- 摘要(Abstract)
- 关键字(Index Terms)
- 1 引言(Introduction)
- 2 定义和分类(Definition and Taxonomy)
- 3 数据增强(Data Augmentation)
- 4 对比式方法(Contrastive Methods)
- 5 生成式方法(Generative Methods)
- 6 预测式方法(Predictive Methods)
- 7 混合式方法(Hybrid Methods)
- 8 SELFRec:自监督推荐系统开源库
- 9 讨论(Discussion)
- 9.1 数据增强选择的理论证明(Theory for Augmentation Selection)
- 9.2 基于自监督推荐系统的可解释性(Explainable Self-Supervised Recommendation)
- 9.3 基于预训练推荐模型中的攻击与防御(Attacking and Defending in Pre-trained Recommendation Models)
- 9.4 移动边缘设备上的自监督推荐模型(On-Device Self-Supervised Recommendation)
- 9.5 通用预训练方法(Towards General-Purpose Pre-training)
- 10 结论(Conclusion)
Self-Supervised Learning for Recommender Systems: A Survey
- Junliang Yu, Hongzhi Yin, Xin Xia, et al. Self-Supervised Learning for Recommender Systems: A Survey[J]. In TKDE 2022
- 昆士兰大学 2022.03.29
IEEE Transactions on Knowledge and Data Engineering IF: 6.977
摘要(Abstract)
近年来,基于神经结构的推荐系统取得了巨大的成功。然而,在处理高维稀疏的时,它们仍然达不到预期。自监督学习作为一种新兴的无标签数据学习技术,近年来在许多领域引起了广泛的关注。也有越来越多的研究将SSL应用于推荐,以缓解数据稀疏问题。本文对自监督推荐(SSR)的研究成果进行了及时而系统的回顾。具体地说,我们提出了SSR的专有定义,在此基础上建立了一个全面的分类方法,将现有的SSR方法分为四类:对比法、生成法、预测法和混合法。对于每一种类别,叙述都会沿着其概念和表述、涉及的方法以及优缺点展开。同时,为了便于SSR模型的开发和评估,我们发布了一个开源的库SELFRec,它融合了多个基准数据集和评估指标,并实现了一些最先进的SSR模型用于实证比较。最后,我们指出了当前研究的局限性,并展望了未来的研究方向。
关键字(Index Terms)
1 引言(Introduction)
推荐系统[1]作为一种可以发现用户潜在兴趣和简化决策方式的工具,已经被广泛部署在各种在线电子商务平台上,在创造令人愉快的用户体验的同时增加收入。近年来,在高度表达的深层神经结构的推动下,现代推荐系统[2]、[3]、[4]取得了巨大的成功,并产生了无与伦比的性能。然而,深度推荐模型本质上是数据饥渴的。为了利用深层架构,需要大量的训练数据。与可以通过众包进行的图像标注不同,推荐系统中的数据获取成本很高,因为个性化推荐依赖于用户自己生成的数据,而大多数用户通常只能消费/点击无数项目中的一小部分[5]。因此,数据稀疏性问题成为深度推荐模型充分发挥其潜力的瓶颈[6]。<br /> 自监督学习[7]作为一种学习范式,可以减少对人工标签的依赖,并能够对大量的未标签数据进行训练,最近受到了相当大的关注。SSL的基本思想是通过设计良好的辅助任务(pretext tasks)(即自监督任务)从大量的未标记数据中提取和传递的知识,其中监督信号是半自动生成的。由于能够克服普遍存在的标签不足问题,SSL已被应用于广泛的领域,包括视觉表征学习[8]、[9]、[10]、语言模型预训练[11]、[12]、音频表征学习[13]、节点/图分类[14]、[15]等,并且它已被证明是一种强大的技术。由于SSL的原理与推荐系统对更多标注数据的需求非常一致,受SSL在上述领域的巨大成功的推动,目前正在进行大量且不断增长的研究,以将SSL应用于推荐。<br /> 自监督推荐(SSR)的早期原型可以追溯到无监督方法,如基于自编码器的推荐模型[16]、[17],它依赖于不同的损坏数据来重构原始输入以避免过拟合。后来,SSR作为基于网络嵌入的推荐模型出现[18]、[19],其中随机游走邻近度被用作自监督信号来捕获用户与物品之间的相似性。在同一时期,一些增强用户-项目交互的基于生成对抗网络[20] (GANs)的推荐模型[21]、[22]可以被视为SSR的另一个实例。在预训练的语言模型BERT[12]在2018年取得巨大突破后,作为一个独立的概念,SSL进入了聚光灯下。然后,推荐社区开始接受SSL,随后的研究[23]、[24]、[25]将注意力转移到了具有类似完形填空的序列数据任务的预训练推荐模型上。自2020年以来,SSL经历了一段繁荣期,最新的基于SSL的方法在许多CV和NLP任务中的表现几乎与其受监督的同行不相上下[9]、[26]。特别是,对比学习(CL)[27]的复兴极大地推动了SSL的前沿。与此同时,人们也见证了一阵对SSR的狂热[28]、[29]、[30]、[31]、[32]、[33]。SSR的范式变得多样化,场景不再局限于顺序推荐。<br /> 虽然已经在CV、NLP[34]、[7]和图学习[35]、[36]、[37]领域中已经有了一些关于SSL的综述,但尽管论文数量迅速增长,SSR的研究努力还没有得到系统的调查。与上述领域不同,推荐涉及的场景太多,优化目标不同,处理的数据类型也不同,很难将已有的针对CV、NLP和图任务的SSL方法完美地推广到推荐中。因此,它为新型SSL提供了土壤。同时,推荐系统所独有的高度倾斜的数据分布[38]、广泛观察到的偏差[39]和大词汇分类特征[40]等问题也刺激了一系列独特的SSR方法,这些方法可以丰富SSL家族。随着SSR的日益盛行,迫切需要进行一次及时而系统的综述,总结已有的SSR研究成果,讨论其优缺点,以促进未来的研究。为此,我们对SSR的前沿进行了最新和全面的回顾。总而言之,我们的贡献有四个方面:
我们调查了一系列SSR方法,尽可能多地涵盖相关论文。据我们所知,这是针对这一新主题的第一次综述。
- 我们提供了SSR的专有定义,并阐明了它与相关概念的联系。最重要的是,我们提出了一个全面的分类方法,将现有的SSR方法分为四类:对比、生成、预测和混合。对于每个类别,叙述都会沿着它的概念和表述、涉及的方法以及优缺点展开。我们相信,定义和分类为开发和定制新的SSR方法提供了一个清晰的设计空间。
- 我们引入了一个开源库来促进SSR模型的实现和评估。它整合了多个基准数据集和评估指标,并实施了10多种最先进的SSR方法进行实证比较。
- 我们揭示了现有研究的局限性,并确定了推进SSR的剩余挑战和未来方向。
论文收集Paper collection 在这次调查中,我们回顾了60多篇纯粹专注于SSR的论文,这些论文是在2018年后发布的。至于SSR的早期实现,如基于自编码器和基于GAN的模型,它们已经包含在之前关于深度学习[6],[41]和对抗训练[42],[43]的综述中并得到了充分的讨论。因此,我们不会在接下来的章节中重新讨论它们。在检索相关文献时,以DBLP和Google Scholar为主要搜索引擎,检索词为:自监督+推荐、对比+推荐、增强+推荐、预训练+推荐。然后,我们遍历了识别的论文的引文图,并保留了相关论文。特别是,我们密切关注ICDE、CIKM、ICDM、KDD、WWW、SIGIR、WSDM、AAAI、IJCAI、TKDE、TOIS等顶级会议/期刊,以避免错过高质量的工作。除了这些发表的论文,我们还在arxiv上筛选了预印本,并整理出那些新颖有趣的想法,以获得更具包容性的全景图。
与现有综述的联系Connections to existing surveys 虽然已经有一些关于Graph SSL的综述[35],[36],[44],其中包含了一些关于推荐的论文,但他们只是将这些工作作为Graph SSL的补充应用。另一项相关综述[45]关注推荐模型的预训练。然而,它的重点是通过利用知识图谱在不同领域之间迁移知识,并且只涵盖了少数以自监督的方式预训练的类似BERT的工作。与它们相比,我们的综述纯粹集中在特定于推荐的SSL上,并且是第一个对这一研究领域的大量最新论文进行系统综述的调查。
