- 摘要(Abstract)
- 1 引言(Introduction)
- 2 背景和分类(Backgrounds and Categorization)
- 3 用户-项目协同过滤(User-Item Collaborative Filtering)
- 4 序列推荐(Sequential Recommendation)
- 5 社交推荐(Social Recommendation)
- 6 基于知识图谱的推荐(Knowledge Graph Based Recommendation)
- 7 其他任务(Other Tasks)
- 8 数据集、评估指标和应用(Datasets, Evaluation Metrics and Applications)
- 9 未来研究方向和有待解决的问题(Future Research Directions and Open Issues)
- 9.1 多样化的用户表征(Diverse and Uncertain Representation)
- 9.2 GNN用于推荐系统的可扩展性和效率(Scalability of GNN in Recommendation)
- 9.3 推荐中的动态图上如何使用GNN技术(Dynamic Graphs in Recommendation)
- 9.4 推荐中GNN的接收域(Reception Field of GNN in Recommendation)
- 9.5 自监督学习(Self-supervised Learning)
- 9.6 基于GNN的推荐系统的鲁棒性(Robustness in GNN-based Recommendation)
- 9.7 隐私保护(Privacy Preserving)
- 9.8 公平性(Fairness in GNN-based Recommender System)
- 9.9 可解释性(Explainability)
- 10 结论(Conclusion)
Graph Neural Networks in Recommender Systems: A Survey
- Shiwen Wu, Fei Sun, Wentao Zhang, et al. Graph Neural Networks in Recommender Systems: A Survey[J]. In ACM Computing Surveys 2022.
- 北京大学、阿里巴巴
ACM Computing Surveys IF 10.282/Q1 小类学科:计算机:理论方法 1区
摘要(Abstract)
随着在线信息的爆炸性增长,推荐系统在缓解此类信息过载方面发挥了关键作用。由于推荐系统的重要应用价值,这一领域一直以来都有新兴的研究成果。在推荐系统中,主要的挑战是从他们的交互和辅助信息(如果有的话)中学习有效的用户/项目表示。近年来,图神经网络(GNN)技术在推荐系统中得到了广泛的应用,因为推荐系统中的大多数信息本质上都是图的结构,而图神经网络在图表示学习方面具有优势。本文旨在对基于GNN的推荐系统的最新研究成果进行全面的综述。具体地说,我们根据使用的信息类型和推荐任务提供了基于GNN的推荐模型的分类。此外,我们系统地分析了在不同类型的数据上应用GNN的挑战,并讨论了该领域现有的工作如何应对这些挑战。此外,我们对这一领域的发展提出了新的观点。我们收集了具有代表性的论文以及它们的开源实现[https://github.com/wusw14/GNN-in-RS](https://github.com/wusw14/GNN-in-RS)
1 引言(Introduction)
随着电子商务和社交媒体平台的快速发展,推荐系统已经成为许多商家不可或缺的工具[15、25、84、183、190、200]。根据行业的不同,它们可以被识别为各种形式,例如在线电子商务网站(例如亚马逊和淘宝)上的产品建议或视频和音乐服务的播放列表生成器(例如YouTube、Netflix和Spotify)。用户依赖推荐系统来缓解信息过载问题,并从海量的项目(例如产品、电影、新闻或餐馆)中探索他们感兴趣的内容。因此,根据用户的历史交互(例如,点击、观看、阅读和购买)准确地建模用户的偏好是有效推荐系统的核心。<br /> 总的来说,在过去的几十年里,推荐系统中的主流建模范式已经从邻域方法[6,60,95,123]演变为基于表示学习的框架[25,77,78,125,143]。基于条目的邻域方法[6,95,123]直接向用户推荐与他们交互过的历史条目相似的条目。在某种意义上,他们通过直接使用他们历史上相互作用的项目来代表用户的偏好。早期的基于项目的邻域方法因其简单、高效和有效而在实际应用中取得了巨大的成功。<br /> 另一种方法是基于表示学习的方法,该方法试图将用户和项目都编码为共享空间中的连续向量(即,嵌入),从而使它们直接可比较。自从Netflix奖竞赛[7]证明矩阵因式分解模型优于传统的邻域推荐方法以来,基于表示的模型引发了人们的兴趣激增。在此之后,已经提出了从矩阵分解[77,78]到深度学习模型[25,58,125,200]的各种方法来学习用户和项的表示。如今,深度学习模型已经成为学术研究和工业应用中推荐系统的主流方法,因为它能够有效地捕捉非线性和非平凡的用户-项目关系,并容易地整合大量的数据源,例如上下文、文本和视觉信息。<br /> 在所有的深度学习算法中,有一种是基于图学习的方法,它从图的角度来考虑推荐系统中的信息[151]。推荐系统中的大多数数据本质上都是一种图结构[8,190]。例如,推荐应用中的交互数据可以由用户和项目节点之间的二分图表示,观察到的交互由链接表示。甚至用户行为序列中的项目转换也可以被构建为图。当合并结构化的外部信息,例如用户之间的社会关系[33,172]和与项[146,196]相关的知识图时,将推荐表述为图表上的任务的好处变得特别明显。通过这种方式,图学习为推荐系统中丰富的异质数据建模提供了一个统一的视角。早期的基于图学习的推荐系统使用图嵌入技术来建模节点之间的关系,这些方法可以进一步分为基于因式分解的方法、基于分布式表示的方法和基于神经嵌入的方法[151]。受GNN在图结构数据上的优越学习能力的启发,近年来涌现了大量基于GNN的推荐模型。<br /> 然而,提供一个统一的框架来对推荐应用程序中的大量数据进行建模只是GNN在推荐系统中广泛采用的部分原因。另一个原因是,与传统的只隐式捕获协同信号(即使用用户-项目交互作为监督信号)不同,GNN可以自然地显式地编码关键的协同信号(即拓扑结构),以改善用户和项目的表示。事实上,在推荐系统中使用协作信号来改进表征学习并不是一个源于GNN[41,69,76,184,203]的新想法。早期的努力,如SVD++[76]和FISM[69],已经证明了交互项目在用户表征学习中的有效性。鉴于用户-项目交互图,这些前人的工作可以看作是使用一跳邻居来改进用户表征学习。GNN的优势在于它提供了强大的系统工具来探索多跳关系,这些关系已经被证明对推荐系统是有益的[55,155,190]。<br /> 凭借这些优势,GNN在过去几年中在推荐系统中取得了显著的成功。在学术研究中,大量工作表明,基于GNN的模型在公共基准数据集[55,155,210]上的性能优于以往的方法,并获得了最新的结果。同时,它们的许多变体被提出并应用于各种推荐任务,例如,基于会话的推荐[115,175],兴趣点(POI)推荐[10,92,177],组推荐[59,153],多媒体推荐[164,165]和捆绑推荐[11]。