Unify Local and Global Information for Top-N Recommendation
- Xiaoming Liu, Shaocong Wu, Zhaohan Zhang, et al. Unify Local and Global Information for Top-N Recommendation[C]. In SIGIR 2022.
-
摘要(Abstract)
知识图谱(KG)整合了复杂的信息,包含了丰富的语义,被广泛认为是增强推荐系统的辅助信息。然而,现有的基于KG的方法大多集中于对图中的结构信息进行编码,而没有利用用户-项目交互数据中的协同信号,而这些信号对于理解用户偏好是非常重要的。因此,这些模型学习的表示不足以表示推荐环境中用户和项目的语义信息。这两种数据的结合为解决这一问题提供了很好的机会,但面临着以下挑战:1)用户-项目交互数据中的内在关联很难从用户或项目的一侧捕捉;2)捕获整个KG上的知识关联会引入噪声,并对推荐结果产生不同程度的影响;3)两种数据之间的语义鸿沟很难消除。<br /> 为了弥补这一研究空白,我们提出了一种新的Duet表示学习框架KADM,用于融合局部信息(用户-项目交互数据)和全局信息(外部知识图谱)用于Top-N推荐,该框架由两个独立子模型组成。一种是通过知识感知的协同注意机制发现局部信息中的内在关联来学习局部表征,另一种是通过关系感知注意网络对全局信息中的知识关联进行编码来学习全局表征。将这两个子模型作为语义融合网络的一部分进行联合训练,来计算用户偏好,从而区分这两个子模型在特定上下文下的贡献。我们在两个真实世界的数据集上进行了实验,评估结果表明,KADM的性能明显优于最新的方法。进一步的消融研究证实,Duet架构在推荐任务上的表现明显好于任一子模型。
关键词(Keywords)
推荐系统、Duet表征学习、协同信号、知识图谱、局部和全局信息
1 引言(Introduction)
随着互联网技术的快速发展,在线数据量急剧增加。海量的信息会让用户不堪重负,因此他们要在大量的选择中筛选出自己喜欢的信息是很耗时的。为了缓解这一影响,推荐系统已经成为一个重要的和不可或缺的工具来帮助用户作出决策。
1.1 前人的工作和局限性(Prior Works and Limitations)
推荐系统引起了广泛的研究兴趣,并得到了广泛的应用[33]。传统的协同过滤方法[12,48,57]已经取得了显著的成功,它们基于用户-项目交互数据提供推荐。然而,由于即使是最活跃的用户也只与推荐环境中的一小部分项目进行了交互,因此基于CF的方法通常存在数据稀疏性和冷启动问题[45]。同时,它们大多无法对交互数据中的协同信号进行彻底的编码,因为它们只能捕捉用户或项目的部分影响,并对用户与项目之间的浅层关联进行建模。为了解决这些问题,许多方法尝试利用不同类型的辅助信息(例如,项目描述[5]、用户简档[10]和社交网络[16])。例如,基于用户可能与其信任用户共享相似偏好的假设,提出了许多信任感知推荐方法[9,27]。<br /> 近年来,随着语义网的发展,将知识图谱作为辅助信息引入推荐系统引起了人们的广泛注意。与通常局限于捕捉具有同质信息特征的辅助信息(例如,社交网络)相比,KG是在统一的全局表示空间中连接与用户或项目相关的各种类型的特征的异构图[37]。KGs中的结构信息有助于从不同的角度探索用户或项目之间的潜在联系,这有利于提高推荐算法的性能[3,26,38,46,54]。然而,现有的基于KG的方法仍然存在一些共同的局限性:首先,大多数方法更多注意KG中的知识关联,而没有利用用户-项目交互数据,这不足以表示用户偏好;第二,大多数研究都是在全图上进行信息传播,这可能会引入不相关实体的负面噪声;第三,大多数工作平等地对待来自不同关系路径的信息,这与真实的推荐场景相反。
1.2 动机和关系(Motivations and Relations)
