受KG噪声影响的项目表征的偏差。这些信号作为用户-项目图对比学习视图的指导,保持了有用的图结构并包含较少的噪声。<br /> KGCL从知识图谱学习和自监督的数据增强中得到启发,结合知识图谱上下文来指导模型使用新的知识感知对比目标来精炼用户/项目表示。在我们的框架中,我们的联合对比学习网络基于知识图谱的结构一致性来学习丢弃不相关的KG三元组和项目,以实现稳健的用户偏好学习。由于KGCL的模型无关性,它可以插入到各种图神经推荐模型中。在KGCL中,知识图谱引导的对比学习模型和图神经CF结构以端到端的方式进行联合优化。<br />综上所述,我们的贡献如下:
该工作引入了在联合自监督学习范式下将知识图谱学习与用户-项目交互建模相结合的思想,以提高推荐的鲁棒性并缓解数据噪声和稀疏性问题。
- 提出了一种通用的知识图谱引导的拓扑去噪框架KGCL,它提供了具有知识感知对比目标的跨视图自我鉴别监督信号。我们还提供了理论分析来证明联合学习目标所带来的好处。
我们在三个公共数据集上进行了不同的实验,提出的KGCL在不同的设置下始终优于各种先进的推荐方法。进一步的消融分析证明了我们关键部件的合理性。
2 预备知识 Preliminaries
这一节介绍了本文使用的关键符号,并对我们研究的任务进行了形式化。我们考虑具有用户集和项目集的典型推荐场景。单个用户和项目分别表示为和。我们定义了用户-物品交互矩阵来表示用户对不同物品的消费行为。在矩阵中,假设用户以前采用了项目(例如,点击、评论或购买),则元素,否则。<br />** 用户-项目交互图User-Item Interaction Graph** 基于矩阵,我们首先构造了用户-项目交互图,其中如果,则在中生成节点集,边。<br />** 知识图谱Knowledge Graph** 我们用表示知识图谱,该知识图谱具有不同类型的实体和对应关系的外部项目属性。具体地说,每个实体-关系-实体三元组表征了头部和尾部实体和与关系之间的语义关系,例如movie推荐(Titanic, Directed by, James Cameron)和venue推荐(McDonald’s, Located in, Chicago)的三元组。这些信息结合了项目之间丰富的事实和联系作为辅助信息,以改进用户推荐偏好的建模。<br /> 在构建用户交互行为和项目知识的基础上,寻求利用项目知识信息来辅助用户的兴趣学习。然而,现实世界的知识图谱通常含有噪声的,并且涉及我们之前描述的与项目无关的实体。在这种情况下,并不是所有的实体和关系都对学习适当的项目特征有用。在大多数现有的知识感知推荐系统中,从“有噪声”的实体和关系中聚合的信息可能会严重影响项目表示的质量,这显著限制了KG增强用户偏好建模的有效性。为了应对这一挑战,该工作利用知识图谱拓扑去噪的潜力来提取用户和项目表示的信息指导。<br />** 任务制定Task Formulation** 我们的任务正式描述如下:输入:用户-项目交互数据和项目知识图谱数据。输出:学习函数,它预测用户想要交互的项目,其中Θ表示模型参数。
3 方法 Methodology
我们在图3中介绍了KGCL的总体架构。技术细节将在以下小节中讨论。<br />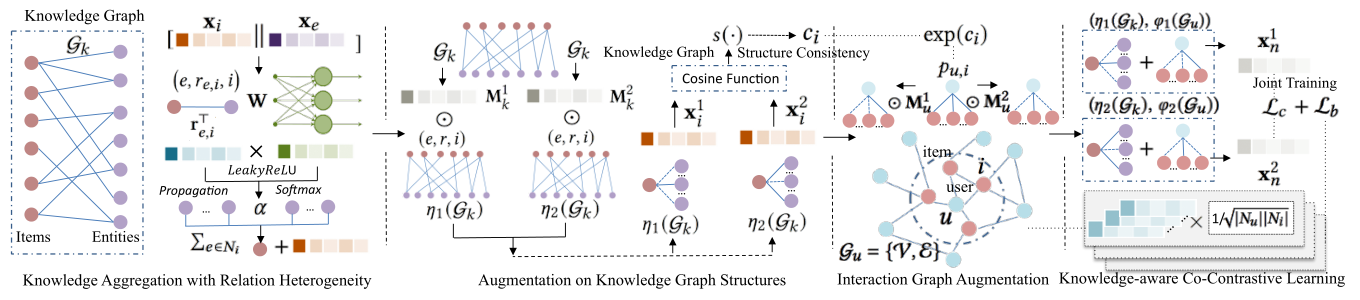<br />**图3 KGCL的整体框架。**在知识图谱和用户-项目交互图上具有增强功能的知识感知联合对比学习。对比目标与由知识图谱聚合和基于图的CF编码器共享的主嵌入空间联合优化。
3.1 关系感知的知识聚合 Relation-aware Knowledge Aggregation
3.1.1 基于关系异构性的知识聚合 Knowledge Aggregation with Relation Heterogeneity
受[32,39,45]中图注意机制的启发,我们首先设计了一个关系感知的知识嵌入层,以反映知识图连接结构上的关系异构性。为了解决在知识图谱上手动设计路径生成的局限性,我们的KGCL使用参数化的注意矩阵将实体和关系依赖的上下文投影到特定的表示中。为此,我们在项目及其在的连接实体之间构建了我们的的消息聚合机制,用于基于异构注意聚合生成知识感知的项目嵌入,如下所示:<br /><br /> (1)<br />其中是知识图谱中基于不同类型的关系的项目的相邻实体。这里,项目和实体的嵌入分别表示为和。表示在知识聚合过程中估计的特定于实体和关系的注意相关性。尤其是,编码项目和实体之间的关系的不同语义。表示为输入项目和实体表示形式自定义的参数权重矩阵。非线性变换采用_LeakyReLU_激活函数。
3.1.2 语义表示增强 Semantic Representation Enhancement
此外,为了进一步增强实体-项目依赖的多关系语义表示空间,我们在关系感知知识聚合和TransE[2]之间进行交替训练。这种基于translation的知识图谱嵌入的基本思想是使头部和关系嵌入和的和与尾部表示一样接近。这里,我们定义来表示嵌入向量之间基于范数的相似性度量函数,即。形式上,基于translation的优化损失如下所示:<br /> (2)<br /> 负样本是通过随机替换来自知识图谱的观测三元组的尾部来生成的。