在工业上,GNN也被部署在网络规模的推荐系统中,以产生高质量的推荐结果[32,114,190]。例如,Pinterest在一个有30亿个节点和180亿条边的图上开发和部署了一个基于随机游走的图卷积网络(GCN)算法模型PinSage,并在在线A/B测试中获得了显著的用户参与度改进。<br /> **此调查与现有调查之间的差异Differences between this survey and existing ones**。现有的调查侧重于对推荐系统的不同观点[4、16、22、28、45、117、200]。然而,很少有全面的评论来定位现有的工作和当前在推荐系统中应用GNN的进展。例如,张等人。[200]和Batmaz等人。[4]侧重于推荐系统中的大多数深度学习技术,而忽略了GNN。Chen等人。[16]总结了推荐系统中的偏向问题的研究。郭某等人。[45]回顾基于知识图表的推荐,Wang等人。[150]在以届会为基础的建议中提出一项全面调查。这两部作品只包括了应用于相应子领域的GNN方法中的一部分,并考察了有限数量的作品。据我们所知,正式发表的最相关的调查是一篇简短的论文[151],它回顾了基于图学习的系统,并简要讨论了GNN在推荐中的应用。最近的一项调查[40]从推荐系统的四个角度,即阶段、场景、目标和应用,对基于GNN的推荐系统的现有工作进行了分类。这种分类侧重于推荐系统,但对GNN技术在推荐系统中的应用关注不够。此外,这份调查[40]很少讨论现有方法的优点和局限性。有一些关于GNN技术的全面调查[179,208],但他们只是粗略地讨论了推荐系统作为应用之一。<br /> 鉴于基于GNN的推荐模型正在以令人印象深刻的速度增长,我们认为在一个统一和可理解的框架中总结和描述所有具有代表性的方法是很重要的。本调查总结了基于GNN的推荐研究进展的文献,并讨论了该领域存在的问题和未来的发展方向。为此,本次调查对100多项研究进行了入围和分类。<br />** 本综述的贡献Contribution of this survey**。本次调查的目的是全面回顾基于GNN的推荐系统的研究进展,并讨论进一步的发展方向。对推荐系统感兴趣的研究人员和实践者可以对基于GNN的推荐领域的最新发展有一个大致的了解。这项调查的主要贡献概括如下:
新的分类New taxonomy。我们提出了一种系统的分类模式来组织现有的基于GNN的推荐模型。具体来说,我们根据所使用的信息类型和推荐任务将现有的工作分为五类:用户-项目协同过滤、顺序推荐、社交推荐、基于知识图的推荐,以及其他任务(包括POI推荐、多媒体推荐等)。
- 全面审查Comprehensive review。对于每一类,我们都演示了要处理的主要问题。此外,我们还介绍了具有代表性的模型,并说明了它们如何解决这些问题。
未来研究Future research。我们讨论了现有方法的局限性,并提出了九个潜在的未来发展方向。
本文的其余部分安排如下:第二节介绍了推荐系统和图神经网络的基本知识。然后,讨论了将GNN应用于推荐系统的动机,并对现有的基于GNN的推荐模型进行了分类。第3-7节总结了每类模型的主要问题以及现有工作如何应对这些挑战,并分析了它们的优势和局限性。第8节总结了主流基准数据集、广泛采用的评估指标和实际应用。第9节讨论了挑战,并指出了该领域的九个未来方向。最后,我们在第10节对调查进行了总结。
2 背景和分类(Backgrounds and Categorization)
在深入到这项调查的细节之前,我们对推荐系统和GNN技术进行了简要的介绍。我们还讨论了在推荐系统中使用GNN技术的动机。此外,我们还提出了一种新的分类方法来对现有的基于GNN的模型进行分类。在本文中,我们使用粗体大写字符来表示矩阵,粗体小写字符来表示向量,斜体粗体大写字符来表示集合,书法字体来表示图形。为便于阅读,我们在表1中总结了整篇论文中将使用的符号。<br />**表1 本文中使用的关键符号**<br />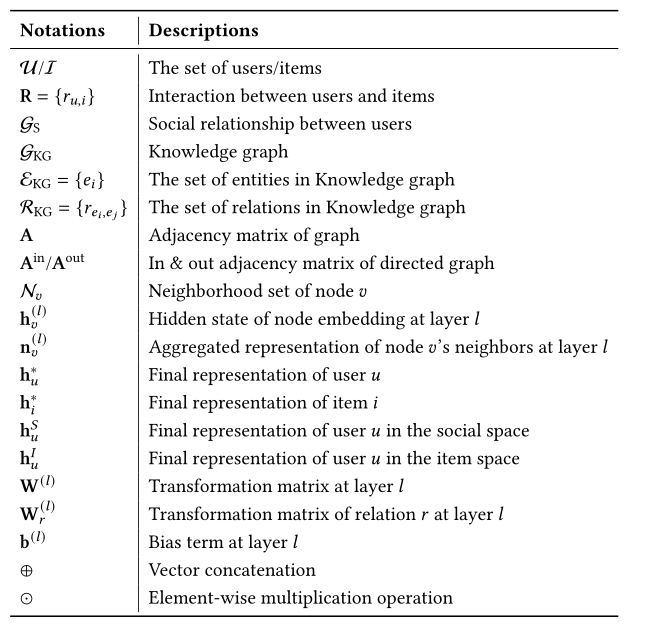
2.1 推荐系统(Recommender Systems)
推荐系统从用户-项目交互或静态特征中推断用户的偏好,并进一步推荐用户可能感兴趣的项目[1]。几十年来,它一直是一个热门的研究领域,因为它具有巨大的应用价值,但该领域的挑战仍然没有得到很好的解决。形式上,任务是通过学习的用户表示푖∈和项表示ℎ∗푢估计她/他对任何项ℎ∗푖i的偏好,即,<br />其中得分函数푓(·)可以是点积、余弦、多层感知等,푦푢,푖表示用户푢对项目푖的偏好得分,通常以概率表示。<br /> 根据用于学习用户/项目表示的信息的类型,推荐系统的研究通常可以分为特定类型的任务。用户-项目协同过滤推荐旨在通过仅利用用户-项目交互来捕捉协作信号,即,从成对数据[58、78、80、121、125、178]联合学习用户/项目表示。当用户的历史行为的时间戳已知或历史行为按时间顺序组织时,可以通过探索她/他的历史交互[53、61、70、85、97、119、131、136、150]中的顺序模式来增强用户表示。根据用户是否是匿名的、行为是否被分成会话,该领域的工作可以进一步分为顺序推荐和基于会话的推荐。基于会话的推荐可以被视为具有匿名和会话假设的顺序推荐的子类型[117]。在本调查中,我们没有区分它们,为简单起见将它们统称为更广泛的术语顺序建议,因为我们主要关注的是GNN对建议的贡献,而它们之间的差异对于GNN的应用来说可以忽略不计。除了顺序信息之外,另一个研究方向利用社会关系来增强用户表征,这被归类为社会推荐[43,65,103-105,138]。社交推荐假设拥有社会关系的用户倾向于具有相似的用户表征,这是基于社会影响理论,即联系的人会相互影响。除了用户表示的增强之外,很多人还试图利用知识图来增强项的表示,知识图通过属性来表达项之间的关系。这些工作通常被归类为基于知识图的推荐系统,它将项目之间的语义关系融入到协作信号中。
2.2 图神经网络技术(Graph Neural Network Techniques)
最近,基于GNN变体的系统在许多与图形数据相关的任务上表现出了突破性的性能,例如物理系统[5,122]、蛋白质结构[37]和知识图[49]。在这一部分中,我们首先介绍了图的定义,然后对现有的GNN技术进行了简要的总结。<br /> 图被表示为G=(V,E),其中V是节点集,E是边集。设푣푖∈V为节点,푒푖푗=(푣푖,푣푗)∈E为从푣푗指向푣푖的边。节点푣的邻域表示为N(푣)={푢∈V|(푣,푢)∈E})。一般而言,图表可以分为以下几类:<br />**有向/无向图Directed/Undirected Graph**。有向图是指所有边从一个节点指向另一个节点的图。无向图被认为是有向图的一种特殊情况,如果两个节点相连,则存在一对方向相反的边。<br />**同质/异质图Homogeneous/Heterogeneous Graph**。同质图由一种类型的结点和边组成,而异质图由多种类型的结点或边组成。<br />**超图Hypergraph**。超图是图的推广,其中一条边可以连接任意数量的顶点。<br /> 在给定图数据的情况下,GNN的主要思想是迭代地聚集来自邻居的特征信息,并在传播过程中将聚集的信息与当前中心节点表示相结合[179,208]。从网络结构的角度来看,GNN堆叠了多个传播层,由聚合和更新操作组成。传播的公式是<br />聚合Aggregation:<br />更新Update:<br />其中h(푙)푢表示节点푢在푙푡ℎ层的表示,聚合器푙和更新器푙分别表示푙푡ℎ层的聚合操作和更新操作的功能。在聚集步骤中,现有的工作要么用均值池操作来平等对待每个邻居[50,89],要么用注意机制来区分邻居的重要性[140]。在更新步骤中,中心节点的表示和聚集的邻域将被整合到中心节点的更新表示中。为了适应不同的场景,人们提出了各种策略来更好地整合这两种表示,如GRU机制[89]、级联与非线性变换[50]和求和运算[140]。要了解更多关于GNN技术的信息,请读者参考调查[179,208]。<br /> 在这里,我们简要总结了推荐领域广泛采用的五个典型GNN框架的聚合和更新操作。