读者Readers 这项调查将使推荐社区的以下研究人员和从业者受益:1)刚接触SSR并希望快速进入这一领域;2)迷失在一系列令人困惑的自监督方法中,需要鸟瞰这一领域;3)想要跟上SSR的最新进展;以及4)正在开发自监督推荐系统并寻求指导。
综述结构Survey Structure 本次综述的其余部分结构如下。在第2节中,我们从SSR的定义和表述入手,介绍了从调查大量研究论文中提炼出来的分类。第三节介绍了常用的数据增强方法。第4-7节分别回顾了四类SSR模型,并论证了它们的优缺点。第8节介绍了开源框架SELFRec,它方便了SSR方法的实现和比较。第9节讨论了当前研究的局限性,并确定了一些有希望的方向。最后,第十节对本文进行了总结。
2 定义和分类(Definition and Taxonomy)
在本节中,我们首先定义并形式化SSR。然后,我们根据现有SSR方法的辅助任务的特点,将现有的SSR方法分为四种范式(图1)。最后,介绍了三种典型的SSR训练方式。<br />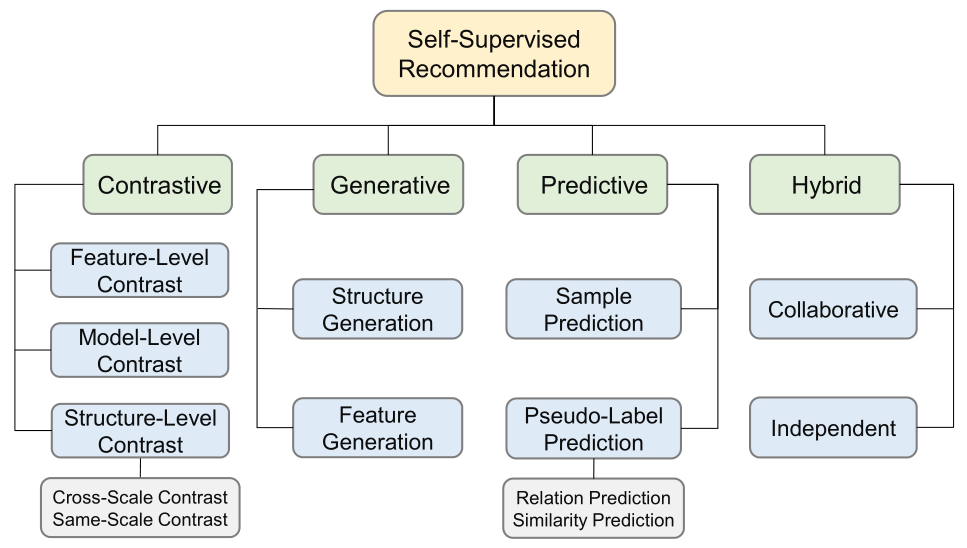<br />**图1 自监督推荐的分类**
2.1 预备知识 Preliminaries
目前的SSR研究主要利用图和序列数据,其中原始的用户-项目交互分别被建模为按时间顺序的二部图和项目序列。在基于图的推荐场景中,我们设表示用户-项目二部图,其中是节点集(即用户和项目),是边集(即交互)。图结构用邻接矩阵表示,其中表示节点和节点相连。在基于序列的下一项目推荐场景中,我们用表示项目集。每个用户的行为通常被建模为有序序列,并且指的是整个数据集。在某些情况下,用户和项目与其属性相关联。我们用来表示属性矩阵,其中是表示对象的属性的multi-hot向量表示。推荐模型的一般目的是学习用户和项目的质量表示,以产生满意的推荐结果,其中是表示维度。为了便于阅读,在本文中,矩阵用大写字母表示,向量用粗体小写字母表示,集合用斜体大写字母表示。
2.2 自监督推荐的定义(Definition of Self-Supervised Recommendation)
SSL为克服推荐中的数据稀疏性问题提供了一种新的方法。然而,SSR还没有明确的定义。参考其他领域[7]、[35]中对SSR的定义以及收集的有关推荐的文献中的SSR如何工作,我们将SSR的基本特征总结为:<br /> (i)通过半自动化的方式获取更多的监督信号。<br /> (ii)通过一个辅助任务利用增强的数据来微调推荐系统。<br /> (iii)辅助任务(Pretext task)协助推荐系统任务(Primary task)来完成更高性能的推荐模型。<br />其中, (i)确定了SSR的**基本范围**,(ii)确定了SSR区别于推荐系统其他领域的问题**设置**,(iii)阐述了与推荐主任务与辅助任务的**关系**。<br /> 给定定义,我们可以澄清基于预训练的推荐模型[45]和SSR模型之间的区别。前者经常被误解为后者的一个分支或是后者的同义词,因为在CV和NLP领域,预训练已经成为SSL的标准技术。然而,一些基于预训练的推荐方法[46]、[47]在没有数据增强的情况下是纯监督的,并且它们需要额外的人类标注辅助信息用于预训练。因此,这两种范式只是部分重叠。类似地,基于对比学习(CL)[27]的推荐通常被认为是SSR的子集。然而,CL可以适用于监督和无监督环境,不增加原始数据[48]、[49]、[50]仅优化边际损失[51]、[52]的基于CL的推荐方法也不应被粗略地归类为SSR中。<br /> 由于推荐系统中数据和优化目标的多样性,要正式定义SSR,需要一个模型不可知的框架。虽然具体的结构和使用的编码器和映射头的数量因情况而异,但大多数现有的模型一般都可以概括成**编码器 + 映射头**结构。为了处理不同的数据,如图、序列和分类特征,像GNN[53]、Transformers[54]和MLP这样的广泛的神经网络可以作为编码器的候选结构,而映射头(也称为生成模型中的解码器)通常具有轻量级结构。它可以是线性变换、非线性映射(例如,浅层MLP)或者甚至是非参数全等映射。编码器通常旨在学习用户和项目的分布式表示。映射头为推荐任务或特定辅助任务细化。基于这种架构,SSR可以表示为:<br /> (1)<br />其中,表示原始数据,表示满足的增强数据,表示增强模块,是合并损失函数,可分为推荐任务的损失和辅助任务的损失。通过最小化等式(1),可以学习最优编码器、映射头(s)和表示以生成质量推荐结果。
2.3 自监督推荐方法的分类(Taxonomy of Self-Supervised Recommendation Methods)
作为SSR的关键组成部分,辅助任务使SSR有别于其他推荐范式。根据辅助任务(pretext task)的特征,我们将现有的SSR模型分为四类:对比模型、预测模型、生成模型和混合模型。<br />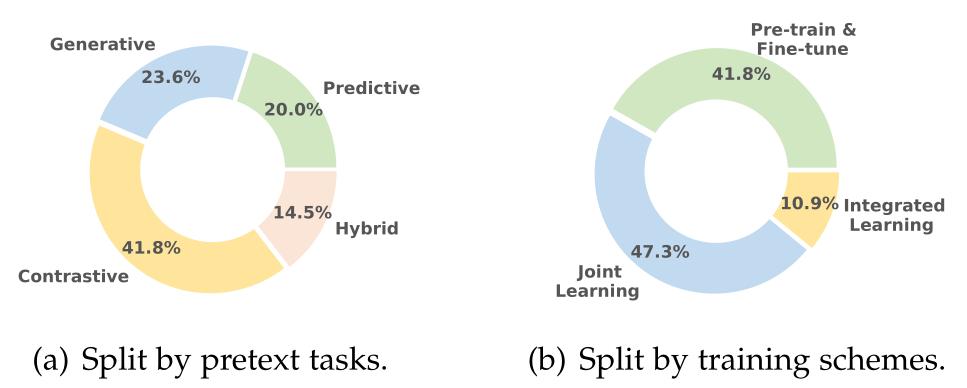<br />**图2 自监督推荐的分布**<br />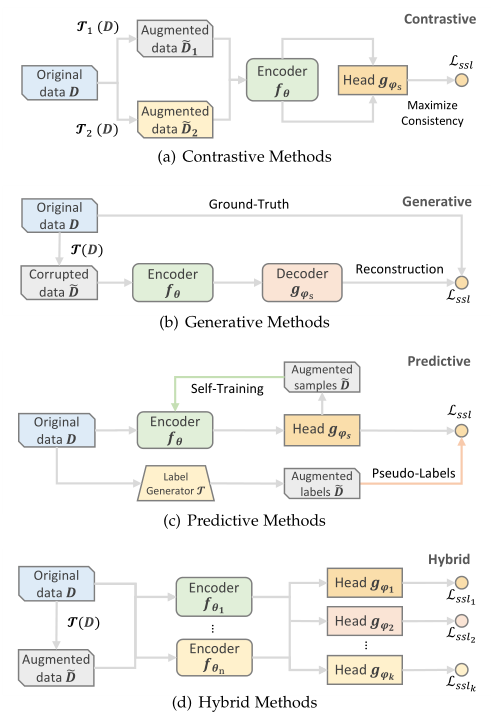<br />**图3 自监督推荐的四种常见范式**
2.3.1 对比式方法(Contrastive Methods)
在CL[27]的推动下,对比式方法已成为SSR的主导分支(如图2(a)所示)。对比式方法背后的基本思想是将每个实例(例如,用户/项目/序列)视为一个类,然后在嵌入空间中拉近相同实例的视图,拉远不同实例的视图,其中通过对原始数据施加不同的变换来创建视图。通常,同一实例的两个视图被视为正对,而不同实例的视图被视为彼此的负样本。积极的观点应该是在不改变语义的情况下将非必要的变化引入例句。通过最大化正对之间的一致性和最小化负对之间的一致性,我们可以得到可区分的和可概括的推荐表示。形式上,对比SSR方法的辅助任务(图3(a))可以定义为:<br /> (2)<br />其中和是的两个不同的增强视图,和是增强运算符(例如,节点丢失和项目重新排序)。损失函数通过由共享编码器学习的表示来估计视图之间的互信息(MI ),其中映射头通常具有诸如双线性网络的轻量化结构。<br />
2.3.2 生成式方法(Generative Methods)
生成式方法的灵感来自掩蔽语言模型(MLM)[12],其辅助任务是重构具有损坏版本的原始用户/项目配置文件(图3(b))。换句话说,该模型学习从其余数据中预测部分可用数据。最常见的任务是结构重构(例如,掩蔽项目预测)和特征重构。在这些情况下,辅助任务表示为:<br /> (3)<br />其中,表示原始输入的损坏版本。在大多数生成SSR方法中,目标函数通常被实例化为交叉熵损失(CE)或均方误差(MSE),其估计掩蔽项目/数字特征的概率分布/值。<br />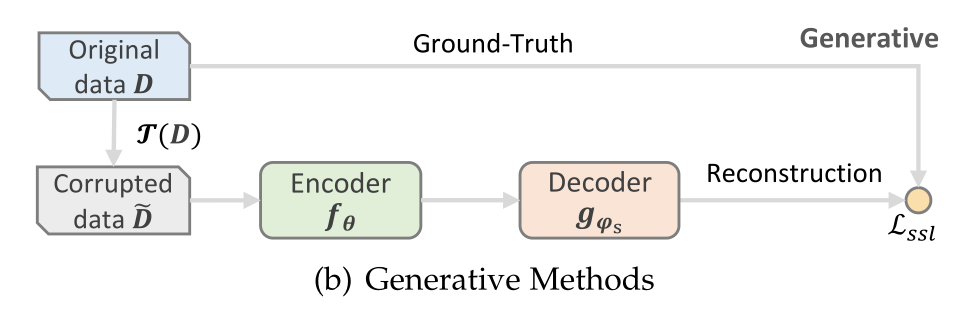
2.3.3 预测式方法(Predictive Methods)
预测式方法通常看起来像生成式方法,因为它们都具有预测的作用。然而,在生成式方法中,目标是预测原来存在的缺失部分,这可以被视为自我预测。而在预测式方法中,新的样本或标签从原始数据中产生,以指导辅助任务。我们进一步将现有的预测SSR方法分为两类:基于样本的和基于伪标签的(图3(c))。前者侧重于根据编码器当前的参数预测信息样本,然后将这些样本再次馈送到编码器,以产生具有更高置信度的新样本[55],[56]。通过这种方式,自训练(一种半监督学习的味道)和SSL联系在一起。基于伪标签的分支通过生成器产生标签,生成器可以是另一个编码器或基于规则的选择器。然后使用所生成的标签作为地面事实来引导编码器。基于伪标签的分支可以表示为:<br /> (4)<br />其中表示生成的标签,通常以CE/Softmax或MSE的形式出现。前者将预测概率与标签对齐,后者测量的输出与标签之间的差异,分别对应于分类问题和回归问题。<br />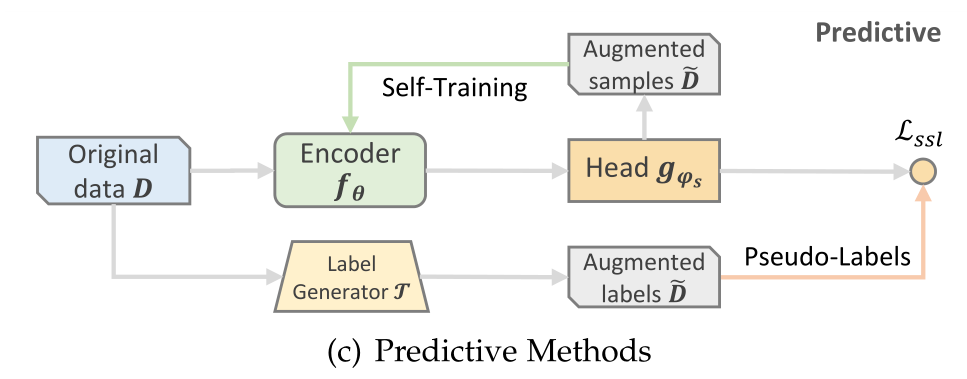
2.3.4 混合式方法(Hybrid Methods)
