- 摘要(Abstract)
- 关键字(Keywords)
- 1 引言(Introduction)
- 2 问题表述(Problem Formulation)
- 3 方法(Methodology)
- 4 实验(Experiments)
- 5 相关工作(Related Work)
- 6 结论和下一步工作(Conclusion and Future Work)
HAKG: Hierarchy-Aware Knowledge Gated Network for Recommendation
- Yuntao Du, Xinjun Zhu, Lu Chen, et al. HAKG: Hierarchy-Aware Knowledge Gated Network for Recommendation[C]. In SIGIR 2022.
浙江大学 截稿日期2022-01-28 录用通知2022-04-15 会议日期2022-07-11
摘要(Abstract)
知识图谱(KG)在提高推荐性能和可解释性方面发挥着越来越重要的作用。最新的技术趋势是基于信息传播方案设计端到端模型。然而,现有的基于传播的方法不能(1)对底层的层次结构和关系进行建模,(2)捕获项目的高阶协同信号以学习高质量的用户和项目表示。<br /> 在本文中,我们提出了一个新的模型,称为层次感知知识门控网络(HAKG),以解决上述问题。从技术上讲,我们在双曲空间中对用户和项目(由用户-项目图捕获)以及实体和关系(在KG中捕获)进行建模,并设计一个双曲聚合方案来收集KG上的关系上下文。同时,我们引入了一种新的角度约束来保持嵌入空间中项目的特征。此外,我们还提出了一种双项目嵌入设计,将协同信号和知识关联分开表示和传播,并利用门控聚合来提取区分信息,以更好地捕获用户行为模式。在三个基准数据集上的实验结果表明,HAKG比CKAN、HyperKnow和KGIN等最先进的方法取得了显著的改进。对学习到的双曲线嵌入的进一步分析证实,HAKG提供了对数据层次结构的有意义的见解。
关键字(Keywords)
1 引言(Introduction)
在信息爆炸的时代,推荐系统已经成为提供个性化信息服务的互联网应用的重要组成部分。传统的基于协同过滤的推荐系统[14,20,26,46]通常存在数据稀疏和冷启动问题。最近,知识图谱(KG)通过关系提供了与项目相关的各种真实世界的事实,在缓解冷启动问题和提高推荐的可解释性方面表现出了令人印象深刻的能力。<br /> 从辅助KG中学习用户和项目表示已经成为知识感知推荐的术语。早期的研究[1,42,53]直接将知识图谱嵌入与项目相结合来增强其表示。后来的一些研究[5,19,23,48]通过从用户到项目的元路径来丰富交互,以更好地识别用户-项目的连接性。然而,为了获得信息路径,这些方法存在着劳动强度大[48]、泛化能力差[19,56]、性能不稳定[51]等问题。最近,图神经网络(GNN)[16,25,38]的成功激发了社区开发基于信息聚合方案[8,10,37,41,43,45,47,49]的端到端模型。其核心思想是在KG上迭代传播高阶信息,可以有效地将多跳邻居集成到表示中,从而提高推荐性能。<br /> 虽然现有的基于传播的方法能够获得良好的性能,但我们想要强调的是,它们都没有对以下两个重要因素进行建模。
层级结构和关系Hierarchical Structures and Relations。现有的方法都在欧氏空间中对用户-项目交互和知识生成进行建模,而这两种数据结构都表现出高度的非欧几里德潜在解剖学。具体地说,用户-项交互通常遵循指数分布(如图1(B)所示),表示底层的层次结构[8、39、54]。同时,由于人类知识是按层次组织的[2,6],因此层次化信息在现实世界的KG中是无处不在的。基于欧几里得的方法不足以捕获数据的内在层次结构,因为它们在嵌入层次数据时遭受高度失真[7,12,34]。此外,它们都没有在更细粒度的层次结构中考虑KG关系。它们都很方便地忽略了一个重要的事实,即等级关系(图1(A)中的蓝线)和非等级关系(图1(A)中的黑线)对于表征项目不具有同等的重要性。以图1(A)中的服装推荐为例。层次关系푟1在以下方面向Cloth푖1提供补充信息:푖1是牛仔裤푒1,而非层次关系푟5意味着Cloth푖2和Cloth푖3可以组成服装。因此,层次关系可以表示项目的属性,而非层次关系只能揭示实体之间的关联性。忽略层次结构和关系限制了模型的表达能力。
