A Survey on Knowledge Graph-Based Recommender Systems
- Qingyu Guo, Fuzhen Zhuang, Chuan Qin, et al. A Survey on Knowledge Graph-Based Recommender Systems[J]. In TKDE 2020.
中国科学院大学计算所,中国科学技术大学 2020.02.28
摘要(Abstract)
为了解决各种在线应用中的信息爆炸问题,提高用户体验,人们开发了推荐系统来对用户偏好进行建模。尽管已经做出了许多努力来实现更个性化的推荐,但推荐系统仍然面临着一些挑战,例如数据稀疏和冷启动。近年来,利用知识图谱作为辅助信息生成推荐引起了人们的极大兴趣。这种方法不仅可以缓解上述问题,以便更准确地进行推荐,而且还可以为推荐的项目提供解释。本文对基于知识图谱的推荐系统进行了系统的综述。我们收集了这一领域最近发表的论文,并从两个角度进行了总结。一方面,我们通过重点研究论文如何利用知识图谱来获得准确和可解释的推荐来研究所提出的算法。另一方面,我们介绍了这些工作中使用的数据集。最后,我们提出了该领域几个潜在的研究方向。
关键词(Keywords)
1 引言(Introduction)
随着互联网的快速发展,数据量呈指数级增长。由于信息过载,用户很难在大量的选择中挑选出自己感兴趣的东西。为了改善用户体验,推荐系统已被应用于诸如音乐推荐[1]、电影推荐[2]和在线购物[3]等场景。<br /> 推荐算法是推荐系统的核心,主要分为基于协同过滤(CF)的推荐系统、基于内容的推荐系统和混合推荐系统[4]。基于CF的推荐基于交互数据中用户或项目的相似度来建模用户偏好,而基于内容的推荐则利用项目的内容特征。基于CF的推荐系统能够有效地捕捉用户偏好,不需要在基于内容的推荐系统中提取特征,易于在多种场景下实现,因此得到了广泛的应用。然而,基于CF的推荐存在数据稀疏性和冷启动问题[6]。为了解决这些问题,混合推荐系统被提出以统一交互级别的相似性和内容级别的相似性。在这个过程中,已经探索了多种类型的辅助信息,例如项目属性[7]、[8]、项目评论[9]、[10]以及用户的社交网络[11]、[12]。<br /> 近年来,将知识图谱(KG)作为辅助信息引入推荐系统引起了研究者的关注。KG是一个异构图,其中节点充当实体,边表示实体之间的关系。项目及其属性可以映射到KG中,以了解项目之间的相互关系[2]。此外,还可以将用户和用户侧信息整合到KG中,使用户与项目之间的关系以及用户偏好能够更准确地捕获[13]。图1是一个基于KG的推荐示例,其中向Bob推荐了电影《Avatar》和《Blood Diamond》。这个KG将用户、电影、演员、导演和流派作为实体,而互动、归属、表演、导演和友谊是实体之间的关系。通过KG,电影和用户之间有着不同的潜在联系,这有助于提高推荐的精确度。基于KG的推荐系统的另一个好处是推荐结果的可解释性[14]。在同一示例中,通过遵循用户-项目图中的关系序列,可以知道向Bob推荐这两部电影的原因。例如,推荐《Avatar》的一个原因是,《Avatar》与Bob之前看过的《Interstellar》是同一类型。最近,提出了多个KGs,如Freebase[15],DBpedia[16],Yago[17],以及Google的Knowledge Graph[18]等,方便构建推荐的KGs。<br />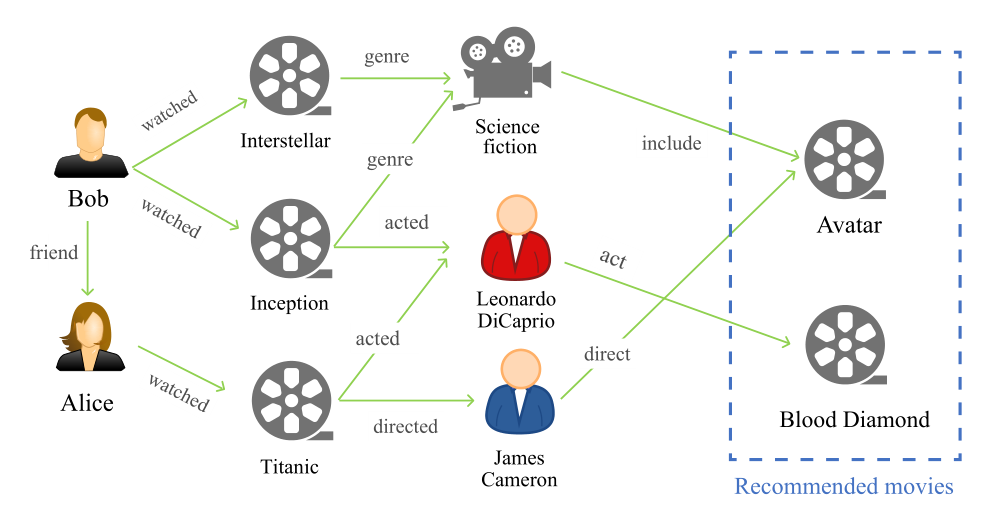<br />**图1 基于KG推荐的示例**<br /> 这项调查的目的是提供一个全面的文献回顾,在推荐系统中使用KGs作为辅助信息。通过调查,我们发现现有的基于KG的推荐系统有三种方式应用KGs:基于嵌入的方法、基于路径的方法和统一的方法。我们详细说明了这些方法之间的异同。除了更准确的推荐外,基于KG的推荐的另一个好处是可解释性。我们讨论了不同的工作如何利用KG进行解释性推荐。此外,根据我们的调查,我们发现KG在多个场景中充当辅助信息,包括对电影、书籍、新闻、产品、兴趣点(POI)、音乐和社交平台的推荐。我们收集最近的工作,根据应用对它们进行分类,并收集在这些工作中评估的数据集。<br /> 本文的结构如下:在第二节中,我们介绍了KGs和推荐系统的基础;在第三节中,我们介绍了本文使用的符号和概念;在第四节和第五节中,我们分别从方法和评价数据集的角度对基于KGs的推荐系统进行了回顾;在第六节中,我们提供了该领域的一些潜在的研究方向;最后,我们在第七节中总结了本次调查。
2 相关工作(Related Work)
这一部分介绍了基于知识图谱的推荐的基础知识,并总结了基于知识图谱的推荐领域的相关工作,包括知识图谱和推荐系统。
2.1 知识图谱(Knowledge Graphs)
KG是一种表示来自多个领域的大规模信息的实用方法[19]。描述KG的一种常见方式是遵循资源描述框架(RDF)标准[20],其中节点代表实体,而图中的边充当实体之间的关系。每条边都以三元组(头实体、关系、尾实体)的形式表示,在图中也称为事实,表示头实体和尾实体之间的特定关系。例如,美国总统唐纳德·特朗普(Donald Trump)表示唐纳德·特朗普是美国总统。KG是一个异构网络,因为它在图中包含多种类型的节点和关系。这样的图具有很强的表示能力,因为一个实体的多个属性可以通过跟踪图中的不同边来获得,并且通过这些关系链接可以发现实体的高层关系。知识图谱的概念发展于1980年代[21],当时知识图谱被纳入医学和社会科学专家系统的框架。后来,这一应用被扩大到语言和逻辑领域。2012年,谷歌将KG引入搜索框架,以更好地理解查询并使搜索结果更加用户友好[18]。到目前为止,KGs已经被创建并应用于多种场景,包括搜索引擎、推荐系统、问答系统[22]、关系检测[23]等。<br /> 我们在表1中列出了一些流行的KG。根据所涵盖的知识范围,这些KG可以分为两类。第一组是跨域KG,如Freebase[15]、DBpedia[16]、Yago[17]和Nell[24],第二组是特定领域的KG,如Bio2RDF[25]。