3.2 知识图谱增强 Knowledge Graph Augmentation
3.2.1 知识图谱结构增强 Augmentation on Knowledge Graph Structures
受最近在CV/NLP任务中使用对比学习的数据增强技术的成功激励,例如图像分析[33]和机器翻译[27],我们建议使用辅助自监督信号来连接知识图谱嵌入和对比学习范例。对比学习的核心是最大化增强观点之间的互信息,并规范具有对比目标发嵌入学习。<br /> 在我们的KGCL框架中,我们提出通过实体自我辨别为对比学习生成不同的知识图谱结构视图。特别地,我们对输入的知识图谱采用随机数据增强方案来生成两个相关的数据视图。然后,推导出单个项目的知识图谱结构一致性,以反映项目对知识噪声扰动的不变性。为此,我们在具有两个随机选择的知识图谱结构上设计了数据增强算子和,其形式表示如下:<br /> (3)<br />其中表示项目及其依赖实体之间的知识三元组。这里,我们定义掩蔽向量,作为具有概率的二元指示符,以表示在采样过程中是否选择了特定的知识三元组。通过这样做,我们可以生成具有不同增强结构视图的知识子图。我们的知识图谱增强方案的目标是识别对结构变化不那么敏感的item,以及更能容忍与噪声实体的连接的item。这样识别的项目在它们的特征方面不那么模糊,并且更有助于捕获相关用户的偏好。
3.2.2 增强结构视图之间的一致性 Agreement between Augmented Structural Views
在对知识图谱结构进行增强后,我们得到了两个知识图谱依赖视图,其算子分别为和。受[16,55]中关于图一致性的研究的启发,为了探索基于增强视图的每个项目的一致性性质,我们定义了项目的知识图谱结构一致性,其中不同视图编码的表示之间的一致性如下:<br /> (4)<br />这里,表示关系感知知识聚合方案(在等式1中定义),以生成与不同的增强结构视图和相对应的项目嵌入和。表示用于估计和之间相似性的余弦函数。基于上述定义,我们可以注意到,如果一个项目达到较高的结构一致性得分,它对拓扑信息的变化不太敏感。因此,如果item比item受KG噪声的影响更大,则更有可能是。这种导出的每个项目的知识结构一致性属性可以作为指导,以便用辅助自监督信号对抗知识图谱依赖性和用户-项目交互噪声。
3.3 知识导向的对比学习 Knowledge-Guided Contrastive Learning
我们将我们的知识图谱增强模式与图对比学习范式相结合,以提高基于图的协同过滤在模型准确性和鲁棒性方面的表示能力。为了有效地传递用户偏好学习中有用的项目外部知识,我们设计了两个用于用户-项目交互的对比表示空间。在这种对比学习框架中,可以利用去噪项目知识来指导用户和项目表示,并缓解监督信号的稀疏性。
3.3.1 交互图增强机制 Interaction Graph Augmentation Mechanism
虽然最近提出的自监督推荐模型SGL[44]在用户-项目交互图上执行数据增强,但纯粹随机的丢弃操作限制了它在保持对比学习的有用交互方面的有效性。<br /> 为了缓解这一限制,我们利用项的估计知识图谱结构一致性来指导用户-项目交互图上的数据增强。我们的知识引导图对比学习背后的基本原理是识别更有用的交互,以更少的偏见信息来表征用户偏好。具体地说,KG结构一致性分数越高的项目涉及的噪音越少,对用户真实兴趣的建模贡献越大。根据我们的知识引导增强,我们将导出的特定于项目的KG结构一致性合并到用户-项目交互图上的运算符中,公式如下:<br /><br /> (5)<br /><br />其中,表示用户和项目之间的交互边缘丢失的估计概率。表示item对user的影响程度,与对应的结构一致性分数成正比。我们进一步用截断概率,对进行最小-最大归一化,以缓解低值效应。然后,得到中间变量,并将与平均值积分,以求出丢弃概率的值。在这里,控制着基于平均值的影响的强度。利用概率,我们进一步基于伯努利分布[23]生成两个掩蔽向量。之后,将应用于用户-项目交互图,如下所示:<br /> (6)<br />其中表示图增强算子,它根据推断的概率在图的边集中丢弃用户-项目交互。
3.3.2 知识感知协同对比学习 Knowledge-aware Co-Contrastive Learning
不同于现有的大多数对比学习模型(如SGL[44],GraphCL[49])直接对结构级别的增强(如节点dropout或边缘扰动)执行转换,我们将项目知识语义融入到对比学习体系中。我们的KGCL旨在通过增强自监督信号来提高模型的鲁棒性,从项目语义和用户行为模式的角度来扰乱图结构。在我们的协同对比学习范式中,我们整合了我们设计的图增强算子和来创建两个对比视图,从而使特定于视图的编码能够相互协作监督。<br /> 具体地说,给定通过和获得的增强知识子图,我们在基于和的基础上,进一步分别破坏由导出的项目的知识结构一致性(,)指导的用户项交互图。之后,我们可以在用户、项目和实体之间创建两个知识引导的损坏图。然后,利用基于图的协同过滤框架和关系感知的知识聚合机制对用户和项目的表示进行编码。