- 物品的高阶协同信号High-order Collaborative Signals of Items。在现有的研究中,项聚合方案大多是面向KG的,即递归地从KG中收集项的知识关联,而不考虑来自用户的协同信号[47,49],或者盲目地将来自相邻节点(用户或实体)的异质信息混合在统一知识图中[37,45]。它们没有显式地编码项目的关键高阶协同信号,这些信号潜伏在用户项目交互中,并在从行为方面学习用户偏好方面发挥着重要作用。以图1(A)为例。路径푖1→푢1→푖3→푢2→푖2表示项目푖1和项目푖2之间的远程连通性:由于用户푢1和푢2共享相同的兴趣(即,他们都喜欢项目푖3),所以分别被用户푖1和用户푖2偏爱的项目푢1和푢2可能在某种程度上相似。因此,这种面向KG的聚合方案不足以显式地捕获用于综合项目表示的高阶协同信号。
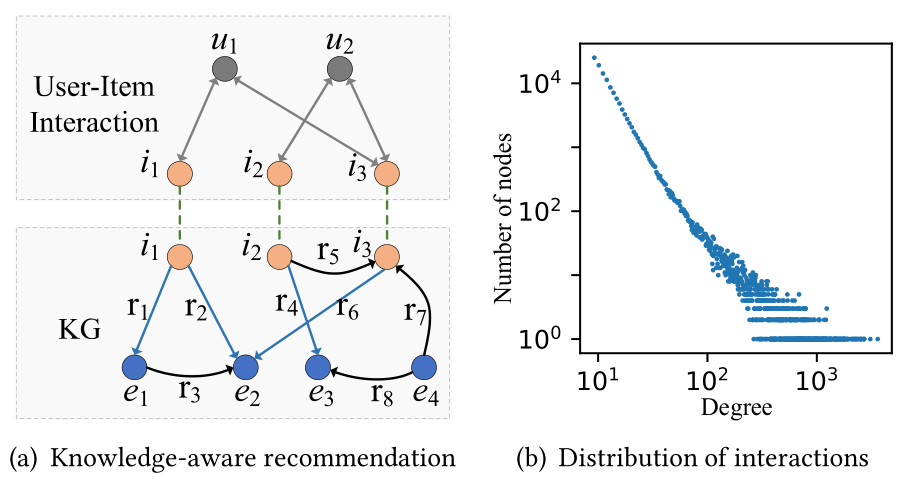
图1 知识感知推荐的一个例子。蓝线表示等级关系,黑线表示非等级关系。(B)阿里巴巴-iFashion数据集的学位分布。
为了应对上述挑战,需要一种嵌入失真较小的新的潜在空间。双曲几何提供了一种理想的替代方案,因为它不仅能够以更小的失真嵌入[7,12],而且自然地保留了数据层次[6,54]。双曲空间的主要性质是,与欧几里德空间不同,它按指数而不是多项式展开。这允许双曲空间具有比欧几里得空间大得多的数据容量,因此,它有“足够的”空间来更好地保持层次数据之间的距离,如图2左侧所示。此外,双曲空间可以被视为树的连续版本,这使得它由于其相似的结构而完美地建模层次树状数据。因此,我们提出了层次感知知识门控网络(HAKG),这是一种新的具有两个关键组成部分的双曲知识感知模型,它能够有效地捕获和建模上述两个重要因素,而现有的任何方法都没有对这两个重要因素进行建模。
- 支持层次结构的建模。为了更好地捕获底层的层次结构,我们将用户和项嵌入以及实体和关系嵌入映射到双曲空间。我们还设计了一种新的双曲关系传递聚合机制来捕获双曲空间中邻居携带的关系依赖关系。此外,针对层次关系引入了一种新的角度约束,能够更好地保留嵌入空间中项目的属性信息,从而提高了项目的表示能力和表达能力。
- 具有双重嵌入的门控聚合。与以往面向KG的聚合策略不同,我们将用户-项目交互和KG视为两个不同的信息渠道,并针对这两个渠道制定了不同的聚合策略。此外,由于项可以作为连接两个信息通道的天然桥梁,因此我们使用双重嵌入而不是单一嵌入来分别表示和传播每个通道的信息,从而更好地捕获到项的整体语义。此外,为了更好地识别用户行为模式,引入了一种信息门控机制来自适应地融合两种类型的语义。
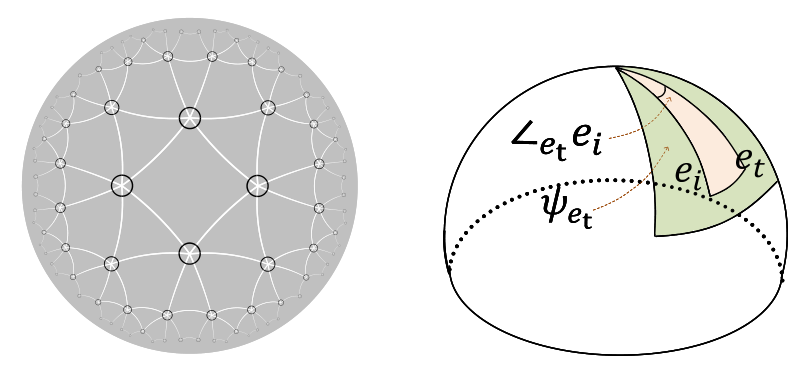
图2 (A)双曲空间呈指数扩张。(B)双曲圆锥的图解。
为此,新提出的HAKG框架旨在i)利用双曲几何的表现力进行更好的层次建模,以及ii)有效地捕获项目的整体语义。我们在三个真实数据集上进行了大量的实验,以评估HAKG和现有方法的性能。实验结果表明,我们的HAKG算法的性能明显优于CKAN[49]、Hyper-Know[31]和KGIN[47]等最新方法。此外,HAKG能够揭示数据在嵌入空间中的底层层次结构和关系,从而获得更好的模型表达能力。<br /> 综上所述,我们的贡献如下:
- 我们从一个新的角度提出了知识感知推荐,考虑了层次结构和高阶项的协同信号。
- 在双曲空间中嵌入用户和项,以及实体和关系,并在KG中设计了一种新的双曲聚合来保持邻居之间的关系依赖。此外,对于属性在嵌入空间中的配置文件项的层次关系,引入了角度约束。
- 我们设计了双项目嵌入设计,以更好地同时表示和传播协同信号和知识关联,以及更有效地利用信息门机制从行为和属性两个方面控制对用户偏好的区分信号。
我们在三个公共基准数据集上进行了大量的实验,以验证HAKG的优越性。
2 问题表述(Problem Formulation)
我们首先介绍了与我们研究的问题相关的数据结构,然后阐述了我们的任务。<br />** 用户-项目二部图User-Item Bipartite Graph**。在本文中,我们专注于从隐式反馈中学习用户偏好[35]。更具体地说,行为数据(例如,点击和评论)涉及一组用户U={푢}和一组项I={푖}。我们将用户-项交互建模为二部图G푏={(푢,푖)|푢∈U,푖∈I,其中每个(푢,푖)对表示用户푢已经与项푖交互。<br />** 知识图谱Knowledge Graph(KG)**。KG是真实世界事实的集合,例如项目属性、概念或外部常识。设T是三元组集合,E是实体集合,R是关系集合,它既涉及规范方向的关系,也涉及反向关系(例如,Compose和Composed-Of)。设KG是一个异构图G푘={(ℎ,푟,푡)|ℎ,푡∈E,푟∈R},其中每个三元组(ℎ,푟,푡)∈T表示在头实体푟和尾实体ℎ之间存在关系푡。例如,一个三元组(牛仔裤、品牌、Levi‘s)表明牛仔裤的品牌是Levi’s。由于我们假设所有项目在KG中都以实体(即I⊂E)的形式出现,这是所有现有的知识感知推荐系统[44,45,47]所做的共同假设,我们可以将用户-项目图中的项目与KG中的实体链接起来,为交互提供辅助语义。<br />** 任务描述Task Description**。给定用户-项目图G푏和KG G푘,我们的知识感知推荐的任务是预测用户采用她从未接触过的项目的可能性有多大。