上述每种类型的辅助任务都有自己的优势,可以利用不同的自监督信号。获得全面自监督的一个自然方式是将不同的辅助任务组合在一起,并将它们整合到一个推荐模型中。在这些混合方法中,可能需要不止一个编码器和映射头(3(d))。不同的辅助任务或独立工作,或协同强化自监督信号。不同类型的辅助任务的组合通常被表述为上述类别中提出的不同自监督损失的加权总和。<br />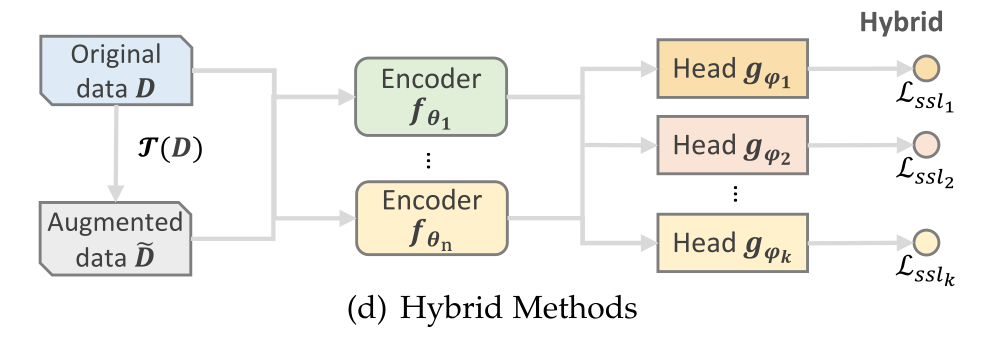
2.4 自监督推荐的典型训练方式
尽管SSR有统一的表述(等式(1)),在不同的场景中,推荐任务与辅助任务以更具体的方式相结合在一起。在本节中,我们将介绍三种典型的SSR训练方案:联合训练(JL)、预训练和微调(PF)以及综合训练(IL)。图4给出了它们的简要路线(pipelines)。
2.4.1 联合训练(Joint Learning, JL)
根据图2(b),收集的SSR方法中近一半倾向于JL训练方案。在该方案中,辅助和推荐任务通常与共享编码器联合优化(图4(a))。通过调整控制自监督的大小的超参数α,在两个目标和之间实现权衡。虽然JL方案可以被认为是一种多任务学习,但辅助任务的结果通常不被关注,而是视为有助于正则化推荐任务的辅助任务。JL方案的定义如下:<br /> (5)<br />对比式方法中多采用JL训练。
2.4.2 预训练和微调(Pre-train and Fine-tune, PF)
PF方案是第二种最流行的训练方案,它包括两个阶段:预训练和微调(图4(b))。在第一阶段中,利用关于增强数据的辅助任务来预训练编码器,以便很好地初始化编码器的参数。在此之后,预训练的编码器在原始数据上进行微调,随后用于推荐任务的映射头。之前关于图的综述[35],[37]介绍了另一种称为无监督表示学习的训练方案,该方案首先用辅助任务预训练编码器,然后冻结编码器,并且只学习下游任务的线性头部。我们认为它是PF方案的一个特例,在推荐的场景中很少使用。PF方案的公式定义如下:<br /> (6)<br /> PF方案通常用于训练类BERT生成式SSR模型,该模型在基于掩码的序列增强上进行预训练,然后在交互数据上进行微调。一些对比式方法也采用了这种训练方案,其中对比辅助任务是用于预训练的。
2.4.3 综合训练(Integrated Learning, IL)
与JL和PF方案相比,IL方案受到的关注较少,也没有得到广泛的应用。在这一背景下,辅助任务和推荐任务很好地结合在一起,并统一为一个综合目标。损失通常衡量两个输出之间的差异或互信息。IL方案可以形式化如下:<br /> (7)<br />IL方案主要用于基于伪标签的预测式方法和少数对比式方法。<br />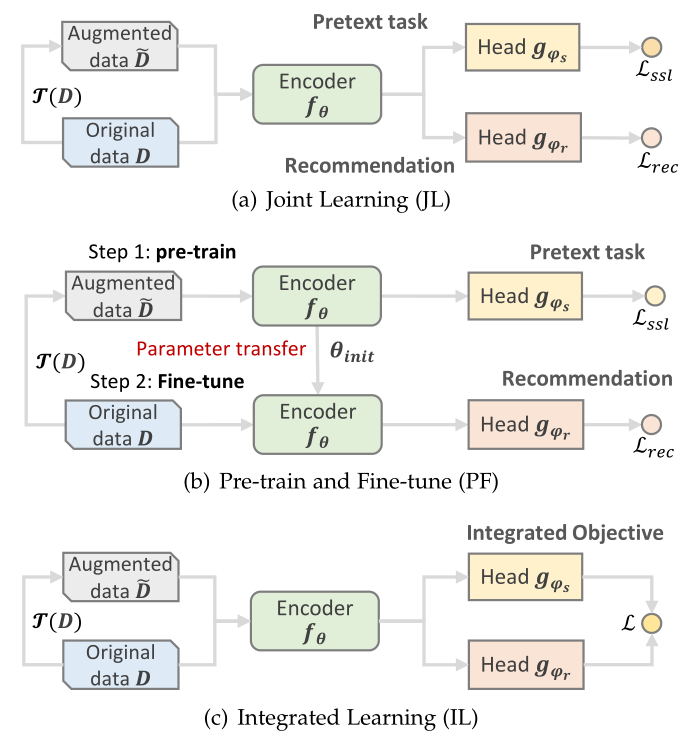<br />**图4 自监督辅助任务的三种典型训练方案**
3 数据增强(Data Augmentation)
先前在多个领域对SSL[57]、[58]、[59]所做的努力已经证明,数据增强在学习质量和泛化表示中起着关键作用。在详细介绍SSR方法之前,我们总结了SSR中常用的数据增强方法,并将其分为三类:基于序列的、基于图的和基于特征的。这些增强方法中的大多数都是独立于任务和模型不可知的,已经在SSR的不同范例中使用。对于那些依赖于任务和模型的方法,我们将在第4-7节中介绍它们以及具体的SSR方法。
3.1 序列数据增强(Sequence-Based Augmentation)
给定作为用户历史行为的项目的序列,常见的基于序列的增强(如图5(a)所示)如下所示。<br />** 项目掩蔽Item Masking** 类似于BERT[12]中的单词masking,项目掩蔽策略(也称为项目丢弃)[60]、[25]、[61]、[62]、[63]随机地掩蔽部分项目并用特殊标记[mask]替换它们。背后的想法是,用户的意图在一段时间内相对稳定。因此,尽管部分项目被屏蔽,但主要意图信息仍保留在其余项目中。设表示掩码项目的索引。这一增强策略可以表述为:<br /> (8)<br />** 项目裁剪Item Cropping** 受CV中图像裁剪的启发,一些工作[61]、[25]、[62]、[60]提出了项目裁剪增强方法(又名:序列拆分)。给定一个用户的历史序列,随机选择一个长度为的连续子序列,其中η∈(0,1)是调整长度的系数。项目裁剪增强可以表示为:<br /> (9)<br /> 此方法提供用户历史序列的局部视图。通过自监督任务,所选择的子序列有望赋予模型学习概括表示的能力,而不需要全面的用户简档。<br />** 项目重新排序Item Reordering** 许多顺序推荐器[64]、[65]、[68]假定序列中的项目顺序是严格的,因此项目转换是顺序依赖的。然而,这种假设可能是有问题的,因为在现实世界中,许多未被观察到的外部因素可能会影响项目顺序[66],而不同的项目顺序实际上可能对应于相同的用户意图。一些工作[61],[60]提出将一个连续的子序列混洗到来创建序列增强,其公式如下:<br /> (10)<br />** 项目替换Item Substitution** 随机的项目裁剪和掩蔽会在短序列中夸大数据稀疏性问题。[67]提出将短序列中的项目替换为高度相关的项目,从而减少对原始序列信息的破坏。给定表示要被替换的随机选择的项目的索引,项目替换增强[68]、[67]方法被表示为:<br /> (11)<br /> 其中相关item是通过计算基于item的共现或对应表示的相似度的相关分数来获得的。<br />** 项目插入Item Insertion** 在短序列中,记录的交互无法跟踪全面的用户动态和项目相关性。因此,[67]还提出在短序列中插入相关item来完成序列。首先从给定序列中随机选择个项目,然后在它们周围插入高度相关的item。插入后,长度为的扩增序列为:<br /> (12)
3.2 图数据增强(Graph-Based Augmentation)
给定具有邻接矩阵的用户-项目图(或诸如用户-用户图和项目-属性图的其他图),可以应用以下图增强方法(图5(b)中示出)。<br />** 边/节点丢弃Edge/Node Dropout** 利用概率,可以从图中移除每条边。其背后的思想是只有部分连接对节点表示有贡献,丢弃冗余连接可以使表示对噪声交互具有更强的鲁棒性,这类似于项目掩蔽和裁剪方法。这种边丢弃方法的公式如下:<br /> (13)<br /> 其中是由伯努利分布生成的边集上的掩蔽向量。该方法被广泛应用于许多对比式方法[31]、[69]、[30]、[70]、[56]、[71]中。类似地,利用概率,还可以从图中丢弃每个节点及其相关边[72]、[30]、[70]。这种增强方法期望从不同的增强视图中识别有影响力的节点,其公式如下:<br /> (14)<br />其中是节点集上的掩蔽向量,而是掩蔽相关边的向量。<br /> **图扩散Graph Diffusion** 与基于丢弃的方法相反,基于扩散的增强将边添加到图中以创建视图。[73]认为缺失的用户行为包括未知的积极偏好,该偏好可以用加权的用户-项目边缘来表示。因此,它们通过计算用户和项目表示的相似度来发现可能的边,并保留具有top-相似度的边。扩散方法的公式为:<br /> (15)<br />当边被随机添加时,该方法也可用于生成负样本。<br /> **子图采样Subgraph Sampling** 该方法对构成子图并反映局部连通性的节点和边的进行采样。有很多方法可以用来归纳子图,如元路径引导的随机游走[74]、[70]和自网络采样[29]、[75]、[76]、[77]。子图采样的基本思想类似于边丢失的思想,而子图采样通常对局部结构进行操作。在给定采样节点集的情况下,该增强方法可以表示为:<br /> (16)<br />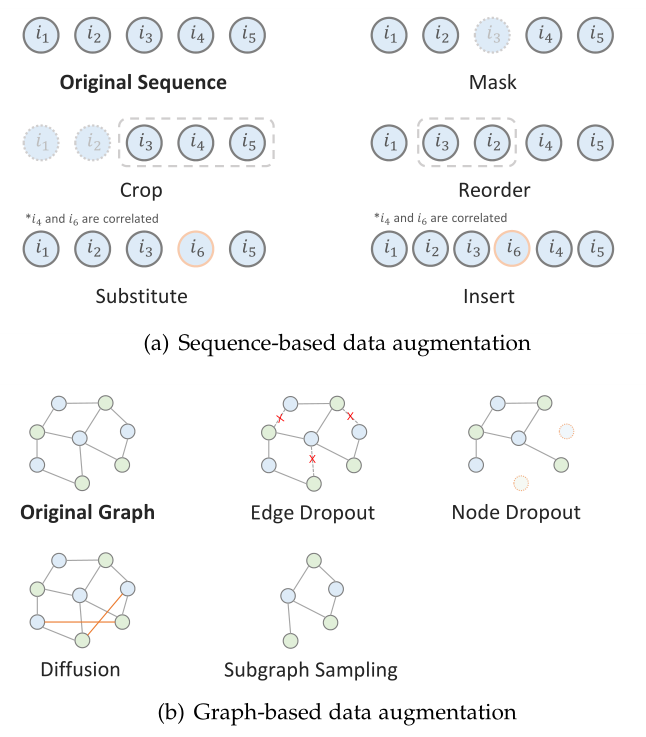<br />**图5 序列和图的数据增强**
3.3 特征数据增强(Feature-Based Augmentation)