由于LightGCN[11]的有效性和轻量级架构,我们采用其消息传播策略来编码来自用户-项目交互的协同效果如下:<br /> (7)<br />其中和表示用户和项目在第图传播层下的编码表示。和分别表示用户的交互项目和项目的连接用户的集合。在图结构的CF结构中,高阶协同信号可以通过堆叠多个图传播层来捕获。在该编码pipeline中,使用我们设计的异构注意力聚合(在等式1中定义)在保持知识图谱语义的情况下生成输入项目特征向量。这样的项目嵌入被馈送到基于图的CF中用于表示细化。<br /> 之后,KGCL使用生成的两个知识感知图视图,即和来协同监督彼此。具体地说,KGCL对特定视图的用户/项目表示和进行对比学习。对于每个用户或项目节点,基于节点的自区分能力,从用户或项目的两个视图特定嵌入中生成正对。负对是两个图视图中不同节点的表示。我们KGCL中的对比目标基于InfoNCE[5]损失定义如下:<br /> (8)<br />其中,是温度参数。我们采用余弦函数来估计正对和负对的相似度。通过最小化对比目标损失,我们可以实现正对与负对之间的一致性。<br /> **联合训练Joint Training** 在KGCL的学习过程中,我们设计了一个由主推荐任务和辅助自监督信号共享的联合嵌入空间。特别地,我们进一步将原始的贝叶斯个性化排名(BPR)推荐损失与上述对比损失相耦合。首先,我们正式提出采用BPR损失如下:<br /> (9)<br />其中表示观察到的用户的交互。我们从用户的非交互项目中抽取否定实例。是用户和项目之间的估计交互概率,它是用点积得出的:。根据上述定义,我们的KGCL的综合优化损失为:<br /> (10)<br />其中,和表示用于确定自监督信号的强度和联合损失函数正则化的参数。表示可学习的模型参数。
3.4 KGCL模型分析 Model Analysis of KGCL
3.4.1 KGCL的理论讨论 Theoretical Discussion of KGCL
在我们的KGCL中,我们利用提取的知识图谱语义来指导图的跨结构视图的对比学习,以提高对困难负样本的识别能力。具体地说,在[17,44]中的工作之后,给定一个节点实例(即,用户或项目)与其负样本之间的估计相似度,可以形式地呈现所获得的对比梯度:<br /> (11)<br /> 假设=0.2,=0.3,图4显示的分布。如图所示,具有高相似性分数(例如,)的困难负样本导致梯度的值接近40。在这种情况下,与简单负样本相比,困难负样本将对梯度学习产生更大的影响。<br />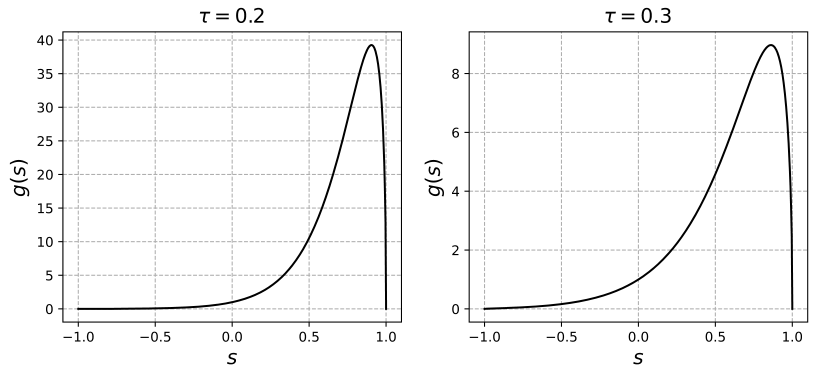<br />**图4 ****= 0.2和****= 0.3下梯度函数****的分布。****是正例和负例之间的相似性得分。困难负例影响显著**<br /> 在我们的知识感知对比学习范式中,项目的知识图谱结构一致性被纳入用户-项目交互图的增强中,以指导边丢弃操作。通过这样做,KGCL的困难负样本的区分能力可以从以下几个方面得到提高:i)与噪声实体相关的项目随着噪声三元组的丢失而被更好地区分,例如,;ii)与模糊项目交互的用户可以用较低的相似度来建模。在[17,44]研究工作的启发下,我们给出了知识感知的对比梯度分析。具体地说,我们首先定义将false困难负样本集合定义为:<br /> (12)<br />其中,的最大值是用最大点得到的。衡量中的节点实例与对应的正样本之间的平均相似度。这里,表示知识图谱中噪声实体相关信息所涉及的有偏差的相似度估计。在没有用于数据增强的知识图谱去噪的情况下,正负样本之间的相似性很可能会影响根据的分布曲线的具有大梯度(由false困难负样本引起)的模型优化:<br /> (13)<br />这里,表示的与false困难负样本的实际估计相似性。在我们的KGCL中,我们的对比增强函数和可以减轻false困难负样本的影响。由KGCL得到的相似性被表示为。基于以上讨论,我们分别更新了false困难负样本和true困难负样本的相似度推导如下:<br /><br /> (14)<br /> 在增强了对困难负样本的识别能力后,我们可以利用准确和有助于模型学习的梯度来提高知识感知推荐系统的鲁棒性。
3.4.2 模型时间复杂度分析 Model Time Complexity Analysis
我们从KGCL框架的三个关键部分分析时间复杂性。(1)对于知识聚合模块,需要进行计算来计算权重并进行信息聚合,其中表示知识图谱中关系的个数。该模块使用TransE进行知识图谱嵌入需要额外的时间,其中表示一批训练三元组的数量。(2)我们设计的知识图谱增强算法仅需时间即可得到KG结构的一致性和扰动。(3)基于图的协同过滤需要时间进行用户-项目交互建模。计算InfoNCE损失的时间复杂度,其中是一个批次处理中唯一的用户和项目的数量。基于以上分析,我们的KGCL在与最先进的知识感知推荐模型[37, 39]竞争时实现了相当的时间复杂度。
4 实验Experiment
通过回答以下研究问题,我们进行了大量实验来评估我们的KGCL的性能:
RQ1:我们的KGCL在与不同类型的推荐方法竞争时表现如何?