在本次调查中,推荐系统使用了六个跨域KG,我们简要介绍如下:Frebase[15]由Metaweb于2007年推出,并于2010年被Google收购。到2015年,它包含了30多亿个事实和近5000万个实体[26]。虽然它是一个跨域的KG,但它大约77%的信息是在媒体领域[27]。目前,这些数据可以在谷歌的数据转储中获得[28]。DBpedia[16]是一个开放社区项目,由柏林自由大学和莱比锡大学的研究人员与OpenLink Software合作发起。第一个版本于2007年发布,每年更新一次。主要知识是从维基百科的不同语言版本中提取出来的,DBpedia将它们结合在一个大规模的图结构中。Yago[17](%E5%8F%88%E4%B8%80%E4%B8%AA%E4%BC%9F%E5%A4%A7%E7%9A%84%E6%9C%AC%E4%BD%93%E8%AE%BA)是由马克斯·普朗克研究所于2007年提出的。它包含500多万个事实,如人员、地点和组织。它自动从维基百科和多个来源(包括WordNet[29]和GeoNames[30])提取和统一知识,然后将它们统一到RDF图中。Satori[31]是微软提出的KG。与支持谷歌搜索引擎的谷歌知识图谱类似,Satori也被整合到搜索引擎必应中。虽然关于Satori KG的公开可访问文件有限,但众所周知,Satori在2012年由3亿个实体和8亿个关系组成[32]。CN-DBpedia[33]是中国最大的KG。它由复旦大学于2015年发布,拥有超过1600万个实体和超过2.2亿个关系。它自动从百度百科、互动百科和中文维基百科中提取知识,然后将它们整合到中文数据库中。该系统不断更新,几乎不需要人力。<br />**表1 常用知识图谱汇总**<br />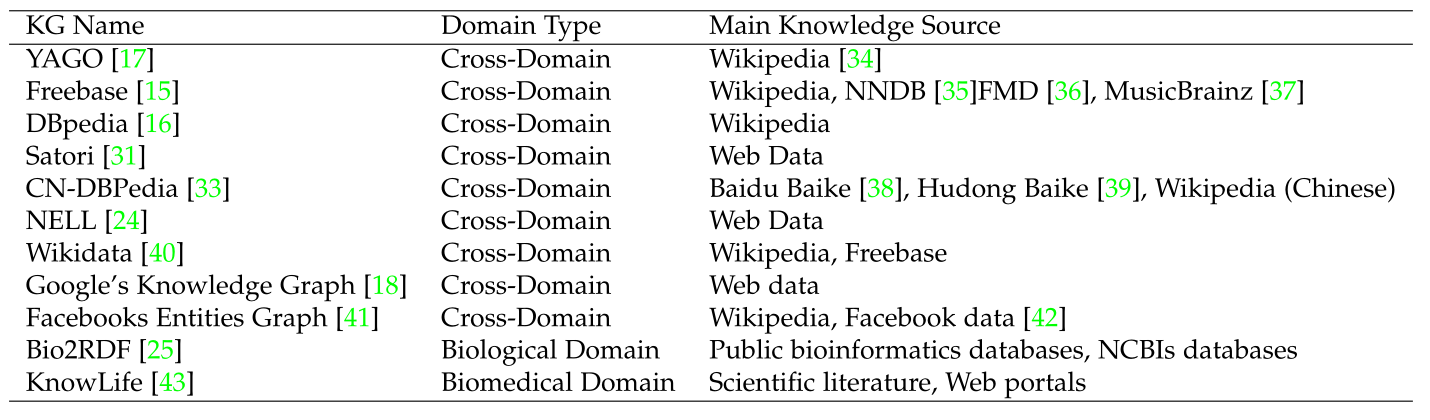
2.2 推荐系统(Recommender Systems)
推荐系统已经应用于许多领域,包括电影[2]、[44]、音乐[1]、[45]、POI[46]、[47]、新闻[14]、[48]、教育[49]、[50]等。推荐任务是向给定的用户推荐一个或一系列未被观察到的项目,可以分为以下几个步骤。首先,系统学习给定用户和项目的表示和。然后学习一个评分函数,该函数对对的偏好进行建模。最后,可以通过对项目的偏好分数进行排序来生成推荐。要了解用户/项目表示和评分函数,有三种主要方法,如下所述。
协同过滤(Collaborative Filtering)。CF假设用户可能对与他们有相似交互记录的人选择的项目感兴趣。交互可以是显式交互[51]、[52],如评级,也可以是隐式交互[53]、[54],如点击和查看。要实现基于CF的推荐,需要来自多个用户和项目的交互数据,从而形成用户-项目交互矩阵。基于CF的方法包含两种主要技术:基于内存的CF和基于模型的CF[5]。具体地,基于内存的CF首先从用户-项目交互数据中学习用户-用户相似度。然后,基于与特定用户相似的人的交互记录,将未观察到的项目推荐给给定用户。或者,一些模型学习项目之间的相似性,并基于用户的购买历史向用户推荐相似的项目。基于模型的CF方法试图通过建立推理模型来缓解稀疏性问题。一种常见的实现是潜在因素模型[55]、[56],它从高维用户-项目交互矩阵中提取用户和项目的潜在表示,然后使用内积或其他方法计算用户和项目之间的相似度。
- 基于内容的过滤(Content-based Filtering)。与从全局用户-项目交互数据中学习用户和项目表示的基于CF的方法相比,基于内容的方法从项目的内容中描述用户和项目。基于内容的过滤的假设是,用户可能对与他们过去交互的项目相似的项目感兴趣。项目表示是通过从项目的辅助信息(包括文本、图像等)中提取属性来获得的,而用户表示是基于个人交互项目的特征。将候选项目与用户简档进行比较的过程实质上是将它们与用户以前的记录进行匹配。因此,该方法倾向于推荐与用户在过去喜欢的项目相似的项目[57]。
混合方法(Hybrid Method)。混合方法是利用多种推荐技术,以克服仅使用一种方法的局限性。基于CF的推荐的一个主要问题是用户-项目交互数据的稀疏性,这使得从交互的角度很难找到相似的项目或用户。这个问题的一个特例是冷启动问题,这意味着对新用户或项目的推荐是困难的,因为如果没有任何交互记录就无法确定用户-用户和项目-项目的相似度。通过将用户和项目的内容信息,也称为用户侧信息和项目侧信息,融入到基于CF的框架中,可以获得更好的推荐性能[6]。一些常用的项目辅助信息包括项目属性[7]、[8]、[58]、[58],如品牌、类别;项目多媒体信息,如文本描述[59]、图像特征[60]、音频信号[61]、视频特征[62];以及项目评论[9]、[10]。用户侧信息的常见选项涉及用户的人口统计信息[63],包括职业、性别和爱好;以及用户网络[11]、[12]。在本次调查中,基于KG的推荐系统利用KG作为辅助信息,结合基于CF的技术来实现更准确的推荐。
3 概述(Overview)
在深入研究利用KGs作为辅助信息进行推荐的最新方法之前,我们首先介绍本文中使用的符号和概念,以消除误解。为方便起见,我们在表2中列出了一些符号及其说明。<br />**表2 本文中使用的符号**<br />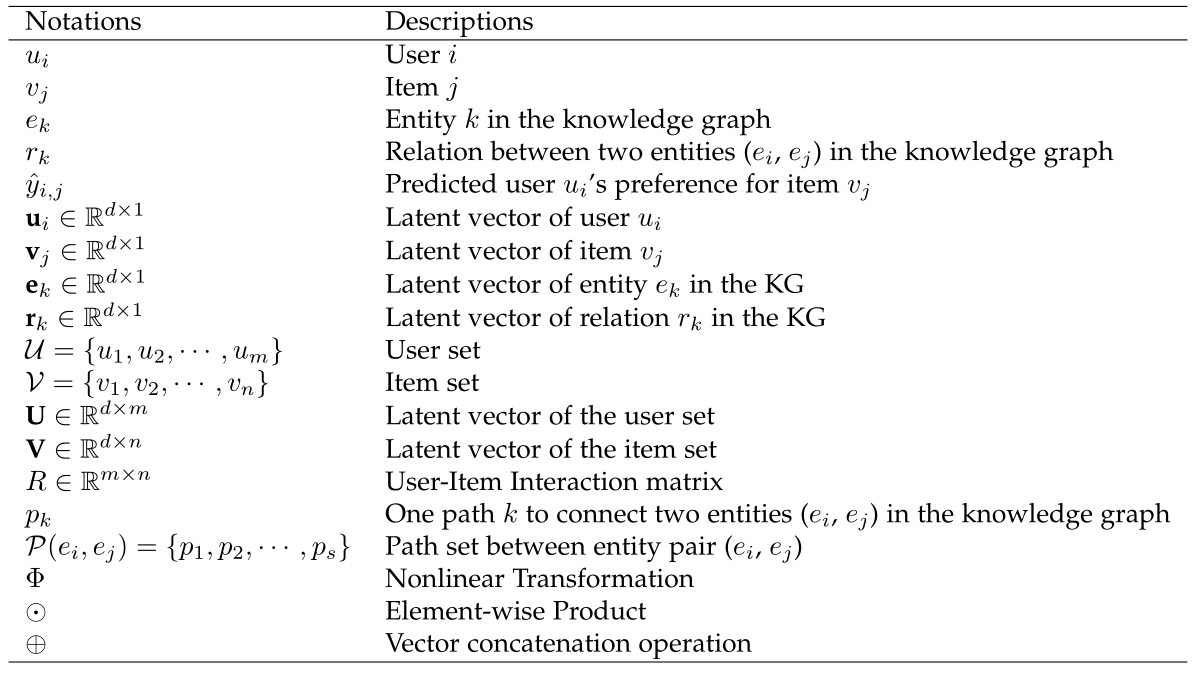
异构信息网络(HIN)。HIN是具有实体类型映射函数
 和链接类型映射函数
和链接类型映射函数 的有向图
的有向图 。每个实体
。每个实体 属于实体类型
属于实体类型 ,并且每个链接
,并且每个链接 属于关系类型
属于关系类型 。此外,实体类型的个数
。此外,实体类型的个数 和/或关系类型的个数
和/或关系类型的个数 。
。- 知识图谱(KG)。知识图谱
 是一个有向图,它的节点是实体,边是主体-属性-客体三重事实。形式上的每条边(头部实体、关系、尾部实体)(表示为