GCN[73]逼近图的拉普拉斯的一阶特征分解,以迭代地聚集来自邻居的信息。具体地说,它通过以下方式更新嵌入
聚合Aggregation:
其中훿(·)是非线性激活函数,如ReLU,W(푙)是层的可学习变换矩阵,푙,˜푎푣푗是邻接权
- GraphSAGE[50]为每个节点采样固定大小的邻域,提出均值/和/最大池化聚合器,并采用拼接操作进行更新,
其中,聚合器푙表示푙푡ℎ层的聚合函数,훿(·)表示非线性激活函数,W(푙)表示可学习变换矩阵
- GAT[140]假设邻居的影响既不相同也不是图结构预先确定的,因此它通过利用注意力机制来区分邻居的贡献,并通过关注每个节点的邻居来更新其向量,
其中Att(·)是注意力函数,典型的Att(·)是LeakyReLU?A푇?w(푙)h(푙)푣⊕W(푙)h(푙)푗?,W(푙))负责在푙푡ℎ传播时变换节点表示,a是可学习参数。
- GGNN[89]在更新步骤中采用门控递归单元(GRU)[89],
GGNN在所有节点上多次执行递归函数[179],这在应用于大型图时可能会面临可伸缩性问题。
- HGNN[36]是一种典型的超图神经网络,它将高阶数据相关性编码在超图结构中。超边卷积层具有以下公式:
其中훿(·)是非线性激活函数,与RELU一样,W(푙)是层푙的可学习变换矩阵,E是超图邻接矩阵,D푒和D푣分别表示边度和顶点度的对角矩阵。
2.3 为什么用图神经网络进行推荐(Why Graph Neural Network for Recommendation)
在过去的几年里,已经提出了许多基于GNN的推荐工作。在深入研究最新发展的细节之前,了解将GNN应用于推荐系统的动机是有益的。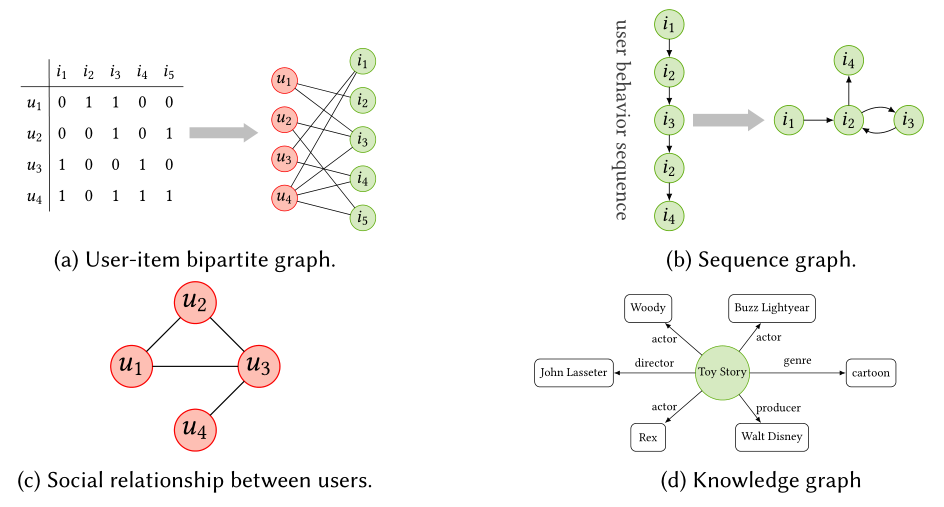
图1 推荐系统中的代表性图结构
最直观的原因是,GNN技术已经被证明在对不同领域的图形数据的表示学习方面是强大的[44,208],并且推荐中的大多数数据本质上具有图1所示的图结构。例如,用户-项交互数据可以由用户和项节点之间的二分图来表示(如图1a所示),其中链接表示相应用户和项之间的交互。此外,可以将一系列项目转换为序列图,其中每个项目可以与一个或多个后续项目相连接。图1b显示了序列图的一个例子,其中在连续的项之间有一条边。与原始序列数据相比,序列图可以更灵活地处理项与项之间的关系。除此之外,一些辅助信息还自然具有图形结构,如社会关系和知识图形,如图1C和1D所示。
由于不同类型数据在推荐中的具体特点,人们提出了各种模型来有效地学习它们的模式,以获得更好的推荐结果,这对模型设计是一个很大的挑战。从图表的角度考虑建议中的信息,可以利用统一的GNN框架来处理所有这些任务。例如,非顺序推荐的任务是学习有效的节点表示,即用户/项表示,并进一步预测用户偏好。序列推荐的任务是学习信息性的图表示,即序列表示。无论是节点表示还是图表示,都可以通过GNN学习。此外,与非图观点相比,加入附加信息(如果可用)更加方便和灵活。例如,社交网络可以作为统一的图被集成到用户-项目二方关系中。在迭代传播过程中,既可以捕获社会影响,也可以捕获协作信号。
此外,GNN可以对用户-项目交互的关键协作信号进行显式编码,从而通过传播过程增强用户/项目的表示。利用协作信号进行更好的表征学习并不是一个全新的想法。例如,SVD++[76]结合了交互项的表示以丰富用户表示。ItemRank[41]通过交互构建项-项图,并采用随机游走算法根据用户偏好对项进行排序。注意,SVD++可以被视为使用一跳邻居(即,项)来改进用户表示,而ItemRank利用两跳邻居来改进项表示。与非图模型相比,GNN更灵活、更方便地从用户-项目交互的角度来建模多跳连通性,并且捕获的高跳邻居的CF信号被证明是有效的推荐。
2.4 基于图神经网络的推荐分类(Categories of Graph Neural Network-Based Recommendation)
在这篇综述中,我们提出了一种新的分类方法来对现有的基于GNN的模型进行分类。根据使用的信息类型和推荐任务,现有的工作分为用户-项目协同过滤、顺序推荐、社交推荐、基于知识图的推荐和其他任务。除了前四类任务外,还有其他推荐任务,如POI推荐、多媒体推荐和捆绑推荐。由于在这些任务中利用GNN的研究并不是那么丰富,我们将它们归类为一类,并分别讨论它们的现状。
分类的基本原理如下:图表结构在很大程度上取决于信息的类型。例如,社交网络自然是同质图,用户-项目交互可以被认为是二部图或两个同质图(即,用户-用户和项目-项目图)。此外,信息类型在设计高效的GNN体系结构中也起着关键作用,如聚合和更新操作以及网络深度。例如,知识图具有多种类型的实体和关系,这就需要在传播过程中考虑这种异构性。此外,推荐任务与使用的信息类型高度相关。例如,社交推荐是利用社交网络信息进行推荐,基于知识图的推荐是通过利用知识图中项目之间的语义关系来增强项目表示。本调查主要面向对GNN在推荐系统中的开发感兴趣的读者。因此,我们的分类主要是从推荐系统的角度进行的,但也考虑了GNN。
3 用户-项目协同过滤(User-Item Collaborative Filtering)
在给定用户-项目交互数据的情况下,用户-项目协同过滤的基本思想实质上是使用用户交互的项目来增强用户表示,使用用户曾经与项目交互的用户来丰富项目表示。受到GNN技术在模拟信息扩散过程中的优势的启发,最近的努力研究了GNN方法的设计,以便更有效地利用用户-项目交互的高阶连通性。图2展示了将GNN应用于用户-项目交互信息的管道。
为了充分利用GNN方法从用户-项目交互中捕获协作信号,有四个主要问题需要处理:
图的构建Graph construction。图表结构对于信息传播的范围和类型是必不可少的。原始的二分图由一组用户/项目节点以及它们之间的交互组成。是将GNN应用于异质二部图,还是构建基于两跳邻居的同质图?考虑到计算效率,如何对图的代表性邻域进行采样而不是对整个图进行操作?
邻居聚合Neighbor Aggregation。如何聚合邻居节点的信息?具体地说,是区分邻居的重要性,还是对中心节点和邻居之间的亲和力进行建模,还是对邻居之间的交互进行建模?
信息更新Information Update。如何集成中心节点表示和相邻节点的聚合表示?
最终节点表示Final Node Representation。预测用户对项目的偏好需要整体的用户/项目表示。是使用最后一层中的节点表示还是所有层中的节点表示的组合作为最终的节点表示?
3.1 图的构建(Graph construction)