综合分析表明,用户-项目交互数据和KG可以从不同的角度反映人们的决策模式。具体地说,用户-项目交互中的协同信号可以从项目和用户两个层面引入两种效应。对于项目层面,用户倾向于购买与其历史物品相似的物品,这反映了历史不变和独立的用户偏好。另一方面,人们可能更倾向于选择其他用户经常购买的商品以及他们喜欢的商品。此外,KG中蕴含着丰富的知识关联,可以从属性层面表示用户或项目之间的语义关系。例如,如果两部电影有相同的导演或演员,看过一部电影的用户可能也愿意看另一部电影。此外,KG中还存在多种关系路径。不同的关系路径会对用户偏好产生不同程度的影响。例如,用户更可能从电影选角而不是导演的角度选择电影。<br /> 本文根据用户-项目交互数据和知识图谱的特征和对推荐的不同影响,将用户-项目交互数据和知识图谱分别定义为局部信息和全局信息,如图1所示。根据上述分析,这两种信息可以相互结合和补充,共同推断用户对目标项目的决策,但面临以下挑战:1)如何发现局部信息中用户与项目之间的内在关联?2)如何消除噪声三元组的负面影响并对全局信息中不同关系路径的影响进行建模?3)如何缓解局部信息和全局信息之间的语义鸿沟?<br />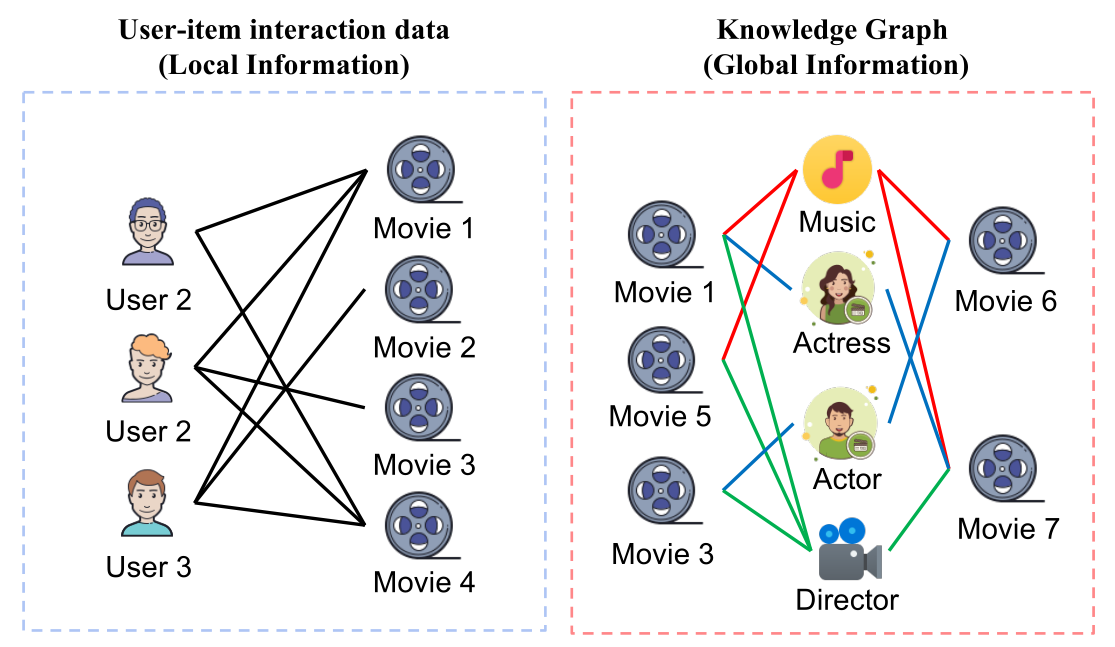<br />**图1 局部信息和全局信息的图解**。局部信息是用户-项目交互数据,这是一个包含用户、项目和交互的二部图。全局信息是一个具有多种关系和实体的异构知识图谱。
1.3 方法和结果(Methodologies and Results)
为了解决上述问题,我们提出了一种知识感知Duet模型(KADM),它由两个子模型组成,分别基于局部信息和全局信息来制定用户偏好:i)局部模型,通过在局部信息中编码协同信号来计算每个用户或项目的局部表示。它首先表示每个用户和项目与他们的协同邻居。其次,通过计算基于协同邻居的注意矩阵来获取内在关联性,进而通过池化操作得到注意向量。最后,通过从用户和项目两个方面聚合反映用户偏好的邻居表示来生成用户和项目的局部表示。ii)全局模型,它通过捕获全局信息中丰富的知识关联来学习每个用户或项目的全局表示。它首先从全局信息中提取用户-项目对的封闭子图。其次,用心聚合不同关系路径在子图中传播的语义信息来更新节点的表示。最后,通过将聚合特征与各自的特征相结合,生成用户和项目的全局表示。<br /> 然后,由于局部信息和全局信息可以相互补充,共同影响用户对目标项目的决策,并且它们的重要性对于不同的用户-项目对而言是不同的,因此我们利用门控网络来动态权衡这两个子模型,这对于控制网络中不同信息流的重要性是有用的,即这两个子模型被联合训练为门控网络的一部分。<br />本文的主要贡献概括如下:
基本概念(General Concepts):我们根据用户-项目交互数据的特征和对推荐的不同影响来区分用户-项目交互数据和KG的概念。然后我们将它们分别定义为局部信息和全局信息。
- Duet推荐体系结构(Duet Recommendation Architecture):我们提出了一种新颖的Top-N推荐的Duet体系结构模型,该模型利用全局和局部视图来研究用户偏好。在Duet推荐体系中,局部模型采用知识感知的协同注意机制,对局部信息中的协同信号进行编码来发现内在关联,而全局模型利用关系感知GNN来捕获从全局信息中提取的封闭子图中的知识关联。
- 门控网络语义融合(Gating network Semantic Fusion)。为了消除两类信息之间的语义鸿沟,基于线性单元的门控网络根据特定的上下文动态地权衡两种信息的不同影响。
出色性能(Outstanding Performance)。我们在两个真实世界的数据集上部署了KADM。实验结果证明了KADM的最新性能,所提出的组件的有效性,以及它对建模用户偏好的可能的可解释性。
2 相关工作(Related Work)
2.1 基于CF的推荐(CF-based recommendation)
协同过滤(CF)是推荐系统中广泛使用的一种技术,它利用用户项目反馈数据来对用户偏好进行建模。它主要包括基于邻域的方法[19,33]和矩阵分解方法[20,30]。最近,许多深度学习方法与新的深度学习技术相结合[7,55]。然而,虽然这些方法有时能达到较好的推荐效果,但大多数方法仍然存在数据稀疏和冷启动问题,并且只能建模用户与项目之间的浅层关系。
2.2 基于KG的推荐(KG-based recommendation)
