Self-supervised Graph Learning for Recommendation
- Jiancan Wu, Xiang Wang, Fuli Feng, et al. Self-supervised Graph Learning for Recommendation[C]. In SIGIR 2021.
-
摘要(Abstract)
用于推荐的用户-项目图上的表征学习已经从使用单个ID或交互历史发展到利用高阶邻居。这导致了用于推荐的图卷积网络(GCNs)的成功,例如PinSage和LightGCN。尽管有效,但我们认为它们存在两个局限性:(1)高度节点对表征学习的影响更大,恶化了低度(长尾)项目的推荐;(2)表征容易受到噪声交互的影响,因为邻域聚合方案进一步扩大了观察到的边的影响。<br /> 在本文中,我们探索了用户-项目图上的自监督学习,以提高推荐的准确性和鲁棒性。其思想是用一种辅助的自监督任务来补充经典的有监督的推荐任务,该任务通过自区分来加强节点表示学习。具体地说,我们生成节点的多个视图,最大化同一节点的不同视图与其他节点的不同视图之间的一致性。我们设计了三种算子来生成视图--节点丢弃、边丢弃和随机游走--它们以不同的方式改变了图的结构。我们将这种新的学习范式称为自监督图学习(SGL),并在最新的模型LightGCN上实现。通过理论分析,我们发现SGL具有自动挖掘困难负样本的能力。在三个基准数据集上的实验结果证明了SGL算法的有效性,它提高了推荐的准确率,尤其是对长尾项目的推荐准确率,以及对交互噪声的鲁棒性。我们的实现在[https://github.com/wujcan/SGL](https://github.com/wujcan/SGL)
关键字(Keywords)
1 引言(Introduction)
从交互数据中学习高质量的用户和项目表示是协同推荐的主题。早期的工作如矩阵分解(MF)[34]将每个用户(或项目)的单个ID投影到嵌入向量中。一些后续研究[20,25]用交互历史丰富了单一ID,以学习更好的表征。最近,表征学习已经发展到利用用户-项目图中的高阶连通性。该技术的灵感来自于图卷积网络(GCNs),它提供了一种端到端的方式将多跳邻居集成到节点表示学习中,并实现推荐的最先进的性能[19,38,46,50]。<br /> 尽管有效,但当前基于GCN的推荐模型存在一些局限性:
稀疏监督信号Sparse Supervision Signal。大多数模型在有监督的学习范式下处理推荐任务[19,21,34],其中监督信号来自观察到的用户-项目交互。然而,与整个交互空间相比,观察到的交互作用是非常稀疏的[3,18],这使得学习质量表示是不够的。
- 倾斜的数据分布Skewed Data Distribution。观察到的交互作用通常呈幂律分布[9,30],其中长尾由缺乏监督信号的低度项目组成。相比之下,高度项目在邻域聚合和监督损失中出现的频率更高,因此对表征学习的影响更大。因此,GCN很容易偏向高度项目[5,36],牺牲低度(长尾)项目的性能。
交互作用中的噪音Noises in Interactions。用户提供的大多数反馈是隐式的(例如,点击、查看),而不是显式的(例如,评级、喜欢/不喜欢)。因此,观察到的交互通常包含噪声,例如,用户被误导点击一项目并在消费它之后发现它不感兴趣[44]。GCNs中的邻域聚合机制放大了交互对表征学习的影响,使得学习更容易受到交互噪声的影响。
在本工作中,我们重点探讨推荐中的自监督学习,以解决上述局限性。虽然SSL在计算机视觉(CV)[11,40]和自然语言处理(NLP)[10,26]中很流行,但在推荐中相对较少涉及。其思想是设置一个辅助任务,从输入数据本身提取额外的信号,特别是通过利用未标记的数据空间。例如,Bert[10]随机掩蔽句子中的一些标记,将掩蔽标记的预测设置为辅助任务,以捕捉标记之间的依赖关系;RotNet[11]随机旋转标记的图像,在旋转的图像上训练模型,以获得对象识别或图像分类的掩蔽任务的改进表示。与有监督学习相比,SSL允许我们通过改变输入数据来利用未标记的数据空间,从而显著改善下游任务[6]。<br /> 这里,我们希望将SSL的优势引入推荐表示学习,这与CV/NLP任务不同,因为数据是离散的和相互连接的。为了解决上述基于GCN的推荐模型的局限性,我们将辅助任务构造为区分节点本身的表示。具体地说,它由两个关键部分组成:(1)**数据增强**,为每个节点生成多个视图;(2)**对比学习**,与其他节点相比,最大化同一节点的不同视图之间的一致性。对于用户-项目图上的GCN,图结构作为输入数据,对表征学习起着至关重要的作用。从这个角度来看,通过改变图邻接矩阵来构造“未标记”数据空间是很自然的,我们为此开发了三个算子:节点丢弃、边丢弃和随机游走,每个算子的工作原理不同。之后,我们在改变的结构上基于GCN进行对比学习。