是一个有向图,它的节点是实体,边是主体-属性-客体三重事实。形式上的每条边(头部实体、关系、尾部实体)(表示为 )表示从实体
)表示从实体 到实体
到实体 的关系
的关系 。它可以被视为HIN的一个实例。
。它可以被视为HIN的一个实例。 - 元路径。元路径
 是定义在网络模式
是定义在网络模式 的图上的一条路径,它定义了
的图上的一条路径,它定义了 和
和 之间的一种新的复合关系
之间的一种新的复合关系 ,其中
,其中 和
和 对
对 。它是连接HIN中对象对的关系序列,可以用来提取图中的连通性特征。
。它是连接HIN中对象对的关系序列,可以用来提取图中的连通性特征。 - 元图。与元路径类似,元图是连接HIN中两个实体的另一个元结构。不同之处在于,元路径仅定义一个关系序列,而元图是不同元路径的组合[64]。与元路径相比,元图可以包含图中实体之间更具表现力的结构信息。
- 知识图谱嵌入(KGE)。KGE是将知识图谱
 嵌入到低维空间[65]中。在嵌入过程之后,每个图组件,包括实体和关系,用
嵌入到低维空间[65]中。在嵌入过程之后,每个图组件,包括实体和关系,用 维向量来表示。低维嵌入仍然保留了图的固有性质,这些性质可以通过语义或图中的高阶邻近度来量化。
维向量来表示。低维嵌入仍然保留了图的固有性质,这些性质可以通过语义或图中的高阶邻近度来量化。 - 用户反馈。对于
 个用户
个用户 和
和 个项目
个项目 ,我们定义二进制用户反馈矩阵
,我们定义二进制用户反馈矩阵 如下:
如下:

注意, 的值为1表示用户
的值为1表示用户 与项目
与项目 之间存在隐式交互,比如点击、观看、浏览等行为,这种隐式交互并不一定意味着用户
之间存在隐式交互,比如点击、观看、浏览等行为,这种隐式交互并不一定意味着用户 对项目
对项目 的偏好。除非另有说明,本文中使用的用户反馈是指隐式反馈。然而,在某些特定的场景中,使用显式用户偏好的显式反馈。例如,在电影推荐中,用户明确地将一部电影的评分范围定在1到5之间。一些论文提取了评分等级为5的数据,以表明用户在这种情况下的偏好。
的偏好。除非另有说明,本文中使用的用户反馈是指隐式反馈。然而,在某些特定的场景中,使用显式用户偏好的显式反馈。例如,在电影推荐中,用户明确地将一部电影的评分范围定在1到5之间。一些论文提取了评分等级为5的数据,以表明用户在这种情况下的偏好。
- H-Hop邻居。图中的节点可以通过多跳关系路径连接:
 ,在这种情况下,
,在这种情况下, 是
是 的
的 跳邻居,可以表示为
跳邻居,可以表示为 。请注意,
。请注意, 就是
就是 本身。
本身。 - 相关实体。给定交互矩阵
 和知识图谱
和知识图谱 ,用户
,用户 的
的 跳相关实体的集合可以表示为
跳相关实体的集合可以表示为

其中 是用户的历史交互项目的集合。
是用户的历史交互项目的集合。
- 用户波纹集。用户的波纹集被定义为知识三元组,其头实体是
 跳相关实体
跳相关实体 ,
,

- 实体波纹集。实体
 的波纹集定义为
的波纹集定义为

4 基于知识图谱的推荐系统方法(Methods of Recommender Systems with Knowledge Graphs)
在这一部分中,我们收集了与基于KG的推荐系统相关的论文。根据这些工作如何利用KG信息,我们将其分为三类:基于嵌入的方法、基于路径的方法和统一方法。我们将介绍不同的方法如何利用KGs来提高推荐结果。为了方便读者查阅文献,我们在表3中总结和组织了这些论文,其中列出了它们的出版信息、利用KG进行推荐的方法以及这些作品所采用的技术。<br /> 解释性推荐是近年来的另一个研究热点。如果向用户提供适当的解释,则有助于用户采用由推荐系统生成的推荐[97]。与传统的推荐系统相比,基于KG的推荐使得推理过程变得可行。在这一部分中,我们还将展示不同的工作方式如何利用KGs提供可解释的推荐。<br />**表3 论文收集表**<br />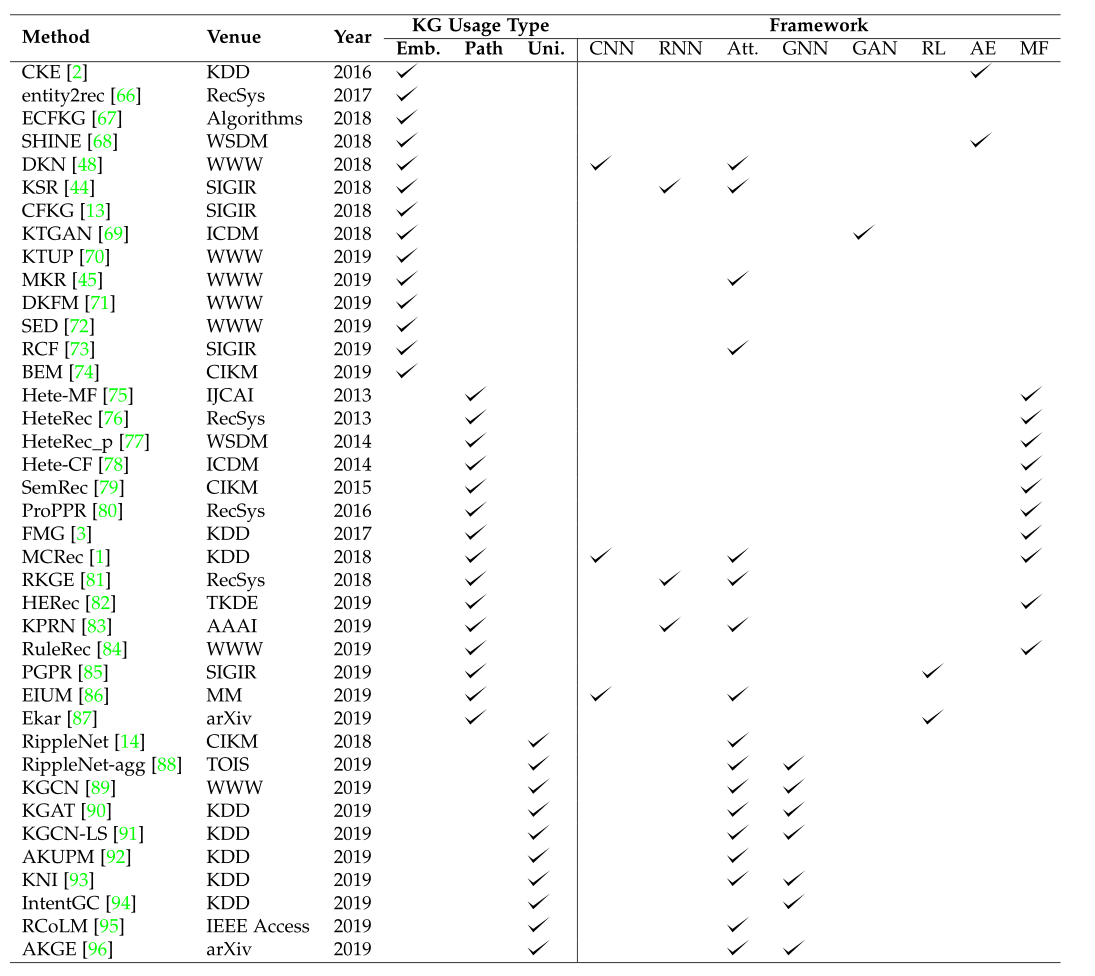
4.1 基于嵌入的方法(Embedding-based Methods)
基于嵌入的方法通常直接使用KG中的信息来丰富项目或用户的表示。为了充分利用KG信息,需要使用知识图谱嵌入(KGE)算法将KG编码为low-rank嵌入。KGE算法可以分为两类[98]:translation距离模型,如TransE[99]、TransH[100]、TransR[101]、TransD[102]等,以及语义匹配模型,如DistMult[103]。<br /> 根据用户是否包含在KG中,基于嵌入的方法可以分为两类。在第一种类型的方法中,使用从数据集或外部知识库中提取的项目及其相关属性来构建KG。我们称这样的图为项目图。请注意,用户不包括在这样的项目图中。遵循这一策略的论文利用知识图谱嵌入(KGE)算法对图进行编码,以更全面地表示项目,然后将项目辅助信息整合到推荐框架中。大体思路可以说明如下。每个项目的潜在向量是通过聚合多个来源的信息获得的,例如知识图谱、用户-项目交互矩阵、项目内容和项目属性。每个用户的潜在向量可以从用户-项目交互矩阵中提取,也可以从交互项目的嵌入组合中提取。然后,用户选择的概率可以用以下公式计算<br /> (1)<br />其中指的是将用户和项目的嵌入映射到偏好分数中的函数,该偏好分数可以是内积、DNN等。在推荐阶段,将按照偏好分数的降序生成结果。<br /> 例如,Zhang等人[2]提出了CKE,它统一了CF框架中的各种辅助信息。他们将项目的结构知识(用知识图谱表示的项目属性)和内容(文本和视觉)知识输入到知识库嵌入模块中。使用TransR算法对项目的结构知识的潜在向量进行编码,同时使用自编码器结构提取文本特征和视觉特征。然后,将这些表示与从用户-项目交互矩阵提取的偏移向量一起聚合。每一项目的最终表示可以写成<br /> (2)<br /> 在获得用户的潜在向量后,通过内积获得偏好分数。最后,在预测阶段,通过以下排序标准向推荐项目:<br /> (3)<br /> 实验表明,加入结构知识可以提高推荐的性能。<br /> Wang等人[48]提出DKN进行新闻推荐。