process对象是 Node 的一个全局对象,提供当前 Node 进程的信息。它可以在脚本的任意位置使用,不必通过require命令加载。该对象部署了EventEmitter接口。
属性
process.argv:返回一个数组,成员是当前进程的所有命令行参数。 process.env:返回一个对象,成员为当前Shell的环境变量,比如process.env.HOME。 process.installPrefix:返回一个字符串,表示 Node 安装路径的前缀,比如/usr/local。相应地,Node 的执行文件目录为/usr/local/bin/node。 process.pid:返回一个数字,表示当前进程的进程号。 process.platform:返回一个字符串,表示当前的操作系统,比如Linux。 process.title:返回一个字符串,默认值为node,可以自定义该值。 process.version:返回一个字符串,表示当前使用的 Node 版本,比如v7.10.0。 process.stdin/stdout/stderr process.execPath属性返回执行当前脚本的Node二进制文件的绝对路径 process.execArgv属性返回一个数组,成员是命令行下执行脚本时,在 Node 可执行文件与脚本文件之间的命令行参数。
process.stdout process.stdin process.argv process.env
通过shell命令
通过package.json中的script
"scripts" : { "test" : "echo \"Error: no test specified\" && exit 1" , "start" : "NODE_ENV=dev node process.js" }, webpack.DefinePlugin
我们的代码最终是运行在浏览器的,而浏览器并不存在 process.env 这个变量,但是我们是可以在代码访问 process.env 比如
if ( process . env . NODE_ENV === 'development' ) { // 开发环境逻辑 } else { // 生产环境逻辑 } DefinePlugin 允许创建一个在编译 时可以配置的全局常量,这可能会对开发模式和生产模式的构建允许不同的行为非常有用。
new webpack . DefinePlugin ({ NODE_ENV : JSON . stringify ( 'test' ), }) 方法
process.chdir():切换工作目录到指定目录。 process.cwd():返回运行当前脚本的工作目录的路径。 process.exit():退出当前进程。 process.getgid():返回当前进程的组ID(数值)。 process.getuid():返回当前进程的用户ID(数值)。 process.nextTick():指定回调函数在当前执行栈的尾部、下一次Event Loop之前执行。 process.on():监听事件。data process.setgid():指定当前进程的组,可以使用数字ID,也可以使用字符串ID。 process.setuid():指定当前进程的用户,可以使用数字ID,也可以使用字符串ID。
process.cwd(),process.chdir()
console . log ( process . cwd ()) ///Users/guan/Desktop/learn-node process . chdir ( '/Users/guan/Desktop' ) console . log ( process . cwd ()) ///Users/guan/Desktop 注意,process.cwd()与dirname的区别。前者进程发起时的位置,后者是脚本的位置,两者可能是不一致的。比如,node ./code/program.js,对于process.cwd()来说,返回的是当前目录(.);对于 dirname来说,返回是脚本所在目录,即./code/program.js
process.nextTick()
process . nextTick ( function () { console . log ( '下一次Event Loop即将开始!' ); }); 上面代码可以用setTimeout(f,0)改写,效果接近,但是原理不同。
setTimeout ( function () { console . log ( '已经到了下一轮Event Loop!' ); }, 0 ) setTimeout(f,0)是将任务放到下一轮事件循环的头部,因此nextTick会比它先执行。另外,nextTick的效率更高,因为不用检查是否到了指定时间。
根据Node的事件循环的实现,基本上,进入下一轮事件循环后的执行顺序如下。
setTimeout(f,0) 各种到期的回调函数 process.nextTick push(), sort(), reverse(), and splice()
process.exit()
if ( err ) { process . exit ( 1 ); } else { process . exit ( 0 ); } 如果不带有参数,exit方法的参数默认为0。
function printUsageToStdout () { process . stdout . write ( "...some long text ..." ); } if ( true ) { printUsageToStdout (); process . exit ( 1 ); } 上面的代码可能不会达到预期效果。因为process.stdout有时会变成异步,不能保证一定会在当前事件循环之中输出所有内容,而process.exit会使当前进程立刻退出。
if ( true ) { printUsageToStdout (); // process.exit(1); process . exitCode = 1 ; throw new Error ( "xx condition failed" ); } process.on()
data事件:数据输出输入时触发 SIGINT事件:接收到系统信号SIGINT时触发,主要是用户按Ctrl + c时触发。 SIGTERM事件:系统发出进程终止信号SIGTERM时触发 exit事件:进程退出前触发
```
process.on(“uncaughtException”, function(err) {
console.error(“got an error: %s”, err.message);
process.exit(1);
});
setTimeout(function() {
throw new Error(“fail”);
}, 100);
** process . kill ()**< br /> process . kill 方法用来对指定 ID 的线程发送信号,默认为 SIGINT 信号。 process.on(“SIGTERM”, function() {
console.log(“terminating”);
process.exit(1);
});
setTimeout(function() {
console.log(“sending SIGTERM to process %d”, process.pid);
process.kill(process.pid, “SIGTERM”);
}, 500);
setTimeout(function() {
console.log(“never called”);
}, 1000);
上面代码中, 500 毫秒后向当前进程发送 SIGTERM 信号(终结进程),因此 1000 毫秒后的指定事件不会被触发。 ** exit 事件**< br />当前进程退出时,会触发 exit 事件,可以对该事件指定回调函数。 process.on(“exit”, code =>
console.log(“exiting with code: “ + code))
** beforeExit 事件**< br /> beforeExit 事件在 Node 清空了 Event Loop 以后,再没有任何待处理的任务时触发。正常情况下,如果没有任何待处理的任务, Node 进程会自动退出,设置 beforeExit 事件的监听函数以后,就可以提供一个机会,再部署一些任务,使得 Node 进程不退出。< br /> beforeExit 事件与 exit 事件的主要区别是, beforeExit 的监听函数可以部署异步任务,而 exit 不行。< br />此外,如果是显式终止程序(比如调用 process . exit ()),或者因为发生未捕获的错误,而导致进程退出,这些场合不会触发 beforeExit 事件。因此,不能使用该事件替代 exit 事件。 常见进程码 - 1 ,发生未捕获错误 - 5 , V8 执行错误 - 8 ,不正确的参数 - 128 + 信号值,如果 Node 接受到退出信号(比如 SIGKILL 或 SIGHUP ),它的退出码就是 128 加上信号值。由于 128 的二进制形式是 10000000 , 所以退出码的后七位就是信号值。 < a name = "BMZxQ" ></ a > ### 事件循环 < a name = "tvekZ" ></ a > ### 进程process与线程thread 通俗讲解 计算机的核心是 cpu ,承担了所有计算任务,就像一座工厂,时刻在运行。< br />假设工厂的电力有限,一次只能给一个车间使用,也就是说一个车间开工的时候,其他车间都无法工作。单个 cpu 一次只能运行一个任务。进程就好比车间,代表 cpu 处理的单个任务。任一时刻, cpu 总是运行一个进程,其他进程处于非运行状态。< br />线程好比车间里的工人,协同完成一个任务,一个进程包含多个线程,车间的空间是工人共享的,进程间的内存空间是共享的,线程可以使用这些共享内存。< br />房间的大小有限,有的房间只能容纳一个人,比如厕所有人的时候,其他人不能进去,线程使用某些共享内存的时候,其他线程只有等这个线程使用完才能使用。通过互斥锁 Mutex 防止多个线程读写某一块内存区域。< br />有些房间可以容纳 n 个人,如果人数大于 n ,只能在房间外面等,这就好比是一块内存区域,只能供特定数目的线程使用。解决办法是在门口挂 n 把要是,进去的人就取一把钥匙,出来的时候,就将钥匙放回原处。门口的钥匙空了,就在门口排队。这种做法就是信号量,用来保证多个线程不会冲突。不难看出,互斥锁是信号量的一种特殊情况 n = 1 。< br />操作系统的设计,可以归纳为三点: - 多进程,允许多个任务同时进行 - 多线程,允许单个任务拆分成不同的部分进行 - 提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面,允许进程和线程之间共享资源 术语解释 **进程**:是计算机中程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统的结构基础。