Deep Graph Infomax
- Petar Velickovic, William Fedus, William L. Hamilton, et al. Deep Graph Infomax[C]. In ICLR 2019.
- 剑桥大学、Google
摘要(Abstract)
我们提出深度图Infomax (DGI),这是一种以无监督方式在图结构数据中学习节点表示的通用方法。DGI依赖于最大化图块表示和相应的高级图摘要之间的互信息-两者都是使用已建立的图卷积网络结构导出的。学习的小块表示概括了以感兴趣的节点为中心的子图,并且因此可以被重新用于下游的节点学习任务。与大多数使用GCNs进行无监督学习的方法不同,DGI不依赖于随机游走目标,并且很容易适用于直推式和归纳式学习(transductive and inductive learning)设置。我们在各种节点分类基准上展示了具有竞争力的性能,有时甚至超过了监督学习的性能。
1 引言(Introduction)
2 相关工作(Related Work)
3 DGI 方法(DGI Methodology)
在本节中,我们将以自上而下的方式介绍深度图Infomax方法:首先是我们特定的无监督学习设置的抽象概述,然后是我们方法优化的目标函数的阐述,最后是在单图设置中枚举我们过程的所有步骤。3.1 基于图的无监督学习(Graph-Based Unsupervised Learning)
3.2 局部-全局互信息最大化(Local-Global Mutual Information Maximization)
3.3 理论动机(Theoretical Motivation)
3.4 DGI概述(Overview of DGI)
一、DGI模型核心观点
DGI模型对比学习预训练框架,依赖于Node Representation和Graph Representation之间互信息最大化。本文之前方法在构建图模型是大多数依赖于Random Walk Objectives,例如GCN模型,Random Walk成立的的一个前提假设就是当前节点和邻居节点是相似的。本文则是从互信息Mutual Information作为核心指标出发,通过对比学习Local Representation和Global Representation的互信息最大化来进行图学习。
明确点1:DGI模型是基于互信息最大化,计算的是节点表征和全图表征之间的互信息,对于大规模知识图谱肯定现需要进行子图采样,因此计算的是节点表征和当前节点所在子图表征之间的互信息。
明确点2:DGI模型采用的是对比学习,那么正样例和负样例如何定义?首先就是Node Representation对应的Sub-Graph Representation,而正样例就是当前Sub-Graph中的节点表征,而负样例就是当前子图之外的其他节点表征。
明确点3:如何有Node Representation得到Sub-Graph Representation?使用Readout Function,公式如下所示,其中 是节点特征,
是节点特征, 是全局子图特征,图级表示
是全局子图特征,图级表示 ,
, 根据实际情况可自定义。
根据实际情况可自定义。

明确点4:如何计算Local Representation和Global Representation之间相似度?用 表示,