它通过结合Kim CNN[104]学习的句子的文本嵌入和通过TransD在新闻内容中的实体的知识嵌入来对新闻进行建模。通过引入实体KG,可以在新闻的最终嵌入中描述新闻的高层语义关系。为了捕捉用户对新闻的动态兴趣,通过使用注意力机制聚合历史点击新闻的嵌入来学习用户的表示。被点击的新闻集合中每个新闻的注意权重通过下式计算<br /> (4)<br />其中是DNN层,是候选新闻。然后,通过点击新闻嵌入的加权和来计算最终的用户嵌入:<br /> (5)<br />最后,用户对候选新闻主播的偏好可以用公式1来计算,其中f(·)是DNN层。Huang等人的研究成果。[44]提出了顺序推荐的KSR框架。KSR使用具有知识增强型键值记忆网络(KV-MN)的GRU网络来模拟来自顺序交互的全面用户偏好。GRU网络捕获用户的顺序偏好,而KV-MN模块利用知识库信息(通过TRANSE学习)来建模用户的属性级偏好。通过这种方式,可以捕获细粒度的用户偏好来进行推荐。具体地,在时间t处,用户界面的潜在向量被表示为Uti=HTi⊕MTi,其中HTi和MTi分别代表用户交互级别偏好和属性级别偏好的表示。主播的潜在向量表示为Vj=qj⊕Ej·uti,其中Qj是嵌入到GRU网络中的项,Ej是嵌入到KG中的项。在将UTI和主播转换为相同维度后,根据公式1得到的分数对用户的物品偏好进行排名,其中f(·)为内积。<br />另一种基于嵌入的方法直接构建用户-项目图,其中用户、项目及其相关属性充当节点。在用户-项目图中,既有属性级关系(品牌、类别等),也有与用户相关的关系(共同购买、共同查看等)。用作边。在获得实体在图中的嵌入后,用户的偏好可以用公式1来计算,或者通过进一步考虑关系在图中的嵌入来计算<br />其中f(·)映射用户表示ui、项表示vj以及将r嵌入标量的关系。<br />张某等人。[13]提出了CFKG,它构造了一个用户项KG。在这个用户-物品图中,用户行为(购买、提及)被视为实体之间的一种关系类型,以及多种类型的物品边信息(评论、品牌、品类、购买等)。都包括在内。为了学习实体和关系在图中的嵌入,该模型定义了一个度量函数d(·)来根据给定的关系来度量两个实体之间的距离。在推荐阶段,系统会按照用户界面到主播距离的升序对候选项目j进行排序<br />其中,rBuy是关系类型‘Buy’的学习嵌入。通过购买关系衡量的UI和主播之间的距离越小,表示偏好分数ˆyi,j越高。<br />Wang等人。[68]提出SINE,将名人推荐任务作为图中实体之间的情感链接预测任务。具体来说,SINE为用户和目标(名人)建立了情感网络Gs,并利用他们的社交网络Gr和个人资料信息网络Gp作为辅助信息。这三个网络嵌入了自动编码技术,然后聚合为用户和目标的表示。最后,推荐可以通过以下公式1来生成,其中f(·)是DNN层。Dadoun等人。[71]为POI建议提议的DKFM。DKFM在城市KG上应用TRASE来丰富目的地的表示,这表明POI推荐的性能有所提高。<br />以往的工作一般直接利用KGE技术学习的结构知识的原始潜在向量进行推荐。最近,一些文献试图通过改进学习的实体/关系表示来提高推荐性能。例如,Yang等人。[69]引入了一个基于GaN的模型KTGAN,用于电影推荐。在第一阶段中,KTGAN通过在电影的KG上合并Metapath2V EC模型[105]以及在电影的属性上将Vtj与Word2V EC模型[106]合并来学习嵌入Vkj的知识。电影主播的初始潜在向量被表示为VInitialj=Vkj⊕Vtj。类似地,用户界面的初始潜在向量表示为uInitiali=uki⊕uti,其中uki是用户界面喜欢的电影的知识嵌入的平均值,而uti是用户界面的标签嵌入。然后,提出了一个生成器G和一个鉴别器D来提炼用户和项目的初始表示。生成器G尝试根据得分函数pθ(vj|ui,r)为用户UI生成相关(喜爱的)电影,其中r表示UI和主播之间的相关性。在训练过程中,G的目标是让pθ(主播|ui,r)近似ui真正喜欢的电影分发(vj|ui,r),这样G就可以选择相关的用户电影配对。识别器D是根据学习的得分函数fφ(ui,vj)区分相关用户-电影对和无关对的二进制分类器。GaN模块的目标函数被写为,<br />其中P(vj|ui)=11+exp(−fφ(ui,vj))表示用户UI偏爱电影主播的概率。在对抗性训练后,学习了UI和主播的最佳表示,并可以使用G的得分函数pθ(vj|ui,r)对电影进行排名。后来,叶诗文等人。[74]提出了BEM,它对物品使用两种类型的图,知识相关图(包含物品属性信息,如品牌、类别等)。和用于推荐的行为图(包含与商品交互相关的信息,包括共同购买、共同评级、共同添加到购物车)。边界元首先从知识关联图和基于GNN模型的行为图中学习初始嵌入。然后,BEM应用贝叶斯框架来相互细化这两种类型的嵌入。推荐可以通过在行为图中找到交互项中最接近的项来生成,这些项是通过‘共同购买’或‘共同点击’的关系来衡量的。<br />另一种趋势是采用多任务学习策略,在KG相关任务的指导下共同学习推荐任务。通常,在推荐任务中,从用户-项交互矩阵中学习函数f(ui,vj),以对比观察到的交互对(ui,vj)和未观察到的交互对(ui,vj0);在KG相关任务中,学习另一个函数g(eh,r,et)以确定(eh,r,et)是否为KG中的有效三元组。这两个部分与以下目标函数相联系,<br />其中,LREC是推荐的损失函数,LKG是KG相关任务的损失函数,λ是平衡两个任务的超参数。多任务学习的一般动机是,嵌入在推荐模块中的项目与嵌入在KG中的关联实体共享特征。<br />曹等人。[70]提出了联合学习推荐和知识图补全的KTUP算法。在推荐模块中,损失函数定义为<br />其中(u,v)是用户-项目交互矩阵中的观察到的用户-项目对(ruv=1);(u,v0)表示未观察到的用户-项目对(ruv=0);p表示用户对给定项目的偏好的潜在向量;f(·)是提出的基于翻译的模型TUP,用于对这种用户-项目对的正确性进行建模;以及σ是S型函数。