进程是线程的容器。< br />**线程:**是操作系统能进行运算调度的最小单位,被包含在进程中,是进程中实际运作的单位。一条线程是指进程中的单一顺序的控制流,一个进程中可以并发多个线程,每条线程执行不同的任务。程序执行的最小单位 **总结**: - 一个程序至少要有一个进程,一个进程有多个线程 - 进程是资源分配和调度的最小单位,线程是程序执行的最小单位 - 一个线程可以创建和销毁另一个线程,一个进程中多个线程可以并发执行 同一块代码,可以根据系统 CPU 核心数启动多个进程,每个进程都有属于自己的独立运行空间,进程之间是不相互影响的。同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等。但同一进程中的多个线程有各自的调用栈( call stack ),自己的寄存器环境( register context ),自己的线程本地存储( thread - local storage ),线程又有单线程和多线程之分,具有代表性的 JavaScript 、 Java 语言。 **单线程**: Node . js 虽然是单线程模型,但是其基于事件驱动、异步非阻塞模式,可以应用于高并发场景,避免了线程创建、线程之间上下文切换所产生的资源开销。 如果你有需要大量计算, CPU 耗时的操作,开发时候要注意。 **多线程**:代价还在于创建新的线程和执行期上下文线程的切换开销,由于每创建一个线程就会占用一定的内存,当应用程序并发大了之后,内存将会很快耗尽。**线程间资源是共享的,关注的是安全问题。共享变量** < a name = "AWCUF" ></ a > #### < a name = "DR4Vd" ></ a > ## console console . log error warn info < br /> console . trace < br /> console . time console . timeEnd < br /> console . group ()< br /> console . count () < a name = "N5hJ7" ></ a > ## Buffer [ Buffer . xmind ]( https : //www.yuque.com/attachments/yuque/0/2021/xmind/248010/1624447518549-29943ca7-9e13-48fd-9487-c950fa97508a.xmind) < a name = "qnYvU" ></ a > ### [Buffer 内存分配总结](https://www.nodejs.red/#/nodejs/buffer?id=buffer-%e5%86%85%e5%ad%98%e5%88%86%e9%85%8d%e6%80%bb%e7%bb%93) ** Buffer 对象的内存分配不是在 V8 的堆内存中的,而是由 Node 的 C ++层面实现的内存申请的**。由于大对象的存储空间是不确定的,不可能向操作系统申请,会对操作系统造成压力。所以 Node 在内存的使用上面应用的是 C ++层面申请内存,在 JavaScript 中分配内存的策略< br /> 1. 在初次加载时就会初始化 1 个 ** 8KB 的内存空间**, buffer . js 源码有体现 1. 根据申请的内存大小分为 **小 Buffer 对象** 和 **大 Buffer 对象** 1. 小 Buffer 情况,会继续判断这个 slab 空间是否足够 - 如果空间足够就去使用剩余空间同时更新 slab 分配状态,偏移量会增加 - 如果空间不足, slab 空间不足,就会去创建一个新的 slab 空间用来分配 4. 大 Buffer 情况,则会直接走 createUnsafeBuffer ( size ) 函数 4. 不论是小 Buffer 对象还是大 Buffer 对象,内存分配是在 C ++ 层面完成,内存管理在 JavaScript 层面,最终还是可以被 V8 的垃圾回收标记所回收。 真正的 buffer 内存是在 node 的 c ++层面提供的, js 层面只是使用它。当进行小而频繁的 buffer 操作时,采用 slab 的机制进行预先申请和事后分配,使得 js 到操作系统之间不必有过多的内存申请方面的系统调用。对于大块的 buffer 而言,直接使用 c ++层面提供的内存,无需频繁的分配操作。 那么它的具体分配策略是怎么样的呢?大对象和小对象的分配方式采用的算法是否是一样的呢?< br />首先来介绍一下 ** slab 内存分配机制**。它是一种动态内存管理机制,采用的是**预先申请,事后分配**的方式,简单来说它就是一块申请好的固定大小的内存区域。有如下 3 种状态: - full :完全分配 - partial :部分分配 - empty :没有被分配 ** 8KB 限制**< br /> Node . js 以 8KB 为界限来区分是小对象还是大对象,在 [ buffer . js ]( https : //github.com/nodejs/node/blob/v10.x/lib/buffer.js) 中可以看到以下代码 Buffer.poolSize = 8 * 1024; // 102 行,Node.js 版本为 v10.x
在 ** Buffer 初识** 一节里有提到过 Buffer 在创建时大小已经被确定且是无法调整的 到这里应该就明白了。 ** Buffer 对象分配**< br />以下代码示例,在加载时直接调用了 createPool () 相当于直接初始化了一个 8 KB 的内存空间,这样在第一次进行内存分配时也会变得更高效。另外在初始化的同时还初始化了一个新的变量 ** poolOffset = 0 ** 这个变量会记录已经使用了多少字节。 Buffer.poolSize = 8 * 1024;
var poolSize, poolOffset, allocPool;
… // 中间代码省略
function createPool() {
poolSize = Buffer.poolSize;
allocPool = createUnsafeArrayBuffer(poolSize);
poolOffset = 0;
}
createPool(); // 129 行
此时,新构造的 slab 如下所示:< br /><br />现在让我们来尝试分配一个大小为 2048 的 Buffer 对象,代码如下所示: Buffer.alloc(2 * 1024)
现在让我们先看下当前的 slab 内存是怎么样的?如下所示:< br /><br />那么这个分配过程是怎样的呢?让我们再看 buffer.js 另外一个核心的方法 allocate(size) // https://github.com/nodejs/node/blob/v10.x/lib/buffer.js#L318
function allocate(size) {
if (size <= 0) {
return new FastBuffer();
}
// 当分配的空间小于 Buffer.poolSize 向右移位,这里得出来的结果为 4KB
if (size < (Buffer.poolSize >>> 1)) {
if (size > (poolSize - poolOffset))
createPool();
var b = new FastBuffer(allocPool, poolOffset, size);
poolOffset += size; // 已使用空间累加
alignPool(); // 8 字节内存对齐处理
return b;
} else { // C++ 层面申请
return createUnsafeBuffer(size);
}
}
读完上面的代码,已经很清晰的可以看到何时会分配小 Buffer 对象,又何时会去分配大 Buffer 对象。< br />这块内容着实难理解,翻了几本 Node . js 相关书籍,朴灵大佬的「深入浅出 Node . js 」 Buffer 一节还是讲解的挺详细的,推荐大家去阅读下。 < a name = "DD14X" ></ a > # 核心模块 < a name = "R89h7" ></ a > ## 模块加载 **模块分类** - C / C ++ 模块,也叫 built - in 模块,在 src 目录下。一般我们不直接调用,而是在 native module 中通过 process . binding ( 'XXX' )调用,然后我们再 require - native 模块,在 lib 目录下,通过 require 引用。比如 Node . js 中常用的 buffer , fs , os 等 native 模块,其底层都有调用 built - in 模块。 - 第三方模块:非 Node . js 源码自带的模块都可以统称第三方模块,比如 express , webpack 等等。 - JavaScript 模块,这是最常见的,我们开发的时候一般都写的是 JavaScript 模块 - JSON 模块,这个很简单,就是一个 JSON 文件 - C / C ++ 扩展模块,使用 C / C ++ 编写,编译之后后缀名为 . node **模块加载机制**< br /> < a name = "MlDCT" ></ a > ## Event < a name = "U5DZb" ></ a > ## [Crypto加解密模块](https://www.nodejs.red/#/nodejs/crypto?id=crypto%e5%8a%a0%e8%a7%a3%e5%af%86%e6%a8%a1%e5%9d%97) [参考链接-加密]( https : //juejin.cn/post/6844903638117122056) 加密算法分 **对称加密** 和 **非对称加密**,其中对称加密算法的加密与解密 **密钥相同**,非对称加密算法的加密密钥与解密 **密钥不同**,此外,还有一类 **不需要密钥** 的 **散列算法**。< br />常见的 **对称加密** 算法主要有 DES 、 3DES 、 AES 等,常见的 **非对称算法** 主要有 RSA 、 DSA 等,**散列算法** 主要有 SHA - 1 、 MD5 等。 **对称加密算法** 是应用较早的加密算法,又称为 **共享密钥加密算法**。在 **对称加密算法** 中,使用的密钥只有一个,**发送** 和 **接收** 双方都使用这个密钥对数据进行 **加密** 和 **解密**。这就要求加密和解密方事先都必须知道加密的密钥。< br /> 1. 