大多数作品[8,18,55,82,132,135,142,155,173,197,205]直接将GNN应用于原始用户项二部图。在原始图上直接应用GNN有两个问题:一个是原图结构可能不足以学习用户/项目表示的有效性;另一个是聚集所有节点邻域的信息需要很高的计算代价,特别是对于大规模图[190]。
解决第一个问题的一种策略是通过添加边来丰富原始的图结构,例如两跳邻居和超边之间的链接。例如,多GCCF[133]和DGCF[101]在原始图上的两跳邻居之间添加边,以获得用户-用户和项目-项目图。以此方式,用户和项目之间的接近信息可以被显式地合并到用户-项目交互中。为了捕捉显式混合高阶相关性,DHCF[66]引入了超边,并构造了用户/项目超图。另一种策略是引入虚拟节点来丰富用户与项目的交互。例如,DGCF[156]引入了虚拟意图节点,并将原始图分解为每个意图对应的子图,从不同的角度表示节点,具有更好的表达能力。HiGNN[91]通过对相似的用户/项目进行聚类,并将聚类的中心作为新的节点来创建新的粗化的用户-项目图,以显式地捕捉用户和项目之间的层次关系。
针对第二个问题,本文提出了抽样策略,使GNN具有更高的效率和可伸缩性,适用于大规模的基于图的推荐任务。PinSage[190]设计了一种基于随机游走的抽样方法,以获得访问次数最高的固定大小的社区。以这种方式,不直接与中心节点相邻的那些节点也可以成为其邻居。多GCCF[133]和NIA-GCN[132]随机抽样固定大小的邻居。采样是原始图形信息和计算效率之间的权衡。模型的性能取决于抽样策略,更有效的邻域建设抽样策略值得进一步研究。
3.2 邻居聚合(Neighbor aggregation)
聚集步骤对图结构的信息传播至关重要,它决定了邻居的信息应该传播多少。Mean-Pooling是最直接的聚合操作之一[8,133,135,197,198],它平等对待邻居,
Mean-Pooling很容易实现,但当邻居的重要性明显不同时,可能不合适。在传统的GCN的基础上,一些工作采用了“度归一化”[18,55,173],它根据图的结构为节点赋权,
由于采用随机游走抽样策略,PinSage[190]在聚合邻居的向量表示时,采用归一化访问计数作为邻居的重要性。然而,这些聚集函数根据图的结构来确定邻居的重要性,而忽略了相连节点之间的关系。
MCCF[158]和DisenHan[107]利用注意力机制来学习邻居[107,146]的权重,其动机是根据用户兴趣的项的嵌入应该更多地传递给用户(类似于项)。NGCF[155]使用基于元素的产品来增强用户关心的项目的特征或用户对该项目所具有的特征的偏好。以用户节点为例,聚合邻居表示的计算方法如下:
NIA-GCN[132]认为现有的聚集函数不能保持邻域内的关系信息,因此提出了两两邻域聚集方法来显式地捕捉邻域之间的交互。具体地说,它在每两个邻居之间应用元素相乘来建模用户-用户/项目-项目关系。
3.3 信息更新(Information update)
给定从其邻居那里聚集的信息,如何更新节点的表示是迭代信息传播的关键。根据是否保留节点本身的信息,现有的方法可以分为两个方向。一种是完全丢弃用户或项目节点的原始信息,而使用邻居的聚集表示作为新的中心节点表示[8,55,156,197],这可能会忽略固有的用户偏好或固有的项目属性。
另一种是同时考虑节点本身(h(푙)푢))及其邻域消息(n(푙)푢))来更新节点表示。最直接的方法是将这两种表示与总和合用或平均合用操作线性组合在一起[132,155,173,198]。受GraphSAGE[50]的启发,一些作品[82,133,190]采用了具有非线性变换的级联函数来整合这两个表示,如下所示:
其中휎表示激活功能,例如RELU、LeakyReLU和Sigmoid。与线性组合相比,级联运算和特征变换允许更复杂的特征交互。LightGCN[55]和LR-GCCF[18]观察到,非线性激活对整体性能的贡献很小,并且他们通过去除非线性来简化更新操作,从而保持甚至改善性能并提高计算效率。
3.4 最终节点表示(Final node representation)
逐层应用聚合和更新操作将为GNN的每个深度生成节点的表示。最终的预测任务需要用户和项的整体表示。
主流方法是使用最后一层中的节点向量作为最终表示,即h∗푢=h(퐿)푢[8,82,135,161,190,197]。然而,在不同层中获得的表示强调通过不同连接传递的消息[155]。具体地说,较低层的表示更多地反映单个要素,而较高层的表示更多地反映相邻要素。为了利用不同层次的输出所表达的联系,最近的研究使用了不同的方法来整合来自不同层次的信息。
其中훼(푙)是一个可学习的参数。请注意,均值合用和总和合用可以视为加权合用的两种特殊情况。与平均池和总和池相比,加权池允许更灵活地区分不同层的贡献。在这四种方法中,前三种方法都属于线性运算,只有拼接运算保留了所有层的信息。
3.5 总结(Summary)
与本节开头的讨论相对应,我们从四个问题简要总结现有工作:
图形构造Graph Construction。最直接的方法是直接使用原始的用户-项目二部图。如果一些节点在原始图中的邻居很少,则通过添加边或节点来丰富图的结构将是有益的。在处理大规模图时,为了提高计算效率,需要对邻域进行采样。抽样是有效性和效率之间的权衡,更有效的抽样策略值得进一步研究。
邻居聚合Neighbor Aggregation。当邻居的异质性较大时,聚集权重较等权和度归一化的邻居更好;否则,后两者更容易计算。明确建模邻居之间的影响或中心节点与邻居之间的亲和力可能会带来额外的好处,但需要在更多的数据集上进行验证。
信息更新Information Update。与丢弃原始节点相比,使用其原始表示和聚合邻居表示来更新节点将是优选的。最近的工作表明,通过去除变换和非线性运算来简化传统的GCN可以获得比原始GCN更好的性能。
最终节点表示Final Node Representation。为了获得整体用户/项表示,使用来自所有层的表示比直接使用最后一层表示更可取。在集成来自所有层的表示的功能方面,加权池化允许更多的灵活性,而拼接保留来自所有层的信息。
图3总结了每个主要问题的典型策略,并相应地列出了代表性作品。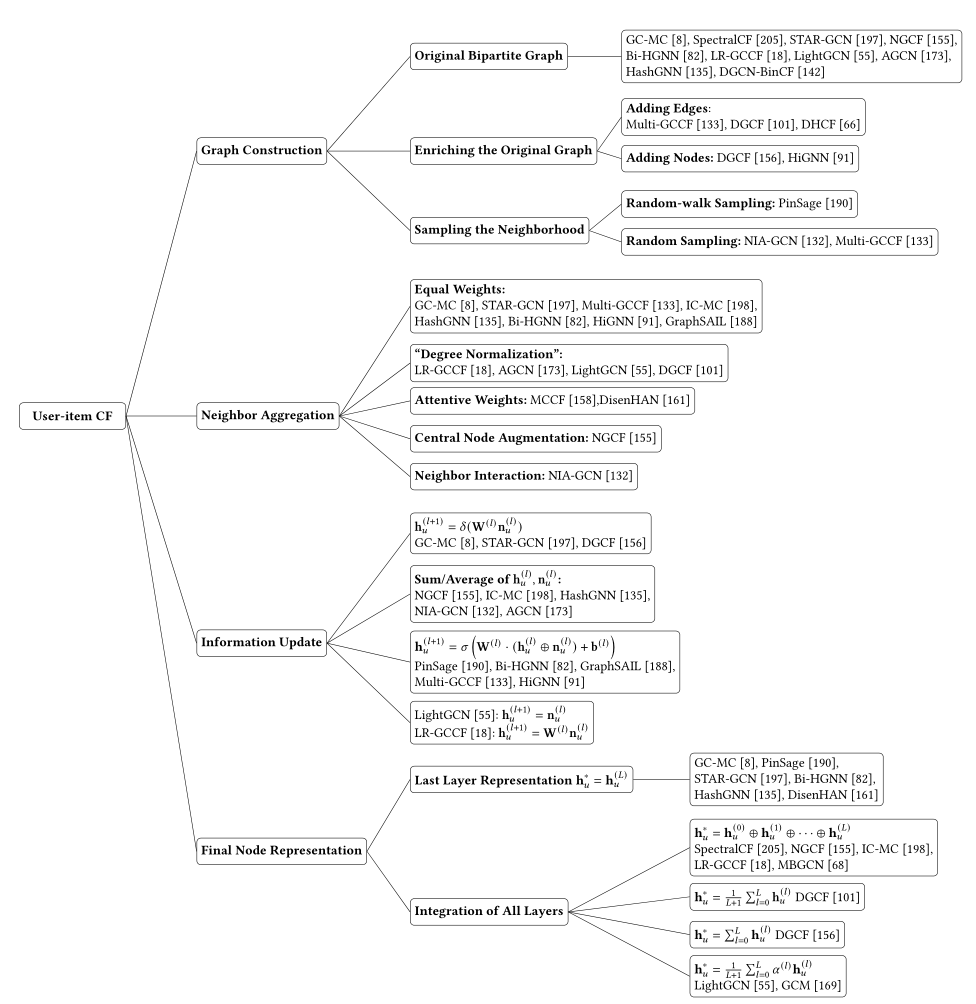
图3 用户项协同过滤领域的代表性研究成果综述。
4 序列推荐(Sequential Recommendation)
顺序推荐基于用户最近的活动来预测用户的下一个偏好,这寻求对连续项目之间的顺序模式进行建模,并为用户生成准确的推荐[117]。从项目间邻接关系的角度出发,项目序列可以建模为图结构的数据。受GNN优势的启发,利用GNN将用户的序列行为转化为序列图,从而获取用户序列行为的转换模式成为一种流行的方法。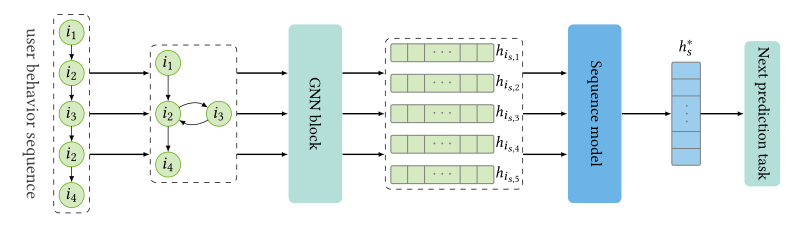
图4 按顺序推荐的GNN的总体框架。
图4说明了GNN按顺序推荐的总体框架。要在顺序建议中充分利用国民总收入,有三个主要问题需要处理:
图形构造Graph construction。为了将GNN应用于序列推荐,需要将序列数据转换为序列图。单独为每个序列构造一个子图是否足够?在几个连续的项目之间添加边是否比仅在两个连续的项目之间添加边更好?
信息传播Information propagation。要捕捉过渡模式,哪种传播机制更合适?是否有必要区分链接项的顺序?
序贯偏好Sequential preference。为了获得用户的时间偏好,应该对序列中的项目表示进行整合。是简单地应用专注池还是利用RNN结构来增强连续的时间模式?