3 方法(Methodology)
在这一部分中,我们首先介绍了双曲空间的基本概念,然后详细介绍了HAKG的两个关键组件,即层次感知建模和双重嵌入的门控聚合。前者将用户与物品、实体与关系嵌入到双曲空间中。它在KG上采用了一种新的双曲关系感知聚合,并引入了角度约束来学习嵌入空间中项目的属性语义。后者利用双项目嵌入分别对用户-项目图中的高阶协同信号和KG中的知识关联进行编码,并通过GATE机制提取有用的语义以学习高质量的用户表示。<br />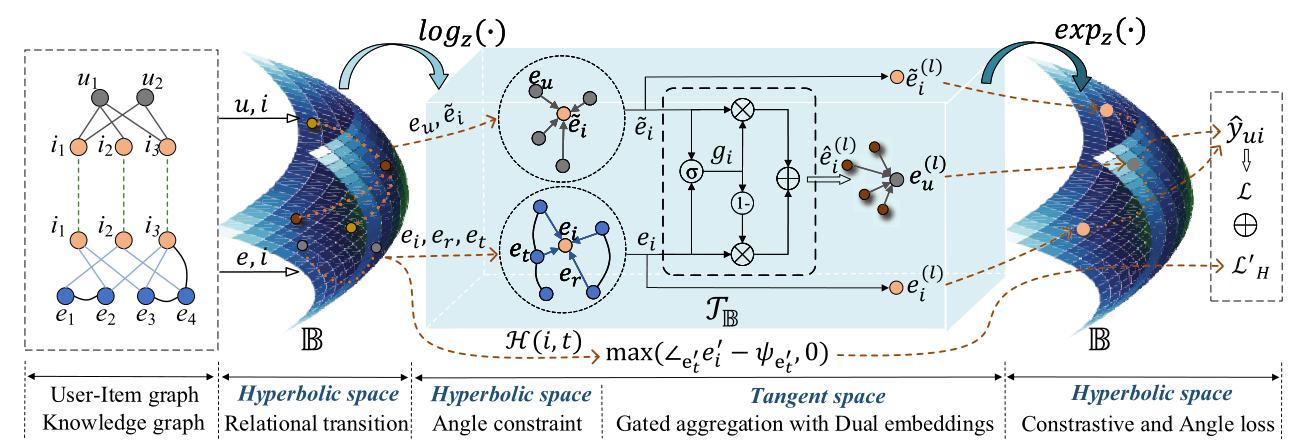<br />**图3 提出的HAKG框架图解**
3.1 预备知识(Preliminaries)
双曲几何[3]是具有常负曲率的非欧几里得几何。与欧几里德空间相比,双曲几何所覆盖的空间量是指数增长的,而不是多项式的。半径。该属性允许我们在双曲空间中有效地捕获用户-项目交互和KG的底层层次结构。在这项工作中,我们使用常曲率−푐=−1的Poincaréball模型来学习双曲嵌入,因为它对于梯度优化是可行的[34,54]。在下文中,我们首先介绍Poincaréball模型所必需的数学基础。<br />**PoincaréBall&切线空间Poincaré Ball & Tangent Space**。Poincaréball模型的定义域是:<br /> (1)<br />在R푛。在B上的点푧处的切线空间TzB是푛维欧氏空间,它在푧附近最佳地逼近B,这对于在双曲空间中进行聚合运算是有用的[7]。<br />**指数映射和对数映射Exponential Map & Logarithmic Map**。双曲空间和切线空间可以通过指数和对数映射来连接。具体地说,指数映射可以将切线空间TzB映射到双曲空间B,而对数映射可以将B映射到TzB。具体地说,在点푧处的两个地图的闭合形式表达式定义如下。<br /> (2)<br /> (3)<br />其中⊕表示莫比乌斯加法[12]:<br /> (4)
3.2 层次化建模(Hierarchy-Aware Modeling)
与以前基于传播的研究[37,43,45,47]简单地将用户-项目图和KG嵌入欧氏空间不同,我们的目标是捕获数据的非欧几里德潜在解剖。以图1(B)所示的阿里巴巴-iFishion数据集为例,用户-项目交互的程度分布揭示了具有幂规律分布的底层层次树状结构。同时,KG也呈现出层次化模式[2,6]。然而,由于数据的高失真[12,34],数据的层次属性不能在欧几里德空间中被正确地捕获。因此,我们将用户和项以及实体和关系嵌入到双曲空间中,在双曲空间中可以自然地保留层次结构。由于以前的基于欧几里德的方法在双曲空间中不可行,我们还在KG中设计了一种新的聚合方案。<br /> 同时,我们认为,以前的方法不能正确地刻画项目,因为它们没有区层次次关系和其他关系,并且只能在粗粒度上建模KG关系。具体来说,KG中的层次关系往往携带实体的属性信息(例如品牌和面料),而非层次关系只能表示实体之间的关联性(例如匹配和相似)。这促使我们在嵌入空间中引入对层次三元组的附加约束,以提高表示能力和表达能力。
3.2.1 双曲关系-传递聚合(Hyperbolic Relation-Transitive Aggregation)
我们首先考虑了KG在双曲空间中的聚合格式。由于一个项目푖可以涉及多个KG三元组,其邻域在一定程度上反映了푖与其关联实体之间的关系相似度。在形式上,给定KG中的目标项푖,聚合来自KG中푖的邻居的本地信息可以揭示푖的相关知识关联。因此,我们使用N푖={(푟,푡)|(푖,푟,푡)∈G푘}来表示KG中的项푖的邻域实体和一阶关系,并提出集成来自邻域实体的关系上下文来生成项푖的知识表示:<br /> (5)<br />其中e(1)푖∈B푑是从一阶连通性中收集项푖的上下文信息的双曲知识表示,而푓B(·)是从双曲空间中的每个连接(푖)中提取和集成与项푖,푟,푒相关的信息的双曲聚合函数。以前的研究[47]表明,基于节点的聚合不能区分关系路径,这无法保留路径所携带的关系依赖关系。因此,有必要将关系路径集成到表示中。此外,基于欧几里德传播的方法主要使用均值聚合来平均邻居信息。双曲空间中平均聚合的一个模拟是Fréchet平均[11],然而,它没有闭合形式的解。