因此,SGL通过探索节点之间的内在联系来增强节点表示学习。<br /> 在概念上,我们的SGL在以下几个方面补充了现有的基于GCN的推荐模型:(1)节点自区分提供辅助监督信号,这是对仅来自观察到的交互的经典监督的补充;(2)增强算子,特别是边丢弃,通过有意地减少高度节点的影响来帮助缓解度偏差;(3)节点的多视角w.r.t。不同的局部结构和邻域增强了模型对交互噪声的鲁棒性。最后,我们对对比学习范式进行了理论分析,发现它有挖掘困难负样本的作用,这不仅提高了性能,而且加快了训练过程。<br /> 值得一提的是,我们的SGL是模型不可知的,可以应用于任何包含用户和/或项目嵌入的基于图的模型。在这里,我们在简单但有效的模型LightGCN[19]上实现它。在三个基准数据集上的实验研究表明,SGL算法是有效的,它显著提高了推荐的准确率,特别是在长尾项目上,并增强了对交互噪声的鲁棒性。我们总结了这项工作的贡献如下:
我们设计了一种新的学习范式SGL,它以节点自区分为自监督任务,为表征学习提供辅助信号。
- 除了缓解度偏差和增强对交互噪声的鲁棒性外,我们在理论上证明了SGL固有地鼓励从困难负样本中学习,由Softmax损失函数中的温度超参数控制。
我们在三个基准数据集上进行了大量的实验来证明SGL的优越性。
2 预备知识 Preliminaries
我们首先总结了基于GCN的协同过滤模型的常见范式。设和分别为用户和项目的集合。设为观察到的交互,其中表示用户之前采用了项目。现有的大多数模型[19,38,46]构造了一个二部图,其中节点集涉及所有用户和项目,边集表示观察到的交互。<br />** 重述GCN**。核心是在上应用邻域聚合方案,通过聚合邻居节点的表示来更新ego节点的表示:<br /> (1)<br />其中表示第层的节点表示,表示上一层的节点表示,表示ID嵌入(可训练参数)。表示邻域聚合的函数,从向量级更容易解释:<br /> (2)<br /> 为了更新第层的ego节点的表示,它首先在第层聚合其邻居的表示,然后与其自己的表示合并。和[12,15,41,48]有多种设计。我们可以看到,第层的表示编码了图中的阶邻居。在获得层表示之后,可以有读出函数来生成用于预测的最终表示:<br /> (3)<br /> 常见设计包括仅最后一层[38,50]、级联(concatenation)[46]和加权和[19]。<br />** 监督学习损失**。预测层建立在最终表示的基础上,以预测采用的可能性有多大。经典解决方案是内积,它支持快速检索:<br /> (4)<br /> 为了优化模型参数,现有的工作通常将任务定义为监督学习,其中监督信号来自观察到的交互作用(也是的边)。例如,鼓励预测值接近ground真实值,并从缺失数据中选择反例[21]。除了上述逐点学习,另一个常见的选择是成对贝叶斯个性化排名(BPR)损失[34],它强制预测观察到的交互比未观察到的交互得分更高:<br /> (5)<br />其中是训练数据,是未观察到的交互。在这项工作中,我们选择它作为主要的监督任务。<br />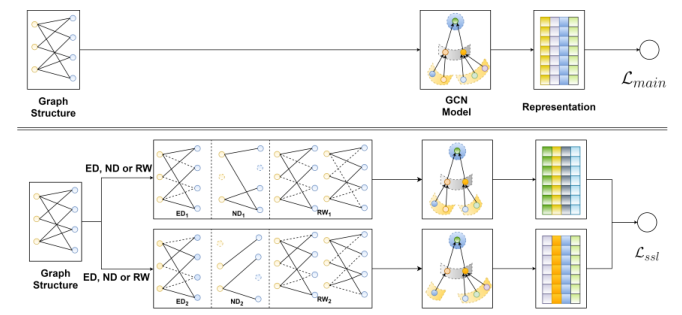<br />**图1 SGL的整体系统框架**。上层展示了主监督学习任务的工作流程,下层展示了在图结构上进行增强的SSL任务的工作流程。
3 方法(Methodology)
我们提出了自监督图学习(SGL)范式,它用自监督学习来辅助主监督任务。图1说明了SGL的工作流程。具体地说,自监督任务(也称为借口任务或辅助任务)是根据输入数据中的相关性来构造监督信号。<br /> 具体地说,我们介绍了如何执行数据增强来生成多个表示视图,然后基于生成的表示进行对比学习来构建辅助任务。以多任务学习的方式将SSL与经典的GCN相结合。然后,从梯度层面对SSL进行了理论分析,揭示了它与困难负样本的联系。最后,我们分析了SGL的复杂性。
3.1 基于图结构的数据增强(Data Augmentation on Graph Structure)
直接移植CV和NLP任务[6,10,17,47]中的数据增强对于基于图的推荐是不可行的,原因在于:(1)用户和项目的特征是离散的,如one-hot ID等分类变量。因此,图像上的增强算子,如随机裁剪、旋转或模糊,是不适用的。(2)更重要的是,与将每个数据实例视为孤立的CV和NLP任务不同,交互图中的用户和项目本质上是相互连接和依赖的。因此,我们需要为基于图的推荐定制新的增强算子。<br /> 二分图建立在观察到的用户-项目交互的基础上,因此包含协同过滤信号。具体地,第一跳邻域直接描述ego用户和项目节点-即,用户的历史项目(或项目的交互用户)可以被视为用户(或项目)的预先存在的特征。用户(或项目)的第二跳相邻节点展示相似的用户w.r.t.行为(或类似的项目w.r.t.受众)。此外,从用户到项目的高阶路径反映了用户对项目的潜在兴趣。毫无疑问,挖掘图结构中的内在模式有助于表征学习。因此,我们在图结构上设计了三个算子,节点丢弃、边丢弃和随机游走,以创建节点的不同视图。算子可以统一表示如下:<br /> (6)<br />其中两个随机选择和独立地应用于图,并建立节点和的两个相关视图。我们对增强算子的阐述如下:
节点丢弃Node Dropout (ND)。使用概率
 ,将从图中丢弃每个节点及其连接的边。具体地说,
,将从图中丢弃每个节点及其连接的边。具体地说, 和
和 可以建模为:
可以建模为:
 (7)
(7)
其中 是应用于节点集
是应用于节点集 以生成两个子图的两个掩码向量。因此,这种增强有望从不同的增强视图中识别有影响力的节点,并使表示学习对结构变化不那么敏感。
以生成两个子图的两个掩码向量。因此,这种增强有望从不同的增强视图中识别有影响力的节点,并使表示学习对结构变化不那么敏感。
- 边缘丢弃Edge Dropout (ED)。它以丢弃率
 丢弃图中的边。两个独立的过程表示为:
丢弃图中的边。两个独立的过程表示为:
 (8)
(8)
其中 是边集
是边集 上的两个掩码向量。只有邻域内的部分连接对节点表示有贡献。因此,将这两个子图耦合在一起的目的是捕获节点局部结构的有用模式,并进一步赋予表示对噪声交互的更强鲁棒性。
上的两个掩码向量。只有邻域内的部分连接对节点表示有贡献。因此,将这两个子图耦合在一起的目的是捕获节点局部结构的有用模式,并进一步赋予表示对噪声交互的更强鲁棒性。
- 随机游走Random Walk (RW)。上述两个操作符生成一个在所有图卷积层之间共享的子图。为了探索更高的性能,我们考虑为不同的层分配不同的子图。这可以看作是使用随机游走为每个节点构造一个单独的子图31。假设我们在每一层选择边缘丢弃(具有不同的比率或随机种子),我们可以通过使掩码向量对层敏感来表示RW:
 (9)
(9)
其中 是位于层
是位于层 的边集
的边集 上的两个掩码向量。
上的两个掩码向量。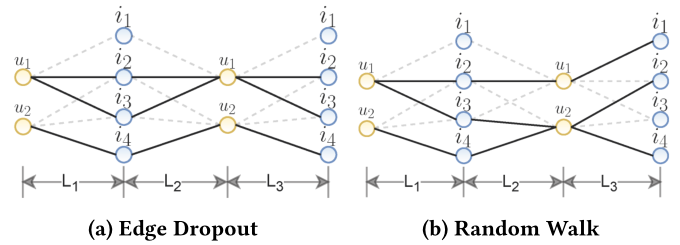
图2 一个三层GCN模型中高阶连通性的示例,具有边缘丢弃(左)和随机游走(右)。对于随机游走,图结构在各层之间不断变化,而不是边丢弃。因此,在节点 和
和 之间存在三阶路径,而在边缘丢弃中是不存在的。
之间存在三阶路径,而在边缘丢弃中是不存在的。
为了简单起见,我们将这些增强应用于每个epoch的图结构-即,我们在新的训练epoch开始为每个节点生成两个不同的视图(对于RW,在每个层生成两个不同的视图)。请注意,对于两个独立的过程(即 和
和 ),丢弃和掩蔽率保持相同。我们把不同比率的调整留在了以后的工作中。值得一提的是,只涉及丢弃和掩蔽操作,没有添加任何模型参数。
),丢弃和掩蔽率保持相同。我们把不同比率的调整留在了以后的工作中。值得一提的是,只涉及丢弃和掩蔽操作,没有添加任何模型参数。
3.2 对比学习(Contrastive Learning)
在建立了节点的增强视图后,我们将同一节点的视图视为正对(即),将任何不同节点的视图视为负对(即。正对的辅助监督鼓励同一节点不同视图之间的一致性,负对的监督加强不同节点之间的区分。形式上,我们遵循SimCLR[6],采用对比损失InfoNCE[14],以最大化正对的一致性并最小化负对的一致性:<br /> (10)<br />其中度量两个向量之间的相似度,设置为余弦相似度函数;是超参数,称为Softmax中的温度。类似地,我们获得项目侧的对比损失。结合这两个损失,我们得到自监督任务的目标函数:
3.3 多任务训练(Multi-task Training)
为了通过SSL任务改进推荐,我们利用多任务训练策略来联合优化经典推荐任务(参见等式(5))和自监督学习任务(参见等式(10))<br /> (11)<br />其中是中的模型参数集,因为没有引入额外的参数;和分别是控制SSL和正则化强度的超参数。我们还考虑了替代优化方法的预训练和的微调。详见第4.4.2节。
3.4 SGL的理论分析(Theoretical Analyses of SGL)
在本节中,我们将对SGL进行深入分析,旨在回答这个问题:推荐模型如何从SSL任务中获益?为此,我们研究了等式(10)中的自监督损失,发现了一个原因:它具有执行困难负样本挖掘的内在能力,这对优化贡献了大而有意义的梯度,并指导了节点表示学习。在下文中,我们将一步一步地介绍我们的分析。<br /> 形式上,对于节点,自监督损失的梯度_w.r.t._表示如下:<br /> (12)<br />其中是等式(10)中单个节点的单个项目;是另一个节点,用作节点的负视图;和分别表示正节点和负节点对梯度w.r.t.的贡献:<br /> (13)<br /> (14)<br />其中;和是节点在不同视图下的归一化表示;类似于节点的符号(参见等式(14)),其范数与以下项成正比:<br /> (15)<br />由于和都是单位向量,我们可以引入另一个变量来简化等式(15),如下所示:<br /> (16)<br />其中直接反映了正节点和负节点之间的表示相似性,根据相似性,我们可以将负节点大致地分为两类:(1)困难负节点,其表示与正节点的表示相似(即),从而难以在潜在空间中区分和;(2)容易负节点,与正节点不相似(即),容易区分。