4.1 图的构建(Graph construction)
与本质上具有二部图结构的用户-项交互不同,序列行为自然地以时间的顺序即序列来表示,而不是序列图。基于原始二部图构建图是可选的,主要受可伸缩性或异构性问题的驱动,而基于用户顺序行为的顺序图的构建是将GNN应用于顺序推荐的必要条件。图5显示了顺序行为的典型图形构建策略。
通过将序列中的每个项视为节点并在两个连续单击的项之间添加边来构建每个序列的有向图是最直接的方法[48,115,116,175,185]。然而,在大多数情况下,用户序列的长度很短,例如,经过预处理的YooChoose1/41数据集的平均长度为5.71[175]。由单个短序列构建的序列图由少量的节点和连接组成,有些节点甚至可能只有一个邻居,其包含的知识太有限,不能反映用户的动态偏好,不能充分利用GNN在图学习中的优势。为了应对这一挑战,最近的工作提出了几种策略来丰富原始的序列图结构,这些策略可以分为两个主流。
一种主流是利用额外的序列来丰富项到项的转换。附加序列可以是其他类型的行为序列[152]、同一用户的历史序列[176]、或整个数据集中的部分/全部序列[14、163、206、207]。例如,HetGNN[152]利用所有行为序列,在同一序列中的两个连续项之间构造边,并将其行为类型作为边类型。A-PGNN[176]处理已知用户的情况,从而将用户的历史序列与当前序列相结合以丰富项-项连接。GCE-GNN[163]和DAT-MDI[14]利用所有会话中的项转换来帮助当前序列中的转换模式,这利用了局部上下文和全局上下文。与GCE-GNN[163]和DAT-MDI[14]一视同仁地对待所有转变不同,TASRec[207]更重视最近的转变,以增强较新的转变。DGTN[206]没有合并所有会话,而是仅将类似的会话添加到当前会话,基于相似的序列更可能反映相似的转换模式的假设。所有这些方法都在原始图中引入了更多的信息,与单一的序列图相比,提高了性能。
另一种主流方法是调整当前序列的图形结构。例如,假设当前节点对多个连续项具有直接影响,MA-GNN[102]提取三个后续项并在它们之间添加边。考虑到只在连续项之间添加边可能会忽略距离较远的项之间的关系,SGNN-HN[113]引入了一个虚拟的星形节点作为序列的中心,该节点与当前序列中的所有项相关联。星形节点的向量表示反映了整个序列的整体特征。因此,每个项目都可以获得一些关于项目的知识,而不是通过“星形”节点进行直接连接。Chen和Wong[19]指出,现有的图构造方法忽略了邻域的顺序信息,导致了低效的长期捕获问题。因此,他们提出了LESSR,它从一个序列构造两个图:一个区分邻居的顺序,另一个允许从项目到它后面的所有项目的最短路径。
除了上述两种主流方法外,最近还出现了其他的图形构造方法。受超图在建模超配对关系方面的优势的启发,超图被用来捕捉项目之间的高阶关系和跨会话信息。Share[148]为每个会话构造一个超图,其中的超边由不同大小的滑动窗口定义。DHCN[182]将每个会话视为一条超边,并将所有会话集成到一个超图中。为了显式地合并跨会话关系,DHCN[182]和COTREC[181]构建了会话到会话图,该图将每个会话作为一个节点,并基于共享项来分配权重。
4.2 信息传播(Information propagation)
在给定已建立的序列图的情况下,设计一种有效的传播机制来捕获项目之间的转换模式是至关重要的。GGNN框架被广泛应用于有向图上的信息传播。具体地说,它采用均值池化的方法分别聚合前一项和下一项的信息,将两种聚合表示结合在一起,并利用GRU[89]组件整合邻居节点和中心节点的信息。传播函数如下所示:
其中,N in푖푠,푡,N out푖푠,푡表示前一项和下一项的邻域集,gru(·)表示gru分量。与池操作不同,GRU中的门机制决定了哪些信息应该保留和丢弃。不同于GGNN对邻居一视同仁,注意力机制也被用来区分邻居的重要性[12,115,163]。上述方法在消息传递过程中都采用了排列不变的聚集函数,忽略了邻域内项的顺序,这可能会导致信息的丢失[19]。为了解决这个问题,LESSR[19]保留了图结构中项目的顺序,并利用GRU组件[89]按顺序聚合邻居,如下所示:
对于具有超图结构的序列图,DHCN[182]采用典型的超图神经网络HGNN[36],在传播过程中对节点一视同仁。为了区分同一超边内项目的重要性,Share[148]设计了两种注意力机制来传播项目节点的信息。一个是超边,另一个是连接的项目节点的超边的信息。对于用户感知的序贯推荐,A-PGNN[176]和GAGA[116]隐含地融合了用户信息,并用用户表示扩充了邻域中项的表示。
4.3 序列偏好(Sequential preference)
由于传播的迭代有限,GNN不能有效地捕获项之间的长范围依赖关系[19]。因此,序列中最后一项(或任何项)的表示不足以反映用户的顺序偏好。此外,大多数将序列转换为图的图构造方法丢失了部分序列信息[19]。为了获得有效的序列表示,已有的工作提出了几种策略来整合序列中的项表示。
考虑到序列中的项目具有不同的优先级,因此广泛采用注意机制进行整合。一些工作[113,116,175,206]计算序列中最后一项和所有项之间的关注度权重,并将项表征聚合为全局偏好,并将其与局部偏好(即,最后一项表征)合并为整体偏好。这样,总体偏好在很大程度上依赖于最后一项与用户偏好的相关性。受多层自我注意策略在序列建模中的优越性的启发,GC-SAN[185]在GNN生成的项表示的顶部堆叠了多个自我关注层,以捕捉长范围依赖关系。
除了利用注意机制进行序列整合外,序列信号还被明确地整合到整合过程中。例如,Niser[48]和GCE-GNN[163]添加了反映项的相对顺序的位置嵌入,以有效地获得位置感知的项表示。为了平衡连续时间和灵活的转换模式,FGNN[115]使用带注意力的GRU机制来迭代地用序列中的项目表示来更新用户偏好。
所有上述工作都将项目表征整合到用户的行为序列中,以生成顺序偏好的表征。除了这些方法外,DHCN[182]和COTREC[181]在图的构造步骤中通过会话到会话图丰富了序列图。因此,它们将从会话到会话图中学习的顺序表示和在此步骤中从项聚集的顺序表示结合在一起。
4.4 总结(Summary)
这一部分主要从三个方面对评介作品进行了简要的总结。
图形构造Graph Construction。最简单的构造是在两个连续的项目之间添加边。当序列长度较短时,利用附加序列可以丰富序列图,如果附加序列与原始序列更相似,则更可取。另一行是调整行为序列的图形结构。关于哪种方法更好,目前还没有得到认可的说法。此外,将会话到会话图结合到序列图中也可以获得进一步的改进。
信息传播Information Propagation。大多数传播方法都是传统GNN框架中传播方法的变体,对于哪种方法更好还没有达成共识。一些复杂的传播方法,如LESSR[19],以更多的计算量为代价获得了性能上的提高。在实际应用中,是否采用复杂传播方法取决于在计算成本和性能收益之间的权衡。
序贯偏好Sequential Preference。为了获得序列偏好,人们广泛采用注意机制来整合序列中项目的表征。除此之外,添加位置嵌入可以增强项目的相对顺序,并可以带来一些改进。利用RNN结构是否可以提高所有顺序推荐任务的性能,还需要进一步的研究。
图6总结了每个主要问题的典型策略,并相应地列出了代表性作品。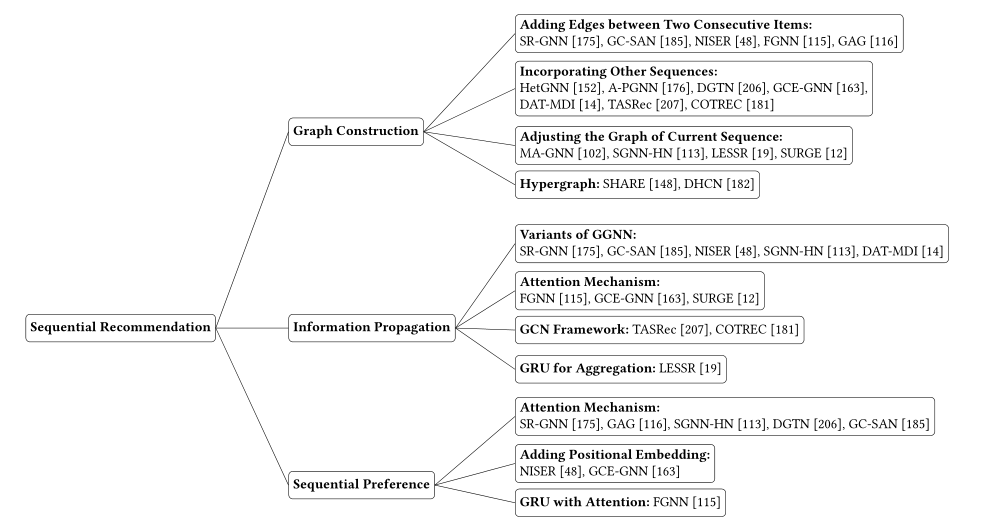
图6 按顺序推荐的代表性作品摘要。
5 社交推荐(Social Recommendation)
5.1 朋友的影响(Influence of friends)
5.2 偏好聚合(Preference Integration)
5.3 总结(Summary)
6 基于知识图谱的推荐(Knowledge Graph Based Recommendation)
利用反映用户之间关系的社会网络来增强用户表示,而利用通过属性来表达项之间关系的知识图来增强项表示。将知识图引入推荐可以带来两个方面的好处[144]:(1)知识图中条目之间丰富的语义关系有助于挖掘它们之间的联系,改善条目表示;(2)知识图连接用户历史上交互过的条目和推荐条目,从而增强结果的可解释性[189]。
尽管有上述优点,但由于其复杂的图结构,即多类型实体和多类型关系,在推荐中利用知识图是相当具有挑战性的。以前的工作是通过知识图嵌入(KGE)方法对知识图进行预处理,以学习实体和关系的嵌入,如[26,146,196,202]。常用的KGE方法的局限性是,它们侧重于建模带有变迁约束的严格语义关联,更适合于与图相关的任务,如链接预测而不是推荐[145]。基于元路径的方法手动定义携带高阶信息的元路径,并将它们馈送到预测模型中,因此它们需要领域知识,并且对于复杂的知识图来说是相当劳动密集型的[147,154]。
在给定用户-项目交互信息和知识图的情况下,基于知识图的推荐试图充分利用知识图中丰富的信息,通过显式捕获项目之间的关联度来帮助估计用户对项目的偏好。对于基于知识图的推荐的有效性,有两个主要问题需要处理:
图形构造Graph construction。如何有效地集成来自用户-项目交互的协同信号和来自知识图的语义信息?是显式地将用户节点合并到知识图中,还是隐式地使用用户节点来区分不同关系的重要性?
关系感知聚合Relation-aware Aggregation。知识图的一个特征是它具有实体之间的多种类型的关系。如何设计一个关系感知的聚合函数来聚合来自链接实体的信息?