基于特征的增强集中在用户/项目特征上,在属性/嵌入空间中操作。在这一部分中,分类属性和学习到的连续嵌入统称为特征,为简明起见用表示<br />** 特征丢弃Feature Dropout** 特征丢弃(也称为特征掩蔽)[25]、[71]、[78]、[79]、[33]、[80]类似于项目掩蔽和边丢弃,其随机地掩蔽/丢弃一小部分特征,其公式如下:<br /> (17)<br />其中M是掩蔽矩阵,如果向量的第个元素被掩蔽/丢弃,则,否则。矩阵由伯努利分布产生。<br />** 特征混洗Feature Shuffling** 特征混洗[29]、[28]、[81]切换特征矩阵中的行和列。通过随机改变上下文信息,被破坏以产生增强。这种方法可以表示为:<br /> (18)<br />其中和是置换矩阵,它们在每行和每列中恰好有一个条目1,并且在其他地方具有0。<br />** 特征聚类Feature Clustering** 这种增强方法[82]、[83]、[84]将CL与聚类结合起来,后者假设在特征/表示空间中存在原型,并且用户/项目表示应该更接近其分配的原型。扩展的原型表示可以通过期望最大化(EM)框架内的聚类来学习。这种方法可以表示为:<br /> (19)<br />其中是预设的簇(原型),而是增强的原型表示。<br />** 特征混合Feature Mixing** 该增强方法[85]、[71]将原始用户/项目特征与来自其他用户/项目或先前版本的特征混合,以合成信息丰富的负/正样本[86]。它通常以下列方式内插两个样本:<br /> (20)<br />其中α∈[0,1]是控制来自的信息的比例的混合系数。
4 对比式方法(Contrastive Methods)
灵活的数据增强技术与多种多样的辅助任务可以催生出许多SSR方法。本文根据自监督信号的来源分为了结构对比、特征对比和模型对比式方法,表1根据场景、数据增强方法、对比类型等条件列举了多种SSR方法。<br />**表1 对比式自监督推荐研究综述**<br />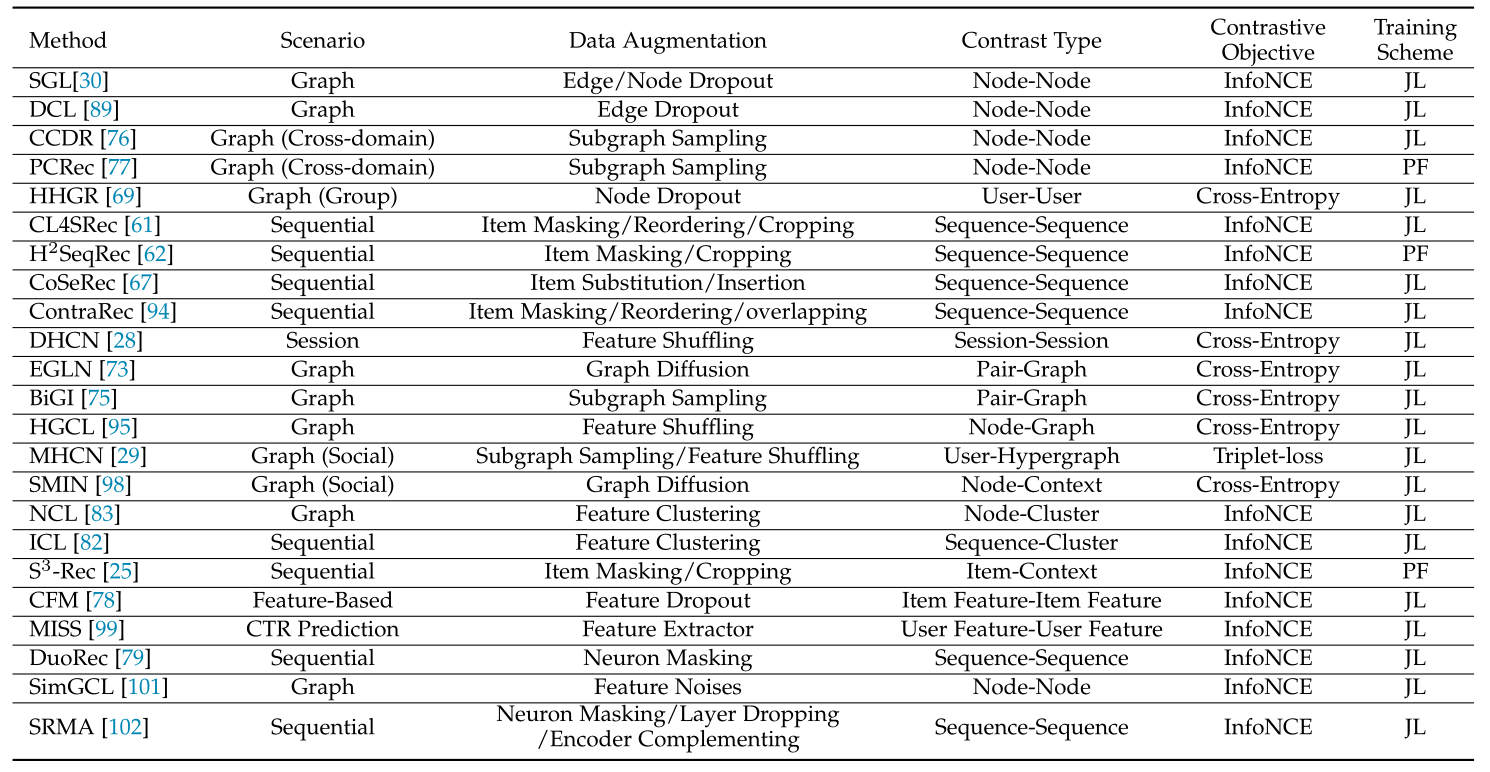
4.1 结构对比(Structure-Level Contrast)
用户行为数据通常被组织为图或序列。具有轻微扰动的图/序列结构可能具有相似的语义。通过对比不同的结构,得到结构扰动的共同不变性作为自监督信号。我们借鉴了文献[35]、[36]的分类方法,将结构层次的对比分为:同尺度对比和跨尺度对比。在前一类中,要对比的视图来自相同比例的两个对象。在后一类中,要对比的视图来自不同比例的两个对象。我们将同一尺度的对比度进一步细分为两个层次:局部-局部和全局-全局。类似地,跨尺度对比又细分为:局部-全局和局部-上下文。对于图结构,local指的是节点,global指的是图。对于序列结构,local指的是项目,global指的是序列。
4.1.1 局部-局部对比(Local-Local Contrast)
这种类型的对比通常在基于图的SSR模型中进行,以最大化用户/项目节点表示之间的互信息,其可表示为:<br /> (21)<br />其中和是通过共享编码器从两个增强视图学习的节点表示,是将在第4.4节中引入的对比损失。<br /> 对于局部对比,dropout-based的增强是创建受干扰的局部视图的最首选方法。**SGL**[30]作为一个典型的graph CL-based的推荐模型,在用户-项目二部图上应用了三种类型的随机图增强:节点丢弃、边丢弃和随机游走(多层边丢弃)。它首先生成两个具有相同类型的增强算子的增强图。然后应用共享图LightGCN编码器[87]从增强图中学习节点嵌入。节点水平对比是通过批次内负采样优化InfoNCE损失[13]来进行的。最后,SGL联合优化上述InfoNCE损失和贝叶斯个性化排名损失[88]进行推荐。与SGL类似,**DCL**[89]也使用随机边丢弃来扰动给定节点的-跳自网络,从而产生两个增强邻域子图。然后,它最大化在两个子图上学习的节点表示之间的一致性。<br /> 考虑到丢弃重要节点可能导致局部结构高度倾斜,**HHGR**[69]提出了一种双尺度节点丢弃方法,以在组推荐[90]的场景下产生有效的自监督信号。提出的粗粒度丢弃方案将部分用户节点从所有组中移除,而细粒度丢弃方案仅从特定组中丢弃随机选择的成员节点。然后,该方法最大化从这两个具有不同丢弃粒度的视图学习的用户节点表示之间的互信息。<br /> 子图采样是局域图对比度的另一种流行的增强方法。**CCDR**[76]将CL应用于跨域推荐。它设计了两种类型的对比任务:内部对比任务和中间对比任务。CL内任务与DCL[89]中的对比任务几乎相同,后者是在目标域中进行的,并使用图注意网络[91]作为编码者。InterCL任务旨在最大化在源域和目标域中学习的同一对象的表示之间的互信息。同一时间的工作**PCRec**[77]还将跨域推荐与CL联系起来。它使用随机游走对-hop自网络进行采样,以增加数据。采样子图之间的对比任务预训练了源域中的GIN[92]编码器。然后,参数被传送以初始化MF[93]模型,该模型与用于在目标域中推荐的交互数据微调。
4.1.2 全局-全局对比(Global-Global Contrast)
全局对比通常在序列推荐模型中进行,其中序列被认为是用户的全局视图,其可以表示为:<br /> (22)<br />其中和是两个序列增强,Agg是合成序列表示的聚合函数。<br /> **CL4SRec**[61]使用三个随机增强操作符:项目掩蔽、项目裁剪和项目重新排序来增强序列。给定N个序列,CLS4Rec应用两个增强算子,得到2N个增强序列。然后,它将视为正样本,并将小批次内的其他2(N-1)个增强序列视为负样本。使用基于Transformer的编码器[54]来编码增强的序列并学习用于全局对比度的用户表示。在**H2SeqRec**[62]中也发现了非常类似的想法,其中使用序列级别的对比任务来预训练基于Transformer的编码器。另外两个类似的作品**CoSeRec**[67]和**ContraRec**[94]也遵循CL4SRec的管道来对比序列。CoSeRec还提出将短序列中的项目替换为相关item,或者将相关item插入短序列中以实现稳健的数据增强。ContraRec不仅对比从相同输入中增强的序列,而且还将具有相同目标item的序列视为正对。在基于会话的推荐方案中,**DHCN**[28]通过分别对会话内和会话间的结构信息进行建模,创建了给定会话的两个基于超图的视图。它将同一会话的表示视为正对,将不同会话的损坏表示(通过在嵌入空间中的特征洗牌获得)视为负样本。
4.1.3 局部-全局对比(Local-Global Contrast)
局部-全局对比有望将高层全局信息编码成局部结构表示,并统一全局和局部语义。它通常应用于图学习场景,可以表示为:<br /> (23)<br />其中是生成全局图表示的读出函数。<br /> **EGLN**[73]提出通过将合并的用户-项目对表示与全局表示进行比较来达到局部-全局一致性,全局表示是所有用户-项目对表示的平均值。为了挖掘更多的自监测信号,采用了图扩散的数据增强方法。通过计算用户与项目之间的相似度,保留TOP-K相似度,得到增强图邻接矩阵。矩阵和用户/项目表示迭代地相互学习,并通过图编码器进行更新。在**BiGI**[75]中,也进行了类似的局部-全局对比。不同之处在于,当生成用户-项目对表示时,仅对其-跳子图(即,该子图中的任何节点满足dist或dist)进行采样以进行特征聚合。在**HGCL**[95]中,构造了用户和项目节点类型特定的齐次图。对于每个同质图,它遵循DGI[15]的流水线,最大化图的局部块和整个图的全局表示之间的互信息。此外,还提出了cross-type对比来度量不同类型的同质图的局部和全局信息。
4.1.4 局部-上下文对比(Local-Context Contrast)
在基于图和基于序列的场景中都可以观察到局部上下文对比。语境通常是通过采样、自网络或聚类来构建的。这种类型的对比可以表示为:<br /> (24)<br />其中表示节点(序列)的上下文。<br /> **NCL**[83]遵循[84]设计了一个原型对比目标,以捕获用户/项目与其原型之间的相关性。原型可以被视为每个用户/项目的上下文,它表示一组语义邻居,即使它们在用户-项目图中在结构上没有连接。将原型学习视为一种用于数据增强的特征聚类,通过K-Means算法对嵌入的所有用户或项目进行聚类来得到原型。然后利用EM算法对原型进行递归调整。ICL[82]具有几乎相同的流水线,唯一的区别是ICL是为顺序推荐而设计的,其中NCL中的语义原型在ICL中被建模为用户意图,而这里所属的序列是原型的局部视图。<br /> 在社交网络中,用户通常与他们的拓扑上下文相似。**MHCN**[29]是第一个将SSL应用于社交推荐的工作[96]、[97]。它定义了三种类型的三角社会关系,并使用多通道超图编码器对它们进行建模。对于每个通道中的每个用户,MHCN分层最大化用户表示、用户的自超图表示和全局超图表示之间的互信息。后续工作**SMIN**[98]继承了MHCN中的思想,将节点与其上下文进行对比。不同之处在于,上下文是通过从具有不同顺序的用户-项目邻接矩阵链中聚合信息来获得的。<br /> 此外,也有跨越不同对比级别的方法。**S****3****-Rec**[25]应用了两个运算符:项目掩蔽和项目裁剪来增强序列。然后设计了四个对比任务:项目-属性互信息最大化(MIM)、序列-项目MIM、序列-属性MIM、序列-序列 MIM,用于为下一项目预测预训练双向Transformer。