知识图谱(KG)被广泛用作辅助信息来增强推荐系统,并取得了有效的效果。它主要包括三类,即基于嵌入的方法[15,42,56],基于路径的方法[11,14,35]和基于传播的方法[41,43,58]。其中,基于传播的方法通常可以通过递归地传播来自多跳节点的信息来改进整个KG上的用户和项目的表示,从而获得最先进的结果。例如,Wang等人[44]提出了协同知识图谱的概念,将用户行为和项目知识编码为一个统一的关系图,并进一步探索了协同知识图谱中语义关系的高阶连通性。MVIN[39]收集KG(用户视图)中的个性化知识信息,并进一步考虑各层(实体视图)之间的差异,以最终增强项目表示。CKAN[47]显式地编码用户-项目交互,并以端到端的方式将它们与知识关联自然地结合在一起。<br /> 与以往的方法相比,我们提出的模型有几个关键的优点:i)KADM将来自用户-项目交互数据的协同信号与知识关联以**双重结构**结合起来。这两种信息可以相互补充,以实现更好的推荐性能。ii)KADM采用关系感知的注意机制,捕捉信息传播过程中不同关系路径的各种影响,而以往的方法大多是基于节点的,并且平等对待。iii)KADM是基于从特定上下文中提取的封闭子图的计算,而大多数方法直接作用于整个图。它可以缓解传播过程中不相关节点的负面影响,减小图的大小以节省计算资源。
2.3 双重机制(Dual Mechanism)
现实生活中存在着许多双重现象,这些现象启发了模型设计中的几种双重结构。例如,Xia等人[50]提出了一个模型级的双重学习框架,将两个双重任务的训练融合在一起。DGCN[60]将GCN扩展到双重结构,共同考虑图中的局部一致性和全局一致性。Cheng等人[6]提出了一种用户和推荐项目双重嵌入的深层潜在因素模型DELF。DANSER[49]包括两个双重图注意网络,用于学习推荐系统中社会效应的深层表示。<br /> 与以前的方法相比,我们的模型有几个关键的区别:i)KADM为每种类型的数据设计了特定的子模型,而其他模型则使用子模型的对称结构。ii)在语义融合模块中,KADM动态权衡来自不同子模型的表示的重要性,而其他模型通常直接连接不同的特征向量。
3 问题描述(Problem Formulation)
假设有个用户和个项目,我们将历史数据表示为用户-项目交互矩阵,其中表示观察到的用户和项目之间的交互,例如,用户阅读书籍或用户点击新闻;否则。此外,我们在推荐过程中引入知识图谱作为辅助信息,其中每个三元组表示从头实体到尾实体存在关系,和是KG中的实体和关系的集合。<br />**输入Input**:用户-项目交互矩阵和知识图谱。<br />**输出Output**:提出了一种新的用于推荐任务的duet表示学习框架,用于正确预测用户将采用项目的概率。
4 方法(Methodology)
在本节中,我们将提供所提出的知识感知Duet模型KADM的细节,其框架如图2所示。提出的KADM模型由四个关键部分组成,用于彻底学习局部信息和全局信息的内在特征。首先,利用知识补充链接模块将项目映射到KG中的外部实体,以挖掘丰富的语义信息;然后,设计基于知识感知协同注意机制的局部模型和基于关系感知GNN的全局模型,分别从局部和全局信息中学习用户和项目的表示;最后,基于门控网络进行语义融合,以缓解这两种信息之间的语义鸿沟,并依次计算最终预测值。这一节的其余部分按照上述四个部分进行。<br />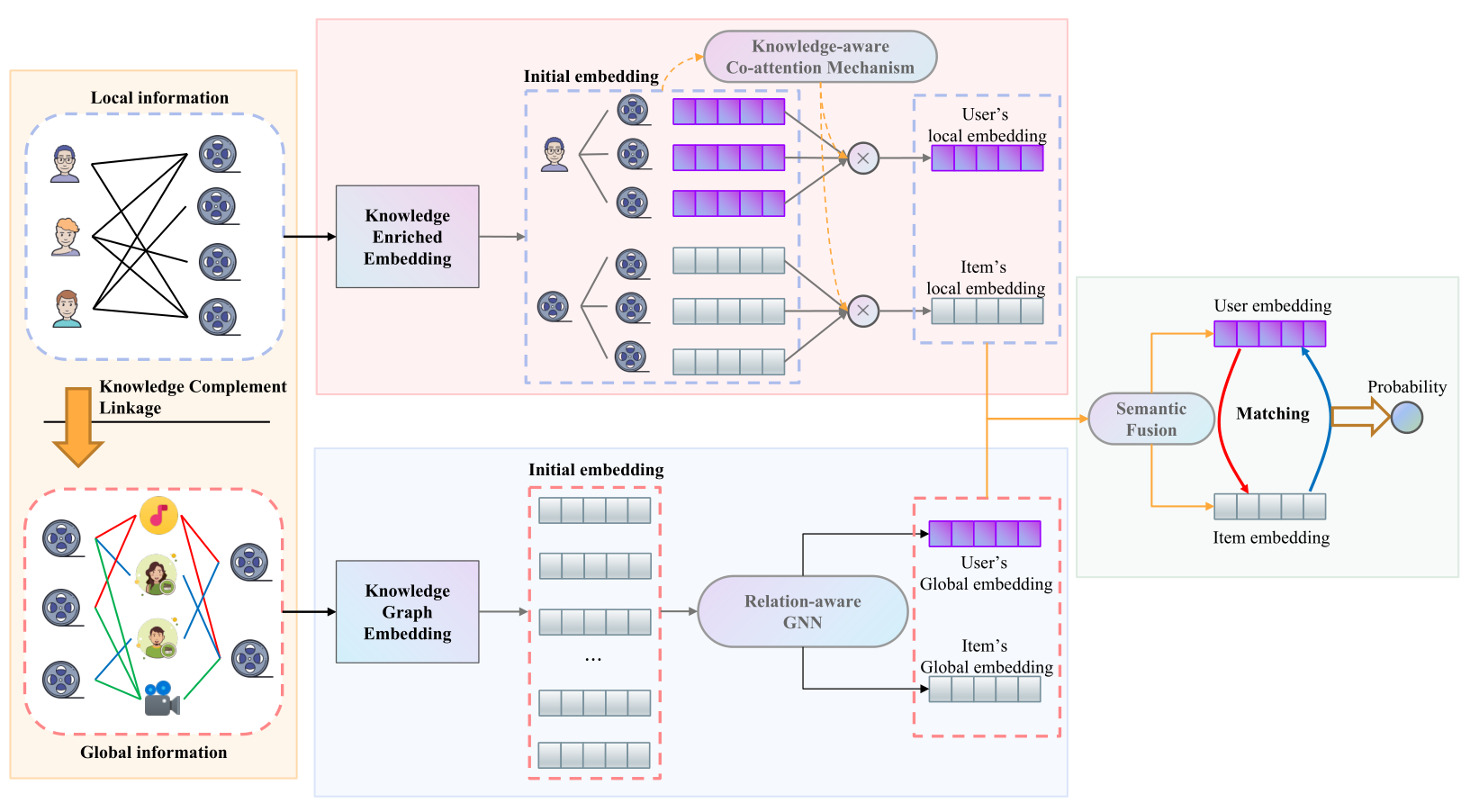<br />**图2 知识感知Duet模型图解**,它包括四个组成部分:i)知识补充链接(橙色背景,左),它将项目映射到外部实体,以捕获KG中丰富的语义信息。ii)局部模型(红色背景,中间),它从局部信息中学习用户和项目的局部表示。iii)全局模型(蓝色背景,中间),它基于全局信息学习用户和项目的全局表示。IV)预测(绿色背景,右),通过门控网络缓解局部和全局信息之间的语义鸿沟,并计算最终的预测概率。
4.1 知识补充链接(Knowledge Complement Linkage)
知识互补链接的目标是将每一个项目与其在KG中的对应实体链接起来。在这个过程中,我们首先利用实体链接[29,36]技术来检索带有项目标题的相关实体作为查询。有时,在链接过程中,一个项目可能返回多个实体。为了解决这个问题,我们进一步结合其他项目的属性信息来识别准确的链接实体(例如,IMDB ID和作者姓名分别用于电影和书籍)。基于链接结果,我们可以进一步提取每个实体及其中心子图的文本描述作为辅助信息,以增强推荐过程。例如,如图3所示,我们将标题Now You See Me作为查询,来检索在电影外部KG中的链接实体Now You See Me,并基于其链接的实体进一步提取文本描述和子图。<br />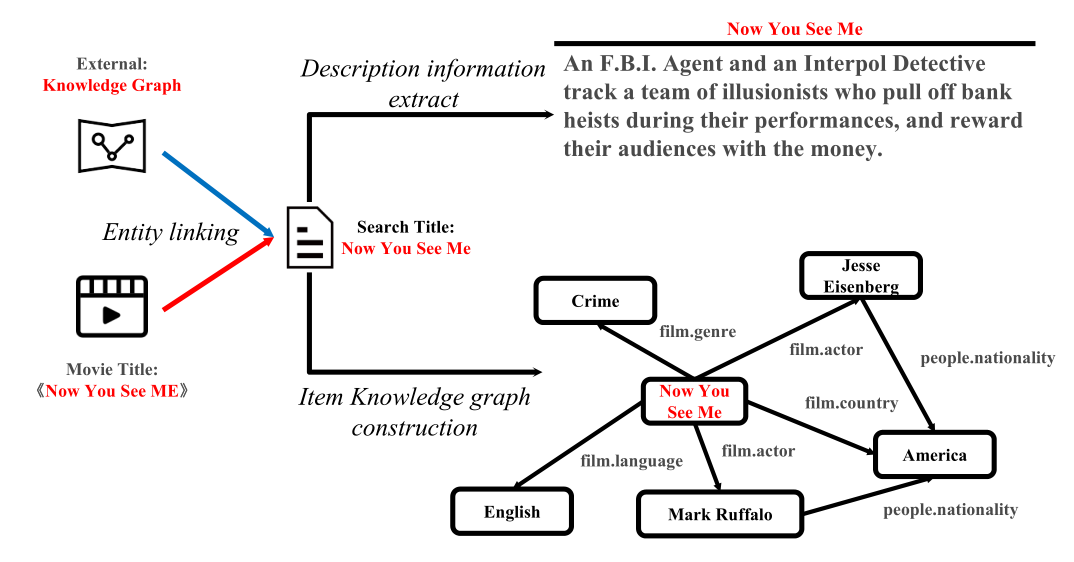<br />**图3 每一个项目知识补充链接过程**,包括实体链接、实体消歧、从外部KGs中提取项目描述信息和构建项目知识图谱。