KG完井模块采用铰链损耗,<br />其中,G−是通过替换有效三元组(eh,r,et)∈G中的eh或Et来构造的;g(·)是TransH模型,较低的g(eh,r,Et)值推断这种三元组的更高的正确性;[·]+,max(0,·);以及γ是正确三元组和错误三元组之间的差值。推荐模块用于挖掘用户u与项目v之间的偏好关系,知识补全模块用于挖掘KG中项目之间的关系。这两个模块之间的桥梁是项目可以与KG中对应的实体对齐,用户的偏好与KG中实体之间的关系有关。因此,项目和偏好的嵌入可以通过在KTUP框架下的每个模块中传递实体、关系和偏好的知识来丰富。同时,Wang等人也提出了自己的观点。[45]拟议的MKR,由一个推荐模块和一个KGE模块组成。前者学习用户和项的潜在表示,后者利用语义匹配KGE模型学习项关联实体的表示。这两个部分与交叉压缩单元相连,用于传递知识并共享推荐模块中的项目和KG中的实体的规则化。Xin等人。[73]提出了RCF,它引入了项的层次描述,包括关系类型嵌入和关系值嵌入。RCF利用KGE的DistMult模型来保留项之间的关系结构。然后,利用注意机制分别对用户的类型偏好和价值偏好进行建模。通过推荐模块和KG关系建模模块的联合训练,可以做出像样的推荐。<br />**基于嵌入的方法综述(Summary for Embedding-based Methods)**大多数基于嵌入的方法[2]、[44]、[45]、[48]、[69]、[70]、[72]、[73]、[74]构建具有多种类型的项旁信息的KG以丰富项的表示,并且这些信息可用于更精确地对用户表示进行建模。一些模型[13]、[66]、[67]、[68]、[71]通过在图中引入用户来构建用户-项目图,从而可以直接对用户偏好进行建模。实体嵌入是基于嵌入的方法的核心,一些论文使用GaN[69]或BEM[74]来改进嵌入以获得更好的推荐。基于嵌入的方法本质上利用了图结构中的信息。文献[45]、[70]、[73]应用多任务学习策略,将推荐模块与图相关任务一起进行联合训练,以提高推荐质量。
4.2 基于路径的方法(Path-based Methods)
基于路径的方法构建用户-项目图,并利用图中实体的连接模式进行推荐。基于路径的方法是从2013年发展起来的,传统的论文将这种方法称为HIN中的推荐方法。通常,这些模型利用用户和/或项目的连接性相似性来增强推荐。为了度量图中实体之间的连接性相似性,通常使用PathSim[107]。它被定义为
其中Pmn是实体m和n之间的路径。
一种基于路径的方法利用不同元路径中实体的语义相似性作为图的正则化来细化HIN中用户和项的表示。然后,UI对主播的偏好可以通过下面的公式1来预测,其中f(·)是指内积。通常利用三种类型的实体相似性,
- 用户-用户相似度:这个术语的目标函数是
其中k·kf表示矩阵Frobenius范数,Θ=[θ1,θ2,···,θL]表示每个元路径的权重,U=[U1,U2,···,Um]表示所有用户的潜在向量,以及SLi,j表示元路径l中用户i和j的相似度得分。
如果用户共享较高的基于元路径的相似度,则用户-用户相似度迫使用户嵌入到潜在空间中
- 项目-项目相似度:此术语的目标函数为
其中V=[v1,v2,···,vn]表示所有项目的潜在向量。与用户-用户相似度相似,如果基于元路径的相似度较高,则项目的低级表示应该是接近的。
用户-项目相似度:本术语的目标函数
如果用户和项目基于元路径的相似度较高,则用户-项目相似项将迫使用户和项目的潜在向量彼此接近。
Yu等人。[75]提出了HETE-MF,它提取L条不同的元路径,并计算每条路径上的项-项相似度。项目-项目正则化与加权非负矩阵分解方法[108]相结合,以提炼用户和项目的低级表示以获得更好的推荐。后来,罗等人提出了自己的观点。[78]提出了HeteCF方法,将用户-用户相似度、项目-项目相似度和用户-项目相似度作为正则化条件,发现用户对未评分项目的亲和度。因此,HETE-CF模型的性能优于HETE-MF模型。
基于路径的方法综述Summary for Path-based Methods。基于路径的推荐方法基于用户-项目图生成推荐,在过去也被称为基于HIN的推荐。传统的基于路径的方法[3]、[75]、[76]、[77]、[78]、[79]、[82]一般将MF与HINS中提取的元路径相结合。这些方法利用路径连通性来规则化或丰富用户和/或项表示。这些方法的缺点是它们通常需要领域知识来定义元路径的类型和数量。RuleRec[84]试图通过以自动方式利用外部KG中的规则来克服这一限制。随着深度学习技术的发展,人们提出了不同的模型[1]、[81]、[83]、[85]、[86]、[87]对路径嵌入进行显式编码。推荐可以通过路径嵌入来生成,或者通过发现连接用户-项目对的最显著的路径来生成。
基于路径的方法自然会将可解释性引入推荐过程。对于传统的基于路径的方法,其动机是在元路径级别上匹配项目或用户的相似度。推荐结果可以从预定义的元路径中找到引用。RuleRec利用外部KG生成推荐规则。由于规则和对应的权重是明确的,因此用户也可以获得推荐的原因。最近的工作利用深度学习模型自动挖掘用户-项目对的显著路径,这反映了图中的推荐过程。
4.3 基于统一的方法(Unified Methods)
如4.1节和4.2节所讨论的,基于嵌入的方法利用KG中用户/项的语义表示来进行推荐,而基于路径的方法使用语义连通性信息,并且这两种方法仅利用图中信息的一个方面。为了充分利用KG中的信息以获得更好的推荐,提出了将实体和关系的语义表示与连接信息相结合的统一方法。统一的方法是基于嵌入传播的思想。这些方法在KG中联结结构的指导下,对实体表示进行了细化。在获得用户UI和/或潜在项目VJ的丰富表示之后,可以用公式1预测用户的偏好。
第一组作品从用户的交互历史中提炼出用户的表示。这些工作首先提取多跳波纹集合Skui(k=1,2,···,H)(在第3节中定义),其中S1ui是图中的三元组(Eh,r,Et),头部实体是用户UI的参与项。该方法的基本思想是通过利用过去交互项的嵌入以及这些交互项的多跳邻居来学习用户嵌入。学习用户表示UI的过程可以以如下的一般形式来编写