数据加密过程:在对称加密算法中,**数据发送方** 将 **明文** (原始数据) 和 **加密密钥** 一起经过特殊 **加密处理**,生成复杂的 **加密密文** 进行发送。 1. 数据解密过程:**数据接收方** 收到密文后,若想读取原数据,则需要使用 **加密使用的密钥** 及相同算法的 **逆算法** 对加密的密文进行解密,才能使其恢复成 **可读明文**。 **非对称加密算法**,又称为 **公开密钥加密算法**。它需要两个密钥,一个称为 **公开密钥** ( public key ),即 **公钥**,另一个称为 **私有密钥** ( private key ),即 **私钥**。< br />因为 **加密** 和 **解密** 使用的是两个不同的密钥,所以这种算法称为 **非对称加密算法**。< br /> 1. 如果使用 **公钥** 对数据 **进行加密**,只有用对应的 **私钥** 才能 **进行解密**。 1. 如果使用 **私钥** 对数据 **进行加密**,只有用对应的 **公钥** 才能 **进行解密**。 **例子**:甲方生成 **一对密钥** 并将其中的一把作为 **公钥** 向其它人公开,得到该公钥的 **乙方** 使用该密钥对机密信息 **进行加密** 后再发送给甲方,甲方再使用自己保存的另一把 **专用密钥** (**私钥**),对 **加密** 后的信息 **进行解密**。 < a name = "A3JGB" ></ a > ## Stream [参考链接- stream ]( https : //zhuanlan.zhihu.com/p/36728655)<br />[Stream.xmind](https://www.yuque.com/attachments/yuque/0/2021/xmind/248010/1623750566296-1baba877-88a0-400b-81ee-7f343739b8b1.xmind)<br /><br />**Stream类型**<br />在 Node.js 中有四种基本的流类型:Readable(可读流),Writable(可写流),Duplex(双向流),Transform(转换流)。 - 可读流是数据可以被消费的源的抽象。一个例子就是 fs . createReadStream 方法。 - 可读流是数据可以被写入目标的抽象。一个例子就是 fs . createWriteStream 方法。 - 双向流即是可读的也是可写的。一个例子是 TCP socket 。 - 转换流是基于双向流的,可以在读或者写的时候被用来更改或者转换数据。一个例子是 zlib . createGzip 使用 gzip 算法压缩数据。你可以将转换流想象成一个函数,它的输入是可写流,输出是可读流。你或许也听过将转换流成为“通过流( through streams )”。 所有的流都是 EventEmitter 的实例。触发它们的事件可以读或者写入数据,然而,我们可以使用 pipe 方法消费流的数据。 **基本 API **< br /> **实现可读流/可写流/双向流/ Transform 流** **可读流**< br />创建可读流时,需要继承 Readable ,并实现 _read 方法。 * _read 方法是从底层系统读取具体数据的逻辑,即生产数据的逻辑。 * 在 _read 方法中,通过调用 push ( data )将数据放入可读流中供下游消耗。 * 在 _read 方法中,可以同步调用 push ( data ),也可以异步调用。 * 当全部数据都生产出来后,必须调用 push ( null )来结束可读流。 * 流一旦结束,便不能再调用 push ( data )添加数据。< br />可以通过监听 data 事件的方式消耗可读流。 * 在首次监听其 data 事件后, readable 便会持续不断地调用 _read (),通过触发 data 事件将数据输出。 * 第一次 data 事件会在下一个 tick 中触发,所以,可以安全地将数据输出前的逻辑放在事件监听后(同一个 tick 中)。 * 当数据全部被消耗时,会触发 end 事件。 const Readable = require(‘stream’).Readable
class ToReadable extends Readable {
constructor(iterator) {
super()
this.iterator = iterator
}
// 子类需要实现该方法
// 这是生产数据的逻辑
_read() {
const res = this.iterator.next()
if (res.done) {
// 数据源已枯竭,调用push(null)通知流
return this.push(null)
}
setTimeout(() => {
// 通过push方法将数据添加到流中
this.push(res.value + ‘\n’)
}, 0)
}
}
const iterator = function (limit) {
return {
next: function () {
if (limit—) {
return { done: false, value: limit + Math.random() }
}
return { done: true }
}
}
}(1e10)
const readable = new ToReadable(iterator)
// 监听data事件,一次获取一个数据
readable.on(‘data’, data => process.stdout.write(data))
// 所有数据均已读完
readable.on(‘end’, () => process.stdout.write(‘DONE’))
**可写** - 上游通过调用 writable . write ( data )将数据写入可写流中。 write ()方法会调用 _write ()将 data 写入底层。 - 在 _write 中,当数据成功写入底层后,**必须**调用 next ( err )告诉流开始处理下一个数据。 - next 的调用既可以是同步的,也可以是异步的。 - 上游**必须**调用 writable . end ( data )来结束可写流, data 是可选的。此后,不能再调用 write 新增数据。 - 在 end 方法调用后,当所有底层的写操作均完成时,会触发 finish 事件。 const Writable = require(‘stream’).Writable
const writable = Writable()
// 实现_write方法
// 这是将数据写入底层的逻辑
//data:要写入的数据块 enc:如果写入的是字符串,必须字符串的编码 next:写入完成后或发生错误时的回调函数
writable._write = function (data, enc, next) {
// 将流中的数据写入底层
process.stdout.write(data.toString().toUpperCase())
// 写入完成时,调用next()方法通知流传入下一个数据
process.nextTick(next) //??????????????????????
}
// 所有数据均已写入底层
writable.on(‘finish’, () => process.stdout.write(‘DONE’))
// 将一个数据写入流中
writable.write(‘a’ + ‘\n’)
writable.write(‘b’ + ‘\n’)
writable.write(‘c’ + ‘\n’)
// 再无数据写入流时,需要调用end方法
writable.end()
** Duplex ** var Duplex = require(‘stream’).Duplex
var duplex = Duplex()
// 可读端底层读取逻辑
duplex._read = function () {
this._readNum = this._readNum || 0
if (this._readNum > 1) {
this.push(null)
} else {
this.push(‘’ + (this._readNum++))
}
//this.push(‘uroeuowhfgoewhoioiwhgewoi’);
//this.push(‘22222’);
//this.push(null);
}
// 可写端底层写逻辑
duplex._write = function (buf, enc, next) {
// a, b
process.stdout.write(‘_write ‘ + buf.toString() + ‘\n’)
next()
}
// 0, 1
duplex.on(‘data’, data => console.log(‘ondata’, data.toString()))
duplex.write(‘a’)
duplex.write(‘b’)
duplex.end()
** Transform ** const Transform = require(‘stream’).Transform
class Rotate extends Transform {
constructor(n) {
super()
// 将字母旋转n个位置
this.offset = (n || 13) % 26
}
// 将可写端写入的数据变换后添加到可读端
_transform(buf, enc, next) {
var res = buf.toString().split(‘’).map(c => {
var code = c.charCodeAt(0)
if (c >= ‘a’ && c <= ‘z’) {
code += this.offset
if (code > ‘z’.charCodeAt(0)) {
code -= 26
}
} else if (c >= ‘A’ && c <= ‘Z’) {
code += this.offset
if (code > ‘Z’.charCodeAt(0)) {
code -= 26
}
}
return String.fromCharCode(code)
}).join(‘’)
// 调用push方法将变换后的数据添加到可读端 this . push ( res ) // 调用next方法准备处理下一个 next () }
}
var transform = new Rotate(3)
transform.on(‘data’, data => process.stdout.write(data))
transform.write(‘hello, ‘)
transform.write(‘world!’)
transform.end()