4.2 局部表征学习模型(Local Representation Learning Model)
提出局部模型是为了基于局部信息探索项目和用户之间的内在联系。如图2所示,它主要包括三个部分:i)知识丰富表示(KEE),用于计算项目的初始表示;ii)用户和项目的编码,用于构建协同邻居集并计算初始表示矩阵;iii)知识感知协同注意机制(KCM),分别为每个用户和项目选择信息最丰富的局部邻居。<br />**知识丰富表征(Knowledge Enriched representation)(KEE)**。与以前的工作[13,56]使用一次性编码或随机生成表示不同,KEE用文本描述丰富了每个项目的初始表示,并且可以作为局部模型的一部分进行学习。<br /> 如图4所示,给定项目及其文本描述由单词序列组成,KEE首先使用表示层,该表示层使用查找表[51]将项目映射为表示,然后利用CNN模型来处理单词序列,这对于建模句子表示[17,52]表现得非常好。具体地说,它利用表示层将每个单词嵌入到中,使用CNN滤波器合成单词表示,并通过最大池化获得每个维度的最大值以生成描述表示,最后,它与项目表示结合学习具有两层DNN 的KEE表示。KEE的数学定义如下:<br /> representation Layer<br /> CNN <br /> Max-Pooling<br /> Description representation<br /> KEE representation<br /> 其中是表示层的参数,和是第个滤波器的权重和大小,是滤波器的数量,是串联运算符。此外,使用KEE,我们还可以使用冷启动项目的文本描述来获得没有交互信息的冷启动项目的初始表示。<br />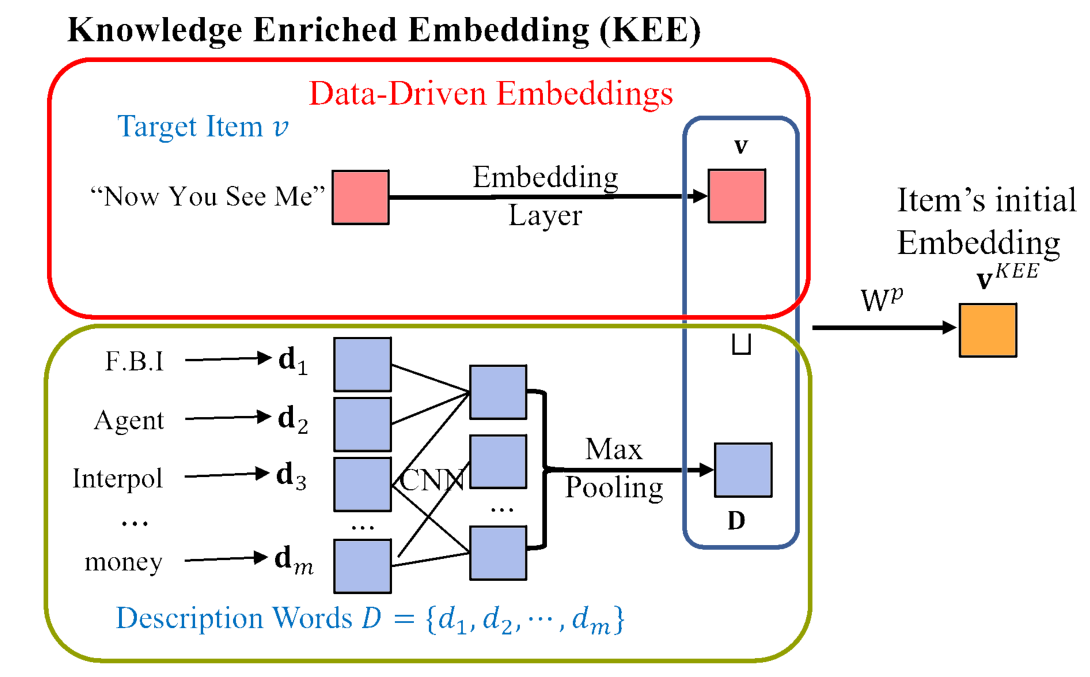<br />**图4 知识丰富表征(KEE)图解**。其生成具有其文本描述的项目的丰富表示。<br />**用户和项目编码(Encoding user and item)**。与传统上使用独立的潜在向量不同,我们用一系列相互作用的项目来表示每个用户,该序列可以定义为,其中表示每个用户的邻居集的大小。由于用户和项目之间的邻居分布不均衡,我们利用邻居选择方法来选择排名最靠前的邻居作为用户的邻居集合,该方法基于互信息[59]来对直接邻居进行排序。该方法的优点是可以减少邻域集合中的冗余,同时最大限度地保留所有邻域特征。<br />类似地,历史上与相同用户交互的项目可以被认为是彼此相似的,这可以被定义为协同邻居。与大多数现有方法不同的是,我们将每个项目表示为其协同邻居集,其中表示每个项目的邻居集的大小。在这个过程中,两个项目之间的相似性或相关性由与它们交互的普通用户来计算[49]。具体地说,对于任何项目对푣푖和푣푗,我们将它们的相似系数푠푖푗定义为与这两个项目交互的用户的比例。这些系数导致了项之间的等价关系,即项푣푖与项푣푗相关,如果푠푖푗>휏与휏具有固定的阈值。<br />对于局部信息中的协同信号的编码,不同于大多数考虑用户或物品的单方面影响的方法,我们分别用从局部信息中提取的历史邻居和协同邻居来表示每个用户和物品。具体地说,对于一个用户-项目对(푢,푣),我们可以将其表示为U∈R퐾×1和V∈R퐾×1,其中퐾是邻居集的大小。在KEE之后,我们将每个邻域变换为一个低维稠密向量。因此,我们将用户푢和项目푣的局部邻居编码为XU∈R퐾×푑和XV∈R퐾×푑,其中푑是表示的维度。<br />**知识感知协同注意机制(Knowledge-aware Co-attention Mechanism)(KCM)**。为了分别为每个用户和项目选择信息量最大的局部邻居,并生成更有意义的用户和项目的表示,我们提出了一个知识感知的共同注意模块,如图5所示。给定用户XU∈R퐾×푑和项目XV∈R퐾×푑的局部邻居表示矩阵,我们设计具有多层的注意力网络来计算注意力矩阵为<br /> (1)<br />其中是用户的第个邻居,是项目的第个邻居,而是计算出的它们之间的相关值。