为了研究困难负样本和容易负样本的贡献,我们通过分别设置 = 1和 = 0.1,在图3a和3b中绘制随节点相似性变化的曲线。显然,在不同的条件下,负节点的贡献彼此显著不同。具体地说,如图3a所示,在τ=1的情况下,的值落在(0,1.5)的范围内,并且随着的变化而略有变化。这表明负样本,无论是困难的还是容易的,对梯度的贡献都是相似的。相反,如图3b所示,当设置τ=0.1时,困难负样本的值可以达到4000,而容易负样本的贡献正在消失。这表明,困难负节点提供更大的梯度来指导优化,从而使节点表示更具区分性,并加速训练过程[33]。<br />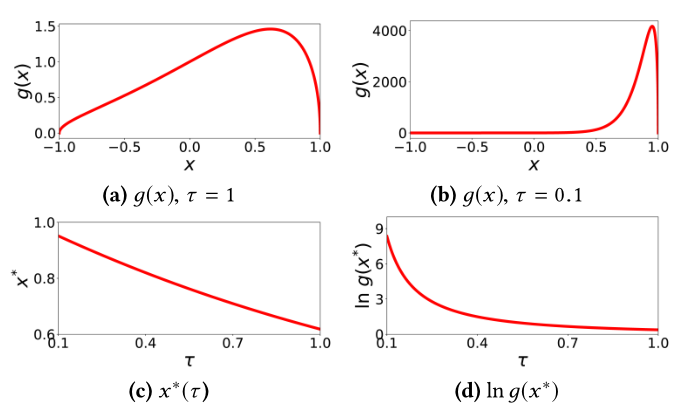<br />**图3 ****在****=1和****=0.1时****的函数曲线,以及****w.r.t. 的最大值的对数及其****最优位置**,即和。<br /> 这些发现启发我们探索对最大值的影响。通过将的导数趋近于零,可以得到的最大值。为了了解如何随变化,我们将其对数表示为:<br /> (17)<br /> 我们分别在图3c和3d中给出了和的曲线。随着的减小,最有影响力的负节点变得更类似于正节点(即接近0.9),而且它们的贡献被超指数地放大(即接近)。因此,适当地设置可以使SGL自动执行困难负样本挖掘。<br /> 值得一提的是,我们的分析灵感来自以前的研究[24],但存在主要差异:(1)[24]将困难负样本定义为与正样本的相似度接近于零的样本(即),将容易负样本定义为明显不相似的样本(即);(2)它没有涉及的区域,但这在我们的例子中是至关重要的。创新性地,我们在的区域提供了一个更细粒度的视图,以突出softmax中的温度超参数在挖掘困难负样本中的关键作用。
3.5 SGL的复杂性分析(Complexity Analyses of SGL)
在这一小节中,我们分析了以ED为策略和LightGCN为推荐模型的SGL的复杂性;其他选择也可以进行类似的分析。由于SGL没有引入可训练参数,因此空间复杂度与LightGCN相同[19]。由于模型结构没有变化,模型推理的时间复杂度也是相同的。在接下来的部分中,我们将分析SGL训练的时间复杂度。<br /> 假设用户-项目交互图中的节点数和边数分别为和。设表示epochs,表示每个训练批次的大小,表示嵌入大小,表示GCN层数,表示SGL-ED的保持概率。复杂度主要来自两个部分:
- 邻接矩阵的正则化。由于每个epoch生成两个独立的子图,假设完全训练图和两个子图的邻接矩阵中的非零元素个数分别为
 ,
, 和
和 ,则其总复杂度为
,则其总复杂度为 。
。 评估自监督损失。在我们的分析中,我们只考虑内积。如等式(10)所定义,在计算用户侧的InfoNCE损失时,我们将所有其他用户节点视为负样本。在一个批次内,分子和分母的复杂度分别为
 和
和 ,其中
,其中 为用户数。因此每个epoch的用户端和项目端的总复杂度为
为用户数。因此每个epoch的用户端和项目端的总复杂度为 。因此,整个训练阶段的时间复杂度为
。因此,整个训练阶段的时间复杂度为 。另一种降低时间复杂度的方法是只将批次中的用户(或项目)视为负样本[6,49],导致总时间复杂度为
。另一种降低时间复杂度的方法是只将批次中的用户(或项目)视为负样本[6,49],导致总时间复杂度为 。
。我们在表1中总结了LightGCN和SGL-ED在训练上的时间复杂度。LightGCN和SGL-ED的分析复杂度实际上是一个量级,因为LightGCN的增加只是缩小了LightGCN的复杂度。在实践中,以Yelp2018数据为例,为0.8的SGLED(Alternative)的时间复杂度大约是LightGCN的3.7倍,考虑到我们将在4.3.2节中展示的收敛速度的加速,这是完全可以接受的。测试平台为配备Inter i7-9700K CPU(32 GB内存)的NVIDIA Titan RTX显卡。对于LightGCN和SGL-ED(Alternative),Yelp2018上每个epoch的时间开销分别为15.2s和60.6s,这与复杂度分析是一致的。<br />**表1 LightGCN与SGL-ED分析时间复杂度的比较**<br />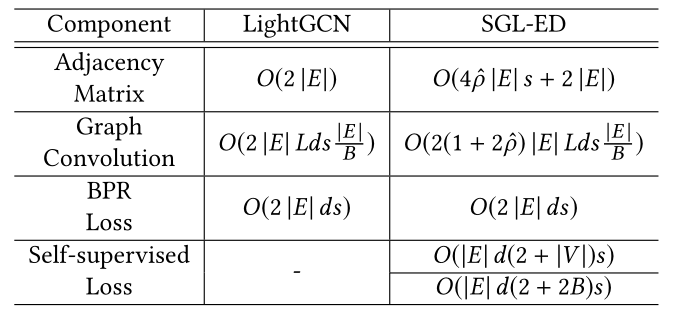
4 实验(Experiment)
为了证明SGL的优越性并揭示其有效性的原因,我们进行了大量的实验并回答了以下研究问题:
RQ1:与最先进的CF车型相比,SGL的w.r.t. top-K推荐性能如何?
- RQ2:在协同过滤中执行自我监督学习有什么好处?