4.2 特征对比(Feature-Level Contrast)
与结构对比相比,特征对比的研究相对较少,因为特征/属性信息在学术用途的数据集中并不总是可用的。然而,在工业中,数据通常是以多字段格式组织的,并且可以利用大量的分类特征,例如用户简档和项目类别。一般来说,这种类型的对比可以正式定义为:<br /> (25)<br />其中,和是可通过修改输入特征或通过模型学习获得的特征增强。<br /> **CFM**[78]采用双塔结构,并对项目特征应用相关特征掩蔽和丢弃,以实现更有意义的特征增强。它试图将高度相关的特征一起掩蔽,这些特征的相关性是通过互信息来度量的。结果,对比任务变得困难,因为保留的特征很难弥补掩蔽特征背后的语义。**MISS**[99]认为,一个用户行为序列可能包含多个兴趣,直接干扰该序列将导致语义上不同的增强。相反,它使用CNN-based的多兴趣抽取器将包含行为数据和分类特征的用户样本转换为一组隐式兴趣表示,从而在特征上增强用户样本。然后对提取的兴趣表示进行对比任务。
4.3 模型对比(Model-Level Contrast)
前两类从数据角度提取自监督信号,并未以完全端到端的方式实现的。另一种方法是保持输入不变,并动态修改模型体系结构,以便动态增加视图对。这些模型增强之间的对比可以正式定义为:<br /> (26)<br />其中和是的扰动版本。这个等式可以看作是等式(2)的特例,这增加了相同输入的中间隐藏表示。<br /> 神经元掩蔽是一种常用的扰动模型的技术。**DuoRec**[79]借鉴了SimCSE[100]中的成功经验,将两组不同的丢弃掩码应用于基于Transformer的主干,用于两个模型的表示增强。然后,它最大化两个表示之间的互信息。虽然这种方法看起来非常简单,但在下一项目预测任务中表现出了显著的性能。与神经元掩蔽丢弃隐藏表示中的某些信息相反,**SimGC**L[101]直接在隐藏表示中添加随机均匀噪声以进行增强。实验证明,优化InfoNCE损失实际上学习了更均匀的节点表示,调整噪声大小可以提供更细粒度的表示一致性规则,从而缓解了流行度偏差问题[39]。得益于基于噪声的增强,SimGCL在推荐准确率和模型训练效率方面都表现出明显的优势。在**SRMA**[102]中,除了神经元水平的扰动外,它还提出在训练期间随机丢弃一小部分层。考虑到丢弃重要层会误导输出,它随机丢弃Transformer中的前馈网络的一些层以进行模型增强。此外,它还引入了另一个预训练的编码器,该编码器具有相同的体系结构,但使用推荐任务进行训练来生成不同的视图进行对比。<br /> 除了分类学之外,还有一些文献[103]、[104]声称他们提出的方法是对比自监督的。它们对多行为数据进行处理,并结合辅助行为数据作为监督信号进行数据增强。同一用户的行为视图被认为是正对,而不同用户的视图被采样为负对。然后,这些方法通过进行行为水平的对比来鼓励正对表示之间的一致性。然而,我们认为称它们为自监督是牵强的,因为事实上,它们不转换原始数据来创建任何新的视图。
4.4 对比损失(Contrastive Loss)
对比损失已成为CV领域的一个新的研究热点,也越来越受到SSR领域的关注。通常,对比损失的优化目标是最大化两个表示(视图)和之间的互信息(MI),其由下式给出:<br /> (27)<br />然而,直接最大化MI是困难的,一个实际的方法是最大化它的下界。在这一部分中,我们回顾了两个最常用的下界:Jensen-Shannon估计[105]和噪声对比估计(InfoNCE[13])。
4.4.1 JS估计(Jensen-Shannon Estimator)
作为对SSL MI的估计,Jensen-Shannon散度(JSD)最早出现在DGI[15]中。与Donsker-Varadhan估计[106]提供MI的严格下限相比,JSD可以更有效地优化并保证稳定的性能(有关JSD如何估计MI的详细导数,请参阅[107])。它在图场景中应用广泛,可以表示为:<br /> (28)<br />其中表示和的联合分布,表示边缘分布的乘积。鉴别器可以以多种形式实现。文献[15]中的标准实现是称为双线性评分函数,直接应用于[73]、[75]。在[28]、[98]中,使用了它的点积形式,并显示出类似的性能。
4.4.2 噪声对比估计(Noise-Contrastive Estimator)
InfoNCE[13]公式遵循基于Softmax的NCE[108]版本,以在一组负样本中识别正样本。还证明了最小化InfoNCE损失等价于最大化MI的下界,[107]发现在CV任务中使用InfoNCE通常比使用JSD更好。作为SSR中最常见的对比损失,它被表述为:<br /> (29)<br />其中,是的负样本集,并且通常在一批次中被采样。当时,它也被称为NT-Xent损失[10],其中是温度(例如,0.2),这是它的公认版本。<br /> 尽管InfoNCE是有效的,但它在SSR中的行为还没有引起足够的重视。Wang和Isola[109]指出了与InfoNCE(NT-Xent损失)有关的两个关键性质:正对表示的对齐(接近)和超球面上归一化表示的一致性。通过重写等式(31)的NT-Xent版本,我们可以获得:<br /> (30)<br />其中,第一项对应于对齐,第二项对应于给定归一化的超球面上样本向量的一致性。在SSR中,也有少数工作报道了它们的存在。Qiu等人[79]和Yu等人[101]证明了优化InfoNCE损失可以学习项目/节点表示的更均匀分布,这可以缓解顺序推荐中的表示退化问题,并解决基于图的推荐中的流行度偏差[110]。此外,Wang和Liu[111]证明了InfoNCE损失是硬感知的,并且温度控制着对困难负样本的惩罚强度。[30]在应用于推荐时也提到了这种性质。<br /> 同时,InfoNCE损失也存在一个值得注意的潜在缺陷。对于输入中的每个实例,InfoNCE将其从其他实例中推开,除了其在表示空间中的增强对应物。然而,相似的用户/项目广泛存在于推荐系统中。因此,许多语义相似的实例与不相关的实例混合在一起,作为false负样本反馈给损失,这将影响推荐性能。为了解决这个问题,受[112]的启发,一些工作[79]、[56]、[55]提出将多个正样本合并到InfoNCE损失中,从而引入定义为:<br /> (31)<br />Qiu等人[79]提出通过检查两个序列是否具有相同的预测项目来识别语义正序列。Yu等人[56]和Xia等人[55]在语义相似的图上构建多个编码器来预测给定实例的正例。
4.5 优缺点(Pros and Cons)
由于可以灵活地增强数据和设置辅助任务,对比式方法在最近几年迅速发展,覆盖了大多数推荐主题。虽然还没有报道表明对比SSR相对于其他SSR范型具有压倒性的优势,但它在改进轻量级体系结构的推荐方面表现出了显著的效果。然而,它经常受到**高质量数据增强的未知标准**的影响[59]。现有的对比式方法大多基于任意的数据增强,并且是通过反复试验来选择的。既没有对它们如何起作用以及为什么起作用的严格理解,也没有规则或准则明确说明什么是好的补充提出。此外,一些被认为有用的常见增强最近甚至被证明对推荐性能有负面影响[101]。因此,在不知道哪些补充信息的情况下,对比任务可能达不到预期。
5 生成式方法(Generative Methods)
生成式SSR方法的思想是通过对原始输入进行重构,将数据中的内在相关性进行编码,从而使推荐任务受益。在本节中,我们主要关注基于MLM的生成SSR方法,这是当前的趋势之一。根据重构目标,我们将生成SSR方法分为两类:结构生成和特征生成。表2根据场景、数据增强方法、训练模式等条件列举了多种SSR方法。<br />**表2 生成自监督推荐研究综述**<br />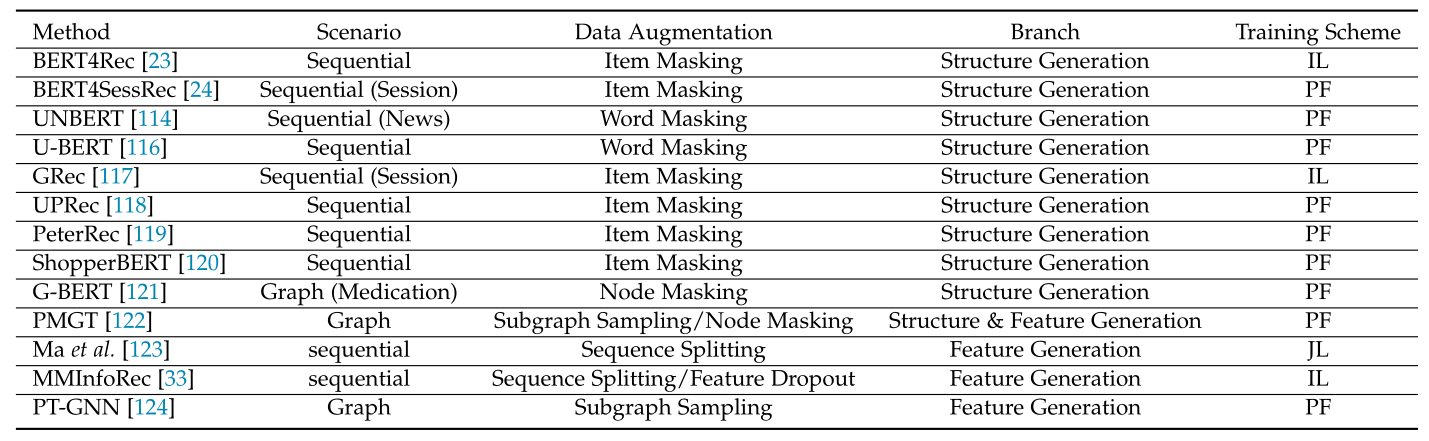