- RQ2:我们的KGCL框架中的不同关键模块对整体性能有何贡献?
- RQ3:提出的KGCL模型在缓解推荐的数据稀疏性和噪声问题方面有多有效?
-
4.1 实验设置 Experimental Settings
4.1.1 数据集 Datasets
我们在从不同现实生活平台收集的三个公共数据集上进行实验:Yelp2018用于商业场所推荐,Amazon-Book用于产品推荐,MIND用于新闻推荐。表1给出了我们的实验数据集的统计信息,这些数据集具有不同的交互稀疏度和知识图谱特征。我们遵循[39]中的类似设置,通过将项目映射到Freebase实体来构建Yelp2018和Amazon-Book数据集的知识图谱[53]。在我们的实验中,我们只收集了两跳内的实体,因为很少有基线考虑在KG中建模多跳关系,并且这种关系通常是有噪声的和语义偏差的。在我们的知识图谱中,采用各种类型的实体(例如,场地类别/位置、图书作者/出版商)来生成实体依赖关系。对于新闻MIND数据集,我们遵循[30]中的数据预处理策略,基于Spacy-Entity-Linker工具和Wikidata构建知识图谱。在我们发布的模型实现中,可以使用摘要部分中的链接获得评估的数据集。<br />**表1 实验数据集的统计**<br />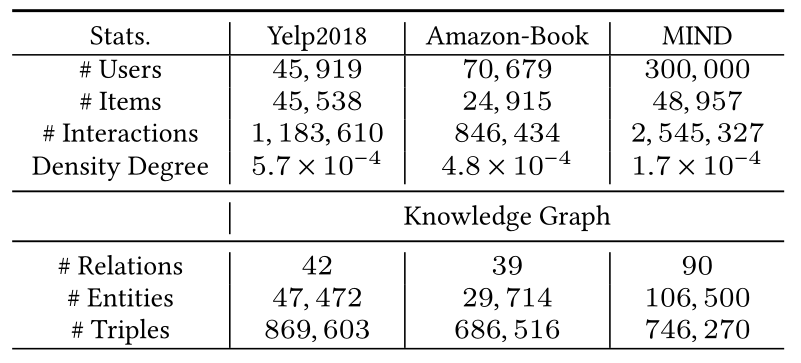
4.1.2 评估方案 Evaluation Protocols
为了公平的比较,我们采用全排名策略与[39,40]中的设置一致。具体来说,对于每个目标用户,我们将他/她所有未交互的项目视为负样本来推断该用户的偏好。对于性能评估,两个有代表性的指标:Recall@N和NDCG@N用于评估top-N推荐项目的准确性[39,46]。默认情况下,测试集中所有用户的平均评估结果以N = 20报告。
4.1.3 基线比较 Baselines for Comparison
我们将KGCL与各种推荐系统进行性能评估。
传统的协同过滤方法 BPR [25] 利用成对排序损失对项目候选进行排序是一种代表性的推荐方法。
基于MLP的神经协同过滤框架
- NCF [10] 它利用多层感知器赋予CF结构非线性特征交互。
基于图神经网络的协同过滤
- GC-MC [1] 它建立在图自编码器架构上,根据二分图中的链接捕获用户和项目之间的交互模式
- LightGCN [11] 这是一种最先进的基于GCN的推荐方法,它简化了用户和项目之间传递消息时的卷积运算。
自监督学习推荐系统
- SGL [44] 这种方法通过使用基于增强结构的自监督信号来增强基于图的CF框架,从而提供了最先进的性能。
基于嵌入的知识感知推荐
- CKE [51] 该方法采用TransR对项目的语义信息进行编码,并将其整合到去噪自编码器中,以知识库表示项目。
基于路径的知识感知推荐
- RippleNet [35] 它通过知识图传播用户偏好以及以该用户为根的构建路径。这是一个类似记忆的神经模型,用来改善用户的表现。
基于GNNs的KG-增强推荐 KG-enhanced Recommendation with GNNs
- KGCN [37] 它的目的是根据KG中的语义信息对高阶依赖上下文进行编码。KGCN的核心是将邻居信息偏差合并到实体表示的聚合消息中。