其中,gu(·)是将多跳实体的嵌入与偏置连接在一起的函数。由于传播是从用户参与的项目开始的,因此该过程可以被视为在图中传播用户的偏好。
Wang等人。[14]提出了RippleNet,这是首次引入偏好传播概念的工作。具体地说,RippleNet首先分配具有初始嵌入的KG中的实体。然后从KG中采样波纹集合Skui(k=1,2,···,H)。为了改进用户表示,聚合过程可以如下所示。从S1ui开始,每个头部实体通过以下方式依次与候选项主播的嵌入交互
其中Ri∈Rd×d表示关系ri的嵌入,Ehi∈Rd表示头部实体在涟漪集合中的嵌入。在此过程中,在关系空间中计算候选项目主播和头部实体的相似度。然后,可以通过以下方式计算用户对历史交互的一阶响应
其中,ETI表示尾部实体在波纹集中的嵌入。通过用公式24中的(h−1)阶响应oh−1u替换vj,然后迭代地与h跳波纹集合Shu中的头部实体交互,可以获得用户的h阶(h=2,3,··,H)阶响应OHu。用户界面的最终表示式为:用户界面=o1ui+o2ui+···+oHue。最后,可以使用以下命令生成偏好分数
其中σ(X)是Sigmoid函数。通过这种方式,RippleNet沿着KG中的路径传播来自历史兴趣的用户偏好。
类似于RippleNet,Tang等人。[92]提出了AKUPM,它根据用户的点击历史对用户进行建模。AKUPM首先将TransR应用于实体表示。在每个传播过程中,AKUPM学习带有自我关注层的实体之间的关系,并将用户的偏好传播到有偏见的不同实体。最后,利用自我注意机制对交互项的不同阶次邻居的嵌入进行聚合,得到最终的用户表示。后来,李等人提出了自己的观点。[95]扩展了AKUPM并设计了RCoLM。RCoLM联合培训KG完成模块和推荐模块,其中AKUPM是骨干。RCoLm假设一个项目在两个模块中具有相同的潜在表征,从而统一了两个模块,促进了它们之间的相互增强。因此,RCoLM的表现优于AKUPM模型。
第二组工作集中于通过聚合项目的多跳邻居N KV(k=1,2,···,H)的嵌入来提炼项目表示VJ。对此过程的一般描述是
其中,Skvj是候选项Vj的波纹集合,而gv(·)是串联多跳邻居的嵌入的函数。串联多跳邻居的嵌入需要两个步骤。第一步是学习候选项主播的k跳邻居的表示,
其中α(Eh,r,Et)表示不同邻居的重要性。则对于Eh∈Skvj,可以通过以下方式更新表示
其中,agg是聚合运算符。在这个过程中,k跳邻居的信息与(k−1)跳邻居的信息被聚合。通常使用四种类型的聚合器:
总和聚合器。求和聚合器对两个表示进行求和,然后进行非线性变换。
Concat聚合器。连接聚集器连接两个表示形式,然后应用非线性变换。
邻居聚合器。邻居聚集器直接用来自邻居的表示替换实体的表示。
双向交互聚合器。双向交互聚集器既考虑实体之间的总和关系,也考虑实体之间的基于元素的乘积关系。第二个术语允许从类似实体传递更多信息。
Wang等人。[89]提出了KGCN,它通过将KG中的实体从主播的远邻聚合到主播本身来对候选项目主播的最终表示进行建模。KGCN首先对KG中的候选项Vj的邻居进行采样,然后为每个实体迭代地采样固定数量的邻居。它从H跳邻居开始,通过迭代地替换公式29中的k=H,H−1,···,1来更新内部实体的表示。
在聚合过程中,多跳邻居的信息可以向内传播到候选项主播。在该特征传播过程之后,项VJ的最终表示是其初始表示和来自多跳邻居的信息的混合。RippleNet和KGCN是两个类似的框架,前者通过向外传播用户的历史兴趣来建模用户,而后者向内学习来自遥远邻居的项目表示。此外,KGCN利用GCN的思想,通过采样固定数量的邻居作为接受域,使得学习过程高效和可扩展。最近,Wang et al.。[91]提出了一种后续方法KGCN-LS,在KGCN模型的基础上进一步增加了标签平滑(LS)机制。LS机制提取用户交互信息,在KG上传播用户交互标签,能够指导学习过程,获得候选项目主播的全面表示。
RippleNet及其扩展专注于在项KG上使用嵌入传播机制。最近,一些文献对用户-项目图中的传播机制进行了探讨。Wang等人。[90]提出了KGAT,通过嵌入传播直接对用户与物品之间的高阶关系进行建模。KGAT首先应用TransR来获取实体的初始表示。然后,它从实体本身向外运行实体传播。在向外传播过程中,来自实体EI的信息将与多跳邻居迭代交互。方程式29可以修改为
其中,Ei0表示实体的初始表示,而Eik包含来自k跳邻居的连接信息。这些H嵌入Eik与偏差聚集以形成最终的表示Ei∗。以此方式,用户表示和项表示都可以用对应的邻居来丰富。用户偏好通过ˆYu,v=e∗Tu e∗v建模,其中e∗u和e∗v分别表示用户u和项目v的最终表示
Qu等人的研究成果。[93]提出了KNI,它进一步考虑了项端邻居和用户端邻居之间的交互作用,使得用户嵌入和项目嵌入的精化过程不分离。赵等人。[94]提出了IntentGC,它利用图中丰富的与用户相关的行为来实现更好的推荐。他们还设计了一个速度更快的图卷积网络,以保证Intent GC的可扩展性。最近,Shae等人提出了一个新的观点。[96]提出了AKGE,它通过在用户-项目对的子图中传播信息来学习用户界面和候选项目VJ的表示。AKGE首先使用TransR对图中实体的嵌入进行预训练,然后根据路径中的两两距离对连接用户界面和主播的几条路径进行采样,形成用户界面和主播的子图。接下来,AKGE在该子图中使用基于注意力的GNN来传播来自邻居的信息,以获得该用户-项目对的最终表示。子图的构造过滤掉图中关联度较低的实体,便于挖掘高阶用户-项目关系进行推荐。
统一方法摘要Summary for Unified Methods。统一方法得益于KG的语义嵌入和语义路径模式。这些方法利用嵌入传播的思想来改进KG中具有多跳邻居的项或用户的表示。这些工作一般采用自然适合嵌入传播过程的基于GNN的体系结构,自2018年RippleNet[14]提出以来,这种方法一直是一个新的研究趋势。统一方法继承了基于路径的方法的可解释性。传播过程可以看作是在KG中发现用户的偏好模式,这类似于基于路径的方法中的连通性模式的发现。