5.1 结构生成(Structure Generation)
此方法分支利用结构信息来监督模型。通过将基于掩蔽/丢弃的增强算子(参见第3节)应用于原始结构,可以获得其损坏的版本。在基于序列的推荐场景中,结构恢复可以表示为:<br /> (32)<br />其中 表示损坏的序列,其中一部分项目被掩蔽(替换为特殊标记[mask])。<br /> BERT4Rec [23]是BERT [12]在顺序推荐中的第一个实例化(BERT4SessRec[24]是一个几乎相同思想的并发作品)。它升级了SASRec [113]中的从左到右训练方案,并提出学习双向表示模型。在技术上,它随机屏蔽输入序列中的一些项目,然后根据它们周围的项目预测那些被屏蔽项目的id。为了使预测阶段与训练阶段一致,它在输入序列的末尾附加了标记[mask],以指示要预测的项目。该目标被表述为:<br /> (33)<br />其中是的损坏版本,是随机掩码项目,是真正的掩码项目。这一损失被广泛应用于BERT类生成SSR模型,作为其生成辅助任务的优化目标。<br /> 受BERT4Rec成功的启发,后续工作将掩蔽项目预测训练应用到更具体的场景中。**UNBERT**[114]和Wu et al.[115]以几乎相同的方式探索该技术在新闻推荐中的使用。UNBERT的输入是带有一组特殊符号的新闻句子和用户句子的组合。它随机屏蔽一些单词块标记,用完形填空任务对标记表示进行预训练,然后在新闻推荐任务中对模型进行微调。另一个类似的工作**U-BERT**[116]使用评论评论在源域中使用掩蔽单词-令牌预测来预训练编码器,然后在目标域中使用评论不足以进行评级预测的附加层来微调编码器。**GREC**[117]开发了一种具有编码器-解码器设置的间隙填充机制。编码器将部分完整的会话序列作为输入,解码器根据编码器的输出和自身的完全嵌入来预测被掩蔽的项目。**UPRec**[118]进一步修改了BERT4Rec,使其能够利用用户属性和社交网络等异质信息来增强序列建模。<br /> 虽然上述生成模型已经取得了很好的效果,但它们主要是针对一种类型的推荐任务进行预训练的。还有一项研究的目标是通过生成性预训练[125]、[119]、[120]学习通用表征,从而使多个下游推荐任务受益。**PeterRec**[119]首次尝试将由掩蔽项目预测预训练的模型参数转移到用户相关任务。它不对预训练的参数进行微调,而是将一系列小的嫁接神经网络注入到预训练的原始模型中,并只训练这些补丁以适应特定的任务。同样,**ShopperBERT**[120]被预训练了9个生成性辅助任务,包括掩蔽-购买-预测,学习的通用用户表示可以服务于6个下游推荐相关任务。得益于大规模的预训练数据集,它显示出了比从零开始学习的基于特定任务的Transformer模型的优越性。<br /> 在基于图的推荐场景中,结构生成式方法表示如下:<br /> (34)<br /> **G-BERT**[121]结合了GNNs和BERT的功能,用于药物推荐。它将电子健康记录中的诊断和药物代码建模为两个树状图,并使用GNNs学习图表示。然后将表示反馈给BERT编码器,并使用两个生成性辅助任务进行预训练:自预测和双重预测。自预测任务用相同类型的图重建掩码,而对偶预测任务用另一种类型的图重建掩码。**PMGT**[122]使用采样子图执行图重建任务。提出了一种对每个项目节点采样子图的采样方法,并根据邻域重要性将采样子图重新组织为有序序列。然后,子图被馈送到基于Transformer的编码器,并且该方法使用缺失的相邻项目预测来预训练项目表示。
5.2 特征生成(Feature Generation)
特征生成任务可以表示为:<br /> (35)<br />其中是MSE损失,而是特征的一般表达式,这些特征可以是用户简档属性、项目文本特征或学习的用户/项目表示。<br /> 在**PMGT**[122]中,除了图重建任务外,特征重建任务也被用来获得基于Transformer的推荐模型。该方法预先提取物品的文本和图像特征,并用提取的特征初始化项目嵌入。然后,它屏蔽部分采样节点,并使用其余节点来恢复被屏蔽节点的特征。对于序列特征的生成,Ma等人[123]提出用过去的行为重建未来序列的表征。具体地说,它们解开任何给定行为序列背后的意图,并在涉及共同意图的任何对子序列之间进行重建。类似地,在**MMInfoRec**[33]中,给定具有t个项目的序列,它对该序列进行编码并预测在时间步长的下一项目的表示。然后将扩展的序列表示与真实的项目的表示(GROUAL-TRUE)进行对比。自回归预测模块被设计为通过预测具有项目到项目的项目来包括更多的未来信息。在编码器中使用了丢弃函数来创建多个语义相似的项目表示,以改进CL。<br /> 为了增强冷启动用户和项目的表示,**PTGNN**[124]提出通过模仿元学习设置来预训练GNN模型。该算法选取交互程度较高的用户/项目作为目标用户/项目,对采样到的K个邻域进行图卷积运算,预测目标在整个图中的真实嵌入情况。对重构损失的优化直接提高了模型的嵌入能力,使得模型能够方便、快速地适应冷启动的用户/项目。
5.3 优缺点(Pros and Cons)
最新的生成式SSR方法大多遵循掩蔽语言模型的pipeline。依靠这一标准pipeline和Transformer的能力,这些方法都取得了显著的效果。BERT在大规模语料库上的成功训练经验也为基于MLM的大型推荐模型的应用铺平了道路。然而,这一分支方法可能会面临繁重的计算挑战。由于大多数开源数据集的规模较小,基于Transformer的生成式方法通常采用一层或两层的设置。然而,当使用大规模数据集进行新闻推荐或通用表示的训练时,计算量非常大。特别是,考虑到扩大预训练数据集确实有所帮助,将在性能和高计算开销之间存在两难选择,特别是对于计算资源有限的研究组。
6 预测式方法(Predictive Methods)
与破坏原始数据以获得自监督的生成式SSR方法不同,预测式SSR方法是从完整的原始数据中获得的自生成的监督信号进行处理。根据预测任务预测的内容,我们将预测式方法分为两个分支:**样本预测**和**伪标签预测**。表3根据场景、数据增强方法、训练模式等条件列举了多种SSR方法。<br />**表3 预测式自监督推荐研究综述**<br />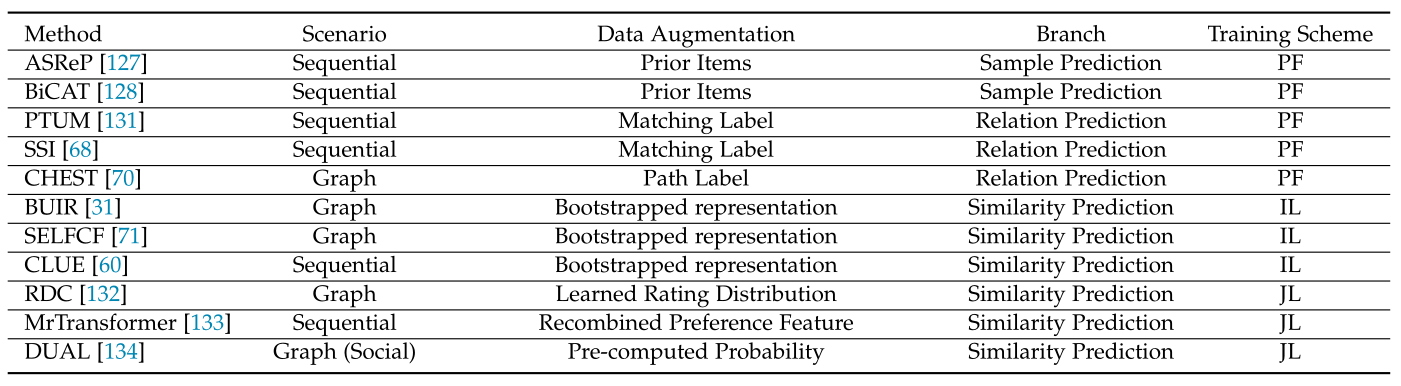
6.1 样本预测(Sample Prediction)
在这个分支下,自训练[126](一种半监督学习的风格)与SSL联系在一起。SSR模型首先用原始数据进行预训练。该模型根据预训练好的参数,预测出对推荐任务有用的潜在样本。获取的样本作为增强的数据,然后被馈送到模型以增强推荐任务或递归地生成更好的样本。基于SSL的样本预测与纯自训练的不同之处在于,在半监督学习环境下,有限数量的未标记样本是准备好的,而在SSL设置下,样本是动态生成的。<br /> 由于有限的用户行为,序贯推荐模型在短序列上的性能往往很差。为了提高模型的性能,**ASReP**[127]提出用伪先验项来增强短序列。按照从左到右的时间顺序给出序列,ASRep首先以相反的方式(即,从右到左)预训练基于Transformer的编码器SASRec[113],以便编码器能够预测伪随机数项。然后,它获得增强序列(例如,),其中所构建的子序列被附加到原始序列的开头。之后,编码器以从左到右的方式对增强序列进行微调,以预测原始序列中的下一项目。后续工作**BiCAT**[128]认为,反向增强可能与原始关联不一致。它还提出同时从左到右和右向左向右方向对编码器进行预训练。双向训练可以弥合反向增强和前向推荐之间的差距。该方法中的这种反向增加是以自训练方式递归地生成并馈送到编码器的。<br /> 在图场景中,还可以基于节点特征/语义相似度来预测样本。当存在建立在不同图上的多个编码器时,它们可以递归地预测用于其他编码器的样本,其中自训练升级为联合训练[129]。在**SEPT**[56]和**COTREC**[55]中,提出了这样的想法。我们在第7节中介绍它们,因为这些方法组合了多个辅助任务。
6.2 伪标签预测(Pseudo-Label Prediction)