对于可读流来说, push ( data )时, data 只能是 String 或 Buffer 类型,而消耗时 data 事件输出的数据都是 Buffer 类型。对于可写流来说, write ( data )时, data 只能是 String 或 Buffer 类型, _write ( data )调用时传进来的 data 都是 Buffer 类型。< br />也就是说,流中的数据默认情况下都是 Buffer 类型。产生的数据一放入流中,便转成 Buffer 被消耗;写入的数据在传给底层写逻辑时,也被转成 Buffer 类型。< br />但每个构造函数都接收一个配置对象,有一个 objectMode 的选项,一旦设置为 true ,就能出现“种瓜得瓜,种豆得豆”的效果。< br /> Readable 未设置 objectMode 时: const Readable = require(‘stream’).Readable
const readable = Readable()
readable.push(‘a’)
readable.push(‘b’)
readable.push(null)
readable.on(‘data’, data => console.log(data))
输出:< br /><** Buffer ** 61 > <** Buffer ** 62 > < br /> Readable 设置 objectMode 后: const Readable = require(‘stream’).Readable
const readable = Readable({ objectMode: true })
readable.push(‘a’)
readable.push(‘b’)
readable.push({})
readable.push(null)
readable.on(‘data’, data => console.log(data))
输出:< br /> a ** b **{} < br />可见,设置 objectMode 后, push ( data )的数据被原样地输出了。此时,可以生产任意类型的数据。 < a name = "uWidC" ></ a > ## Child_process [参考链接 - 子进程]( https : //zhuanlan.zhihu.com/p/36678971)<br />[参考链接2](https://juejin.cn/post/6882290865763680264#heading-19)<br />[进程间通信Socket](https://zhuanlan.zhihu.com/p/143555322)<br />[https://zhuanlan.zhihu.com/p/234806787](https://zhuanlan.zhihu.com/p/234806787) Node :在单核 CPU 系统之上我们采用 单进程 + 单线程 的模式来开发。在多核 CPU 系统之上,可以用过 child_process . fork 开启多个进程( Node . js 在 v0 . 8 版本之后新增了 Cluster 来实现多进程架构) ,即 多进程 + 单线程 模式。注意:开启多进程不是为了解决高并发,主要是解决了单进程模式下 Node . js CPU 利用率不足的情况,充分利用多核 CPU 的性能。 child_process 模块用于新建子进程。子进程的运行结果储存在系统缓存之中(最大 200KB ),等到子进程运行结束以后,主进程再用回调函数读取子进程的运行结果。 通过 child_process 模块,可以实现 1 个主进程,多个子进程的模式,主进程称为 master 进程,子进程又称工作进程。在子进程中不仅可以调用其他 node 程序,也可以执行非 node 程序以及 shell 命令等等,执行完子进程后,以流或者回调的形式返回 ```javascript child_process模块给予Node可以随意创建子进程(child_process)的能力。它提供了4个方 // 法用于创建子进程。 // spawn():启动一个子进程来执行命令。 // exec():启动一个子进程来执行命令,与spawn()不同的是其接口不同,它有一个回调函数获知子进程的状况。 // execFile():启动一个子进程来执行可执行文件。 // fork():与spawn()类似,不同点在于它创建Node的子进程只需指定要执行的JavaScript文 件模块即可。 // spawn()与exec()、execFile()不同的是,后两者创建时可以指定timeout属性设置超时时间, 一旦创建的进程运行超过设定的时间将会被杀死。 // exec()与execFile()不同的是,exec()适合执行已有的命令,execFile()适合执行文件。 // 类型 回调/异常 进程类型 执行类型 可设置超时 // spawn() × 任意 命令 × // exec() √ 任意 命令 √ // execFile() √ 任意 可执行文件 √ // fork() × Node JavaScript文件 ×
child_process.spawn (command[, args][, options]) 适用于返回大量数据,例如图像处理,二进制数据处理。
child_process.exec (command[, options][, callback ]) 适用于小量数据,maxBuffer 默认值为 200 * 1024 超出这个默认值将会导致程序崩溃,数据量过大可采用 spawn。
child_process.execFile (file[, args][, options][, callback ]) 类似 child_process.exec(),区别是不能通过 shell 来执行,不支持像 I/O 重定向和文件查找这样的行为
child_process.fork (modulePath[, args][, options]) 衍生新的进程,进程之间是相互独立的,每个进程都有自己的 V8 实例、内存,系统资源是有限的,不建议衍生太多的子进程出来,通长根据系统 CPU 核心数设置。
.exec()、.execFile()、.fork()底层都是通过.spawn()实现的。
.exec()、execFile()额外提供了回调,当子进程停止的时候执行
command 要运行的命令。
args 字符串参数列表。
options
cwd | 子进程的当前工作目录。
env 环境变量键值对。 默认值: process.env。
argv0 显式设置发送给子进程的 argv[0] 的值。 如果未指定,这将设置为 command。
stdio | 子进程的标准输入输出配置(参见 options.stdio)。
detached 准备子进程独立于其父进程运行。 具体行为取决于平台,参见 options.detached。
uid 设置进程的用户标识(参见 setuid(2))。
gid 设置进程的群组标识(参见 setgid(2))。
serialization 指定用于在进程之间发送消息的序列化类型。 可能的值为 ‘json’ 和 ‘advanced’。 有关更多详细信息,请参阅高级序列化。 默认值: ‘json’。
shell | 如果是 true,则在 shell 内运行 command。 在 Unix 上使用 ‘/bin/sh’,在 Windows 上使用 process.env.ComSpec。 可以将不同的 shell 指定为字符串。 请参阅 shell 的要求和默认的 Windows shell。 默认值: false (没有 shell)
windowsVerbatimArguments 在 Windows 上不为参数加上引号或转义。 在 Unix 上被忽略。 当指定了 shell 并且是 CMD 时,则自动设置为 true。 默认值: false。
windowsHide 隐藏通常在 Windows 系统上创建的子进程控制台窗口。 默认值: false。
signal 允许使用中止信号中止子进程。
timeout 允许进程运行的最长时间(以毫秒为单位)。 默认值: undefined。
killSignal | 当衍生的进程将被超时或中止信号杀死时要使用的信号值。 默认值: ‘SIGTERM’。
返回:
例一 const { spawn } = require(“child_process”);
const ls = spawn(‘ls’, [‘-al’]); //相当于执行 ls -al
ls.stdout.on(‘data’, function(data){
console.log(‘data from child: ‘ + data);
});
ls.stderr.on(‘data’, function(data){
console.log(‘error from child: ‘ + data);
});
ls.on(‘close’, function(code){
console.log(‘child exists with code: ‘ + code);
});
<a name = "c5VIb" ></a> ## 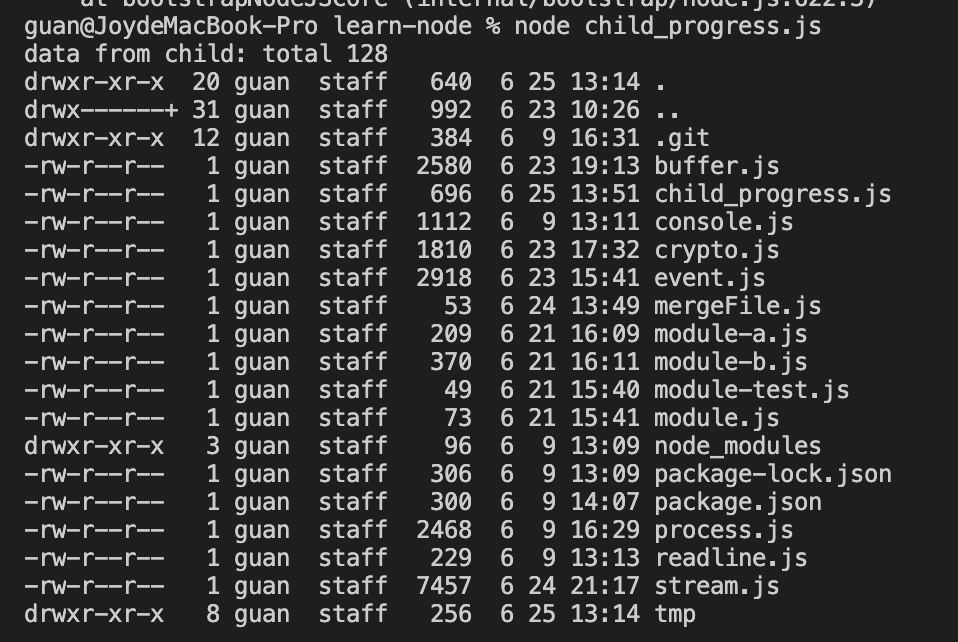 例二:声明使用shell const spawn = require(‘child_process’).spawn;
const ls = spawn(‘bash’,[‘-c’, ‘echo “hello nodejs” | wc’], {
stdio: ‘inherit’,
shell: true
});
ls.on(‘close’, function(code){
console.log(‘child exists with code: ‘ + code);
});
// wc 命令,是一个计算行数,单词数,和字母数的Linux 命令
1 0 1 child exists with code: 0
例三:错误处理 const spawn = require(‘child_process’).spawn;
const child = spawn(‘bad_command’);
//命令bad_command不存在
child.on(‘error’, (err) => {
console.log(‘Failed to start child process 1.’);
});
//参数不存在报错
const child2 = spawn(‘ls’, [‘nonexistFile’]);
child2.stderr.on(‘data’, function(data){
console.log(‘Error msg from process 2: ‘ + data);
});
child2.on(‘error’, (err) => {
console.log(‘Failed to start child process 2.’);
});
Failed to start child process 1.