6.1 图的构建(Graph construction)
对于图形构建阶段,如何有效地集成协同信号和知识信息是一个主要的关注点。
一个方向是将用户节点合并到知识图中。例如,KGAT[154]、MKGAT[134]和CKAN[162]将用户-项二部图和知识图合并为一个统一的图,将用户节点视为一种实体,将用户与项之间的关系视为“交互\”。最近的努力集中在与用户-项目对相关的实体和关系上。因此,他们构造了将用户-项对与用户的历史交互项以及知识图[35,127]中的相关语义链接起来的子图。基于两个节点之间的路径越短反映连接越可靠的假设,AKGE通过以下步骤构建子图:通过TransR[93]预先训练实体在知识图中的嵌入;计算两个链接实体之间的成对欧几里德距离;保持目标用户到项目节点之间距离最短的퐾路径。潜在的限制是子图的结构依赖于预先训练的实体嵌入和距离度量的定义。ATBRG[35]穷举地在多层实体邻居中搜索目标项和用户历史行为中的项,并通过多个重叠实体恢复连接用户行为和目标项的路径。为了突出信息密集型实体,ATBRG进一步使用单一链接对实体进行修剪,这也有助于控制图形的规模。虽然这些方法可以得到与用户-项目对更相关的子图,但对嵌入的实体进行预训练或穷举地搜索和剪枝路径是相当耗时的。一种有效、高效的子图构造策略值得进一步研究。
另一个方向是隐式使用用户节点来区分不同关系的重要性。例如,KGCN[147]和KGNN-LS[145]将用户节点作为查询来为不同的关系赋权。在图形构建方面,这一研究路线强调用户对关系的偏好,而不是用户-项目交互中的协作信号。
6.2 关系感知聚合(Relation-aware Aggregation)
为了充分捕捉知识图中的语义信息,在传播过程中既要考虑链接实体(即푒푖,푒푗),又要考虑它们之间的关系(即푟푒푖,푒푗)。此外,从推荐系统的角度来看,用户的角色也可能会产生影响。由于遗传算法在基于连通节点自适应赋权方面的优势,已有的工作大多将传统遗传算法的变体应用于知识图,即通过链接实体的加权平均来更新中心节点,并根据得分函数来分配权重,记为푎(푒푖,푒푗,푟푒푖,푒푗,푢)。关键挑战是设计一个合理有效的得分函数。
对于将用户节点视为一类实体的作品[35,134,154],在传播过程中,用户的偏好被期望溢出到知识图中的实体,因为条目节点将使用交互用户的信息和相关属性来更新,而其他实体则以迭代扩散的方式包含用户的偏好。因此,这些工作没有明确地建模用户对关系的兴趣,而是区分了连接的节点及其关系对实体的影响。例如,受知识图中变迁关系的启发,KGAT[154]根据关系空间中链接实体之间的距离来赋权,
其中W푟是关系的转换矩阵,它将实体映射到关系空间。这样,较近的实体将向中心节点传递更多信息。这些方法更适合于构建的包含用户节点的子图,因为用户的兴趣很难通过堆叠有限数量的GNN层来扩展到所有相关实体。对于没有将这两个图源结合起来的工作,这些研究[145,147]通过根据连接关系和特定用户分配权重来明确地刻画用户对关系的兴趣。例如,KGCN[147]采用的得分函数是用户嵌入和关系嵌入的点积,即,
这样,关系与用户兴趣更一致的实体就会将更多的信息传播到中心节点。
6.3 总结(Summary)
与本节开头的讨论相对应,我们从两个问题简要总结当前的工作:
图形构造。已有的工作要么将用户节点视为一种实体类型,要么隐含地使用用户节点来区分关系。第一个方向可以进一步分为用户-项目对的整体统一图或特定子图。与整体统一图相比,用户-项子图具有关注更多相关实体和关系的优点,但需要更多的计算时间,性能取决于子图的构造,这还需要进一步研究。
关系感知聚合。考虑到这些关系,GAT的变种被广泛地用来汇总来自相关联实体的信息。对于没有明确合并用户节点的图,使用用户表示来为关系分配权重。
图9总结了每个主要问题的典型策略,并相应地列出了代表性作品。
7 其他任务(Other Tasks)
除了这四种类型的任务外,研究人员还开始利用GNN来提高其他推荐任务的性能,如POI推荐和多媒体推荐。在这一部分,我们将分别总结每项任务的最新发展。
兴趣点推荐(Points-of-interest (POI) recommendation)在基于位置的服务中起着关键作用,它利用地理信息来捕捉兴趣点之间的地理影响,并利用用户的历史签到来建模转换模式。在POI推荐领域,有几种图形数据,如用户-POI二部图、基于签到的序列图和地理图,即一定距离内的POI被连接,边权重取决于POI之间的距离[10,92]。SGRec[88]使用属于其他检入的相关POI来丰富检入序列,这允许协作信号跨序列传播。Chang等人。[10]认为用户连续访问两个POI的次数越多,这两个POI之间的地理影响力就越大。因此,签到不仅反映了用户的动态偏好,还表明了POI之间的地理影响。为了显式地包含POI之间的地理分布信息,序列图中的边权重取决于POI之间的距离[10]。
组推荐(Group recommendation)旨在根据用户的历史行为向一组用户推荐项目,而不是向单个用户推荐项目[59]。存在三种类型的关系:用户-项目,每个用户与多个项目交互;用户-组,由多个用户组成的组;以及组-项目,一组用户都选择相同的项目。“群”可以看作是连接用户和群推荐中条目的桥梁,它既可以被视为图形的一部分,也可以不被视为图形的一部分。以下是分别对应于这两种策略的两部代表作。游戏[59]在图中引入了“组节点”,并应用GAT来为每个交互的邻居分配适当的权重。通过传播扩散,组表示可以随着交互的项目和用户迭代地更新。然而,这种方法不能直接应用于组动态变化和不断形成新组的任务。与以往的换能式方法不同,GLS-GRL[153]以归纳的方式学习群的表示,具体地为每个群构造对应的图。群表示是通过整合群中所涉及的用户表示来生成的,可以解决新的群问题。
捆绑推荐(Bundle recommendation)旨在将一组商品作为一个整体推荐给用户。有三种类型的关系:用户-项目,每个用户与几个项目交互;用户-捆绑,用户选择捆绑;捆绑-项目,捆绑由几个项目组成。对于分组推荐,“group”是由用户组成的;对于捆绑推荐,“group”是指一组条目。类似地,关键挑战是获得包表示。BGCN[11]将这三种关系统一到一个图中,并从用户的角度设计了项级和捆绑级传播。HFGN[87]认为捆绑包是用户通过捆绑包与物品交互的桥梁。相应地,它在用户-捆绑包交互和捆绑项映射上构建了层次结构,并进一步捕获捆绑包中的项-项交互。
点击率(CTR)预测(Click-through rate (CTR) prediction)是大规模工业应用中推荐系统的一项基本任务,它基于多类型特征预测点击率。CTR的关键挑战是对功能交互进行建模并捕获用户兴趣。受GNN信息扩散过程的启发,最近的工作Fi-GNN[90]利用GNN来捕捉特征之间的高阶相互作用。具体地说,它构造了一个特征图,其中每个节点对应一个特征字段,不同的字段通过边相互连接。因此,功能交互的任务被转换为在图中传播节点信息。
尽管Fi-GNN具有相当高的性能,但它忽略了用户行为中隐含的协作信号。DG-ENN[46]设计了属性图和用户-项目协同图,并利用GNN技术捕捉高阶特征交互和协同信号。为了进一步缓解用户-项目交互的稀疏性问题,DG-ENN使用用户-用户相似度关系和项目-项目变迁来丰富原有的用户-项目交互关系。
多媒体推荐(Multimedia Recommendation)已经成为帮助用户识别感兴趣的多媒体内容的核心服务。其主要特点是内容是多模式的,例如文本、图像和视频。近年来,研究人员开始采用GNN来捕捉用户与多模式内容交互时的协同信号。例如,MMGCN[165]为每个通道构建用户-项二部图,并分别应用GNN来传播每个图的信息。总体用户/项表示是不同形态的用户/项表示的总和。GRCN[164]利用多模式内容来改进用户-项目交互的连接性。对于每个传播层,GRCN将不同通道中用户-项目相似度的最大值作为用户-项目交互边的权重,并使用相应的权重来聚合邻居。MKGAT[134]将用户节点和多通道知识图统一为一个图,并使用关系感知图关注网络来传播信息。考虑到实体的多峰特性,MKGAT设计了实体编码器,将每种特定的数据类型映射成一个压缩向量。