相反,我们将Mean聚合器中的关系上下文建模为:<br /> (6)<br />其中⊕是Möbius加法运算,LOG(·)和EXP(·)分别是前面提到的指数映射和对数映射,e(0)푡是实体푡在双曲空间中的ID嵌入。对于KG中的每个三元组(푖,푟,푡),通过将关系푡⊕建模为e(0)푟的向量平移,我们设计了一个关系转移e(0)푟e푡。为了避免双曲空间中的复杂平均运算,我们首先将每个关系上下文映射到切线空间,因为这是欧几里得近似执行得最好的地方(参见。图3);然后,我们利用指数映射将其映射回双曲空间,以获得表示e(1)푖。因此,聚合器能够将关系消息集成到双曲空间中的目标表示中,并通过映射操作避免复杂的双曲均值汇集。类似地,我们可以得到每个KG实体푒E的表示e(1)푒∈。<br /> 我们进一步堆叠了更多的聚合层,以探索项目的高阶知识关联。从技术上讲,我们递归地将项目푖在푙层之后的知识表示形式表示为:<br /> (7)
3.2.2 层次三元组的角度约束(Angle Constraint of Hierarchical triplets)
接下来,重点对具有层次关系的项目的属性信息进行建模。为了方便我们的讨论,我们假设KG中的所有关系都被聚为两种类型(即层级和非层级),并且关系的类型是先验的。事实上,关系的类型在大多数KG[2,6]中都是明确可用的。当这些信息不可用时,有两个替代选择。一种是通过广泛使用的Krackhardt评分标准来推断关系的“层次性”[27];另一种是简单地假设项连接的实体作为项的属性,因此,这些关系是层次化的。我们将在第4.3.2节中报告的实验表明,两个选项之间的差异可以忽略不计。<br /> 如前所述,层次关系可以揭示项目的属性。然而,上述聚合方案不能在嵌入空间中保持这种语义,因为它只是将所有相邻信息聚合到表示中。为了显式地建模项目的特征信息,我们考虑了双曲蕴涵锥[13],它是一族凸锥,可以用嵌套的角锥来建模层次结构。从技术上讲,我们用Cx来表示顶端x处的锥体,并将锥体宽度函数(即锥体Cx的半孔1)定义为휓x=arcsin(퐾1−kxk2 kxk),其中퐾∈R是超参数(我们遵循[2]并设置퐾=0.1)。此外,对于x,y∈B푑,我们将y在x处的角度定义为半直线−→ox和−→xy之间的角度,并将其表示为∠xy:<br /> (8)<br />角锥的传递性保证了如果y在Cx中,Cy也在Cx中。换言之,双曲蕴涵锥在嵌入空间中形成嵌套结构,且宽度(又名。如图2右侧所示,为了利用双曲蕴涵锥体几何的表达能力,我们首先使用H={(푖,푡)|(푖,푟,푡)∈G푘∧푟is Hierarchical})来表示KG中的层次关系푟的层次实体集合,并使用公式Eq。(9)定义嵌入空间中的角度约束:<br /> (9)<br />其中e푡和e푖分别是EQ中定义的实体푖和实体푡的最终知识表示。(15)。角度约束下的铰链损失表明∠e푡e푖的角度小于蕴涵锥体Ct的宽度,这意味着项e푖的嵌入应包含在实体e푡在蕴涵锥几何图形中的嵌入内。<br /> 这种约束在保证属性具有几何角度的语义的同时,也限制了属性的表示能力。例如,假设Item푖是具有多个层次关系(例如,品牌和面料)的牛仔裤。由于푖的每个连通实体在双曲空间中定义了一个蕴涵锥,所以푖的嵌入只能在它们的交点区域内。由于KG中的项目通常具有数十个关系,因此这个交集区域可能非常小,从而可能导致嵌入空间的崩溃。因此,我们通过随机分配满足以下约束的项푖的嵌入的相应子空间来放松它:<br /> (10)<br />其中,e‘푖和e’푡分别是e푖和e푡通过随机掩蔽某些维度而嵌入的子空间。在我们目前的实现中,每个维度被屏蔽的概率为0.5,而这个概率可以很容易地进行调整,以满足应用程序的需要。通过这样做,我们只在푑双曲平面的一个子集上强制执行角度约束,为表达项的关联性和其他知识语义留下了空间。
3.3 双重嵌入的门控聚合(Gated Aggregation with Dual embeddings)
HAKG框架的第二个关键组件主要用于捕获物品的高阶协同信号。现有的方法利用面向KG的聚合策略从相邻节点收集与项目相关的信息。不幸的是,这种方法要么将协同信号与知识关联混合,使得它们变得无法区分[8,45],要么完全忽略了导致次优项目表示的项目[47,49]的协同信号。因此,我们建议使用对偶项嵌入来分别聚合这两种类型的信息,以解决其局限性:(1)知识项嵌入,它用于描述具有KG中的知识信息的项,如3.2节所示。(2)协同项目嵌入,将项目在用户-项目图中的共现关系等高阶协同信号进行编码。基于项目的整体表示,我们进一步提出了一种信息门机制,以自适应地提取有用信息,供用户聚合。我们在图3中说明了我们的方法。
3.3.1 项目的协同聚合(Collaborative Aggregation for Items)