A包含不同协同邻居之间的内在关联。此外,我们通过对注意矩阵A沿列或行进行均值汇集操作来分别计算用户或物品的注意向量,该方法综合考虑了不同邻居的影响,<br /><br />其中和是用户和项目的重要性向量。然后,将重要性向量的归一化值作为权值,通过认真聚合邻域表示来计算局部表示。<br />其中是softmax函数,和分别是用户和项目的局部表示。<br />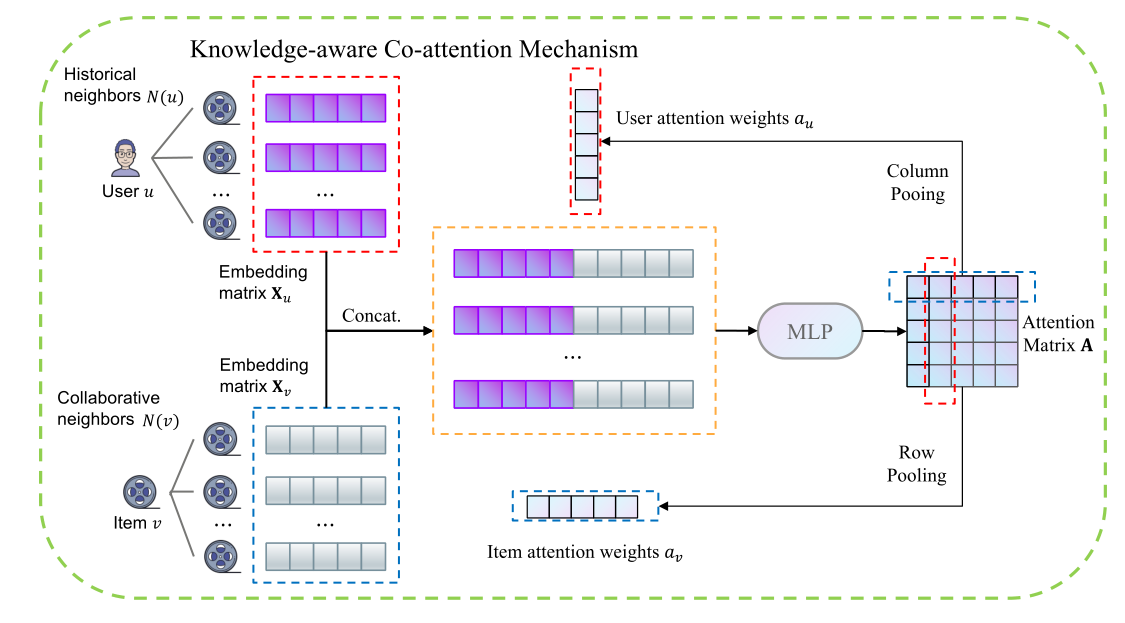<br />**图5 知识感知协同注意机制(KCM)图解**,其根据用户和项目的历史邻居和协同邻居计算对应的局部表示。
4.3 全局表征学习模型(Global Representation Learning Model)
不同于以往的大多数方法忽略不同关系路径的不同影响,在整个知识图的信息传播过程中可能会带来负面噪声,所提出的全局模型由三部分组成:i)封闭子图提取,从知识图中提取给定用户-项目对的封闭子图;ii)子图神经编码,为每个实体和关系学习一个低维表示向量,保留图的结构信息;iii)关系感知GNN,揭示关系路径在子图上信息传播过程中的不同重要性。
封闭子图提取(Enclosing subgraph extraction)。在这篇文章中,我们只考虑KG中特定三元组的邻域来消除传播过程中的噪声,而不是现有的方法来捕获整个图上的知识关联。为此,我们将封闭子图定义为出现在两个目标实体之间的路径上的所有实体所诱导的图。例如 是包含在
是包含在 周围的子图中的一条路径。
周围的子图中的一条路径。
因此,为了提取给定用户项对(푢,푣)的封闭子图,我们首先用其交互项集푁 (푢).)来表示用户푢其次,我们通过将项目映射到它们在KG中对应的实体,为用户푢构建实体集퐸(푢,为项目푣构建目标实体푒。第三,对于每个实体푒푖 ∈ 퐸(푢),我们通过取N푘 (푒푖)和N푘 (푒)的交集来计算푒푖和푒的封闭子图,这些交集是跳跃邻居的集合,并且进一步修剪与实体或分离的实体。最后,如图6所示,我们通过合并퐸(푢的每个实体和目标实体푒.之间的所有封闭子图来构建푣푢的封闭图
图6 全局模型图解,它包含三个组成部分:封闭子图提取、子图的神经编码和关系感知GNN。
子图的神经编码(Neural encoding of subgraph)。知识图表示(KGE)是学习实体和关系的密集低维向量表示的有效方法,它保留了图的结构信息。最近,基于翻译的KGE方法由于其简洁的模型和优越的性能而受到了极大的注意[42]。因此,在本文中,我们采用了一种广泛使用的基于翻译的方法TransR [21],该方法为每个关系引入了一个投影矩阵,以将实体表示映射到它们对应的关系空间。具体地说,对于图中的每一个三元组(ℎ、푟、푡),我们定义eℎ、e푡 ∈ R푑×1、e푟 ∈ R푘×1和m \u\u r \u\u分别作为实体\u、关系\u\u和关系\u的投影矩阵的表示。该表示通过在e푟 ℎ = eℎM푟和e푟푡 = e푡 M푟的约束下优化翻译原则e푟 ℎ +e푟 ≈ e푟푡来学习,它是eℎ和e푡在关系空间中的映射表示。然后,三元组(ℎ、푟、푡)的似真性得分被定义为 (4)
(4)
푔푟 (ℎ,푡)的似真性得分越低,三元组就越有效。为了鼓励区分真假三元组,我们使用以下基于差值的排序损失进行训练, (5)
(5)
其中,훾是裕度, 是KGE的训练集。
是KGE的训练集。
按照这种方式,我们可以通过利用提取的封闭子图中的结构信息来初始化三元组粒度上的实体和关系的表示。
基于关系感知GNN的表征学习(Relation-aware GNN for Representation Learning)。全局模型的目标是根据从全局信息中提取的封闭子图来计算用户项对(푢,푣)的全局表示。我们采用[53]中描述的通用消息传递方案,其中通过将节点表示与其邻居表示的聚合相结合来迭代更新节点表示。具体地,GNN的푘-th层由下式给出
其中,N(푡)是节点的直接邻居的集合,푡,푎푘푡表示来自邻居的聚合消息,ℎ푘푡表示节点푡在푘层中的潜在表示。在消息传递过程中,任何节点ℎ的初始隐含表示푖0푖都是通过对前向分量中KGE的子图进行神经编码初始化的。此外,该框架提供了插入不同聚合和组合功能的灵活性,从而产生各种GNN架构[40]。
受图中不同关系路径传递的消息可能会产生不同影响的事实和多关系R-GCN[34]的启发,我们设计了一个关系感知GNN,如图6所示,其聚合函数定义为 (6)