Error msg from process 2: ls: nonexistFile: No such file or directory
例四:执行 echo "hello nodejs" | grep "nodejs" // echo “hello nodejs” | grep “nodejs”
const child_process = require(‘child_process’);
const echo = child_process.spawn(‘echo’, [‘hello nodejs’]);
const grep = child_process.spawn(‘grep’, [‘nodejs’]);
grep.stdout.setEncoding(‘utf8’);
echo.stdout.setEncoding(‘utf8’);
echo.stdout.on(‘data’, function(data){
grep.stdin.write(data);
});
echo.on(‘close’, function(code){
if(code!==0){
console.log(‘echo exists with code: ‘ + code);
}
grep.stdin.end();
});
grep.stdout.on(‘data’, function(data){
console.log(‘grep: ‘ + data);
});
grep.on(‘close’, function(code){
if(code!==0){
console.log(‘grep exists with code: ‘ + code);
}
});
const spwan = require(‘child_process’).spawn;
const grep = spwan(‘grep’,[‘nodejs’]);
grep.stdin.write(‘hello nodejs \n hello javascript \n i like nodejs’);
grep.stdin.end();
grep.stdout.on(‘data’, data=>{
process.stdout.write(data,’\n’); //=>相当于console.log
})
例五: pipe 流 const child = require(‘child_process’);
const cat = child.spawn(‘cat’,[‘./tmp/file2.txt’]);
const sort = child.spawn(‘sort’);
const uniq = child.spawn(‘uniq’);
sort.stdout.setEncoding(‘utf8’);
uniq.stdout.setEncoding(‘utf8’);
cat.stdout.pipe(sort.stdin);
sort.stdout.on(‘data’,data=> console.log(‘sort’,data));
sort.stdout.pipe(uniq.stdin);
uniq.stdout.on(‘data’,data=> console.log(‘uniq’,data));
uniq.stdout.pipe(process.stdout);
<a name = "OzgIK" ></a> ### exec 默认地,spawn 函数并没有创建一个 shell 去执行我们传入地命令。这使得它比 exec 函数执行稍微高效一点儿,exec 创建了个 shell。exec 函数有另一个主要地区别。将命令的输出放到缓冲区,并且将整个输出值传递给一个回调(而不是像 spawn 那样使用流)。 <br /> exec 函数将输出放入缓存区,并且将它作为 stdout 传递给回调函数(exec 函数的第二个参数)。stdout 是我们想要打印的命令的输出。 <br /> 如果期望的数据很大,那么建议使用 spawn 函数,因为数据可以被标准的 IO 对象流化(streamed)。 child_process.exec(command[, options][, callback])
command 要运行的命令,参数以空格分隔。
options
cwd | 子进程的当前工作目录。 默认值: process.cwd()。
env 环境变量键值对。 默认值: process.env。
encoding 默认值: ‘utf8’
shell 用于执行命令的 shell。 请参阅 shell 的要求和默认的 Windows shell。 默认值: Unix 上是 ‘/bin/sh’,Windows 上是 process.env.ComSpec。
signal 允许使用中止信号中止子进程。
timeout 默认值: 0
maxBuffer 标准输出或标准错误上允许的最大数据量(以字节为单位)。 如果超过,则子进程将终止并截断任何输出。 请参阅 maxBuffer 和 Unicode 的注意事项。 默认值: 1024 * 1024。
killSignal | 默认值: ‘SIGTERM’
uid 设置进程的用户标识(参见 setuid(2))。
gid 设置进程的群组标识(参见 setgid(2))。
windowsHide 隐藏通常在 Windows 系统上创建的子进程控制台窗口。 默认值: false。
callback 当进程终止时使用输出调用。
error
stdout |
stderr |
返回:
``` const { exec } = require("child_process"); exec("find . -type f | wc -l", (err, stdout, stderr) => { if (err) { console.error(` exec error : $ { err } `); return; } console.log(` Number of files $ { stdout } `); }); exec("ls ./tmp", function(error, stdout, stderr) { if (error) { console.error("error: " + error); return; } console.log("stdout: \n" + stdout); });
如果你学要执行一个文件不需要使用 shell,exec 函数就是你所需要的。它表现的和 exec 函数一样,但是不用 shell,这让它更高效一点儿。在 windows 上面,一些文件如 .bat 和 .cmd 凭它们自己不能被执行,这些文件不能被 execFile 执行,执行它们 需要 exec 或者将 shell 设置为 true 的 spawn 函数。
child_process . execFile ( file [, args ][, options ][, callback ]) file <string> 要运行的可执行文件的名称或路径。 args < string []> 字符串参数列表。 options < Object > cwd <string> | < URL > 子进程的当前工作目录。 env < Object > 环境变量键值对。 默认值: process . env 。 encoding <string> 默认值: 'utf8' timeout <number> 默认值: 0 maxBuffer <number> 标准输出或标准错误上允许的最大数据量(以字节为单位)。 如果超过,则子进程将终止并截断任何输出。 请参阅 maxBuffer 和 Unicode 的注意事项。 默认值: 1024 * 1024 。 killSignal <string> | <integer> 默认值: 'SIGTERM' uid <number> 设置进程的用户标识(参见 setuid ( 2 ))。 gid <number> 设置进程的群组标识(参见 setgid ( 2 ))。 windowsHide <boolean> 隐藏通常在 Windows 系统上创建的子进程控制台窗口。 默认值: false 。 windowsVerbatimArguments <boolean> 在 Windows 上不为参数加上引号或转义。 在 Unix 上被忽略。 默认值: false 。 shell <boolean> | <string> 如果是 true ,则在 shell 内运行 command 。 在 Unix 上使用 '/bin/sh' ,在 Windows 上使用 process . env . ComSpec 。 可以将不同的 shell 指定为字符串。 请参阅 shell 的要求和默认的 Windows shell 。 默认值: false (没有 shell ) signal < AbortSignal > 允许使用中止信号中止子进程。 callback < Function > 进程终止时使用输出调用。 error < Error > stdout <string> | < Buffer > stderr <string> | < Buffer > 返回: < ChildProcess > const { execFile } = require ( "child_process" ); execFile ( "echo" , [ "hello" , "world" ], function ( err , stdout ) { console . log ( stdout ); });
fork 函数是spawn 函数的另一种衍生(fork) node 进程的形式。spawn 和 fork 之间最大的不同是当使用 fork 函数时,子进程的通信通道被建立了,因此我们可以在子进程里通过全局的 process 使用 send 函数,在父子进程之间交换信息。通过 EventEmitter 模块接口实现的。
child_process . fork ( modulePath [, args ][, options ]) modulePath <string> 要在子进程中运行的模块。 args < string []> 字符串参数列表。 options < Object > cwd <string> | < URL > 子进程的当前工作目录。 detached <boolean> 准备子进程独立于其父进程运行。 具体行为取决于平台,参见 options . detached 。 env < Object > 环境变量键值对。 默认值: process . env 。 execPath <string> 用于创建子进程的可执行文件。 execArgv < string []> 传给可执行文件的字符串参数列表。 默认值: process . execArgv 。 gid <number> 设置进程的群组标识(参见 setgid ( 2 ))。 serialization <string> 指定用于在进程之间发送消息的序列化类型。 可能的值为 'json' 和 'advanced' 。 有关更多详细信息,请参阅高级序列化。 默认值: 'json' 。 signal < AbortSignal > 允许使用中止信号关闭子进程。 killSignal <string> | <integer> 当衍生的进程将被超时或中止信号杀死时要使用的信号值。 默认值: 'SIGTERM' 。 silent <boolean> 如果为 true ,则子进程的标准输入、标准输出和标准错误将通过管道传输到父进程,否则它们将从父进程继承,有关详细信息,请参阅 child_process . spawn () 的 stdio 的 'pipe' 和 'inherit' 选项。 默认值: false 。 stdio < Array > | <string> 参见 child_process . spawn () 的 stdio 。 提供此选项时,它会覆盖 silent 。 如果使用数组变体,则它必须恰好包含一个值为 'ipc' 的条目,否则将抛出错误。 例如 [ 0 , 1 , 2 , 'ipc' ]。 uid <number> 设置进程的用户标识(参见 setuid ( 2 ))。 windowsVerbatimArguments <boolean> 在 Windows 上不为参数加上引号或转义。 在 Unix 上被忽略。 默认值: false 。 timeout <number> 允许进程运行的最长时间(以毫秒为单位)。 默认值: undefined 。 返回: < ChildProcess > const { fork } = require ( "child_process" ); // 1、默认 silent 为 false,子进程会输出 output from the child3 fork ( './tmp/child_process.js' , { silent : false }); // 2、设置 silent 为 true,则子进程不会输出 fork ( './tmp/child_process.js' , { silent : true }); // 3、通过 stdout 属性,可以获取到子进程输出的内容 const child = fork ( "./tmp/child_process.js" , { silent : false }); child . stdout . setEncoding ( 'utf8' ); child . stdout . on ( "data" , function ( data ) { console . log ( "stdout 中输出:" , data ); });
on-close 事件:子进程的 stdio 流关闭时触发;