8 数据集、评估指标和应用(Datasets, Evaluation Metrics and Applications)
在这一部分中,我们介绍了不同推荐任务常用的数据集和评价指标,并总结了基于GNN的推荐的实际应用。这一部分可以帮助研究人员找到合适的数据集和评估指标来测试他们的方法,并概述基于GNN的推荐的实际应用。
8.1 数据集(Datasets)
这部分介绍了基于GNN的推荐系统常用的公共数据集,如表2所示。由于页数的限制,我们没有列出其他推荐任务使用的数据集,我们建议读者参考已发表的作品。
表2 基于GNN的推荐任务的数据集。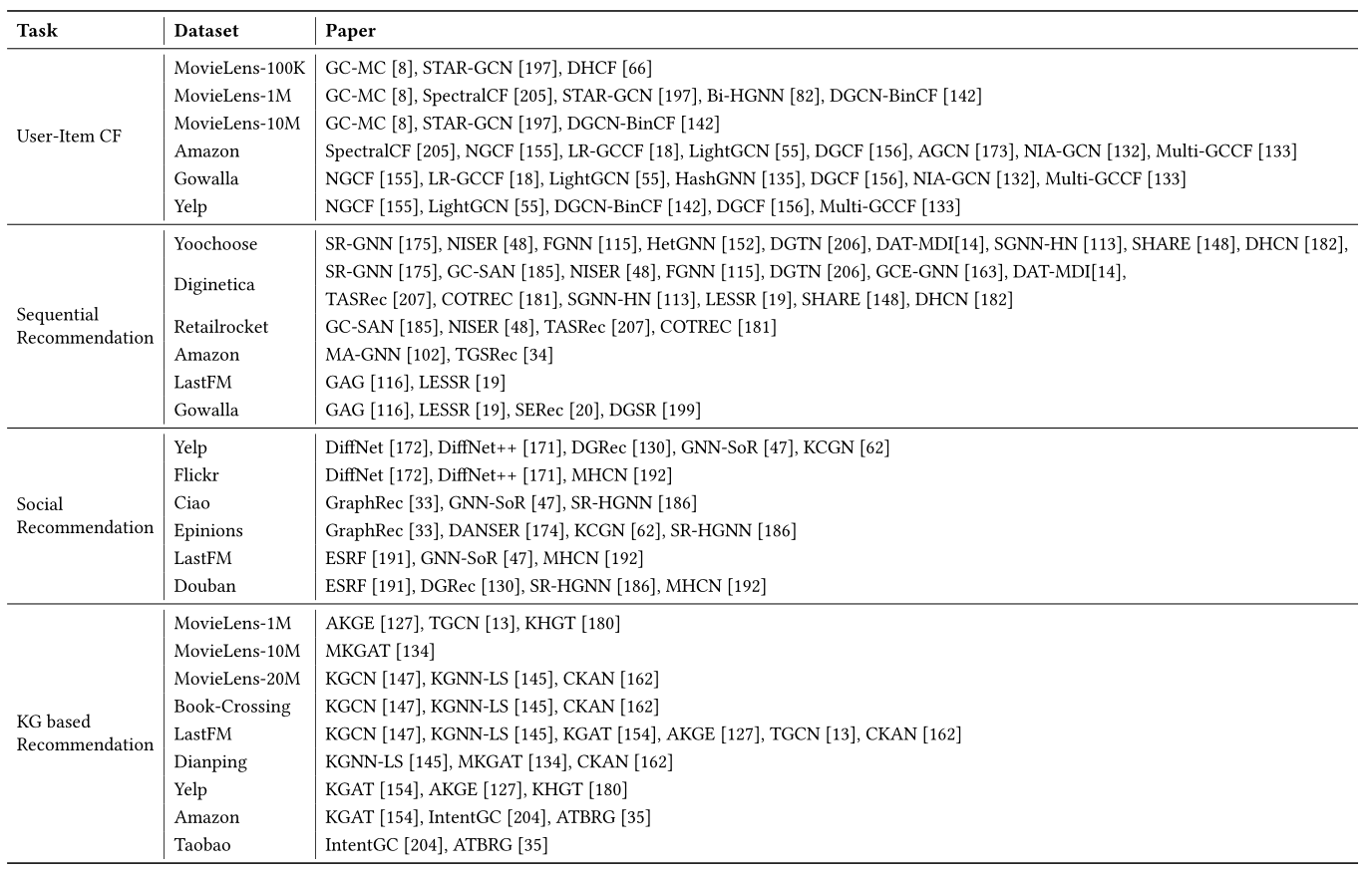
MovieLens2数据集来自MovieLens网站,其中最常用的是三个稳定的基准数据集,即MovieLens-100K、MovieLens-1M和MovieLens-20M。每个数据集都包含带有时间戳的用户-项目评分对、电影的属性和标签以及用户人口统计特征。评分范围从1到5,最小区间为1。MovieLens数据集被广泛用作用户项目协同过滤任务和基于知识图的推荐的基准数据集。
Amazon3数据集包括评论(评级、文本、帮助投票)、产品元数据(描述、类别信息、价格、品牌和图像特征)和链接(还查看/也购买了图表)[52]。整个数据集按类别划分为子数据集,例如亚马逊图书、亚马逊即时视频和亚马逊电子。亚马逊的子数据集通常被用来测试用户项协同过滤和顺序推荐的性能。
Yelp 4数据集包含用户签到,并且仍在更新中。Yelp数据集被广泛应用于用户-项目协同过滤和POI推荐任务中。现有的工作通常选择一年的数据进行实验,例如,NGCF[155]使用的是2018年版的Yelp数据集。
Gowalla5数据集是从Gowalla获得的签到数据集,其中用户通过签入来共享他们的位置[23]。除了签到信息,Gowalla数据集还包含用户之间的社会关系。Gowalla是POI推荐的经典数据集,也被用于用户-项目协同过滤和顺序推荐。
YooChoose6数据集来自RecSys Challest 2015,其中包含6个月内用户在电子商务网站上的点击流。大多数最近的研究使用序列中最新的1/64和1/4的片段作为实验数据集,分别命名为YooChoose1/64和YooChoose1/4,而不是整个数据集。
Diginetica7由2016年CIKM杯提供,其中包含按时间顺序排列的交易数据。Diginetica是一种常用的基于会话的推荐方法。
RetailRocket8数据集是从一个真实的电子商务网站收集的,该网站包含了六个月的用户浏览活动。
LastFM9数据集包含来自2000名用户的音乐家收听信息和来自Last.fm10在线音乐系统[81]的艺术家的属性。该数据集被序列推荐、社会推荐和基于知识图的推荐广泛采用。
Epinions数据集和Ciao数据集由Tang等人共享。[137][老外谈]。每个数据集包含用户的评分(从1到5)、对项目的评论以及用户之间的直接信任关系。这两个数据集已被广泛用作社交推荐的基准。
图书交叉11数据集包含图书的100万个评级(从0到10)以及图书在图书交叉社区中的属性(例如,标题、作者)。该数据集被广泛用作基于知识图的推荐的基准。
8.2 评估指标(Evaluation Metrics)
选择合适的度量来评估比较方法的性能是至关重要的。表3总结了不同推荐任务采用的评估指标。
表3 基于GNN的推荐任务评价指标。
HR衡量至少一次点击推荐项目的用户比例,即,
其中,푇(푢)表示基本事实项集,푅퐾(푢)表示TOP-K推荐项集,퐼(·)表示指示函数。
精确度、召回率和F1被广泛用于评估TOP-K推荐的准确性。Precision@K衡量用户将在推荐的K个项目中点击的项目的比例。Recall@K衡量推荐的K个项目中的用户点击次数占整个点击集的比例。F1@K是Precision@K和Recall@K的组合。
整体度量是所有用户的平均值,例如,Precision@퐾=1|U|Σ푢∈U Precision@퐾(푢)。
NDCG根据它们的排名位置来区分准确推荐的项目的贡献。
MAP是一种被广泛采用的排名指标,它衡量用户的平均精度,
AUC是模型对已点击项目的排名高于未点击项目的概率。当隐式反馈估计被认为是一个二分类问题时,AUC被广泛地用来评估性能
总体AUC是所有用户的平均值。
8.3 应用(Applications)
在这一部分中,我们根据业界已有的工作,总结了基于GNN的推荐模型在现实世界中的应用。
电子商务平台上的产品(广告)推荐是最常见的应用场景之一[35、82、87、135、180、204]。例如,IntentGC[204]通过图卷积网络利用用户-项目交互中的显性偏好和知识图中的异质关系,并部署在阿里巴巴平台上向用户推荐产品。另一个应用是内容推荐,它向用户推荐新闻、文章。例如,吴等人。[174]通过利用用户与文章的互动和社会关系,在真实的文章推荐系统微信Top Story上部署Danser。应用推荐还尝试利用基于GNN的模型,例如,GraphSAIL被部署在主流应用商店的推荐系统中,其从通用集合中为每个用户选择数百个应用[188]。此外,Ying et al.。[190]在Pinterest部署PinSage,它可以生成比同类深度学习和基于图形的替代方案更高质量的图像推荐。
9 未来研究方向和有待解决的问题(Future Research Directions and Open Issues)
虽然GNN在推荐系统方面取得了巨大的成功,但本节概述了几个有前景的研究方向。
9.1 多样化的用户表征(Diverse and Uncertain Representation)
除了数据类型的异构性(例如,像User和Item这样的节点类型,以及像不同行为类型这样的边类型),图中的用户通常还具有不同和不确定的兴趣[21,79]。将每个用户表示为一个单一的向量(低维向量空间中的一个点),很难捕捉到用户兴趣的这种特征。因此,如何表示用户的多重和不确定的兴趣是一个值得探索的方向。
自然的选择是利用各种方法[99,100,166],例如解缠表示学习[106,107]或胶囊网络[83],将这种单一向量扩展到多个向量。一些基于GNN的推荐工作也开始用多个向量来表示用户。例如,DGCF[156]显式地为多方面表示添加了正交约束,并分别迭代地更新每个方面的链接节点之间的相邻关系。面向推荐的多向量表示的研究还处于起步阶段,尤其是基于GNN的推荐模型,如何理清与用户意图相关的嵌入内容;如何自适应地为每个用户设置不同的兴趣值;如何设计高效的多向量表示传播模式等问题有待于进一步研究。
另一个可行的解决方案是将每个用户表示为密度而不是向量。将数据表示为密度(通常为多维高斯分布)提供了许多优点,例如,更好地对表示及其关系的不确定性进行编码,并且比点积、余弦相似性或欧几里德距离更自然地表示不对称性。具体地说,高斯嵌入已被广泛用于对各个领域中的数据不确定性进行建模,例如,单词嵌入[141]、文档嵌入[42,112]和网络/图嵌入[9,54,160]。对于推荐,Dos Santos等人。[31]和江等人。[67]采用高斯嵌入的方法捕捉用户的不确定偏好,以提高用户表示和推荐性能。基于密度的表示,例如高斯嵌入,是一个值得探索的有趣方向,但在基于GNN的推荐模型中还没有得到很好的研究。
9.2 GNN用于推荐系统的可扩展性和效率(Scalability of GNN in Recommendation)
在工业推荐场景中,数据集包括数十亿个节点和边,而每个节点包含数百万个特征,由于内存使用量大和训练时间长,直接应用传统的GNN是具有挑战性的。要处理大规模的图,有两种主流:一种是通过采样来减小图的大小,使其适用于现有的GNN;另一种是通过改变模型的体系结构来设计一个可扩展的高效的GNN。采样是训练大型图形的一种自然且被广泛采用的策略。例如,GraphSAGE[50]随机采样固定数量的邻居,而PinSage[190]采用随机游走策略进行采样。此外,一些工作[35,127]从每个用户-项目对的原始图重构了小规模子图。然而,抽样会或多或少地丢失部分信息,如何设计一种有效的抽样策略来平衡有效性和可扩展性,很少有研究关注。