- KGAT [39] 该模型在知识感知协作图上设计了一个专注的消息传递方案,用于嵌入融合。相邻节点的相关性在传播过程中被区分。
- KGIN [40] 这是最近提出的KG增强推荐模型,用于识别用户的潜在意图,并进一步对用户意图项目和KG三元组进行关系路径感知聚合。
- CKAN [42] 引入异构传播机制来确定知识感知邻居的重要性,从而将协同过滤表示空间与知识图谱嵌入相结合。
- MVIN [29] 这是一个基于图形神经架构的多视图项目嵌入网络。考虑来自用户和实体侧的信息来学习项目的特征嵌入。
参数设置Parameter Settings 我们提出的KGCL是用PyTorch实现的。大多数比较基线都是基于统一推荐库RecBole [54]进行评估的。特别地,我们将所有方法的嵌入维数固定为64,以 的学习率和2048的批量进行模型优化。对于知识感知推荐模型,上下文跳数和内存大小分别设置为2和8。在我们的KGCL中,我们搜索温度参数
的学习率和2048的批量进行模型优化。对于知识感知推荐模型,上下文跳数和内存大小分别设置为2和8。在我们的KGCL中,我们搜索温度参数 和对比损失平衡参数
和对比损失平衡参数 ,范围为
,范围为 ,增量为0.1。此外,在
,增量为0.1。此外,在 的范围内搜索截断概率
的范围内搜索截断概率 和
和 。
。
4.2 与SOTA的性能比较 Performance Comparison with SOTA (RQ1)
表2 所有方法在Yelp、Amazon和MIND上的性能比较。上标*表示当p-value < 0.01水平时,改进具有统计学意义。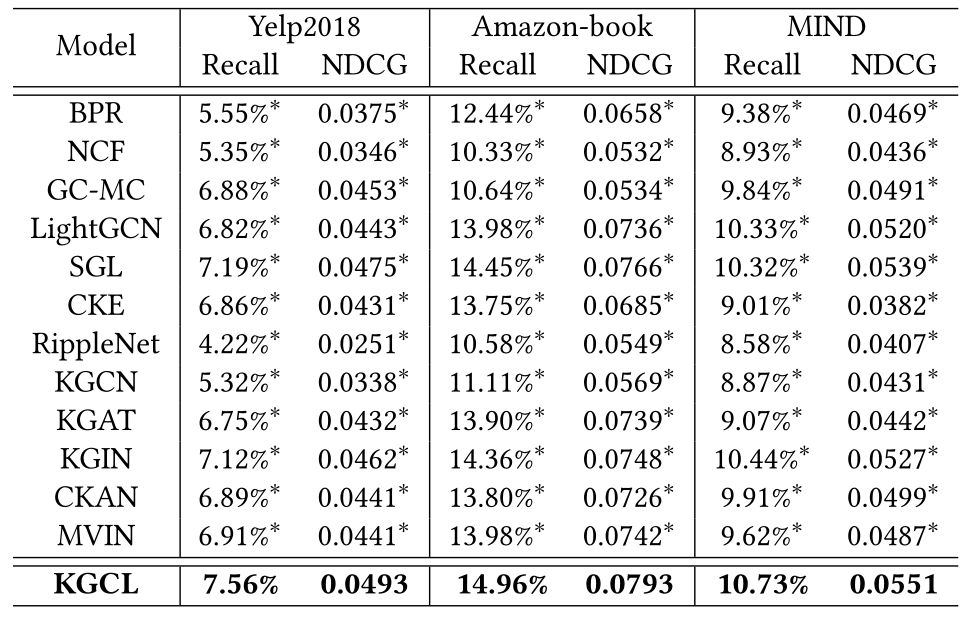
我们在表2中报告了所有方法的总体性能评估。从结果中,我们总结了以下观察结果:
- 在所有情况下,KGCL始终优于其他基线,这验证了将知识图谱嵌入整合到对比学习范式中的有效性。评估数据集的多样性因稀疏度、知识图谱特征和推荐场景而异。优越的结果证明了我们的KGCL框架的通用性和灵活性。总体而言,KGCL获得的改进可以归因于两个方面: i)受益于我们的知识图谱对比学习,KGCL可以去噪实体依赖关系并捕获准确的项目语义。ii) KGCL能够利用提取的项目知识来指导用于自监督信息的交互数据增强模式。
- 我们可以观察到,与BPR和NCF相比,大多数知识感知推荐系统取得了更好的性能。这证实了结合知识图谱信息来解决协同过滤中的稀疏性问题的有用性。在各种知识感知方法中,KGIN表现最好,它通过挖掘潜在意图来增强用户表现,并基于意图感知的关系路径进行嵌入传播。我们的KGCL和其他知识感知模型(例如,KGAT,CKAN,MVIN)之间的性能差距表明,噪声知识图谱误导了项目-项目语义相关的学习。
SGL取得的相对优越的性能表明了从未标记的用户行为中产生自监督信号以提高推荐的鲁棒性的合理性。与自监督推荐模型SGL不同,我们的KGCL使用知识引导的增强模式创建对比自监督信号,该模式有效地结合了基于KG的项目语义相关度,以鲁棒和显式的方式缓解交互稀疏性问题。
4.3 KGCL框架的消融研究Ablation Study of KGCL Framework (RQ2)
4.3.1 知识感知图增强模式的影响(Impact of Knowledge-aware Graph Augmentation Schema)