process . on ( 'message' , ( msg ) => { console . log ( 'message from parent:' , msg ); }); let counter = 0 ; setInterval (() => { process . send ({ counter : counter ++}); }, 1000 ); const { fork } = require ( 'child_process' ); const forked = fork ( './tmp/child_process.js' ); forked . on ( 'message' , ( msg ) => { console . log ( 'messsgae from child' , msg ); }); forked . send ({ hello : 'world' }); 启动服务,分别 curl localhost:3000 和 localhost:3000/compute
const http = require ( 'http' ); const server = http . createServer (); const longComputation = () => { let sum = 0 ; console . info ( '计算开始' ); console . time ( '计算耗时' ); for ( let i = 0 ; i < 1e10 ; i ++) { sum += i }; console . info ( '计算结束' ); console . timeEnd ( '计算耗时' ); return sum ; }; server . on ( 'request' , ( req , res ) => { if ( req . url === '/compute' ) { const sum = longComputation (); return res . end ( `Sum is ${sum}` ); } else { res . end ( 'Ok' ); } }); server . listen ( 3000 , '127.0.0.1' , () => { console . log ( `server started at http://127.0.0.1:${3000}` ); }); //当请求 /compute 时,服务器将不能处理其他的请求 const http = require ( "http" ); const fork = require ( "child_process" ). fork ; const server = http . createServer (( req , res ) => { if ( req . url == "/compute" ) { const compute = fork ( "./tmp/child_compute.js" ); compute . send ( "开启一个新的子进程" ); // 当一个子进程使用 process.send() 发送消息时会触发 'message' 事件 compute . on ( "message" , sum => { res . end ( `Sum is ${sum}` ); compute . kill (); }); // 子进程监听到一些错误消息退出 compute . on ( "close" , ( code , signal ) => { console . log ( `收到close事件,子进程收到信号 ${signal} 而终止,退出码 ${code}` ); compute . kill (); }); console . log ( '继续执行其他……' ) } else { res . end ( `ok` ); } }); server . listen ( 3000 , "127.0.0.1" , () => { console . log ( `server started at http://127.0.0.1:${3000}` ); }); //当我们收到需要长时间计算的请求时,可以执行它,而主线程一点儿也不会被阻塞,可以处理其他的请求。 多进程架构服务
const http = require ( 'http' ); const server = http . createServer (( req , res ) => { res . writeHead ( 200 , { 'Content-Type' : 'text/plan' }); res . end ( '子进程请求返回I am worker, pid: ' + process . pid + ', ppid: ' + process . ppid ); throw new Error ( 'worker process exception!' ); // 测试异常进程退出、重建 }); let worker ; process . title = 'node-worker' ; //接收主进程消息 process . on ( 'message' , function ( message , sendHandle ) { if ( message === 'server' ) { worker = sendHandle ; worker . on ( 'connection' , function ( socket ) { server . emit ( 'connection' , socket ); }); } }); process . on ( 'uncaughtException' , function ( err ) { console . log ( err ); process . send ({ act : 'suicide' }); worker . close ( function () { process . exit ( 1 ); }) }) 当父子进程之间建立 IPC 通道之后,通过子进程对象的 send 方法发送消息,第二个参数 sendHandle 就是句柄,可以是 TCP套接字、TCP服务器、UDP套接字等,为了解决上面多进程端口占用问题,我们将主进程的 socket 传递到子进程
//****************DEMO6:多进程 ********** */ const fork = require ( "child_process" ). fork ; const cpus = require ( "os" ). cpus (); console . log ( "cpu个数" , cpus . length ); process . title = "node-master" ; const server = require ( "net" ). createServer (); server . listen ( 3000 ); const workers = {}; const createWorker = () => { const worker = fork ( "./tmp/child_work.js" ); //接收子进程消息 worker . on ( "message" , function ( message ) { if ( message . act === "suicide" ) { createWorker (); } }); //子进程退出 worker . on ( "exit" , function ( code , signal ) { console . log ( "worker process exited, code: %s signal: %s" , code , signal ); delete workers [ worker . pid ]; }); //向子进程发送消息 worker . send ( "server" , server ); workers [ worker . pid ] = worker ; console . log ( "worker process created, pid: %s ppid: %s" , worker . pid , process . pid ); }; for ( let i = 0 ; i < cpus . length ; i ++) { createWorker (); } process . once ( "SIGINT" , close . bind ( this , "SIGINT" )); // kill(2) Ctrl-C process . once ( "SIGQUIT" , close . bind ( this , "SIGQUIT" )); // kill(3) Ctrl-\ process . once ( "SIGTERM" , close . bind ( this , "SIGTERM" )); // kill(15) default process . once ( "exit" , close . bind ( this )); function close ( code ) { console . log ( "进程退出!" , code ); if ( code !== 0 ) { for ( let pid in workers ) { console . log ( "master process exited, kill worker pid: " , pid ); workers [ pid ]. kill ( "SIGINT" ); } } process . exit ( 0 ); }
每个进程的用户地址空间都是独立的,一般而言是不能互相访问的,但内核空间是每个进程都共享的,所以进程之间要通信必须通过内核。
ps auxf | grep mysql 上面命令行里的「|」竖线就是一个管道 ,它的功能是将前一个命令(ps auxf)的输出,作为后一个命令(grep mysql)的输入,从这功能描述,可以看出管道传输数据是单向的 ,如果想相互通信,我们需要创建两个管道才行。命名管道 ,也被叫做 FIFO,因为数据是先进先出的传输方式。
$ mkfifo myPipe myPipe 就是这个管道的名称,基于 Linux 一切皆文件的理念,所以管道也是以文件的方式存在,我们可以用 ls 看一下,这个文件的类型是 p,也就是 pipe(管道) 的意思:
接下来,我们往 myPipe 这个管道写入数据:
$ echo "hello" > myPipe // 将数据写进管道 // 停住了 ... 发现命令执行后就停在这了,这是因为管道里的内容没有被读取,只有当管道里的数据被读完后,命令才可以正常退出。
$ cat < myPipe // 读取管道里的数据 guanqingchao first pipe 可以看到,管道里的内容被读取出来了,并打印在了终端上,另外一方面,echo 那个命令也正常退出了。管道这种通信方式效率低,不适合进程间频繁地交换数据 。当然,它的好处,自然就是简单,同时也我们很容易得知管道里的数据已经被另一个进程读取了。
管道原理
所谓的管道,就是内核里面的一串缓存 。从管道的一段写入的数据,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据。另外,管道传输的数据是无格式的流且大小受限。
返回了两个描述符,一个是管道的读取端描述符 fd[0],另一个是管道的写入端描述符 fd[1]。注意,这个匿名管道是特殊的文件,只存在于内存,不存于文件系统中
看到这,你可能会有疑问了,这两个描述符都是在一个进程里面,并没有起到进程间通信的作用,怎么样才能使得管道是跨过两个进程的呢?创建的子进程会复制父进程的文件描述符 ,这样就做到了两个进程各有两个「 fd[0] 与 fd[1]」,两个进程就可以通过各自的 fd 写入和读取同一个管道文件实现跨进程通信了。
父进程关闭读取的 fd[0],只保留写入的 fd[1]; 子进程关闭写入的 fd[1],只保留读取的 fd[0];
前面说到管道的通信方式是效率低的,因此管道不适合进程间频繁地交换数据。
对于这个问题,消息队列 的通信模式就可以解决。比如,A 进程要给 B 进程发送消息,A 进程把数据放在对应的消息队列后就可以正常返回了,B 进程需要的时候再去读取数据就可以了。同理,B 进程要给 A 进程发送消息也是如此。
再来,消息队列是保存在内核中的消息链表 ,在发送数据时,会分成一个一个独立的数据单元,也就是消息体(数据块),消息体是用户自定义的数据类型,消息的发送方和接收方要约定好消息体的数据类型,所以每个消息体都是固定大小的存储块,不像管道是无格式的字节流数据。如果进程从消息队列中读取了消息体,内核就会把这个消息体删除。
消息队列生命周期随内核,如果没有释放消息队列或者没有关闭操作系统,消息队列会一直存在,而前面提到的匿名管道的生命周期,是随进程的创建而建立,随进程的结束而销毁。一是通信不及时,二是附件也有大小限制 ,这同样也是消息队列通信不足的点。
消息队列不适合比较大数据的传输 ,因为在内核中每个消息体都有一个最大长度的限制,同时所有队列所包含的全部消息体的总长度也是有上限。在 Linux 内核中,会有两个宏定义 MSGMAX 和 MSGMNB,它们以字节为单位,分别定义了一条消息的最大长度和一个队列的最大长度。消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销 ,因为进程写入数据到内核中的消息队列时,会发生从用户态拷贝数据到内核态的过程,同理另一进程读取内核中的消息数据时,会发生从内核态拷贝数据到用户态的过程。
消息队列的读取和写入的过程,都会有发生用户态与内核态之间的消息拷贝过程。那共享内存 的方式,就很好的解决了这一问题。