-
4.1 实验设置(Experimental Settings)
我们在三个基准数据集上进行实验:Yelp2018[19,46],Amazon-Book[19,46],以及Alibaba-iFashion[8]。在[19,46]之后,我们对Yelp2018和Amazon-Book使用相同的10核设置。Alibaba-iFashion更加稀疏,我们随机采样30万用户,使用他们在时尚服装上的所有互动。表2汇总了所有三个数据集的统计数据。<br />**表2 数据集的统计数据**<br />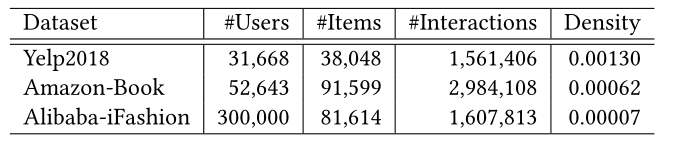<br /> 我们遵循[46]中描述的相同策略,以7:1:2的比例将交互划分为训练、验证和测试集。对于测试集中的用户,我们遵循the all-ranking protocol[46]来评估TOP-K推荐性能,并报告average Recall@K和NDCG@K,其中K=20。
4.1.1 比较方法(Compared Methods)
我们将提出的SGL与以下CF模型进行了比较:
NGCF[46] 这是一种基于图的CF方法,主要遵循标准GCN[12]。它还在消息传递期间将二阶特征交互编码到消息中。我们在建议的范围内调整正则化系数
 和GCN层数。
和GCN层数。- LightGCN[19] 该方法设计了轻量化图卷积,提高了训练效率和生成能力。类似地,我们调整λ2和GCN层数。
- Mult-VAE[28] 这是一种基于变分自编码器(VAE)的基于项目的CF方法。它通过一个额外的重建目标进行优化,这可以被视为SSL的特例。我们按照提出的模型设置并调整dropout ratio和
 。
。 DNN+SSL[49] 这是一种最先进的基于SSL的推荐方法。该算法以DNNs作为项目的编码器,对项目的已有特征采用特征掩蔽(FM)和特征丢弃(FD)两种增强算子。在没有可用项目特征的情况下,我们改为对项目的ID嵌入应用增强。我们按照原始论文中的建议调整DNN体系结构(即层数和每的神经元的数量)。
由于之前的工作[19,28,46]已经证实了潜在基线的优越性,我们放弃了潜在基线,如MF [34],NeuMF [21],GCMC [38]和PinSage [50]。在LightGCN上,我们实现了SGL的三种变体,分别称为SGL-ND、SGL-ED和SGL-RW,他们分别具有Node Dropout、Edge Dropout和Random Walk。
4.1.2 超参数设置(Hyper-parameter Settings)
为了公平比较,所有模型都是从零开始训练,用Xavier方法初始化[13]。模型由Adam优化器优化,学习率为0.001,小批量为2048。早期停止策略与NGCF和LightGCN相同。提出的SGL方法继承了共享超参数的最优值。对于独特的SGL,我们分别在,和的范围内调整、和。
4.2 性能比较Performance Comparison (RQ1)
4.2.1 与LightGCN的比较(Comparison with LightGCN)
表3 与LightGCN在不同层的性能比较
LightGCN在Yelp2018和AmazonBook上的表现都是抄袭其原论文。括号中的百分比表示相对于LightGCN的性能改进。粗体表示最佳结果。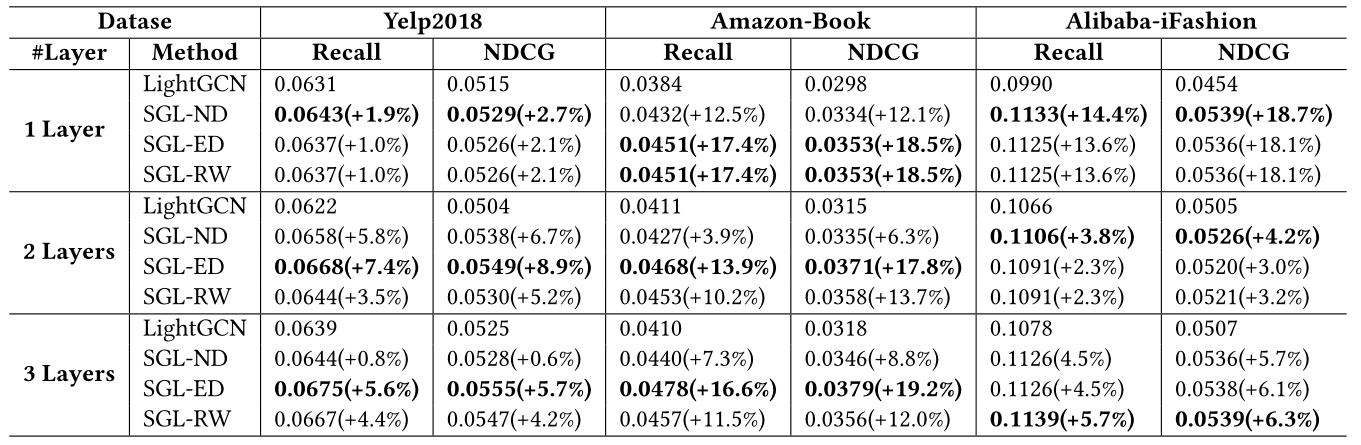
表3显示了SGL和LightGCN之间的结果比较。我们发现:在大多数情况下,三个SGL实现的性能远远优于LightGCN,这表明用自监督学习来补充推荐任务的优越性。
- 在SGL家族中,SGL-ED在10个或18个案例中取得了最好的性能,而SGL-RW在所有三个数据集上的表现也都好于SGL-ND。我们将这些归因于边丢弃算子捕获图结构中固有模式的能力。此外,在较密集的数据集(Yelp2018和Amazon-Book)上,SGL-ED的性能好于SGL-RW,而在较稀疏的数据集(Alibaba-iFashion)中,SGL-ED的性能略差。一个可能的原因是,在较稀疏的数据集中,ED更有可能阻止低度节点(非活跃用户和不受欢迎的项目)的连接,而RW可以在不同的层恢复它们的连接,如图2中所示的节点
 和
和 的情况。
的情况。 - SGL-ND比SGL-ED和SGL-RW相对不稳定。例如,在Yelp2018和Amazon-Book上,SGL-ED和SGL-RW的结果随着层的加深而增加,而SGL-ND则表现出不同的模式。节点丢弃可以被视为边丢弃的特例,即丢弃几个节点周围的边。因此,删除高度节点会极大地改变图的结构,从而影响信息聚合,使训练不稳定。