为了显式地编码项目的协同信号,我们将双曲空间中新的项目表示˜e(0)初始化为项目的协同信息,这些信息隐藏在用户与项目的交互中。我们还使用邻域聚合方案将项目的多跳邻居整合到其表示中,以捕获高阶连通性。给定用户-项目图中的一个项目푖,我们使用˜N푖={푢|(푢,푖)∈G푏}来表示与该项目交互的所有用户。为了生成푙-th层的Item푖表示,我们递归地集成来自Item푖的邻居用户的协同信息:<br /> (11)<br />其中˜e(푙)푖是项푖在푙层之后的协同嵌入,LOG(·)和EXP(·)是用于在欧几里德空间和双曲空间之间映射的指数映射和对数映射,e(푙−1)푢是用户푢在푙−1层之后在双曲空间中的双曲嵌入,我们将在下面详细描述。
3.3.2 用户的信息门控聚合(Information Gated Aggregation for Users)
为了从相邻项中提取有用的信息,我们设计了一个门控模块,该模块能够产生区分信号用于用户聚合。具体地说,受GRU[9]学习选通信号来控制隐藏状态更新的设计的启发,我们提出了学习融合门来自适应地控制两种不同类型的语义项表示的组合。对于项目푖,给定其知识表示e(푙)푖和协同表示˜e(푙)푖)在푙层中,我们利用可学习的门控融合单元来平衡两种不同类型的信息的贡献:<br /> (12)<br /> (13)<br /> 其中푊1,푊2∈R푑×푑是可学习的变换参数,휎(·)是Sigmoid函数。符号g(푙)푖∈R푑表示学习的门信号,以平衡协同信号和物品푖的知识关联的贡献,如图3所示。高值g(푙)푖表示用户与物品푖交互主要是因为物品푖的属性(例如,푖是牛仔裤),而不是物品之间的行为相似性(例如,用户푖喜欢的牛仔裤푢与用户푢喜欢的其他底裤协同相关)。让N푢={푖|(푢,푖)∈G푏}表示用户푢与之交互的项目集。然后,我们可以用提取的信息来表示用户푢:<br /> (14)
3.4 模型预测(Model Prediction)
在퐿Layers之后,我们得到Item푖和User푢在不同层的表示,然后将它们相加为最终的表示:<br /> (15)<br />通过这样做,协同和知识的互补信息在最终表示中被单独编码。与以往的工作不同的是,我们使用余弦相似度从物品的行为和属性两个方面分别预测用户푢푖采用物品푖的可能性,然后将两个预测的总和作为最终预测分数ˆ푦푢푖:<br /> (16)
3.5 模型优化(Model Optimization)
我们选择对比损失[33]来优化HAKG。与广泛使用的业务流程再造损失[35]相比,它通过引入更多的负样本和惩罚没有提供信息的样本来缓解收敛问题。具体地,对于用户-项目图捕获的每个交互(푢,푖)(即正对),我们随机抽样|M푢|未观察到的项目,以与用户푢一起形成负对,记为M푢,并最大化正对之间的相似度,同时最小化具有边距푚的负对的相似度:<br /> (17)<br />其中D是交互数据,(·)+是斜坡函数max(0,·)。通过结合预测损失和角度损失,我们最小化以下目标函数来学习模型参数:<br /> (18)<br />其中,휆是控制公式中定义的角度损失的权重的超参数。(9)。
3.6 模型分析(Model Analysis)
3.6.1 模型大小(Model Size)
以前的研究[47]已经证实,丢弃非线性特征变换不仅可以获得更好的性能,而且还可以减少冗余参数。因此,在HAKG的聚合方案中,我们去掉了非线性激活函数和可学习变换度量。HAKG的模型参数包括(1)用户、项目、KG实体和关系的ID嵌入{e(0)푢,˜e(0)푖,e(0)푒,e푟|푢∈U,푖∈I,푒∈E,푟∈R};(2)Eq中使用的信息门控聚合的转换参数푊1,푊2。(12)。
3.6.2 时间复杂度(Time Complexity)
HAKG的时间开销主要来自聚合方案。在KG上的聚合中,更新双曲空间中知识项嵌入的计算复杂度为푂(|G푘|푑퐿),其中|G푘|,푑,퐿表示KG三元组的个数、嵌入大小和层数。在用户-项目图聚合中,协同项目嵌入和用户嵌入的计算复杂度为푂(|G푏|푑퐿),其中|G푏|为交互次数。对于层次感知建模,角度约束的成本为푂(|i|),其中|i|是项数。此外,欧氏空间到双曲空间的映射代价为푂(|G푏|+|G푘|)。因此,整个训练周期的时间复杂度为푂(|G푘|푑퐿+|G푏|푑퐿)。在相同的实验设置下(即相同的嵌入大小和传播层),HAKG的复杂度与KGAT、CKAN和KGIN这三种典型的基于传播的方法相当。
4 实验(Experiments)
我们给出了实验结果来证明我们所提出的HAKG框架的有效性。这些实验旨在回答以下三个研究问题:
RQ1:与最先进的知识感知推荐模式相比,HAKG的表现如何?
RQ2:HAKG的不同组成部分(即层次建模、门控传播、双重嵌入和传播层深度)如何影响HAKG的性能?