现代操作系统,对于内存管理,采用的是虚拟内存技术,也就是每个进程都有自己独立的虚拟内存空间,不同进程的虚拟内存映射到不同的物理内存中。所以,即使进程 A 和 进程 B 的虚拟地址是一样的,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中 。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去,大大提高了进程间通信的速度。
用了共享内存通信方式,带来新的问题,那就是如果多个进程同时修改同一个共享内存,很有可能就冲突了。例如两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了。
为了防止多进程竞争共享资源,而造成的数据错乱,所以需要保护机制,使得共享的资源,在任意时刻只能被一个进程访问。正好,信号量 就实现了这一保护机制。
信号量其实是一个整型的计数器,主要用于实现进程间的互斥与同步,而不是用于缓存进程间通信的数据 。
一个是 P 操作 ,这个操作会把信号量减去 -1,相减后如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可正常继续执行。 另一个是 V 操作 ,这个操作会把信号量加上 1,相加后如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运行;相加后如果信号量 > 0,则表明当前没有阻塞中的进程;
P 操作是用在进入共享资源之前,V 操作是用在离开共享资源之后,这两个操作是必须成对出现的。
进程 A 在访问共享内存前,先执行了 P 操作,由于信号量的初始值为 1,故在进程 A 执行 P 操作后信号量变为 0,表示共享资源可用,于是进程 A 就可以访问共享内存。 若此时,进程 B 也想访问共享内存,执行了 P 操作,结果信号量变为了 -1,这就意味着临界资源已被占用,因此进程 B 被阻塞。 直到进程 A 访问完共享内存,才会执行 V 操作,使得信号量恢复为 0,接着就会唤醒阻塞中的线程 B,使得进程 B 可以访问共享内存,最后完成共享内存的访问后,执行 V 操作,使信号量恢复到初始值 1。
可以发现,信号初始化为 1,就代表着是互斥信号量 ,它可以保证共享内存在任何时刻只有一个进程在访问,这就很好的保护了共享内存。
另外,在多进程里,每个进程并不一定是顺序执行的,它们基本是以各自独立的、不可预知的速度向前推进,但有时候我们又希望多个进程能密切合作,以实现一个共同的任务。
如果进程 B 比进程 A 先执行了,那么执行到 P 操作时,由于信号量初始值为 0,故信号量会变为 -1,表示进程 A 还没生产数据,于是进程 B 就阻塞等待; 接着,当进程 A 生产完数据后,执行了 V 操作,就会使得信号量变为 0,于是就会唤醒阻塞在 P 操作的进程 B; 最后,进程 B 被唤醒后,意味着进程 A 已经生产了数据,于是进程 B 就可以正常读取数据了。
可以发现,信号初始化为 0,就代表着是同步信号量 ,它可以保证进程 A 应在进程 B 之前执行。
上面说的进程间通信,都是常规状态下的工作模式。对于异常情况下的工作模式,就需要用「信号」的方式来通知进程。 唯一的异步通信机制 ,因为可以在任何时候发送信号给某一进程,一旦有信号产生,我们就有下面这几种,用户进程对信号的处理方式。
1.执行默认操作 。Linux 对每种信号都规定了默认操作,例如,上面列表中的 SIGTERM 信号,就是终止进程的意思。Core 的意思是 Core Dump,也即终止进程后,通过 Core Dump 将当前进程的运行状态保存在文件里面,方便程序员事后进行分析问题在哪里。2.捕捉信号 。我们可以为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。3.忽略信号 。当我们不希望处理某些信号的时候,就可以忽略该信号,不做任何处理。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SEGSTOP,它们用于在任何时候中断或结束某一进程。
前面提到的管道、消息队列、共享内存、信号量和信号都是在同一台主机上进行进程间通信,那要想跨网络与不同主机上的进程之间通信,就需要 Socket 通信了。
实际上,Socket 通信不仅可以跨网络与不同主机的进程间通信,还可以在同主机上进程间通信。
int socket ( int domain , int type , int protocal ) 三个参数分别代表:
domain 参数用来指定协议族,比如 AF_INET 用于 IPV4、AF_INET6 用于 IPV6、AF_LOCAL/AF_UNIX 用于本机; type 参数用来指定通信特性,比如 SOCK_STREAM 表示的是字节流,对应 TCP、SOCK_DGRAM 表示的是数据报,对应 UDP、SOCK_RAW 表示的是原始套接字; protocal 参数原本是用来指定通信协议的,但现在基本废弃。因为协议已经通过前面两个参数指定完成,protocol 目前一般写成 0 即可;
根据创建 socket 类型的不同,通信的方式也就不同:
实现 TCP 字节流通信: socket 类型是 AF_INET 和 SOCK_STREAM; 实现 UDP 数据报通信:socket 类型是 AF_INET 和 SOCK_DGRAM; 实现本地进程间通信: 「本地字节流 socket 」类型是 AF_LOCAL 和 SOCK_STREAM,「本地数据报 socket 」类型是 AF_LOCAL 和 SOCK_DGRAM。另外,AF_UNIX 和 AF_LOCAL 是等价的,所以 AF_UNIX 也属于本地 socket;
接下来,简单说一下这三种通信的编程模式。
服务端和客户端初始化 socket,得到文件描述符; 服务端调用 bind,将绑定在 IP 地址和端口; 服务端调用 listen,进行监听; 服务端调用 accept,等待客户端连接; 客户端调用 connect,向服务器端的地址和端口发起连接请求; 服务端 accept 返回用于传输的 socket 的文件描述符; 客户端调用 write 写入数据;服务端调用 read 读取数据; 客户端断开连接时,会调用 close,那么服务端 read 读取数据的时候,就会读取到了 EOF,待处理完数据后,服务端调用 close,表示连接关闭。
这里需要注意的是,服务端调用 accept 时,连接成功了会返回一个已完成连接的 socket,后续用来传输数据。两个 」 socket,一个叫作监听 socket ,一个叫作已完成连接 socket 。
对于 UDP 来说,不需要要维护连接,那么也就没有所谓的发送方和接收方,甚至都不存在客户端和服务端的概念,只要有一个 socket 多台机器就可以任意通信,因此每一个 UDP 的 socket 都需要 bind。
针对本地进程间通信的 socket 编程模型同一台主机上进程间通信 的场景:
本地 socket 的编程接口和 IPv4 、IPv6 套接字编程接口是一致的,可以支持「字节流」和「数据报」两种协议; 本地 socket 的实现效率大大高于 IPv4 和 IPv6 的字节流、数据报 socket 实现;
对于本地字节流 socket,其 socket 类型是 AF_LOCAL 和 SOCK_STREAM。绑定一个本地文件 ,这也就是它们之间的最大区别。
守护进程运行在后台不受终端的影响,什么意思呢?Node.js 开发的同学们可能熟悉,当我们打开终端执行 node app.js 开启一个服务进程之后,这个终端就会一直被占用,如果关掉终端,服务就会断掉,即前台运行模式。如果采用守护进程进程方式,这个终端我执行 node app.js 开启一个服务进程之后,我还可以在这个终端上做些别的事情,且不会相互影响。
创建步骤
创建子进程:使用 spawn 创建子进程 在子进程中创建新会话(调用系统函数 setsid):options.detached 为 true 可以使子进程在父进程退出后继续运行,设置 (系统层会调用 setsid 方法),参考 options_detached 改变子进程工作目录(如:“/” 或 “/usr/ 等):options.cwd 指定当前子进程工作目录若不做设置默认继承当前工作目录 父进程终止:运行 daemon.unref() 退出父进程,参考 options.stdio
```
const spawn = require(‘child_process’).spawn;
function startDaemon() {
const daemon = spawn(‘node’, [‘daemon.js’], {
cwd: ‘/‘,
detached : true,
stdio: ‘ignore’,
});
console . log ( '守护进程开启 父进程 pid: %s, 守护进程 pid: %s' , process . pid , daemon . pid ); daemon . unref (); }
startDaemon()
// /tmp/daemon.js
const fs = require(‘fs’);
const { Console } = require(‘console’);
// custom simple logger
const logger = new Console(fs.createWriteStream(‘../log/stderr.log’), fs.createWriteStream(‘../log/stdout.log’));
setInterval(function() {
logger.log(‘daemon pid: ‘, process.pid, ‘, ppid: ‘, process.ppid);
}, 1000 * 10);
**孤儿进程 **父进程创建子进程之后,父进程退出了,但是父进程对应的一个或多个子进程还在运行,这些子进程会被系统的 init 进程收养,对应的进程 ppid 为 1 ,这就是孤儿进程 **僵尸进程 **使用 fork 可以创建子进程,正常情况进程退出,内核要释放掉进程所占用的资源:打开的文件、占用的内存等,但是进程的 PID 、退出状态、运行时间等会进行保留,直到父进程调用 wait / waitpid 来获取子进程的状态信息时,这些资源才会释放。< br />如果子进程退出之后,父进程没有调用 wait / waitpid 来获取子进程状态,那么保留的进程号将会一直被占用,且占用系统资源,称为僵死进程或僵尸进程。< br />元凶不是僵尸进程而是其父进程,所以我们把元凶给杀掉之后,僵尸进程会变为孤儿进程被系统的 init 进程 pid = 1 的进程所收养, init 进程会对这些孤儿进程进行管理(调用 wait / waitpid )释放掉其占用的资源。 < a name = "WYuO4" ></ a > ## Cluster [参考- Cluster ]( https : //zhuanlan.zhihu.com/p/36728299)<br />[参考-当我们谈论cluster时在讨论什么](https://github.com/hustxiaoc/node.js/issues/11)<br />[cluster-源码](https://cnodejs.org/topic/56e84480833b7c8a0492e20c)<br />[源码Cluster](https://developer.aliyun.com/article/717323) Node . js 诞生之初就遭到不少这样的吐槽,当然这些都早已不是问题了。 > 1 、可靠性低。< br /> 2 、单进程,单线程,只支持单核 CPU ,不能充分的利用多核 CPU 服务器。一旦这个进程崩掉,那么整个 web 服务就崩掉了。 开发 web 服务器的时候,每个 request 都在单独的线程中处理,即使某一个请求发生很严重的错误也不会影响到其它请求。 Node . js 会在一个线程中处理大量请求,如果处理某个请求时产生一个没有被捕获到的异常将导致整个进程的退出,已经接收到的其它连接全部都无法处理,对一个 web 服务器来说,这绝对是致命的灾难。 应用部署到多核服务器时,为了充分利用多核 CPU 资源一般启动多个 Node . js 进程提供服务,这时就会使用到 Node . js 内置的 cluster 模块了。相信大多数的 Node . js 开发者可能都没有直接使用到 cluster , cluster 模块对 child_process 模块提供了一层封装,可以说是为了发挥服务器多核优势而量身定做的。简单的一个 fork ,不需要开发者修改任何的应用代码便能够实现多进程部署。当下最热门的带有负载均衡功能的 Node . js 应用进程管理器 pm2 便是最好的一个例子,开发的时候完全不需要关注多进程场景,剩余的一切都交给 pm2 处理,与开发者的应用代码完美分离。< br /> pm2 start app . js < br /> pm2 确实非常强大,但本文并不讲解 pm2 的工作原理,而是从更底层的进程通信讲起,为大家揭秘使用 Node . js 开发 web 应用时,使用 cluster 模块实现多进程部署的原理。 < a name = "CIyig" ></ a > ### 负载均衡 - 惊群 最初的 Node . js 多进程模型就是这样实现的, master 进程创建 socket ,绑定到某个地址以及端口后,自身不调用 listen 来监听连接以及 accept 连接,而是将该 socket 的 fd 传递到 fork 出来的 worker 进程, worker 接收到 fd 后再调用 listen , accept 新的连接。但实际一个新到来的连接最终只能被某一个 worker 进程 accpet 再做处理,至于是哪个 worker 能够 accept 到,开发者完全无法预知以及干预。这势必就导致了当一个新连接到来时,多个 worker 进程会产生竞争,最终由胜出的 worker 获取连接。< br />[](https://camo.githubusercontent.com/077a783e0be689462e136322fe33ad3f8485fe8486b3393f3348a6f1d3b2db9e/687474703a2f2f67746d7330342e616c6963646e2e636f6d2f7470732f69342f544231626578764b7058585858614d5858585833477757305658582d3432362d3239382e706e67)<br />为了进一步加深对这种模型的理解,我编写了一个非常简单的 demo。<br />worker const net = require(“net”);
process.on(“message”, function(m, handle) {