4.4 总结(Summary)
基于嵌入的方法使用KGE方法对KG进行预处理,得到实体和关系的嵌入,并进一步集成到推荐框架中。然而,该方法忽略了图中信息丰富的连通性模式,很少有文献能够给出合理的推荐结果。基于路径的方法利用用户-项目图,通过预定义元路径或自动挖掘连接模式来发现项目的路径级相似性。基于路径的方法还可以为用户提供对结果的解释。最近的一个研究趋势是将基于嵌入的方法和基于路径的方法相结合,充分利用双方的信息。此外,统一的方法还具有解释推荐过程的能力。
5 基于知识图谱的推荐系统数据集(Datasets of Recommender Systems with Knowledge Graph)
除了准确性和可解释性的好处外,基于KG的推荐的另一个优点是,这种类型的辅助信息可以自然地结合到推荐系统中,用于不同的应用。为了显示KG作为辅助信息的有效性,基于KG的推荐系统在不同场景下的数据集上进行了评估。在本节中,我们根据数据集对这些工作进行了分类,并说明了这些场景之间的差异。这一部分的贡献是双重的。首先,我们概述了在各种情况下使用的数据集。其次,我们说明了如何为不同的推荐任务构建知识图。
这一部分可以帮助研究人员找到合适的数据集来测试他们的推荐系统。
我们根据表4中总结的数据集对基于KG的推荐系统进行分组。一般来说,这些工作可以分为七个应用场景,我们将说明不同的工作如何使用每个数据集构造KG。
电影Movie。在这项任务中,推荐系统需要根据过去观看的电影来推断用户的偏好。最常用的数据集有两个:MovieLens[110]和DoubanMovie。MovieLens维护着一组从MovieLens网站[111]收集的数据集,其中最常用的是三个具有不同评级编号的稳定基准数据集,MovieLens-100K、MovieLens-1M和MovieLens-20M。每个数据集都包含评分、电影的属性和标签。豆瓣电影是从中国流行的社交媒体网络豆瓣[112]上爬出来的。该数据集包括用户之间的社会关系以及用户和电影的属性。
有不同的方法来构建与电影相关的KG进行推荐。一些文献[2]、[14]、[44]、[45]、[69]、[70]、[73]、[88]、[89]、[91]、[92]、[93]、[95]构建了以电影为中心的项目图,通过从Satori、DBpedia、Freebase、CN-DBpedia或IMDB[113]中提取电影及其相关属性来丰富电影信息。通过这种方式,电影通过属性连接在一起,包括流派、国家、演员、导演等。该项目图用作辅助信息,以促进协作过滤模块。另一种方法是直接将用户的评分作为一种关系类型,并将用户引入图形。一些文献[1]、[79]、[82]直接利用MovieLens数据集或豆瓣电影数据集内的电影的交互数据和属性来构建用户项图,而另一些文献[66]、[75]、[76]、[77]、[80]、[81]、[83]、[86]、[87]、[96]仍然利用外部数据库来丰富电影端信息。
图书Book。图书推荐是另一个受欢迎的任务。有五个常用的数据集:Bookcross[114]、Amazon-Book[115]、DoubanBook、DBbook2014和Intent Books[116]。Book-Crossing、DBbook2014、Intent Books和Amazon-Book包含用户和图书之间的二进制反馈,每个数据集的KG是通过将图书映射到Satori[2]、[14]、[45]、[88]、[89]、[91]、[92]、[93]、[95]、DBpedia[70]、[87]或Freebase[44]、[90]、[93]中的相应实体来构建的。豆瓣图书数据集是从豆瓣[117]抓取的,其中包含用户-项目交互数据和图书属性,如有关作者、出版商和出版年份的信息。这项工作[82]通过利用DoubanBook数据集中的这一知识来构建用户-项目图,而不需要外部KG的帮助。
- 音乐Music。Last.fm[118]是最流行的音乐推荐数据集。该数据集包含关于用户及其来自Last.fm在线音乐系统[119]的音乐收听记录的信息。一些文献[44]、[45]、[89]、[90]、[91]通过从Freebase或Satori提取与音乐相关的子图来构造项目图。一些文献[87]、[96]利用来自Freebase或Satori的知识建立了用户-项目图,而本文[1]直接从Last.fm数据集建立了用户-项目图。另一个受欢迎的数据集是KKBox数据集,它是由WSDM杯2018挑战赛[120]发布的。该数据集包含用户-项交互数据和音乐描述。Paper[73]构建项目图,[83]从该数据集构建用户-项目图,而不利用任何外部数据库。
- 产品Product。产品推荐任务最常用的数据集是Amazon产品数据集[115]。此数据集包括多种类型的项目和用户信息,如交互记录、用户评论、产品类别、产品描述和用户行为。这些作品[3]、[13]、[67]、[85]、[94]仅使用该数据集构建用户-项目图,并且[84]通过使用外部Freebase数据库丰富项目信息来构建项目图。也有一些论文[74]、[94]使用了阿里巴巴淘宝提供的数据。
- 兴趣点Point of Interest (POI)。兴趣点(POI)推荐是对新业务和活动(餐馆、博物馆、公园、城市等)的推荐。基于他们的历史签到数据的用户。最流行的数据集是Yelp Challenger[121],它包含企业、用户、签到和评论的信息。这些论文[1]、[3]、[76]、[77]、[79]、[80]、[81]、[82]、[96]利用数据集中的签到、评论和属性数据构建了用户-项目图,而[90]构建了项目图。论文[71]利用CEM数据集1来推荐下一次旅行。另一项工作[91]使用了大众点评网[122]提供的大众点评-食物数据集来推荐餐厅。