- Amazon-Book和Alibaba-iFashion上的改进比Yelp2018上的改进更显著。这可能是由数据集的特性造成的。具体地说,在Amazon-Book和Alibaba-iFashion中,来自用户-物品交互的监督信号太稀疏,不能指导LightGCN中的表征学习。受益于自监督任务,SGL获得了辅助监督来辅助表征学习。
将模型深度从1增加到3可以提高SGL的性能。这表明利用SSL可以增强基于GCN的推荐模型的泛化能力,即不同节点之间的对比学习有助于解决节点表示的过平滑问题,从而避免过拟合问题。
4.2.2 与最先进技术的比较(Comparison with the State-of-the-Arts)
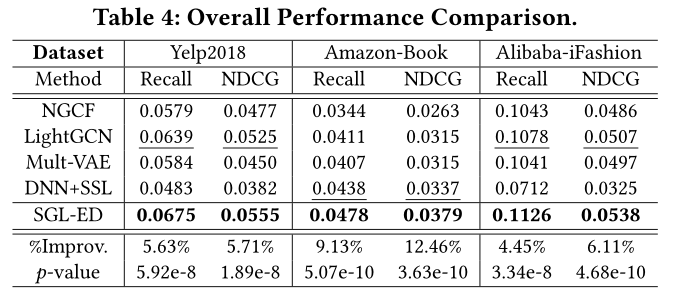
在表4中,我们总结了不同基线的性能比较。我们发现:
(1) SGL-ED始终跑赢所有基线。这再次验证了引入自监督学习的合理性和有效性。
- (2) LightGCN取得了比NGCF和Mult-VAE更好的性能,这与LightGCN论文的主张一致。Mult-VAE在Alibaba-iFashion上的表现与NGCF和LightGCN不相上下,而在Amazon-Book上则优于NGCF。
- (3) DNN+SSL是Amazon-Book上最强的基线,可见SSL在推荐方面的巨大潜力。令人惊讶的是,在其他数据集上,DNN+SSL的表现比SGL-ED差得多。这表明在ID嵌入上直接应用SSL可能比在图表示上应用SSL更次优、更差。
- (4) 此外,我们进行了显著性检验,其中p值< 0.05表示SGL-ED相对于最强基线的改进在所有六个cases中具有统计学显著性。
4.3 SGL的优势Benefits of SGL (RQ2)
在这一部分中,我们从三个方面研究了SGL的好处:(1)长尾推荐;(2)训练效率;(3)对噪声的鲁棒性。由于篇幅有限,我们只报道了SGL-ED的结果,而其他变体也有类似的观察结果。
4.3.1 长尾推荐(Long-tail Recommendation)
正如引言中提到的,基于GNN的推荐模型容易受到长尾问题的影响。为了验证SGL是否有希望解决这个问题,我们根据流行度将项目分为十个组,同时保持每个组的交互总数相同。GroupID越大,项目的度数就越大。然后,我们将整个数据集的Recall@20指标分解为单个组的贡献,如下所示:<br /><br />其中是用户数,和分别是Top-K推荐列表中的项目和用户的测试集中的相关项目。因此,衡量第组的推荐性能。我们报告了图4中的结果,并发现:<br />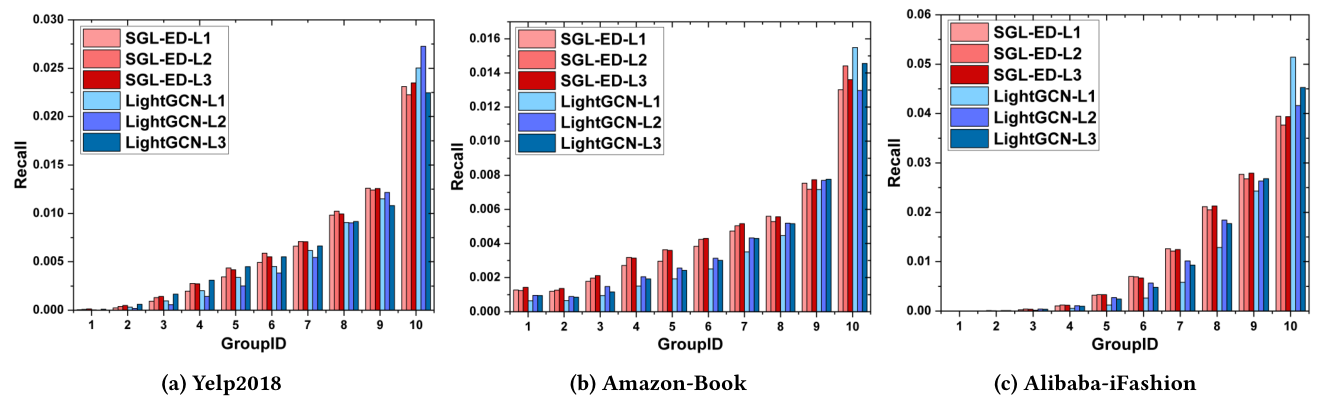<br />**图4 SGL-ED和LightGCN在不同题组上的表现比较**。图例中的后缀表示GCN层的数量。
- LightGCN倾向于推荐度数较高的项目,而让长尾项目曝光度低一些。具体而言,虽然只包含0.83%、0.83%和0.22%的项目空间,但第10组对三个数据集中召回得分的贡献分别为39.72%、39.92%和51.92%。这承认,由于稀疏的交互信号,LightGCN很难学习长尾项目的高质量表示。我们的SGL显示了缓解这一问题的潜力:在三个数据集中,10组的贡献率分别下降到36.27%、29.15%和35.07%。
联合分析表。如图3和图4所示,我们发现SGL的性能提升主要来自于通过稀疏交互来准确推荐项目。这再次验证了表征学习大大受益于辅助监督,从而建立了比LightGCN更好的这些项目的表征。
4.3.2 训练效率(Training Efficiency)
自监督学习已经在预训练自然语言模型[10]和图结构[23,31]中证明了它的优越性。因此,我们想要研究它对训练效率的影响。图5显示了SGL-ED和LightGCN在Yelp2018和Amazon-Book上的训练曲线。随着epoch数的增加,上面的子图显示了训练损失的变化,而下面的子图记录了测试集中的性能变化。我们有以下观察所得:<br />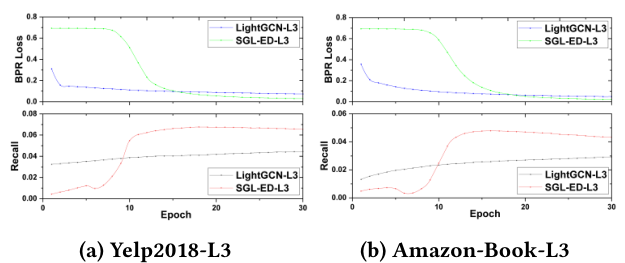<br />**图5 SGL-ED和LightGCN在三个数据集上的训练曲线**。图例中的后缀表示层编号