表示, ,
, 的具体实现就是利用互信息
的具体实现就是利用互信息
- 判别器
 将局部表示和图级表示互信息最大化,
将局部表示和图级表示互信息最大化, 表示一个概率分数,这个分数越高表示对应的局部表示
表示一个概率分数,这个分数越高表示对应的局部表示 包含越多的图级信息
包含越多的图级信息
明确点5:最后Scoring Function定义,最大化正样本节点和图之间的相似度,最小化负样本节点和图之间的相似度,公式如下所示:
二、DGI模型运作流程
1、负采样获得负样本 
- 对于单个图,负样本的生成需要一个随机变换函数
 来生成,可以表述为
来生成,可以表述为
2、通过Encoder模块计算Input Graph的Local Representation 
3、通过Encoder模块计算负样本的Local Representation 
4、通过Readout函数计算Global Representation 
5、带入Scoring Function,最大化Scoring Function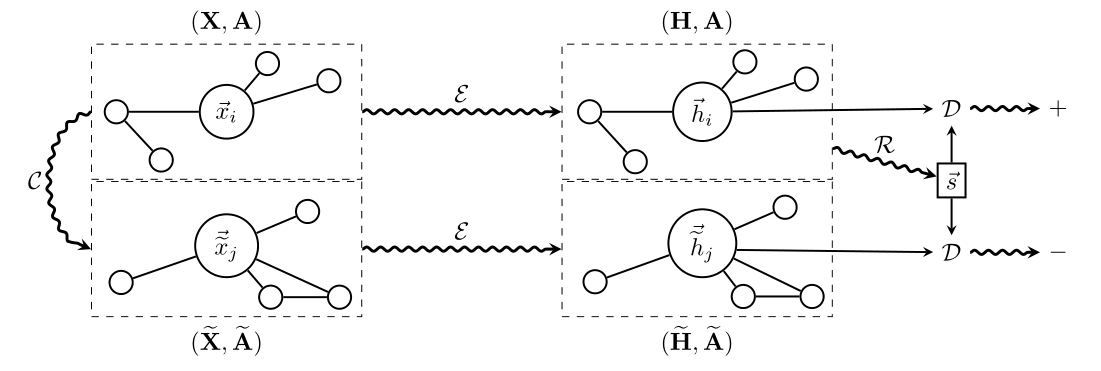
图1 深度图Infomax的高层概述
三、注意点
1、为什么选用互信息,而不是KL散度和JS散度?因为KL散度不满足对称性,JS散度容易出现空值;
2、Sub-Graph中的每一个节点得到的Local Representation都要和该Sub-Graph的Global Representation之间去计算互信息;
3、Discrimination是最大化Node Representation和Sub-graph Representation之间的互信息,最小化负样本表征和该Sub-graph互信息;
4、DGI模型如何生成负样本:邻接矩阵不变,特征进行Shuffle操作;
5、为什么可以将Node Representation和Graph Representation之间计算互信息:考虑到GCN本身节点特征就是通过子图汇聚得到的,所以到底节点有没有学到邻接点信息即学习到子图信息,GCN本身汇聚方法是Global得到Local,自然希望结果上Global也能去还原Local信息,所以解释了Local Representation和Global Representation之间计算互信息的合理性
6、总结Deep Infomax的重要前提:(1)深度特征不仅是复杂语义,还要尽量多的保留原始数据的重要信息,简单来说就是Global特征要尽可能还原Local特征,减少信息的丢失;(2)强化局部特征的传播特性。
四、结论
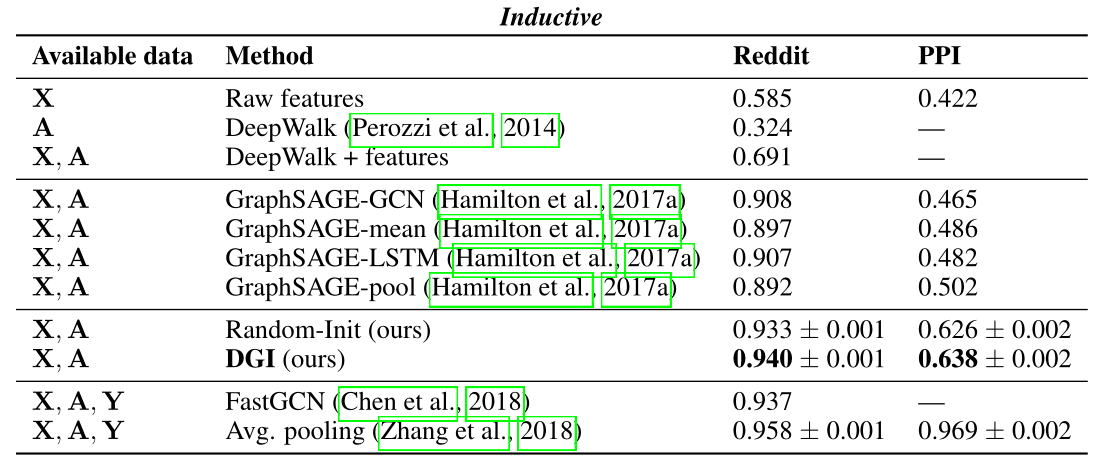
试验展示DGI模型在Transductive Learning和Inductive Learning上各种节点分类基准的竞争性性能,有的甚至超过了有监督学习模型的性能。
表2 分类准确度(直推式任务)或微平均F1分数(归纳式任务)的结果总结 :特征,
:特征, :邻接矩阵,
:邻接矩阵, :标签 “GCN”对应于以监督方式训练的两层DGI编码器
:标签 “GCN”对应于以监督方式训练的两层DGI编码器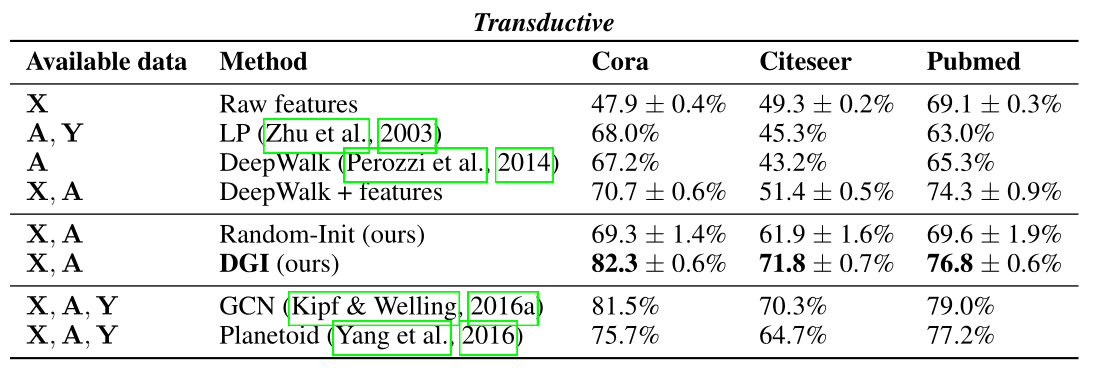

若有收获,就点个赞吧
0 人点赞