RQ3:HAKG能否从结构和关系两个方面对层次化建模提供有意义的见解?4.1 实验设置(Experimental Settings)
4.1.1 数据集描述(Dataset Description)
我们利用三个基准数据集来评估HAKG的表现:阿里巴巴-iFashion、Yelp2018和Last-FM。这三个数据集在最先进的方法[8,31,45,47]中被广泛采用,并且在域、大小和稀疏性方面有所不同。在前人工作[45]的基础上,我们收集KG中项目的两跳邻域实体,为每个数据集构建项目知识图。此外,对于KG中的层次关系类型,在不损失一般性的情况下,我们简单地将项连接关系视为层次关系,因为它们能够揭示项的属性。此外,为了保证数据质量,我们采用了10核设置[45],即保留至少有十个交互的用户和项目,并过滤出参与少于十个三元组的KG实体。我们使用与先前研究相同的数据分区[45,47]进行比较(即,对于所有数据集,训练、验证和测试集的比例分别为80%、10%和10%)。表1总结了我们实验中使用的三个数据集的总体统计数据。<br />**表1 我们实验中使用的数据集的统计数据。**<br />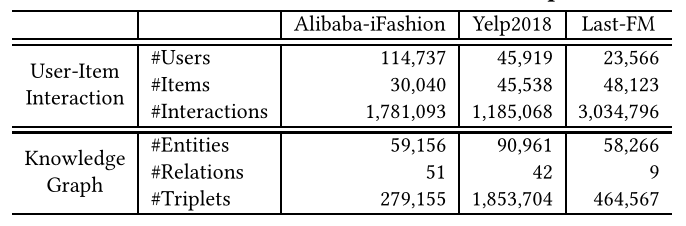
4.1.2 评估指标(Evaluation Metrics)
我们采用全排名策略[28,47]来评价业绩。具体地说,我们将所有用户以前没有采用的项目视为否定的,并将测试集中的相关项目视为肯定的。为了评估TOP-퐾推荐的有效性,我们采用了两个广泛使用的评估协议[18,28]Recall@퐾和Ndcg@퐾,其中默认퐾=20。我们报告测试集中所有用户的平均指标。
4.1.3 基线(Baselines)
为了验证HAKG的有效性,我们将其与最新的方法进行了比较,包括KGFree方法(MF)、基于嵌入的方法(CKE和UGRec)、基于传播的方法(KGNN-LS、KGAT、CKAN和KGIN)以及基于双曲线的方法(Hyper-Know和LKGR):
MF[35]是一个基准分解模型,它只考虑用户与项目的交互,而不考虑KG。这里,我们使用用户和项目的ID嵌入来执行预测。
- CKE[53]是一种具有代表性的嵌入方法,它利用TransR[29]从KG中学习项的结构表示,并将学习到的嵌入反馈给集成框架中的MF。
- UGRec[55]是一种最先进的嵌入方法,它从KG和共现行为数据中建模有向关系和无向关系。虽然这种无向关系对于其他方法是不可访问的,对于三个数据集也是不可用的,但我们添加了由同一用户共同交互的项之间的连通性,并将它们视为共现关系。
- KGNN-LS[43]是一个基于传播的模型,它将KG转换为用户特定的图,然后在信息聚合阶段考虑用户对KG关系的偏好和标签的光滑性,从而生成个性化的项目表示。
- KGAT[45]是一个基于传播的推荐模型。它在UKG中应用了一种统一的关系感知注意聚合机制来生成用户和项的表示。
- CKAN[49]是基于KGNN-LS的,它分别在用户-项目图和KG上使用不同的聚合方案来编码知识关联和协同信号。
- KGIN[47]是一种最新的基于传播的方法,它用潜在意图对用户交互行为进行建模,并提出了一种基于关系感知的信息聚合方案来捕获KG中的远程连接。
- Hyper-Know[31]是一种最先进的双曲方法,它将KG嵌入到双曲空间中。提出了一种自适应正则化机制,对项及其邻域表示进行自适应正则化。
LKGR[8]是一种基于Lorentz模型的最新的双曲GNN方法,它在双曲空间中采用不同的信息传播策略来编码来自历史交互和KG的异质信息。
4.1.4 参数设置(Parameter Settings)
我们在Pytorch中实现了HAKG,并发布了我们的实现2(代码、参数设置和训练日志),以便于重现性。为了进行公平的比较,我们将ID嵌入的大小固定为64,并使用ADAM[24]优化器优化所有模型,其中批处理大小固定为4096。Xavier初始化器[15]用于初始化模型参数。我们对超参数应用网格搜索:学习速率在{10−4,10−3,10−2}之间调节,角度损失휆的权重在{10−5,10−4,··,10−2,10−1}中搜索,并在{1,2,3}中调节퐿层以获得基于传播的方法。对于每个用户的负样本数量|M푢|和对比损失的边际푚,我们分别为阿里巴巴时尚、Yelp2018和Last-FM数据集设置为{200,400,400}和{0.6,0.8,0.7}。此外,由于双曲空间中的优化实际上具有挑战性,我们改为在原点定义切线空间中的所有参数,使用标准欧几里德技术来优化嵌入,并使用指数映射来恢复双曲参数[6]。所有基线方法的参数都经过仔细调整,以实现最佳性能。具体来说,对于KGAT,我们将深度设置为3,隐藏大小为{64,32,16},并使用MF的预先训练的ID嵌入作为初始化;对于UGRec,我们将铰链损失的边际值设置为1.5;对于CKAN,KGNN-LS和LKGR,我们将邻域大小设置为16;对于KGIN,我们将意向数量设置为4;对于Hyper-Know,我们将曲率设置为-1。此外,对于所有方法都执行提前停止策略,即,如果测试集上的recall@20连续10个历元没有增加,则提前停止。
4.2 性能比较(Performance Comparison)(RQ1)
表2 整体性能比较
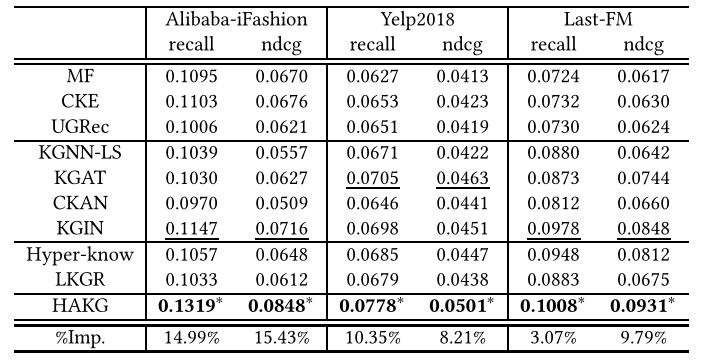