显然,SGL在Yelp2018和Amazon-Book上的收敛速度要比LightGCN快得多。特别是,SGL在第18和第16个epoch达到最佳性能,而LightGCN在这两个数据集中分别达到720和700个epochs。这表明我们的SGL可以大大减少训练时间,同时取得了显著的改进。我们将这种加速归因于两个因素:(1)SGL采用InfoNCE损失作为SSL目标,使模型能够从多个负样本中学习表示,而LightGCN中的BPR损失仅使用一个负样本,限制了模型的感知范围;(2)如第3.4节所分析的,在适当的
 下,SGL受益于动态困难负样本挖掘,其中困难负样本提供有意义的更大梯度来指导优化[54]。
下,SGL受益于动态困难负样本挖掘,其中困难负样本提供有意义的更大梯度来指导优化[54]。另一种观察结果是,BPR损失的快速下降期比Recall的快速上升期稍晚。这表明BPR损失与排名任务之间存在差距。我们将在今后的工作中对这一现象进行深入研究。
4.3.3 噪声交互的鲁棒性(Robustness to Noisy Interactions)
我们还进行了实验来检验SGL对噪声交互的鲁棒性。为此,我们通过添加一定比例的对抗示例(即5%、10%、15%、20%的负面用户-项目交互)来污染训练集,同时保持测试集不变。图6显示了Yelp2018和Amazon-Book数据集的结果。<br />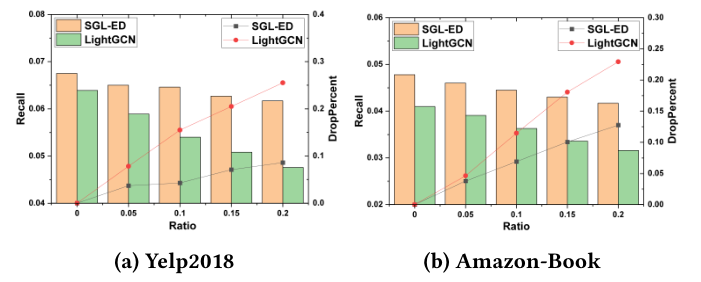<br />**图6 模型性能W.r.t.噪声比**。条形表示召回,折线表示性能下降的百分比。
显然,添加噪声数据会降低SGL和LightGCN的性能。但是,但SGL的性能退化低于LightGCN;而且,随着噪声比的增加,两条退化曲线之间的差距变得更加明显。这表明,通过比较节点的不同增强视图,SGL能够找出有用的模式,特别是节点的信息图结构,并减少对某些边的依赖。简而言之,SGL提供了一个不同的角度来消除推荐中的false positive交互。
- 以Amazon-Book为例,在有20%额外噪声交互的情况下,SGL的性能仍然优于无噪声数据集的LightGCN。这进一步证明了SGL相对于LightGCN的优越性和鲁棒性。
- 我们发现SGL在Yelp2018上更加稳健。可能的原因可能是Amazon-Book比Yelp2018稀疏得多,添加噪声数据对Amazon-Book的图结构的影响比Yelp2018更大。
4.4 SGL研究Study of SGL (RQ3)
我们继续研究SGL中的不同设计。我们首先研究了超参数的影响。然后,我们探讨了采用SGL作为现有基于图的推荐模型的预训练的可能性。最后,我们研究了负面因素对SSL目标函数的影响。由于篇幅所限,我们省略了iFashion上的结果,这些结果与Yelp2018和Amazon-Book上的结果有相似的趋势。
4.4.1 温度
 的影响(Effect of Temperature
的影响(Effect of Temperature  )
)正如第3.4节所证实的那样,在困难负样本挖掘中起着关键作用。图7显示了不同下的模型性能w.r.t.的曲线。<br />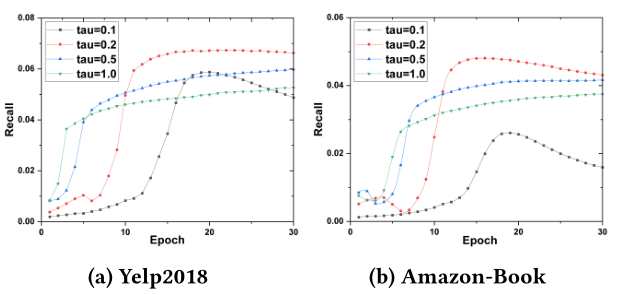<br />**图7 调整****时的模型性能**<br /> 我们可以观察到:(1)增加的值(例如1.0)会导致较差的性能,并且需要更多的训练epoch才能收敛,从而缺乏区分困难负样本和容易负样本的能力。(2)相反,将设置为太小的值(例如,0.1)会损害模型的性能,因为少数负样本的梯度主导了优化,失去了在SSL目标中添加多个负样本的优势。总而言之,我们提出将调整在的范围内。
4.4.2 预训练效果(Effect of Pre-training)
上述实验表明了SGL的有效性,其中主监督任务和自我监督任务被联合优化。在这里,我们想回答一个问题:推荐性能是否受益于预训练好的模型?针对这一目标,我们首先对自监督任务进行预训练以获取模型参数,并用它们来初始化LightGCN,然后通过优化主任务来对模型进行微调。我们将此变体称为SGL-PRE,并在表5中显示了与SGL的比较。显然,尽管SGL-PRE在两个数据集上的表现都不如SGL-ED,但SGL-PRE的结果仍然好于LightGCN(参见表3)。我们的自监督任务能够为LightGCN提供更好的初始化,这与以前研究中的观察结果一致[6]。然而,联合训练的较好表现承认,主任务和辅助任务中的表征是相互促进的。<br />**表5 不同SSL变体的比较**<br />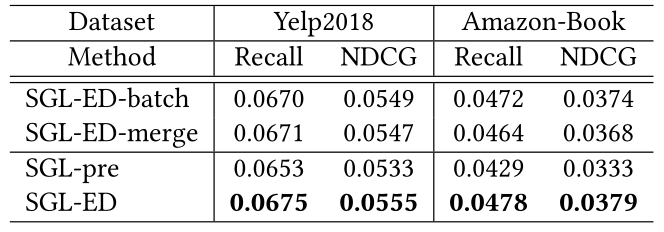
4.4.3 负样本影响(Effect of Negatives)