解决这一问题的另一个主流方法是将连续层之间的非线性运算和折叠权重矩阵的运算解耦[38,55,168]。由于邻域平均特征只需要预计算一次,因此在没有模型训练的通信代价的情况下,它们具有更好的可扩展性。然而,与学习灵活性更高的传统GNN相比,这些模型受到聚合器和更新器选择的限制[17]。因此,面对大规模的图形,还需要进行更多的研究。
9.3 推荐中的动态图上如何使用GNN技术(Dynamic Graphs in Recommendation)
在现实世界的推荐系统中,不仅用户和项目等对象,而且它们之间的关系也随着时间的推移而变化。为了保持最新的建议,应用新的即将到来的信息反复更新系统。从图形的角度来看,不断更新的信息产生了动态的图形,而不是静态的图形。静态图是稳定的,因此可以对它们进行可行的建模,而动态图引入了变化的结构。如何针对实际中的动态图设计相应的GNN框架是一个有趣的前瞻性研究问题。现有的推荐研究很少关注动态图。据我们所知,GraphSAIL[188]首次尝试解决基于GNN的推荐系统的增量学习问题,它处理的是交互的变化,即节点之间的边。为了平衡更新和保存,在连续学习的模型中约束中心节点与其邻域之间的嵌入相似度,并控制增量学习的嵌入接近其先前版本。推荐中的动态图是一个很大程度上未被开发的领域,值得进一步研究。
9.4 推荐中GNN的接收域(Reception Field of GNN in Recommendation)
节点的接收字段指的是一组节点,包括该节点本身及其在퐾-Hop内可达的邻居,其中퐾是传播迭代的次数。通常,聚集步骤퐾与耦合的GNN(例如,GCN和GRAPSAGE)中的GNN层的数目相同。此外,最近的一些基于图扩散的工作[74,75,109]解耦了聚集和更新操作,并以更大的聚集步长拥抱了更大的接收场。对于度数较低的节点,需要较深的GNN结构来扩大接收范围,以获得足够的邻域信息。然而,通过增加传播步长,具有较高度的节点的接收场将扩展得太大,并且可能引入噪声,这可能导致过平滑问题[86],从而导致性能下降。
对于推荐中的图数据,节点度呈长尾分布,即活跃用户与项目的交互较多,而冷用户与项目的交互较少,与热门项目和冷项目相似。因此,在所有节点上应用相同的传播步骤可能不是最佳的。为了获得合理的接收场,只有少数新兴的工作是自适应地决定每个节点的传播步长[71,96,98]。因此,如何在基于GNN的推荐中为每个用户或条目自适应地选择合适的接收域仍然是一个值得研究的问题。
9.5 自监督学习(Self-supervised Learning)
自监督学习是一种新兴的提高数据利用率的方法,它可以帮助缓解稀疏性问题。受SSL在其他领域的成功启发,最近的努力利用SSL来推荐系统,并取得了显著的成就[170,209]。在基于GNN的推荐系统领域,也很少有人尝试使用SSL。例如,COTREC[181]通过最大化最后点击的项和预测项样本的表示之间的一致性,以及给定的会话表示来设计对比学习任务。DHCN[182]最大化了通过会话-会话图和项-会话超图学习的会话表示之间的互信息。关键的挑战是如何设计一个与主任务相对应的有效的监督信号。考虑到稀疏性问题在推荐系统中的普遍存在,我们认为基于GNN的推荐系统中的自监督学习是一个很有前途的方向。
9.6 基于GNN的推荐系统的鲁棒性(Robustness in GNN-based Recommendation)
最近的研究表明,GNN很容易被输入的微小扰动所蒙蔽[187],即如果图结构包含噪声,GNN的性能将大大降低。在现实世界的推荐场景中,节点之间的关系并不总是可靠的是一个常见的现象。例如,用户可能不小心点击了这些项目,并且无法捕获部分社交关系。此外,攻击者还可能向推荐系统注入虚假数据。因此,构建一个健壮的推荐系统,即使在先令攻击的情况下也能产生稳定的推荐具有重要的现实意义。由于GNN对噪声数据的脆弱性,构建一个即使在先令攻击下也能产生稳定推荐的健壮推荐系统具有重要的现实意义[201]。在GNN领域,出现了一些关于图对抗学习以增强稳健性的努力[56,187,211]。在基于GNN的推荐中,很少有尝试开始关注健壮性。例如,GraphRf[201]共同学习评级预测和欺诈者检测,其中成为欺诈者的概率确定评级预测组件中用户评级的可靠性。如何构建一个更健壮的推荐系统是一个值得探索的问题,但在基于GNN的推荐系统中还没有得到很好的研究。
9.7 隐私保护(Privacy Preserving)
由于一般数据保护条例第12条对隐私的严格保护,推荐系统中的隐私保护引起了学术界和工业界的大量关注,因为大多数数据可能被认为是机密/私人的,例如社交网络和历史行为[57]。一种新兴的范例是使用联合学习来训练推荐系统,而无需将用户数据上传到中央服务器[94,111,149]。然而,本地用户数据仅包含一阶用户-项目交互,这对于在没有隐私链接的情况下捕获高阶连接是具有挑战性的[167]。另一条线是在推荐系统的过程中采用差异隐私来保障用户隐私[39,128]。差异隐私的一个限制是它通常会导致性能下降[29]。
一些努力集中在基于GNN的推荐中的隐私保护上。例如,FedGNN[167]基于本地用户-项目图在本地训练GNN模型。提出了伪交互项和用户-项图扩展方法,分别用于保护项和利用高阶交互。基于局部差分隐私(LDP)[24],FedGNN可能会在每个模型的局部梯度中添加噪声,从而降低模型的精度。为了在保持隐私保护的同时减少噪声量,PPGRec[120]将LDP模型转换为中央差分隐私模型,并且仅向聚合的全局梯度添加噪声。随着社会对隐私保护的日益重视,基于GNN的推荐中的隐私保护因其实用价值而成为一个有吸引力的方向。
9.8 公平性(Fairness in GNN-based Recommender System)
近年来,关于推荐偏差以实现公平的研究工作激增[16]。例如,对不同人口统计群体的用户的推荐表现应该接近,每一项都应该有相同的总体曝光概率。随着GNN的广泛传播,越来越多的社会担心GNN可能做出歧视性决定[30]。在基于GNN的推荐系统中,人们已经进行了一些探索,以减轻偏向。例如,Niser[48]对表示应用归一化操作来处理受欢迎程度偏差。FairGNN[27]采用对抗性学习范式,通过利用图结构和有限的敏感信息来消除GNN的偏见。由于推荐系统中普遍存在的偏见和社会对公平的日益关注,基于GNN的推荐系统在保证公平的同时保持可比的性能值得进一步研究。
9.9 可解释性(Explainability)
可解释性对推荐系统是有益的:一方面,向用户提供可解释的推荐允许他们知道为什么推荐项目并且可能具有说服力;另一方面,从业者可以知道为什么模型有效,这可能有助于进一步改进[200]。由于可解释性的重要性,许多兴趣集中在设计可解释性的推荐模型或进行事后解释[63,126,139]。
随着GNN的扩散,最近的努力已经研究了GNN的可解释性方法[194]。这些方法可以分为两类:实例级方法通过为其预测识别重要的输入特征来提供特定于实例的解释[3,124,195];模型级方法提供高级解释和对深度图模型如何工作的一般理解[193]。也有一些关于基于GNN的建议[64,108,157]的解释性的尝试。它们大多利用知识图中的语义信息进行事后解释。到目前为止,可解释的基于GNN的推荐系统还没有得到充分的探索,这应该是一个有趣和有益的方向。
10 结论(Conclusion)
由于GNN在图形数据学习方面的优势,将GNN技术应用于推荐系统在学术界和工业界引起了越来越多的兴趣。在本次调查中,我们全面回顾了基于GNN的推荐系统的最新工作。我们提出了组织现有工程的分类方案。对于每个类别,我们简要阐明了主要问题,详细介绍了代表性模型所采用的相应策略,并讨论了它们的优点和局限性。此外,我们还提出了未来研究的几个有希望的方向。我们希望这项调查能够让读者对这一领域的最新进展有一个大致的了解,并对未来的发展有一些启示。

若有收获,就点个赞吧
0 人点赞