(6)
其中,R是图中存在的关系总数,N푟(푡)是与关系푡相连的节点푟的邻居,W푘+1푟是关系푟用于在푘层传播消息的变换矩阵,휔푘+1푟푠푡是三元组对应的푘层的关系路径注意度权重(푠,푟,푡),通过两层MLP计算如下: (7)
(7)
其中h푘푠和h푘푡是푘层三元组的头和尾节点的潜在表示,e푟是图中关系푟的学习表示,휎是调节从每个邻居聚合的信息的Sigmoid函数。在实际应用中,为了避免由于图中参数的数量随着关系数目的快速增长而导致的稀有关系的过度拟合,我们在广义网络中每一层的关系特定变换矩阵W푘+1푟之间采用了基共享机制,并实现了一种三元组丢弃的形式,即在聚合邻域信息的同时从图中随机丢弃三元组。此外,在给定聚合信息为푘+1푡的节点푡的情况下,我们实现了具有特殊关系类型的自连接的组合函数,以计算其从[34]派生的更新表示。它是由 (8)
(8)
遵循如上所述的关系感知GNN体系结构,我们在对应子图上的퐿层消息传递之后获得项的全局表示。然后,我们计算用户及其交互项的全局表示如下, (9)
(9)
其中|N(푢)|是项目集的大小,vGlobal和uGlobal分别是项目푣和用户푢的全局表示。4.4 基于语义融合的预测(Prediction with Semantic Fusion)
请注意,局部和全局信息可以共同指示用户对项目的偏好,但对于不同的用户-项目对,双重效果的重要性可能不同。因此,在[59]的启发下,我们设计了一个用于语义融合的门控网络,根据特定的用户-项目对,为四个语义特征(vLocal、uLocal、vGlobal、uGlobal)动态分配权重。
基于门控网络的语义融合(Semantic fusion with gating network)。对于用户-项对(푢,푣),给定来自上述两个子模型的用户-项对的局部和全局表示,我们可以用门控网络导出如下的最终表示, (10)
(10)
其中,uFinal是用户的最终表示,푢,훼表示全局特征的权重,而wGate是线性单元的可学习变换矩阵。项目푣的最终表示vFinal也可以以类似的方式计算。以最终表示为输入,我们可以计算用户푢采用项푣的概率, (11)
(11)
其中푛푛(·)可以是具有Sigmoid激活功能的全连接网络。
损失函数(Loss function)。为了优化推荐模型,我们采用了BPR损失[31]的损失函数,它假设指示更多用户偏好的观察到的交互应该被赋予比未观察到的交互更高的预测值: (12)
(12)
其中 表示训练集,I+表示用户푢与项之间的正交互,而I−表示采样的负交互集,휎(·)表示Sigmoid函数,Θ表示模型参数集。采用퐿-2正则化方法,用휆对Θ进行参数化处理,以防止过拟合。为了优化损失函数,我们在实现中采用了小批量ADAM,因为它具有自适应控制学习率的能力。
表示训练集,I+表示用户푢与项之间的正交互,而I−表示采样的负交互集,휎(·)表示Sigmoid函数,Θ表示模型参数集。采用퐿-2正则化方法,用휆对Θ进行参数化处理,以防止过拟合。为了优化损失函数,我们在实现中采用了小批量ADAM,因为它具有自适应控制学习率的能力。
4.5 KADM的时间复杂度
对于局部模型,KEE操作的计算复杂度为푂(푛(푚−ℎ)ℎ푑+푑(푛+푑)),KCM操作的计算复杂度为푂(2퐾(푑+1)),其中푛和푚是过滤器的数量和描述内容的固定长度,ℎ是KEE中的过滤器大小,퐾和푑分别是固定的邻域大小和嵌入长度,所以这部分的计算复杂度是푂(푛(푚−ℎ)ℎ푑+푑(푛+푑)+2퐾(푑+1))。对于全局模型,封闭子图提取的计算复杂度为푂((퐾+1)(|휉|+|퐸|),同时使用广度优先搜索算法对孤立实体进行剪枝,푂(|R|푑푘)用于表示学习。其中|퐸|,|휉|和|R|分别是图中边、节点和关系的大小,푑是节点/关系嵌入的大小。可以看出,全局模型的计算代价依赖于图的大小,通过提取封闭子图可以大大减少计算开销。在语义融合部分,门控网络的计算复杂度为푂(푑),最后一层全连通的计算复杂度为푂(푑2)。
5 实验(Experiments)
为了全面评估所提出的模型KADM,我们进行了实验,以回答以下研究问题:
RQ1:与最先进的推荐模型,特别是基于KG的推荐模型相比,KADM的表现如何?
RQ2:KADM中的超参数和关键组件对推荐性能有何影响?