此外,我们还研究了辅助任务中负样本的选择对实验结果的影响。考虑了两个变体:(1)SGL-ED-Batch,它区分节点类型,并将小批次中的用户和项目分别视为用户和项目的negative视图;(2)SGL-ED-Merge,将小批次中的节点视为negative,而不区分节点类型。我们在表5中报告了这种比较。SGL-ED-Batch的性能优于SGL-ED-merge,这表明有必要区分不同类型的节点。此外,SGL-ED-Batch与SGL-ED不相上下,SGL-ED将用户和项目的整个空间视为negative。它表明,在mini-batching中训练SSL任务是一种有效的替代方案。
5 相关工作(Related Work)
在这一部分中,我们分别回顾了与我们的工作相关的两个任务:基于图的推荐和自监督学习。
5.1 基于图的推荐(Graph-based Recommendation)
基于图的推荐的研究可以分为:模型方法和图方法。模型方法侧重于挖掘用户-项目图的模型设计。研究的重点已经从将图结构编码为转移概率的随机游走[2]发展到在图上传播用户和项目嵌入的GCN[19,38,46,50]。最近,注意力机制被引入到基于GCN的推荐模型[7]中,该模型学习对邻居进行加权,以便捕获更多信息的用户-项目交互。图方法也引起了极大的关注,它通过考虑用户-项目交互之外的辅助信息来丰富用户-项目图,用户-项目交互的范围从用户社会关系[1,32,53]、项目共现[2],到用户和项目属性[27]。最近,知识图谱(KG)也与用户-项目图统一,这使得能够考虑项目之间的链接的详细类型[4,43,45]。<br /> 尽管在这些方法上投入了大量的努力,但所有现有的工作都采用了监督学习的范式来进行模型训练。这项工作是在正交方向上进行的,它探索了自监督学习,开辟了基于图的推荐的一条新的研究路线。
5.2 自监督学习(Self-supervised Learning)
自监督学习的研究大致可以分为两个分支:生成模型[10,29,39]和对比模型[6,11,17,40]。自编码是最流行的生成模型,它学习重构输入数据,其中可以有意添加噪声以增强模型的鲁棒性[10]。对比模型通过噪声对比估计(NCE)目标学习比较,该目标可以是全局-局部对比[22,40]或全局-全局对比[6,17]。前者侧重于对样本的局部部分与其全局上下文表示之间的关系进行建模。而后者直接在不同样本之间执行比较,这通常需要样本的多个视图[6,17,37]。SSL也应用于图数据[51、52、56]。例如,InfoGraph[35]和DGI[42]根据节点和局部结构之间的互信息来学习节点表示。此外,Hu等人[23]将学习GCN的思想扩展到图表示。此外,Kaveh等人[16]采用对比模型学习节点和图表示,将一个视图的节点表示与另一个视图的图表示进行对比。此外,GCC[31]利用实例区分作为图结构信息预训练的辅助任务。这些研究集中在一般图上,而没有考虑二部图的固有性质。<br /> 据我们所知,到目前为止,将SSL与推荐结合起来的工作非常有限。最近的一种是S3-Rec[55]的顺序推荐,它利用互信息最大化原理来学习属性、项目、子序列和序列之间的相关性。另一种尝试[49]也采用带有SSL的多任务框架。然而,它与我们的工作不同之处在于:(1)[49]使用双塔DNN作为编码器,而我们的工作启发了基于图的推荐,并在图结构上设计了三个增强算子。(2)[49]使用类别元数据特征作为模型输入,而我们的工作考虑更一般的协作过滤设置,仅用ID作为特征。
6 结论和未来工作(Conclusion and Future Work)
在这项工作中,我们认识到一般监督学习范式下基于图的推荐的局限性,并探索SSL解决这些局限性的潜力。特别地,我们提出了一个模型不可知的框架SGL,用用户-项目图上的自监督学习来补充监督推荐任务。从图结构的角度出发,我们从不同的方面设计了三种数据增强来构建辅助对比任务。我们在三个基准数据集上进行了大量的实验,证明了我们的提出在长尾推荐、训练收敛和对噪声交互的鲁棒性方面的优势。<br /> 这项工作代表了利用自监督学习进行推荐的初步尝试,并开辟了新的研究可能性。在未来的工作中,我们希望让SSL在推荐任务方面更加稳固。除了图结构上的随机选择,我们计划探索新的视角,如反事实学习以识别有影响的数据点,以创建更强大的数据增强。此外,我们将重点关注推荐中的预训练和微调,即预训练一个模型,该模型可以捕获跨多个域或数据集的通用和可转移的用户模式,并在即将到来的域或数据集上进行微调。另一个有希望的方向是发挥SSL解决长尾问题的潜力。我们希望SGL的发展有助于提高推荐模型的通用性和可移植性。

若有收获,就点个赞吧
0 人点赞