我们从知识图谱和用户-项目交互行为的角度研究了我们的知识感知图增强模式的效果。因此,我们设计了两种模型变体:
i)“w/o KGA”:KGCL的变体,在用户-项目交互图上没有知识引导的增强方案。取而代之的是,交互图的对比视图是用随机边采样构建的,用于互信息估计。
- ii)“w/o KGC”:我们从KGCL中移除了知识图谱对比学习组件,并将从我们的关系感知知识聚合编码的项目表示直接转发到基于图的对比学习CF框架中。
表3 KGCL模型变量对知识感知图增强模式的影响研究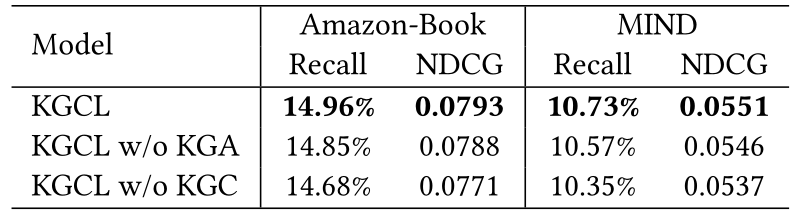
从表3中的结果可以清楚地看出,我们的KGCL框架的性能优势在所有情况下都可以实现。这一事实表明,所提出的基于交互图的知识引导的对比学习和知识图对比学习都可以有效地做出更好的推荐。
4.3.2 超参数灵敏度(Hyper-parameter Sensitivity)
我们进一步给出了我们的超参数和的评估结果,分别用于控制对比正则化和困难负样本采样的强度。具体地,和分别从和(0.1,0.2,0.3,0.4,0.5)的范围搜索。我们可以观察到,当=0.1,=0.2时性能最好,这表明较大的值可能会限制不同负例之间的区分能力。此外,的值越小,对比优化损失对主嵌入空间的影响越小。<br />**表4 ****和****对Amazon-Book数据集的影响**<br />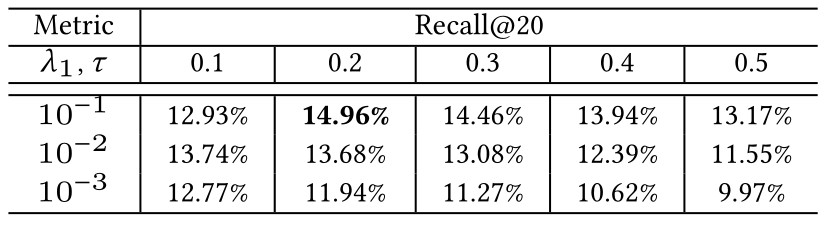
4.4 KGCL在缓解数据稀疏性和噪声影响方面的优势Benefits of KGCL in Alleviating Data Sparsity and Noise Effect (RQ3)
在这一小节中,我们通过评估KGCL在处理稀疏和噪声数据时的性能来研究它的鲁棒性。
4.4.1 稀疏用户交互Sparse User Interactions
为了研究我们的KGCL在处理没有足够交互的用户时的鲁棒性,我们遵循[50]中的类似设置,为Yelp2018和Amazon-Book生成了少于20个交互的稀疏用户集,并为MIND数据生成了5个交互。稀疏用户的结果如图6所示。<br />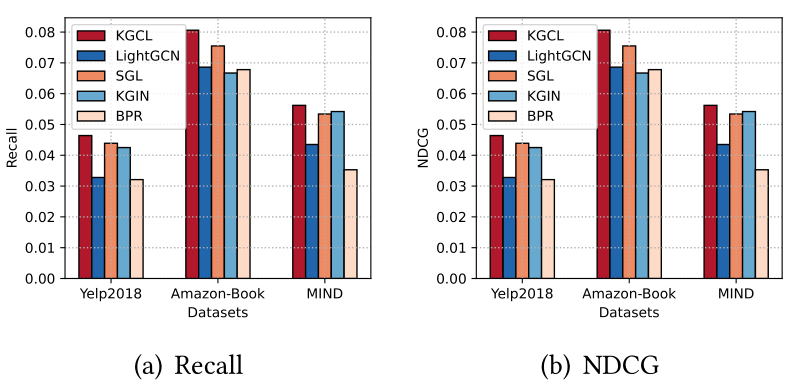<br />**图6 冷启动用户比较**
4.4.2 长尾项目推荐Long-tail Item Recommendation
为了证明我们的KGCL在长尾项目推荐中的作用,我们将所有项目分为五组,每组有相同数量的项目(交互密度从组0增加到组4)。对不同的项目组分别进行评价。结果如图5所示。<br />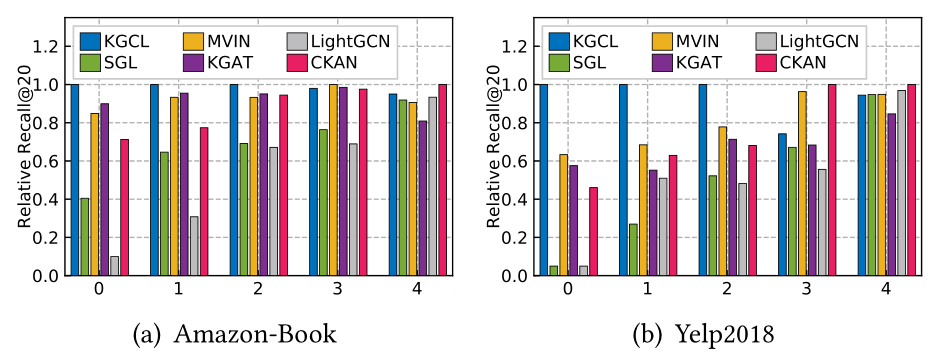<br />**图5 KGCL和基线之间不同项目相互作用密度程度的性能。**为了更好地呈现,召回值被标准化为范围[0,1]。
4.4.3 知识图谱噪声Knowledge Graph Noise