RQ3:KADM能否对受益于知识图谱和注意力机制的用户偏好提供一些合理的解释?5.1 数据集描述(Dataset Description)
为了评估KADM的有效性,我们将我们的模型应用于两个公共基准数据集Movielens和Last-FM。这两个数据集的统计数据如表1所示。关于它们的基本描述总结如下:
表1 数据集的基本统计数据
MovieLens-1M 在MovieLens网站上包含大约100万个显性评级(从1到5)。为了保证数据质量,我们提取了10核数据。
- Last.FM包含来自Last.fm在线音乐系统的2000名用户的音乐家收听信息。类似地,我们使用10核设置来确保每个用户和项目对至少有10个交互。
为了与隐式反馈设置一致,我们将它们转换为隐式反馈,其中每个用户-项目对都标有1,表示用户对该项目给予了肯定的评价。MovieLens-1M的正值阈值为4,而Last.fm由于其稀疏性而未设置阈值。
除了用户与项的交互之外,我们还需要为每个数据集构建知识图。具体地说,我们遵循知识互补链接(SEC.。4.1)通过标题匹配将项目映射到Freebase实体3。对于那些链接失败的项目,我们只需丢弃它们。此外,对于识别的实体,我们考虑与项对齐的实体的直接邻居的三元组,无论它充当哪个角色(即,主体或宾语)。为了确保KG质量,我们然后过滤掉与项对齐的实体(即,在两个数据集中都低于10)预期的不频繁实体,并保留至少50个三元组中出现的关系。表1还总结了为这两个数据集提取的知识图谱信息的基本统计数据。
对于每个数据集,我们随机选取每个用户80%的交互历史作为训练集,其余的作为测试集。我们从训练集中随机选取20%的交互作用作为验证集来调整超参数。对于每个观察到的用户-项目交互,我们将其视为一个积极的实例,然后进行负面抽样策略,将其与用户之前没有评分的一个负面项目配对。
5.2 实验设置(Experiment Setup)
5.2.1 评估指标(Evaluation Metrics)
对于测试集中的每个用户,考虑到计算效率,我们随机抽取用户没有交互过的100个项目作为负项目。然后,每个方法都会输出用户对测试环境中所有项目的偏好分数。为了评估top-K推荐和偏好排序的有效性,我们采用了两种广泛使用的评估协议:recall@K和ndcg@K[4]。默认情况下,我们设置K=20。我们报告测试集中所有用户的平均指标。
5.2.2 基线(Baselines)
为了评估KADM的有效性,我们将所提出的模型与基于CF的(FM和NFM)、基于正则化的(CKE和CFKG)以及基于GNN的(KGAT、MVIN和CKAN)进行比较:
- FM[32]:一种基本的因式分解方法,用于建模输入之间的二阶特征交互作用。在我们的评估中,我们将用户的ID、项目和相关的KG知识作为输入特征。
- NFM[12]:该方法是一种最先进的因式分解模型,它将FM归入神经网络。特别是,我们用KG中连通实体的嵌入丰富了项的表示,并在输入特征上使用了一个隐含层,如[12]中所建议的。
- Cke[56]:它将CF与各种信息结合在一个统一的推荐框架中,包括结构、文本和视觉知识。在本文中,我们将CKE实现为CF加结构知识。
- CFKG[1]:它在包括用户、项、实体和关系的统一图上应用Transe[2],将推荐任务转化为(用户、交互、项)三元组的似然预测。
- KGAT[44]:在包括知识图和用户项图的统一图上使用图注意网络来区分图中邻居的重要性。
- MVIN[39]:它从用户视图和实体视图中学习项的表示形式。MVIN收集KG中的知识和实体之间的不同交互,对用户偏好进行建模。
CKAN[47]:它对用户-项目交互中潜在的协同信号进行编码,并以端到端的方式将它们与KG结合。CKAN使用协同信号初始化用户和项目的实体集。
5.2.3 实施细节(Implement Details)
所有模型都是基于PyTorch实现的,其中超参数是根据流行的选择或先前的研究进行配置的。具体而言,我们使用ADAM[18]优化器对所有模型进行优化,其中批大小固定为512。默认的Xavier初始化式[8]用于初始化模型参数。我们对所有模型中一些常见的超参数进行网格搜索:学习速率在{0.05,0.01,0.005,0.001}之间调节,衰减率为0.9%,퐿2归一化系数在{10−5,10−4,10−3,10−2}中搜索,丢失率在{0.2,0.3,0.4,…,0.8}中调节。对于基线的其他超参数,其设置与其原始文件中报告的相同或其代码中的默认设置相同。然后,对于我们提出的模型的超参数,它们被设置如下:根据邻居的分布,MovieLens-1m的邻居大小设置为40,Last.fm的邻居大小设置为20。对于局部模型,词嵌入的维度为64,并使用维基语料库用word2vec[28]进行初始化。使用64个过滤器对描述进行编码的CNN的长度被设置为3,这是指三元组。根据描述的分布,将MovieLens-1M和Last.fm的描述的固定大小设置为30。对于全局模型,我们选择TransR[21]来学习嵌入128维的预先训练的实体和关系。考虑到计算效率,对于Last.fm和MovieLens-1m,我们将实体所在的三元组数量限制为1000个,MovieLens-1m限制为100个,并在构造封闭子图的过程中保留2跳邻居。本文的代码可在https://github.com/scwu1008/KADM.上找到
5.3 性能比较(Performance Comparison)(RQ1)
算法整体比较的实验结果如表2所示,我们从中得到了一些观察结果:
表2 MovieLens-1M和Last.fm的比较结果。对于Recall,NDCG,值越大越好。
我们提出的KADM在两个数据集的所有度量中都具有最好的性能(Our proposed KADM has the best performance in all metrics on both two datasets)。总体而言,KADM在Last.fm数据集和MovieLens-1M数据集上至少在召回率和ndcg指标上分别显著超过他人约0.05和0.04和0.02和0.03。结果表明,KADM具有以共注意方式显式编码协同信号,以关系感知注意机制捕捉全局信息中蕴含的丰富知识关联的能力。另一方面,将局部信息中的协同信号与全局信息中的知识关联相结合,可以明显提高推荐性能。同时,KADM在两个数据集上的性能都好于CKAN,这表明双重机制对不同类型的信息建模是有效的。