- 新闻News。新闻推荐具有挑战性[48],因为新闻本身是时间敏感的,内容高度浓缩,这需要常识来理解。此外,人们在选择阅读新闻时对话题敏感,可能更喜欢来自不同领域的新闻。传统的新闻推荐模型无法发现新闻之间的高层次联系。因此,在该场景[14]、[45]、[48]、[88]中引入KGs,以发现不同新闻之间的逻辑关系,从而提高推荐的精确度。最流行的数据集是Bing-News,收集自Bing News[123]的服务器日志,其中包含用户点击信息、新闻标题等。要构建新闻推荐KG,第一步是提取标题中的实体。然后,通过提取这些实体在Satori中的邻域来构造子图。
社交平台Social Platform。此任务是向社区中的用户推荐可能感兴趣的人或会议。其中一个应用是利用收集的微博推文数据向用户推荐微博上未被关注的名人[124]。除了用户-项目图来表示用户和名人之间的情感链接外,还构建了一个包含从Satori中提取的知识的项目图,以丰富名人的信息。另一个应用是在社交网站Meetup[125]上向用户推荐离线会议,该网站的数据来自该平台。最后一个应用是在学术领域,利用DBLP数据向研究人员推荐会议[126]。
6 未来方向(Future Directions)
在上述部分中,我们从更准确的推荐和可解释性方面展示了基于KG的推荐系统的优势。虽然已经提出了许多新的模型来利用KG作为辅助信息来进行推荐,但仍然存在一些进一步的机会。在这一部分中,我们概述和讨论了一些前瞻性的研究方向。
动态推荐Dynamic Recommendation。尽管GNN或GCN结构的基于KG的推荐系统取得了较好的性能,但训练过程非常耗时。因此,这类模型可以看作是静态偏好推荐。然而,在一些场景中,例如在线购物、新闻推荐、Twitter和论坛,用户的兴趣可以很快受到社交事件或朋友的影响。在这种情况下,带有静态偏好建模的推荐可能不足以理解实时兴趣。为了捕捉动态偏好,利用动态图网络可以是一种解决方案。最近,Song et al.。[127]设计了一个动态图形注意网络,通过结合朋友的长期和短期兴趣来捕捉用户快速变化的兴趣。遵循这种方法,自然会整合其他类型的边信息,并构建用于动态推荐的KG。
- 多任务学习Multi-task Learning。基于KG的推荐系统可以自然地视为图中的链接预测。因此,考虑到KG的性质,有可能提高基于图的推荐的性能。例如,KG中可能存在缺失的事实,从而导致缺失的关系或实体。然而,用户的偏好可能会因为缺少这些事实而被忽略,这可能会恶化推荐结果。[70],[95]已经表明,联合培训KG完成模块和推荐模块是有效的,以便更好地进行推荐。其他工作已经利用了多任务学习,通过联合训练推荐模块与KGE任务[45]和项目关系调节任务[73]。利用从其他KG相关任务(如实体分类和解析)传输知识来获得更好的推荐性能将是有趣的。
- 跨域推荐Cross-Domain Recommendation。最近,关于跨域推荐的著作层出不穷。其动机是,交互数据在不同领域之间并不相等。例如,在亚马逊平台上,图书评分比其他领域更密集。通过迁移学习技术,可以共享来自数据相对丰富的源域的交互数据,以便在目标域中进行更好的推荐。张某等人。[128]提出了一种基于矩阵的跨域推荐方法。后来,赵等人提出了自己的观点。[129]引入PPGN,将来自不同领域的用户和产品放在一个图中,并利用用户项交互图进行跨域推荐。虽然PPGN的性能明显优于SOTA,但用户项图只包含交互关系,没有考虑用户和项之间的其他关系。通过将不同类型的用户和项目侧信息合并到用户-项目交互图中,以获得更好的跨域推荐性能,这可能是本调查中的后续工作。
- 知识增强语言表示Knowledge Enhanced Language Representation。为了提高各种自然语言处理任务的性能,将外部知识整合到语言表示模型中是一种趋势。知识表示和文本表示可以相互提炼。例如,Chen等人。[130]提出了短文本分类的STCKA算法,该算法利用KGS的先验知识,如YAGO等,丰富了短文本的语义表示。张某等人。[131]提出了Ernie,它融合了维基数据中的知识来增强语言表示,这种方法在关系分类任务中被证明是有效的。虽然DKN模型[48]同时利用了新闻中的文本嵌入和实体嵌入,但这两种嵌入只是简单地连接在一起来获得新闻的最终表示,而没有考虑两个向量之间的信息融合。因此,将知识增强的文本表示策略应用于新闻推荐任务和其他基于文本的推荐任务中,可以更好地进行表示学习,从而获得更准确的推荐结果。
- 知识图谱嵌入方式Knowledge Graph Embedding Method。根据约束条件的不同,KGE方法分为翻译距离模型和语义匹配模型。在本次调查中,这两种KGE方法被用于所有三种基于KG的推荐系统和推荐任务中。然而,没有全面的工作来建议在哪些情况下,包括数据源、推荐场景和模型体系结构,应该采用特定的KGE方法。因此,另一个研究方向在于比较不同KGE方法在不同条件下的优势。
- 用户辅助信息User Side Information。目前,大多数基于KG的推荐系统都是通过结合项目侧信息来构建推荐图的,而很少有模型考虑用户侧信息。然而,用户侧信息,如用户网络和用户的人口统计信息,也可以自然地集成到现有的基于KG的推荐系统的框架中。最近,Fan等人提出了自己的观点。[132]使用GNN分别表示用户-用户社交网络和用户-项目交互图,其性能优于传统的基于用户社交信息的CF推荐系统。我们最近在调查中的一篇论文[96]将用户关系整合到了图表中,并展示了这一策略的有效性。因此,在KG中考虑用户侧信息可能是另一个研究方向。
7 讨论(Conclusion)
在本文中,我们对基于KG的推荐系统进行了研究,并总结了该领域的最新研究成果。这项调查说明了不同的方法如何利用KG作为辅助信息来改进推荐结果,并在推荐过程中提供可解释性。此外,还对不同场景中使用的数据集进行了介绍。最后,对未来的研究方向进行了展望,希望能对该领域的发展起到推动作用。基于KG的推荐系统得益于KGS中包含的丰富信息,有望实现准确的推荐和可解释的推荐。我们希望这份调查报告能帮助读者更好地了解这方面的工作。

若有收获,就点个赞吧
0 人点赞