我们通过分别向知识图谱中注入噪声三元组并对KG中与长尾实体相关的项目进行测试来研究KGCL的鲁棒性。特别是,我们首先在测试集不变的现有KG数据中随机添加10%的噪声三元组,以模拟收集到的KG中有大量主题无关实体的情况。此外,为了模拟长尾实体引起的KG噪声场景,我们收集了20%的长尾实体,并在测试数据中过滤与这些长尾实体相关的项目来执行评估。结果如表5和图7所示。<br />**表5 缓解KG噪声的性能**<br />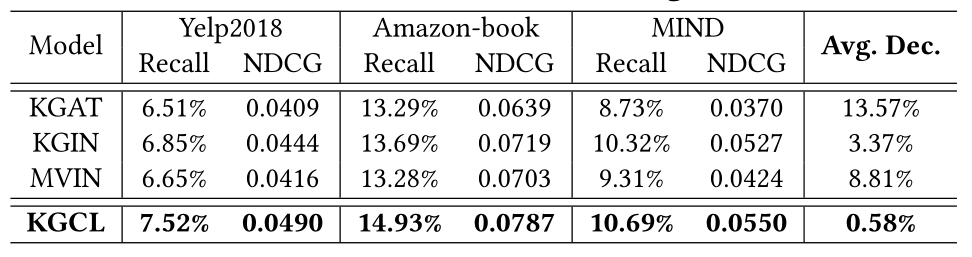<br />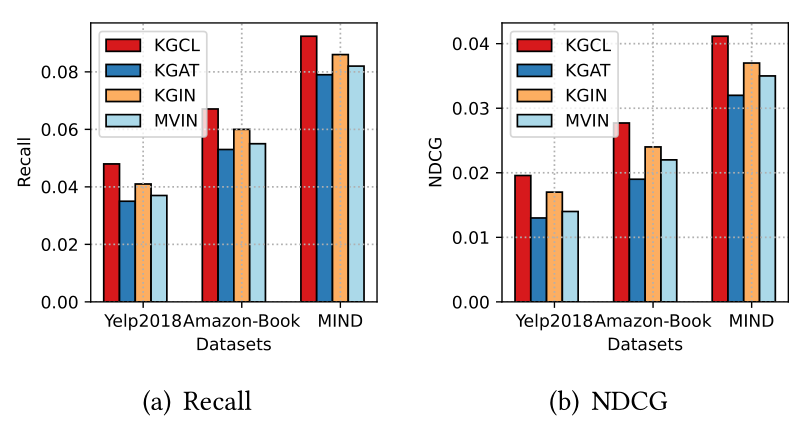<br />**图7 长尾KG实体连接的项目推荐性能比较**
- KGCL在所有情况下都优于SGL,这证明了与基于随机dropout的策略相比,我们的知识图谱引导的对比学习具有优越性。此外,KGCL的性能优于KGIN,表明有必要将知识图谱引导的自监督信号引入知识感知推荐系统中,以解决噪声知识图谱误导用户推荐偏好编码的问题。
- 考虑到推荐场景中项目经常呈现长尾分布,我们的KGCL显著提高了长尾项目的推荐性能。这一观察结果再次证明了KGCL方法在缓解推荐流行度偏差方面的优越性。但是,冷门项目不太可能被其他基线推荐。此外,KGCL与竞争对手的KG增强推荐系统(如KGAT、CKAN)相比的性能优势表明,盲目地将知识图谱信息融入到协同过滤中可能会存在项目关系噪声,不能有效地缓解流行度偏差。
- 我们的KGCL在与最先进的知识感知推荐模型竞争时,从噪声知识图谱中提取有用信息来辅助用户偏好建模方面取得最好的性能。具体地说,KGCL在缓解KG噪声方面的平均性能降幅最低(表5),而在知识实体稀疏的项目上的评估结果最好(图7)。这验证了我们的知识图谱对比学习范式在从噪声KG信息中发现相关项目语义方面的合理性。
4.5 案例研究(RQ4)Case Studies(RQ4)
我们使用新闻推荐的示例进行案例研究,以显示使用和不使用知识图谱对比学习的情况下的推理结果(如图8所示)。<br />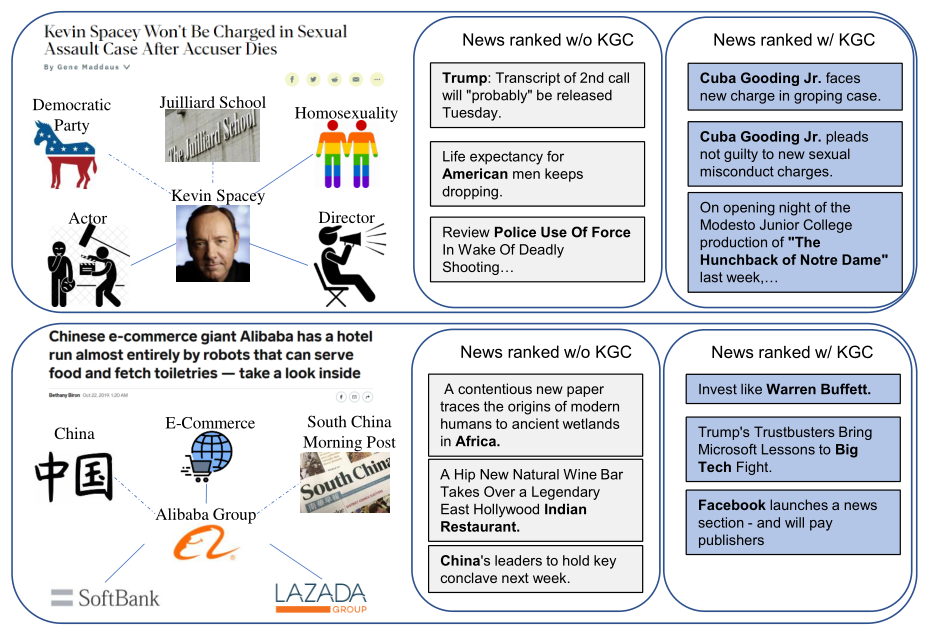<br />**图8 相关新闻排名w/和w/o KGCL的两个例子。**蓝色的新闻表示语义相关,粗体表示从新闻中提取的实体。<br /> 第一个新闻案例是关于名人_Kevin Spacey_和他有争议的婚外情。我们在提供的KG信息中显示了与这条新闻相关的实体,其中他的政治立场_Democratic Party_和他的毕业学校_Julliard School_显然与这条新闻无关。这些含有噪声的KG信息可能会通过引入关于政治或教育的有偏见的信息来误导用户表示。在右边,我们展示了三个与样本新闻最相似的新闻,分别由具有和不具有KG-aware对比学习的模型排序。具体地说,我们可以看到,没有KGC的模型排名的类似新闻都与民族和政治主题有关。其中,新闻话题是关于_Donald Trump_、_American People_和_Police Use of Force_,这些都与电影名人_Kevin Spacey_无关。相比之下,我们KGCL推断的结果都与这一消息密切相关,即电影名人_Cuba Gooding Jr._或者电影《The Hunchback of Notre Dame》。巧合的是,_Cuba Gooding Jr._面临着与_Kevin Spacey_类似的法律指控。在有效地去除KG信息的噪声之后,我们的方法可以将_Cuba Gooding Jr._和_Kevin Spacey_相互关联,以进行准确的推荐。