在该分支下,伪标签以两种形式呈现:预定义的离散值和预计算/学习的连续值。前者通常描述两个对象之间的一种关系。相应的辅助任务的目标是预测在给定的对象对之间是否存在这样的关系。后者通常描述给定对象的属性值(例如,节点度[130])、概率分布或特征向量。相应的辅助任务旨在最小化输出和预计算连续值之间的差异。我们可以将这两个预测任务制定为:关系预测和相似性预测。
6.2.1 关系预测(Relation Prediction)
关系预测任务可以被描述为一个分类问题,其中作为伪标签的预定义关系是自动自生成的,而不需要任何代价。我们可以定义等式(4)为这一方法分支提供如下表述:<br /> (36)<br />其中和是来自的一对对象,是类别标签生成器,是交叉熵损失。<br /> 受BERT[12]中的下一句预测(NSP)(即预测句子B是否在句子A之后)的启发,一些预测性的自监督序列推荐模型提出了预测两个序列之间的关系的方法。**PTUM**[131]复制了ERT中的NSP,将一个用户行为序列分成两个互不重叠的子序列,分别表示过去的行为和未来的行为。然后,它根据过去的行为预测候选行为是否是未来的行为。**SSI**[68]用打乱/替换给定序列中的一部分项的辅助任务来预训练基于Transformer的推荐模型,然后预测修改后的序列是否处于原始顺序/来自同一用户。<br /> 在图的场景中,伪关系通常是通过随机游走来建立的。**CHEST**[70]提出在异构用户-项目图上进行预定义的基于元路径的随机游走,以连接用户-项目对。它将元路径类型预测作为一项预测任务,对基于Transformer的推荐模型进行预训练。给定一个用户-项目对,辅助任务将预测它们之间是否存在特定元路径的路径实例。
6.2.2 相似性预测(Similarity Prediction)
相似性预测任务可以被描述为一个回归问题,其中预先计算/学习的连续值作为模型输出需要近似的目标。我们可以定义等式(4)为这一方法分支提供如下表述:<br /> (37)<br />其中是生成目标的标签生成器。它可以是学习目标的编码器,也可以是预计算目标的一系列动作。<br /> **BUIR**[31]是一种具有代表性的预测SSR方法,它模仿视觉模型BYOL[9],依靠两个不对称的图编码器,称为在线网络和目标网络,在没有负采样的情况下相互监督。给定用户-项目对,在线网络被馈送用户表示,并被训练以预测目标网络输出的项目表示,反之亦然。通过这种方式,BUIR通过boostrapping表示来完成自监督,这意味着使用估计值来估计其目标值。具体地说,在线网络以端到端的方式更新,而目标编码器通过基于动量的移动平均来更新以慢慢逼近在线编码器,这鼓励提供增强的表示作为在线编码器的目标。**SelfCF**[71]继承了BUIR的优点,并通过在两个网络中只使用一个共享编码器来进一步简化它。为了获得更多的监督信号来学习区分表示,它对目标网络的输出进行扰动。另一个非常类似的**CLUE**[60]是BYOL[9]在顺序推荐中的实例化,它也使用一个共享编码器。SELFCF和CLUE之间的主要pipelines区别在于,CLUE增加了输入,而SELF增强了输出表示。<br /> 相似度预测也用于缓解推荐系统中的选择偏差[39]。在**RDC**[132]中,定义了两种类型的用户,它们是随机选择和评分项目的枢纽用户和更有可能对他们强烈喜欢或不喜欢的项目进行评级从而获得有偏见的推荐的非枢纽用户。RDC强制非枢纽用户的评分分布特征与其相似枢纽用户的评分分布特征接近,以纠正偏差,其中评级分布特征是动态计算的,并作为自监督信号。这样的任务还用于用户偏好解缠[135]。在**MrTransformer**[133]中,给定一对代表两个用户的序列,每个用户偏好表示被分成两部分:公共偏好表示和唯一偏好表示。然后,该方法交换公共偏好表示以重新组合用户偏好表示,并且要求重新组合的偏好应尽可能类似于原始偏好表示,以便模型能够学习如何识别和编辑用户偏好,以便学习更具区别性的用户表示。<br /> 当涉及到异质信息图时,相似度预测任务也可以用来捕捉丰富的语义。在**DUAL**[134]中,进行连接用户-项目对的基于元路径的随机游走。对于每个用户-项目对,元路径实例的数量被记录和缩放以测量该对的交互概率。然后,分配路径回归辅助任务来预测预先计算的概率,并期望将路径语义整合到节点表示中以增强推荐。
6.3 优缺点(Pros and Cons)
与主要依赖静态增强算子的对比式方法和生成式方法相比,预测方法以更动态、更灵活的方式获取样本和伪标签。特别是,基于进化的模型参数来预测样本,这直接细化自监督信号并使其与优化目标一致,可能会导致更好的推荐性能。然而,我们也应该**谨慎使用预增强标签**。现有的大多数方法都是基于启发式算法来收集伪标签,而没有评估这些标签和预测任务与推荐的相关程度。考虑到用户-项目交互和相关联的属性/关系产生的原理(例如,社会动态),有必要将专家知识作为先验并入伪标签集合,这增加了开发预测性SSR方法的费用。
7 混合式方法(Hybrid Methods)
混合式方法将多个辅助任务组合在一起,充分利用不同类型的监督信号。我们根据他们的辅助任务功能将调研的混合式方法分为两组,包括**协同式**的和**独立式**的。表4根据场景、数据增强方法、训练模式等条件列举了多种SSR方法。<br />**表4 基于混合辅助任务的自监督推荐方法综述**<br />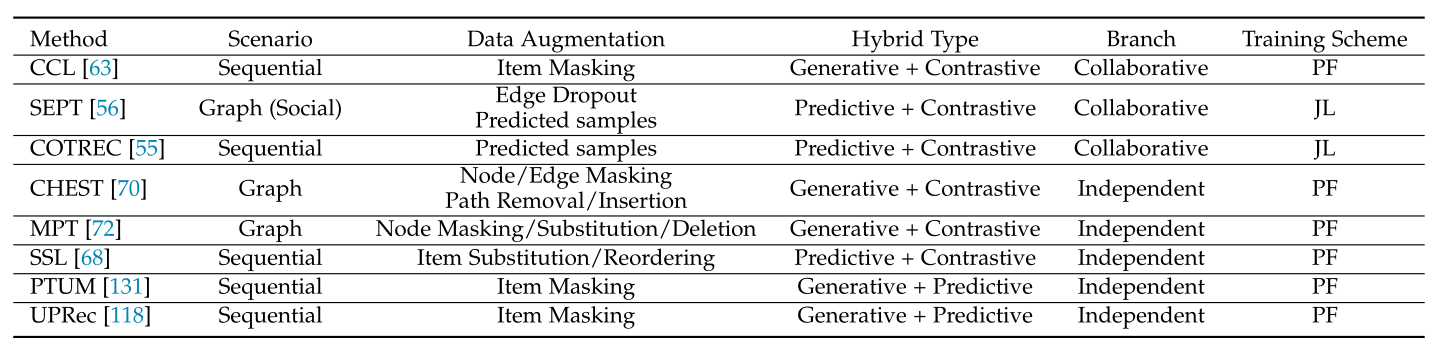
7.1 协同方法(Collaborative Methods)
在这一分支下,不同的辅助任务以一种方式进行协同,其他辅助任务通常通过创建更多信息样本来服务于对比辅助任务。<br /> **CCL**[63]提出了一种课程学习[136]策略,通过将生成性辅助任务与用于顺序推荐的对比辅助任务链接起来,对基于Transformer的模型进行预训练。在给定序列的情况下,生成任务是针对掩蔽项目预测的。利用预测的概率,该方法对项目进行采样以填充用于序列增强的被屏蔽部分。然后,这些增强的序列被馈送到对比任务,以与原始序列进行对比。根据增强序列恢复用户属性信息的能力,将其划分为N个库,进行由易到难的对比课程安排。<br /> 预测性任务也可以服务于下游的对比任务。**SEPT**[56]是第一个SSR模型,通过基于样本的预测任务进行社会推荐,将SSL和Tri-Trading[137](一种特殊类型的半监督学习)结合起来。它在三个具有不同社会语义的视图上构建了三个图编码器(一个用于推荐),任何两个编码器都可以为REST编码器预测语义相似的样本。这些样本作为补充的积极自监督信号被结合到链接的对比任务中,以改进编码器。改进的编码器依次递归地预测更多信息样本。**COTREC**[55]遵循SEPT的框架,将基于会话的推荐使用的编码器数量减少到两个。这两个编码器建立在两个会话诱导的时态图上,并通过对比任务迭代地预测样本以提高彼此的性能。为了防止基于两个编码器的联合训练中的模式崩溃问题[129],它对两个编码器施加了发散约束,通过利用对立的例子来保持它们略微不同[138]。
7.2 独立方法(Independent Methods)
在这一分支下,不同的辅助任务之间没有相关性,它们独立工作。<br /> 与CCL[63]类似,**CHEST**[70]还将课程学习与SSL连接起来,在异构信息网络上预训练一个基于Transformer的推荐模型。然而,它的辅助任务是未连接的。给定用户-项目图和相关属性,CHEST进行基于元路径的随机游走,从一个用户节点开始,到一个项目节点结束,以形成特定于交互的子图,每个子图由多个元路径实例组成。CHEST中的生成任务利用局部上下文信息预测子图中被屏蔽的节点/边,被认为是初级课程。对比任务通过拉近原始子图和增强子图来学习用户-项目交互的子图级别的语义,这利用了全局相关性,被认为是高级课程。**MPT**[72]对PT-GNN[124]进行了扩展,它只考虑了生成性辅助任务中用户和项目子图之间的内在联系,从而增强了冷启动推荐的表示能力。为了捕获不同子图之间的相互关联,它添加了在图和基于随机行走的序列上执行的对比辅助任务,其中节点删除/替换/掩蔽用于增加数据,用于训练基于GNN和Transformer的编码器。对比任务和生成任务按照各自的参数并行进行。最后,对参数进行合并和微调以用于推荐。<br /> 除了生成任务和对比任务的组合外,**SSI**[68]还组合了一个基于标签的预测任务和一个对比任务来预训练模型以进行顺序推荐。给定一个序列,通过预测学习施加两个一致性约束:时间一致性和角色一致性。为了实现时间一致性,这种方法需要预测输入序列是按照原始顺序还是被打乱。为了人物角色的一致性,需要区分输入序列是来自某个用户,还是一些项目被不相关的项目所替代。同时,在被屏蔽的项目表示和序列表示之间进行基于项目掩蔽的对比。至于生成性和预测性任务的结合,**PTUM**[131]模仿Bert[12]进行掩蔽项目生成任务和下一项目预测任务。此外,**UPRec**[118]将BERT与异构用户信息联系起来,并用社会关系和用户属性预测任务并行地对编码器进行预训练。