我们从w.r.t.性能比较开始。Recall@20和ndcg@20。实验结果如表2所示,其中%Imp。表示最佳执行方法(星号)相对于最强基线(带下划线)的相对改进。我们有以下观察所得:HAKG在所有数据集上的性能都是最好的。特别是,即使在最强的基线上,它也取得了显著的改进。在阿里-iFashion、Yelp2018和Last-FM中,ndcg@20分别下降了15.43%、8.21%和9.79%。我们将这些改进归功于HAKG的层次建模和整体信息传播:(1)通过在双曲空间中嵌入用户项交互和KG,并为层次关系引入辅助角度约束,HAKG能够捕获数据的底层层次结构,并更好地刻画嵌入空间中的项。相比之下,所有基线都忽略了层次关系的重要性,只是简单地使用面向KG的聚合方案来捕获KG信息。(2)HAKG使用双项嵌入的门控聚合机制,能够显式地保持项的整体语义,从而更好地编码用户行为模式,而其他基于传播的基线(如CKAN、KGIN和LKGR)则无法捕获项的高阶协同信号。
- 联合分析HAKG在三个数据集上的性能,我们发现在阿里巴巴-iFashion数据集上的改进比在其他数据集上更显著。一个可能的原因是,阿里巴巴-iFashion上的KG规模比Yelp2018和Last-FM上的KG小得多,而且大多数关系是层次化的,因此更重要的是i)保存有价值的商品属性信息,ii)捕获商品的关键协同信号以学习用户偏好。这证实了HAKG可以更好地利用用户与项目的交互和KG来进行全面的项目表示。
- KG的辅助信息对于推荐非常重要。与普通MF相比,CKE通过简单地将KG嵌入到MF中而优于MF。结果与之前的研究一致[47]。
- 基于传播的方法在大多数数据集上的表现优于嵌入方法,这表明了对远程连通性进行建模的重要性。我们将他们的成功归功于信息聚合计划。具体地说,递归地收集相邻节点的信息能够捕获高阶潜在语义,以获得高质量的表示。
与欧几里德方法相比,基于双曲的方法(即Hyper-Know和LKGR)获得了与欧氏方法相当的性能。然而,它们的表现仍然略逊于最先进的传播方法(即KGIN)。这是因为他们没有充分利用双曲空间的表现力来进行全面的表示。具体地说,Hyper-Know将KG嵌入到双曲空间中,直接用三元组优化实体的嵌入,而不考虑高阶知识关联。LKGR为双曲实体的聚合设计了一种欧几里得注意机制,不能保持双曲空间中嵌入的局部相似性。
4.3 HAKG的研究(Study of HAKG)(RQ2)
由于层次建模是HAKG的核心,我们还进行了消融研究以考察其有效性。具体地说,角损耗和门控聚合的存在、双曲嵌入和层次关系、对偶项嵌入以及传播层的数目如何影响我们的模型。
4.3.1 角度损失和门控聚合的影响(Impact of Angle Loss & Gated Aggregation)(RQ3)
表3 角度损失和门控聚合的影响
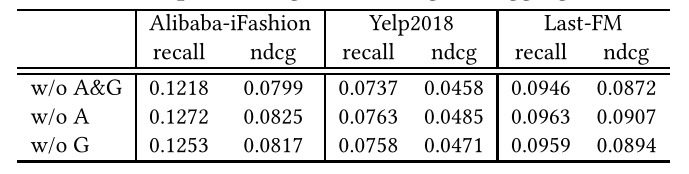
我们首先验证了角度损耗和门控聚合的有效性。为此,通过(1)丢弃角度约束和门控聚合方案(称为HAKGw/o A&G)、(2)去除层次三元组的角度损失(称为HAKGw/o A)和(3)用简单的逐点加法代替门控聚合(称为HAKGw/o G)来构造HAKG的三种变体。我们总结了表3的结果。
与表2中HAKG的完整模型相比,角度约束和门控聚合的缺失显著降低了性能,表明了对层次关系和协同信号进行建模的必要性。具体地说,HAKGw/o A&G直接融合了用于用户聚合的双重项嵌入,而忽略了KG中的层次关系,从而无法正确地描述项并传播全面的信息以供学习使用。类似地,不探索层级关系(即HAKGw/o A)也会降低性能。虽然HAKGw/o G保留了用于表征项目的层次关系的建模,但它不能提供用于识别用户行为模式的区分信号,从而导致次优的用户表示。4.3.2 层次建模的影响(Impact of Hierarchical Modeling)
然后,我们通过考虑层次结构和关系来评估层次建模的影响。具体地说,我们提出了三个替代模型,它们分别是:i)用欧氏替代替换所有的双曲运算,并保留HAKG的计算逻辑(称为欧几里得);ii)利用广泛使用的Krackhardt评分准则[2,27]预测关系的层次类型,以弥补关系类型的不可用(称为PH-关系);以及iii)利用给定的层次关系类型来刻画项(称为GH-关系)。<br />**表4 层次建模的影响**<br />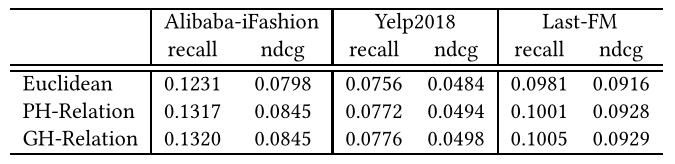<br />表4列出了三种替代模型的结果。我们观察到:
当我们去除HAKG的双曲几何时,所有三个数据集的性能都会下降,这意味着在双曲空间中对用户-项目交互和KG进行建模可以增强模型的表达能力,并产生更好的推荐表示。
当KG关系的层次类型不可用时,替代方法(即PHRelation)的性能与具有地面真实层次关系(即GH关系)的模型的性能接近,这经验表明,即使在KG的层次信息不可用的情况下,我们的模型对于不同的数据集也是健壮的。
4.3.3 双重项目嵌入的影响(Impact of Dual Item Embeddings)
表5 双重项目嵌入的影响
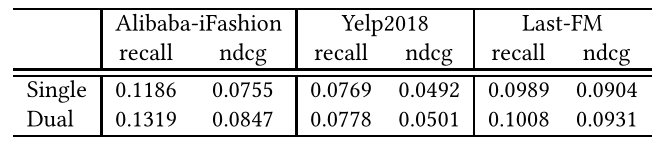
为了分析双项嵌入设计的有效性,我们将其与传统的单项嵌入进行了比较,后者去掉了额外的协同项嵌入,直接利用了方程中项的知识嵌入。(7)用户聚合。我们比较了它们在三个数据集上的性能,并在表5中给出了结果。我们有以下发现:丢弃协同项嵌入将持续降低三个数据集的性能。这是因为如果我们用单一的表示对项目进行建模,它们在执行邻居聚合时不可避免地会遭受信息损失。换言之,由于项目本质上表现出两种语义(协同和知识),因此不太可能同时包含单个嵌入的项目的所有高阶信息。
与在其他两个数据集上相比,Aliabab-iFashion数据集上的单项嵌入性能下降得更明显。一个可能的原因是KG提供的辅助信息量最小,这使得通过额外的协同项目嵌入来捕获项目的协同信号变得更加重要。