<br /> 下面是另一个关于中国科技巨头_Alibaba_的新闻例子。同样,观察到的含有噪声的实体_China_和_South China Morning Post_可能会影响对媒体新闻和民族新闻的项目语义关联度的学习过程。我们可以观察到,推荐的类似新闻都是关于_China_、_India_和_Africa_的国家新闻。通过整合我们的知识图谱对比学习组件,我们的模型允许推荐框架通过消除含有噪声的实体依赖关系来捕捉项目之间准确的语义依赖关系。特别是,我们的KGCL识别的新闻是专门针对大型科技公司的,这些公司与目标新闻非常相关。总体而言,KGCL能够消除推荐系统对知识图谱信息的偏见,消除不相关实体的影响。
5 相关工作 Related work
5.1 知识图谱增强的推荐Knowledge Graph-enhanced Recommendation
现有的KG增强推荐方法大致可以分为两类:基于嵌入的方法和基于路径的方法。对于基于嵌入的方法[30,36,48,51],它们利用KG中的关系和实体来增强推荐系统中的语义表示。通常,这些方法应用转换约束来学习对用户和项目有意义的知识嵌入。例如,CKE[51]将不同类型的辅助信息合并到协同过滤框架中。在CKE模型中,项目结构知识的嵌入使用TransR[19]编码,文本和视觉知识用提出的自编码器学习。另一种有代表性的方法是DKN[36],它整合了新闻的语义表示,以学习更好的条目嵌入。<br /> 基于路径的方法[13,35,37,39,45]旨在通过构造信息传播的元路径来挖掘知识图谱中项目之间的潜在信息。例如,MCRec[13]为Top-N推荐设计了基于元路径的相互注意机制,该机制产生基于用户、项目和元路径的上下文表示。总体而言,与大多数基于嵌入的方法相比,它们提供了相对更好的性能,因为这些方法可以捕获高阶知识感知依赖关系。然而,基于路径的方法高度依赖于元路径的设计,而元路径的设计依赖于领域知识和人的努力。此外,沿着不同的元路径聚合信息非常耗时,导致知识感知推荐系统的效率低下。
5.2 推荐系统的对比学习Contrastive Learning for Recommender System
近年来,对比学习在为不同领域提供自监督信号,如自然语言处理[8]和图像数据分析[6],引起了极大的关注。它旨在通过从不同角度对比正负样本来学习高质量的区别性表征。最近的一些尝试将自监督学习纳入了推荐系统[21,22,43,44]。例如,SGL[44]使用不同的策略对图连接结构执行丢弃操作,即节点丢弃、边丢弃和随机游走。此外,CML[43]通过对比学习考虑了用户和项目之间的多行为关系来增强推荐系统。受这些现有对比学习框架的启发,本文通过有效整合知识图表示和用户-项目交互增强,提出了一种新的面向推荐的图对比学习范式。
6 讨论 Conclusion
在这项工作中,我们提出的KGCL框架进行了初步的尝试,探索了知识图谱的语义,并在知识引导的对比学习范式下缓解了推荐的数据噪声问题。基于对用户偏好学习的知识歧义项目的影响的估计,KG-aware数据增强被用于研究辅助自监督信号。这项工作为知识感知推荐系统的研究开辟了新的可能性。在几个真实数据集上的大量实验证明了KGCL相对于各种先进方法的优越性。

若有收获,就点个赞吧
0 人点赞