7.3 优缺点(Pros and Cons)
混合方法将多个辅助任务组合在一起,因此可以获得增强和全面的自监督。特别是,对于协同分支下的方法,其中生成/预测任务通过动态地产生用于对比的样本来服务于对比任务[56]、[55]、[136],它们在训练有效性方面比它们的静态对应任务具有明显的优势。然而,混合方法面临着**协调多个辅助任务**的问题。对于独立分支[72]、[68]下的方法,它们很难在不同的辅助任务之间进行权衡。需要通过反复试验或昂贵的超参数领域知识进行繁琐的手动搜索。此外,不同的辅助任务也可能相互干扰,这可能需要具有更多参数的更重的体系结构,如多门专家混合网络[139],以分离共享任务和特定任务信息。因此,与只有一个辅助任务的模型相比,强混合SSR模型的训练成本更高。
8 SELFRec:自监督推荐系统开源库
SSR现在正处于一个繁荣期,越来越多的SSR模型被开发出来并声称自己是最先进的。尽管数量在不断增加,但我们注意到,在收集的论文中,不同SSR模型之间的实证比较往往是不公平的。此外,这些方法的一些代码实现效率低下,可读性差。虽然已经有一些开源知识库,如RecBole[140]和QRec[56],实现了一些具有统一框架的SSR模型,并提供了标准的评估指标,但它们的设计涵盖了所有类型的推荐模型,其体系结构对于实现SSR模型效率不高。为了方便SSR模型的开发和标准化评估,我们发布了一个开源的库-**SELFRec**,它继承了RecBole和QREC的优点,其架构如图6所示。<br />**图6 SSR库-SELFRec的体系结构**<br />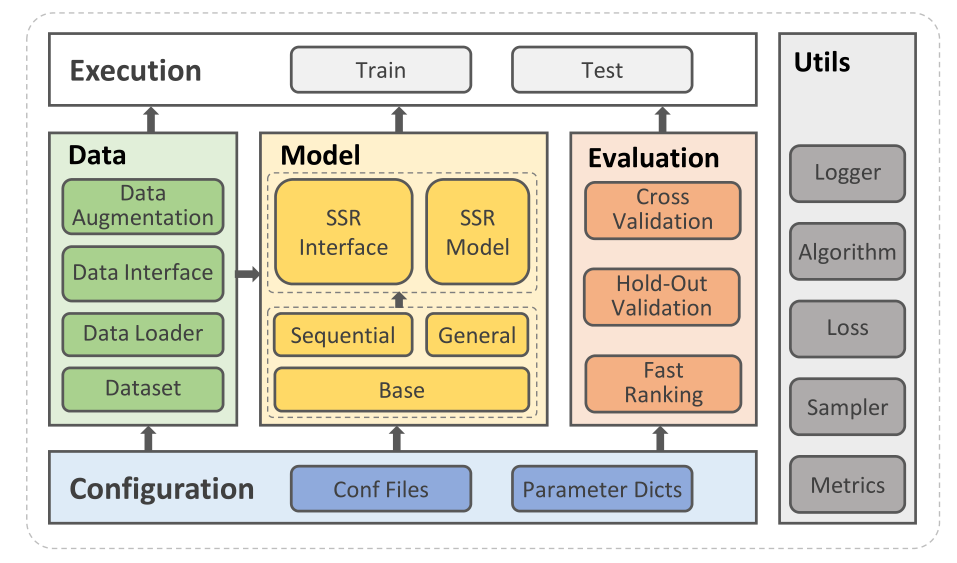<br /> 在SELFRec中,我们整合了多个高质量的数据集,这些数据集在调查的论文中广泛使用,如Amazon-Book[30]、Yelp-2018[87]和MovieLens1M,用于顺序和一般场景。综合了包括MRR@K和NDCG@K等排名指标和MSE和RMSE等评级指标在内的10多个指标。在SELFRec中实现了10多种最先进的SSR方法用于经验比较,如SGL[30]、CL4SRec[61]、DHCN[28]等。以下是SELFRec的一些重要特性:
- 快速运行(Fast Execution):SELFRec是用Python3.7+,TensorFlow 1.14+和Pytorch 1.7+开发的。所有型号都运行在GPU上。特别是,我们对耗时的项目排序过程进行了优化,将排序时间大幅减少到几秒钟。
- 易于扩展(Easy Expansion):SELFRec提供了一组简单和高级的接口,通过这些接口,可以轻松地以即插即用的方式添加新的SSR模型。
- 高度模块化(Highly Modularized):SELFRec分为多个独立的模块/层。这种设计将模型设计与其他程序分离。对于SELFRec的用户来说,他们只需要专注于他们的方法的逻辑,这将简化开发。
- 特定于SSR(SSR-Specific):SELFRec是为SSR设计的。对于数据增强和自监督任务,它提供了特定的模块和接口,便于快速开发。
由于篇幅有限,我们提出您参考SELFRec https://github.com/Coder-Yu/SELFRec 的主页了解使用方法和详细文档。
9 讨论(Discussion)
在这一部分中,我们分析了现有SSR的局限性,并概述了一些值得探索的有前途的研究方向。
9.1 数据增强选择的理论证明(Theory for Augmentation Selection)
数据增强是SSR的关键组成部分,对性能至关重要。现有的SSR方法绝大多数是通过模仿CV、NLP和图学习领域的方法来增强原始数据的。然而,这些方法不能无缝地移植到推荐中来处理与场景紧密耦合、含有噪声的和随机性的用户行为数据。此外,大多数方法都是基于启发式算法对数据进行增强,通过繁琐的试探法寻找合适的增强。虽然已经有一些理论试图揭开对比学习中视觉视角选择的神秘面纱[141],[59],但对推荐中的增强选择原则的研究却很少。因此,迫切需要一个坚实的推荐具体理论基础,以简化选择过程,将人们从繁琐的试错工作中解放出来。
9.2 基于自监督推荐系统的可解释性(Explainable Self-Supervised Recommendation)
尽管现有SSR模型具有理想的性能,但在大多数SSR模型中,导致这些性能提高的原因在理论上是不合理的。它们被认为是黑箱模型,它们的目标只是为了达到更高的性能。有些组成部分,如辅助任务的补充和目标,被认为是有用的,但缺乏可靠的可解释性来证明其有效性。在最近的一项研究[101]中,实验证明,一些过去被认为是信息性的图增强,甚至可能会损害性能。同时,在没有可靠的解释的情况下,尚不清楚这些模型是否以鲁棒性等其他属性来换取性能改进。对于更可靠的SSR模型,有必要弄清楚他们学到了什么,或者模型通过自监督训练发生了怎样的变化。
9.3 基于预训练推荐模型中的攻击与防御(Attacking and Defending in Pre-trained Recommendation Models)
由于开放性,推荐器系统容易受到数据中毒攻击,数据中毒攻击将故意制作的用户-项目交互数据注入模型训练集,以篡改模型参数并按照期望操纵推荐结果[142],[143]。监督推荐系统的攻击和防御方法已经得到了很好的研究。然而,目前尚不清楚以自监督的方式预训练的推荐模型是否对此类攻击具有鲁棒性。我们还注意到,一些开创性的工作已经尝试在视觉和图分类任务中攻击预训练的编码者[144],[145]。我们相信,开发新型的攻击和防御自监督的预训练的推荐系统来抵御这些攻击将是一个有趣的未来研究方向。
9.4 移动边缘设备上的自监督推荐模型(On-Device Self-Supervised Recommendation)
现代推荐系统以完全基于服务器的方式运行,以迎合数百万用户,这是以巨大的碳足迹为代价的,并引发了隐私问题。部署在智能手机等资源受限设备上的分布式推荐系统[146]、[147]已变得越来越流行。然而,设备上的推荐系统受到高度收缩的模型大小和有限的标签数据的影响。对于这些问题,SSL可能是一个潜在的解决方案。具体地说,当与知识蒸馏[148]、[149]技术相结合时,SSL可以在很大程度上补偿设备上推荐模型的准确性下降。目前,设备上的自监督推荐还没有被探索,我们认为它值得进一步的研究。
9.5 通用预训练方法(Towards General-Purpose Pre-training)
在行业中,推荐系统中的数据是多模态的,场景也是多种多样的。针对不同的推荐任务,跨不同的模态(例如,视频、图像、结束文本)训练各种深度推荐模型[150]。训练和任务通常是相互独立的,消耗了大量的计算资源。由于不同模态的数据通常是相关的,因此探索通用的推荐模型是很自然的,这些模型是在大规模数据上用多模态SSL预训练的,并且能够以廉价的微调来适应多个下游推荐任务。特别是,对于训练数据非常稀疏的新任务或场景,从其他通道转移监督真的很有帮助。虽然已经有一些开发通用推荐模型的工作[120],[125],但它们都是以类似于BERT的方式用相似的架构训练的。寻求更有效的训练策略和更有效的模型架构具有重要意义。
10 结论(Conclusion)
在这次综述中,我们及时和系统地回顾了关于SSR的研究成果。具体来说,我们首先给出了SSR的定义,在此基础上我们查阅了大量相关文献,并将现有的SSR研究分为四类:对比式、生成式、预测式和混合式。对于每一类,依次介绍其概念和公式、涉及的方法以及优缺点。此外,为了便于SSR的开发和评估,我们发布了一个开源的库,其中包含了通用的基准数据集和指标,并实现了一些最先进的SSR方法进行实证比较。最后,我们指出了目前研究工作中的局限性,并概述了一些有希望的未来研究以促进SSR。

若有收获,就点个赞吧
0 人点赞