4.3.4 模型深度的影响(Impact of Model Depth)
表6 层的数量퐿的影响。
我们还将探讨汇聚层数量的影响。堆叠更多的层能够收集高阶协同信号和知识关联,以更好地捕获潜在的用户行为模式,但成本较高。在这里,我们在{1,2,3}范围内搜索퐿,并在表6中报告结果。我们有以下观察到的结果:一般来说,增加聚合层可以提高性能,特别是对于Last-FM数据集。我们将这种改进归因于两个原因:(1)收集更多相关的协同信号和知识关联可以为学习高质量的表示提供信息语义,加深对用户兴趣的理解。(2)双项嵌入显式地编码了两个项的行为和属性相似性,比其他方法中使用的单项嵌入更细粒度地描述了项。
值得一提的是,与其他基于传播的方法[45,47,49]相比,我们的模型对模型深度的敏感度较低。具体地说,当퐿=1时,HAKG也能获得与之相当的性能。这是因为我们的单独的聚合方案和GATE机制可以直接从用户-项目交互和KG中获取有用的模式,而面向KG的聚合方案需要更多的层次来编码混合和隐晦信息中的潜在语义。
4.4 层次结构可视化(Hierarchies Visualization)(RQ3)
图4 (A)嵌入到原点的节点(用户或物品)与节点受欢迎程度之间的距离。(B)KG中实体的双曲嵌入。
在本部分中,我们将可视化学习到的嵌入,以直观地了解我们的层次建模。具体地说,我们首先在阿里巴巴时尚数据集上使用二维嵌入训练HAKG,并分别分析G푏和G푘中显示的层次结构:(1)对于交互中的底层层次结构,我们绘制从原点到双曲线嵌入(例如,用户嵌入或协同项目嵌入)的距离与其受欢迎程度的关系。(2)对于KG中的层次关系,我们选择了具有代表性的实体,并用三元组证明了它们的连通性。如图4所示,我们发现:图4的左侧显示了一个明显的指数趋势,即对于不太受欢迎的项目,到原点的距离呈指数级增加,这与图1(B)中交互作用的程度分布一致。这证实了我们的模型利用了双曲线空间中呈指数级增长的数据量,并用它来自然地表示用户和项目。
图4右侧的连接性显示了实体之间清晰的层次关系。例如,实体底裤被分类为裤子、牛仔裤和裙子,并且物品(例如,T恤是上衣的一种)的属性信息可以用层次关系自然地保留。因此,HAKG能够捕获项目在嵌入空间中的属性语义,并为学习用户偏好提供更好的项目表示。
5 相关工作(Related Work)
现有的结合KG信息的推荐系统主要可以分为三类,即基于嵌入的方法、基于路径的方法和基于传播的方法。我们在以下内容中对它们进行简要回顾。
基于嵌入的方法Embedding-based methods[1,4,21,40,42,53,55]通过知识图嵌入(KGE)方法(例如,TransR[29]和TransD[22])将实体和关系直接嵌入KG中,作为推荐中的项目嵌入。例如,CKE[53]利用TransR从知识图中学习项目结构表示,并将学习到的嵌入提供给集成框架中的矩阵分解(MF)[35]。Hyper-Know[31]将知识图嵌入到PoincaréBall中,然后设计了一种自适应正则化机制来正则化项目表示。虽然这些方法得益于KGE的简单性和表现力,但它们未能捕获到用户-项目关系的高阶依赖关系,从而无法用于用户偏好学习。
- 基于路径的方法Path-based methods[5,19,23,32,48,56]旨在发现KG中的语义路径,然后将项目和用户连接起来,发现远程连通性,以便进行推荐。这些路径可用于通过递归神经网络[48、56]或注意力机制[19]来预测用户偏好。例如,KPRN[48]捕获了知识感知路径中的顺序依赖关系,以推断用户-项目交互的底层高阶关系。然而,定义适当的元路径模式需要领域知识,对于具有各种类型的实体和关系的复杂KG来说,这可能非常耗时。此外,特定于领域的元路径不可避免地导致对不同推荐场景的泛化较差[23,30]。
基于传播的方法Propagation-based methods[37,41,43-45,47,49]受到图神经网络[16,17,25,38,46,50]的最新发展的启发,它迭代地从邻域节点执行信息聚合机制。因此,这些方法能够以端到端的方式发现高阶关系。例如,KGAT[45]创建了统一的知识图(UKG),将用户-项目交互和KG结合起来,然后对其进行知识感知关注。CKAN[49]采用了异质传播策略,利用知识关联对用户偏好进行编码,进一步提高了性能。最近,KGIN[47]考虑了一种新的聚合机制来整合长期关系路径,并将用户偏好与意图分开以获得更好的可解释性。
如何在推荐系统中利用双曲线几何和双曲线嵌入已成为最近的趋势[8,31,36,39,54]。例如,HyperML[39]是第一个通过度量学习方法利用双曲几何进行推荐的工作;而HGCF[36]提出了一个用于协同过滤的双曲GCN模型。然而,就我们所知,现有的方法中没有一种考虑在更细粒度的层次结构级别上建模KG关系。此外,它们未能保存物品的关键高阶协同信号。我们的工作与它们在层次建模和聚合方面的不同之处在于,我们的目的是解决层次关系对于剖析项的重要性,并通过双项嵌入显式传播两种信息,以更好地识别用户行为。
6 结论和下一步工作(Conclusion and Future Work)
本文提出了一种新的知识感知推荐模型HAKG,该模型捕获数据在双曲空间中的底层层次结构,并在KG中刻画具有层次关系的项目。此外,HAKG采用双项嵌入分别对项的协同信号和知识关联进行编码,并开发了一种门控机制来控制针对用户行为模式的区分信号。在三个真实数据集上进行的大量实验证明了HAKG的优越性。在未来,我们计划研究双曲空间[52]中的数值误差问题,并研究双曲空间中的所有运算(如加法和乘法),以充分利用双曲几何的力量。

若有收获,就点个赞吧
0 人点赞