- 基于GNN的模型具有比其他基线模型更好的性能,但受到引入噪声的影响(GNN-based models have better performances than other kinds of baselines, but are affected by introduced noise)。结果表明,利用GNN来捕捉KG上的信息传播可以有效地对用户偏好进行建模。然而,当图形变得更密集和更大时,更多的噪声将被引入到传播过程[39]。因此,在KADM中直接计算用户和项之间的封闭子图,可以更有效地计算大规模KG中的相关实体和关系路径。
- 大多数基于KG的方法在所有数据集上的性能都好于传统的基于CF的方法(Most KG-based methods perform better than traditional CF-based methods on all datasets)。这表明KG的使用对推荐有很大的帮助。同时,值得注意的是,基于GNN的模型的性能要好于基于正则化的模型,这表明一阶关系的建模可能没有充分利用KG中的结构信息。
在大多数情况下,模型在电影数据上的性能要好于音乐数据(In most situations, the model performance on movie data is better than music data)。一种可能的假设是,用户与局部信息中的项之间存在更多的交互,而全局信息中的节点之间存在更多的链接,这为学习潜在嵌入提供了足够的信息。
5.4 KADM研究(Study Of KADM)(RQ2)
为了研究模型的性能变化,我们在Last.fm上进行了不同超参数设置的实验。

图7 KADM在Last.fm w.r.t上不同超参数的评估
嵌入大小的影响(Effect of dimension of embedding)。在KADM中,我们探讨了不同维度对模型性能的影响,包括局部模型中的单词嵌入和全局模型中的节点嵌入。结果如图7所示,它启示我们需要一个适当的嵌入维度。如果太小,就会缺乏表现力;如果太大,可能会造成一点过度适应,从而导致性能下降。
采样邻居大小的影响(Effect of sampling neighbor size)。通过改变抽样邻域的大小来考察局部和全局信息的使用对KADM中用户和项目的初始邻域集合的影响。从图7中,我们观察到,随着样本量的增加,性能会更好,但增加的速度正在下降,计算成本也在增加。因此,我们可以选择合适的样本量,在模型性能和复杂性之间保持良好的平衡。
项目描述大小的影响(Effect of item description size)。描述大小的变化可能会影响学习到的项目在局部模型中的初始嵌入。为了研究它的影响,我们用不同大小的描述퐷进行了实验。从图7中可以看出,随着长度的增加,模型的性能首先增加,然后下降。一个合理的解释是,太小的퐷缺乏足够的容量来描述物品,而太大的퐷容易受到噪音的误导。
不同网络配置的影响(Effect of different network configurations)。为了验证模型中某些部分的有效性,我们进行了一些消融实验,实验结果如表3所示。消融实验有三种不同的网络结构:
表3 不同网络配置的影响
1)共同注意机制,它可以计算局部信息中的内部关联。在KADM-Rel中,我们将局部模型中的注意权重固定为1퐾,其中퐾是采样邻域的大小;
- 2)关系感知注意机制,它模拟关系路径在信息传播过程中的不同影响;在KADM-REL中,我们将全局模型中的聚合函数修改为平均函数,并以最近邻居的平均值作为聚合特征。
- 3)局部模型和全局模型的结合,在建模用户偏好时相辅相成。分别在去掉门级网络设置后的局部模型和全局模型上进行了实验。
研究结果启示我们:i)注意机制能有效地帮助我们从局部和全局信息中筛选出有用的特征,这有利于对用户偏好进行建模;ii)这支持了我们的假设,即用局部信息和全局信息来建模用户偏好可以相辅相成,从而获得更好的性能,因此两者的组合更合适。
5.5 案例研究(Case Study)(RQ3)
借助于注意机制和知识图,我们可以根据局部模型中的注意矩阵和全局模型中封闭子图的高阶连通性来推理用户对候选项目的偏好,并提供了一些潜在的解释。特别地,我们对一个用户-项目对进行了案例研究,计算出了图8中用户푢和项目푖之间的注意矩阵和所提取的封闭子图的高阶连通性。用户푢和物品푖的协同邻居之间的注意度权重可以被认为是物品满足用户偏好的证据。正如我们所看到的,商品푖的大多数邻居与用户푢的邻居相似,这意味着目标商品符合用户的品味。B)对于全局信息,KADM捕捉从其提取的封闭子图的高阶连通性,这也可以在推断用户偏好方面发挥重要作用。子图中的连通路径对于推断用户偏好很有用。例如,连接性(퐵푎푚푏푖푟3−−→푂푙푖푣푒푟푊푎푙푙푎푐푒푟3−−→퐷푢푚푏표)和(퐵푎푚푏푖푟1−−→푊푎푙푡퐷푖푠푛푒푦푟1−−→퐷푢푚푏표)指示目标项小飞象与用户过去最喜欢的电影斑比具有相同的导演和发行商。因此,我们可以生成解释,因为小飞象是推荐的,因为你看过由同一个导演奥利弗·华莱士执导、由同一个制片人沃尔特·迪士尼制作的小鹿斑比。C)对于整个模型,局部模型和全局模型可以相辅相成。具体地说,即使目标项目本身在全局信息中几乎没有与用户相关的路径,我们仍然可以通过它与用户的协同邻居相似度来推荐该项目,反之亦然。例如,我们会推荐《绿野仙踪》,即使子图是稀疏的,因为它的协同邻居与用户的非常相似。<br />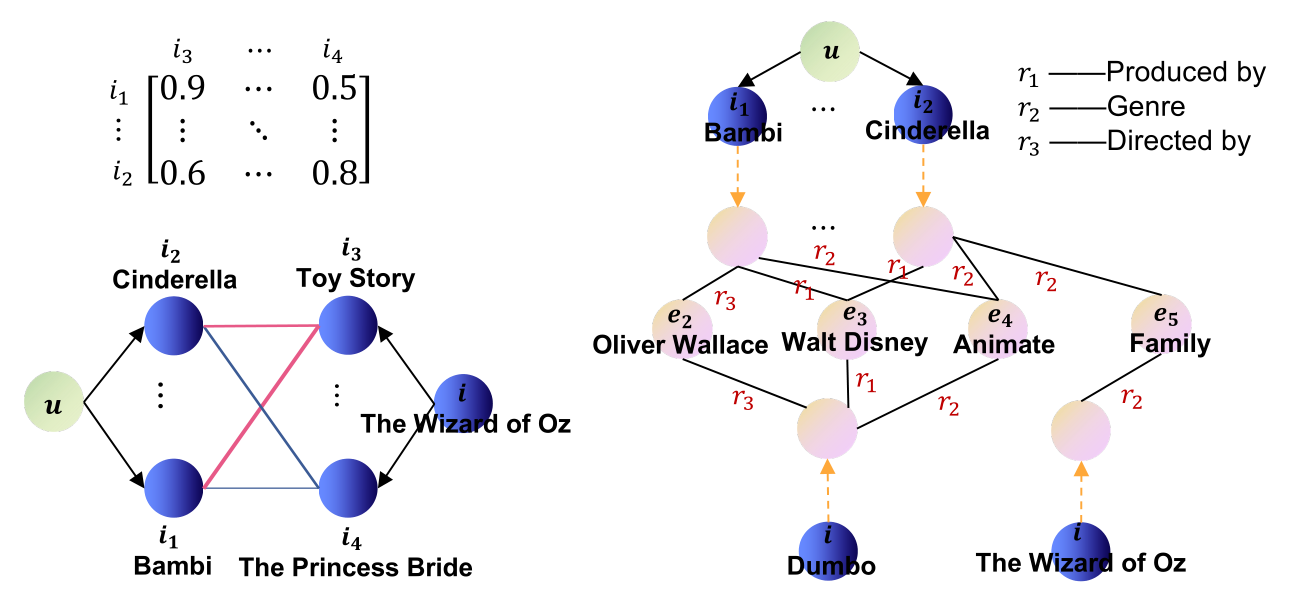<br />图8 来自MovieLens-1M的真实例子,包括局部信息(左)和全局信息(右)。
6 结论和未来工作(Conclusion and Future Work)
在这项工作中,我们研究了结合用户-项目交互数据和知识图信息进行Top-N推荐的任务。我们提出了一个统一局部和全局信息的Duet表示学习框架KADM,其中局部模型和知识感知共同注意机制通过发现协同邻居之间的内在关联来学习项目和用户的局部表示,而具有关系感知GNN的全局模型通过从知识图谱中获取封闭子图中的知识关联来学习项目和用户的全局表示。在两个真实数据集上的大量实验验证了KADM的有效性。对超参数的进一步评估和案例研究也证明了KADM的优势。

若有收获,就点个赞吧
0 人点赞