start(handle);
});
var buf = “hello nodejs”;
var res =
[“HTTP/1.1 200 OK”, “content-length:” + buf.length].join(“\r\n”) +
“\r\n\r\n” +
buf;
const resMap = {}
function start(server) {
server.listen();
server.onconnection = function(err, handle) {
console.log(“worker进程请求 got a connection on worker, pid = %d”, process.pid);
if(resMap[process.pid]){
resMap[process.pid]++
} else {
resMap[process.pid] = 1
}
console.log(‘请求情况’,resMap)
var socket = new net.Socket({
handle: handle
});
socket.readable = socket.writable = true;
socket.end(res);
};
}
master const net = require(‘net’);
const fork = require(‘child_process’).fork;
var handle = net._createServerHandle(‘0.0.0.0’, 3001);
for(var i=0;i<4;i++) {
fork(‘./tmp/cluster.js’).send({}, handle);
压测: ab - n10000 - c100 [ http : //127.0.0.1:3001/](http://127.0.0.1:3001/) guan@JoydeMacBook-Pro learn-node % ab -n10000 -c100 http://127.0.0.1:3001/
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software:
Server Hostname: 127.0.0.1
Server Port: 3001
Document Path: /
Document Length: 12 bytes
Concurrency Level: 100
Time taken for tests: 18.271 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 500000 bytes
HTML transferred: 120000 bytes
Requests per second: 547.30 [#/sec] (mean)
Time per request: 182.714 [ms] (mean)
Time per request: 1.827 [ms] (mean, across all concurrent requests)
Transfer rate: 26.72 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 91 67.7 79 594
Processing: 1 90 66.1 78 603
Waiting: 1 89 65.3 78 596
Total: 10 181 122.0 165 776
Percentage of the requests served within a certain time (ms)
50% 165
66% 230
75% 265
80% 272
90% 329
95% 369
98% 436
99% 455
100% 776 (longest request)
请求情况 { '4984' : 725 }< br />请求情况 { '4985' : 1402 }< br />请求情况 { '4986' : 5159 }< br />请求情况 { '4987' : 2778 } 相信到这里大家也应该知道这种多进程模型比较明显的问题了 - 多个进程之间会竞争 accpet 一个连接,产生惊群现象,效率比较低。 - 由于无法控制一个新的连接由哪个进程来处理,必然导致各 worker 进程之间的负载非常不均衡。 这其实就是著名的 "惊群" 现象。< br />简单说来,多线程/多进程等待同一个 socket 事件,当这个事件发生时,这些线程/进程被同时唤醒,就是惊群。可以想见,效率很低下,许多进程被内核重新调度唤醒,同时去响应这一个事件,当然只有一个进程能处理事件成功,其他的进程在处理该事件失败后重新休眠(也有其他选择)。这种性能浪费现象就是惊群。< br />惊群通常发生在 server 上,当父进程绑定一个端口监听 socket ,然后 fork 出多个子进程,子进程们开始循环处理(比如 accept )这个 socket 。每当用户发起一个 TCP 连接时,多个子进程同时被唤醒,然后其中一个子进程 accept 新连接成功,余者皆失败,重新休眠。 < a name = "OV9Tl" ></ a > ### 方案一:多个node实例+多个端口 集群内的 node 实例,各自监听不同的端口,再由反向代理实现请求到多个端口的分发。 - 优点:实现简单,各实例相对独立,这对服务稳定性有好处。 - 缺点:增加端口占用,进程之间通信比较麻烦。 现代的 web 服务器一般都会在应用服务器外面再添加一层负载均衡,比如目前使用最广泛的 nginx 。< br />利用 nginx 强大的反向代理功能,可以启动多个独立的 node 进程,分别绑定不同的端口,最后由 nginx 接收请求然后进行分配。 http {
upstream cluster {
server 127.0.0.1:3000;
server 127.0.0.1:3001;
server 127.0.0.1:3002;
server 127.0.0.1:3003;
}
server {
listen 80;
server_name www.domain.com;
location / {
proxy_pass http://cluster ;
}
}
}
这种方式就将负载均衡的任务完全交给了 nginx 处理,并且 nginx 本身也相当擅长。再加一个守护进程负责各个 node 进程的稳定性,这种方案也勉强行得通。但也有比较大的局限性,比如想增加或者减少一个进程时还得再去改下 nginx 的配置。该方案与 nginx 耦合度太高,实际项目中并不经常使用。 < a name = "nrVQM" ></ a > ### 方案二:主进程向子进程转发请求 ** fork **< br />本文中要讲解的 fork 是 cluster 模块中非常重要的一个方法,当然了,底层也是依赖上面提到的 fork 函数实现。 多个子进程便是通过在 master 进程中不断的调用 cluster . fork 方法构造出来。下面的结构图大家应该非常熟悉了。< br />[](https://camo.githubusercontent.com/d4ed4918aee3b5311639118827a087249aeb1c88727fcbcf28ff4bcb01d8c1b8/687474703a2f2f67746d7330312e616c6963646e2e636f6d2f7470732f69312f544231584e6e4e4a5658585858616e58705858517a412e395658582d3434372d3330302e706e67)<br />上面的图非常粗糙, 并没有告诉我们 master 与 worker 到底是如何分工协作的。Node.js 在这块做过比较大的改动,下面就细细的剖析开来。<br />集群内,创建一个主进程(master),以及若干个子进程(worker)。由master监听客户端连接请求,并根据特定的策略,转发给worker。 - 优点:通常只占用一个端口,通信相对简单,转发策略更灵活。 - 缺点:实现相对复杂,对主进程的稳定性要求较高。 var cluster = require(“cluster”);
var cpuNums = require(“os”).cpus().length;
var http = require(“http”);
const resMap = {};
if (cluster.isMaster) {
console.log(‘主进程’,process.pid)
for (var i = 0; i < cpuNums; i++) {
cluster.fork();
}
} else {
http
.createServer(function(req, res) {
if (resMap[process.pid]) {
resMap[process.pid]++;
} else {
resMap[process.pid] = 1;
}
console.log(“请求情况”, resMap);
res.end(response from worker ${process.pid},resMap);
})
.listen(3002);
console.log(Worker ${process.pid} started);
}
主进程 27694 < br /><br />发现请求均衡的转发到worker进程中<br />执行 lsof -i -P -n | grep 3002 node 27694 guan 35u IPv6 0xc869df0a3518897 0t0 TCP *:3002 (LISTEN)
理论上说如果多个进程监听同一个端口是会报端口冲突的,现在我们知道了, 8000 端口它并**不是被所有的进程全部的监听,仅受到 Master 进程的监听** ps - ef | grep 27694 查看主进程 502 27694 60380 0 3:02下午 ttys004 0:02.69 node cluster.js
502 27695 27694 0 3:02下午 ttys004 0:00.90 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27696 27694 0 3:02下午 ttys004 0:00.90 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27697 27694 0 3:02下午 ttys004 0:00.90 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27698 27694 0 3:02下午 ttys004 0:00.90 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27699 27694 0 3:02下午 ttys004 0:00.92 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27701 27694 0 3:02下午 ttys004 0:00.89 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27702 27694 0 3:02下午 ttys004 0:00.89 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27703 27694 0 3:02下午 ttys004 0:00.91 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27704 27694 0 3:02下午 ttys004 0:00.91 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27705 27694 0 3:02下午 ttys004 0:00.90 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27706 27694 0 3:02下午 ttys004 0:00.89 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 27707 27694 0 3:02下午 ttys004 0:00.90 /Users/guan/.nvm/versions/node/v10.16.3/bin/node /Users/guan/Desktop/learn-node/cluster.js
502 37907 66601 0 3:06下午 ttys005 0:00.00 grep 27694
清楚展示了 Worker 与 Master 的关系, Master 通过 cluster . fork () 这个方法创建的,本质上还是使用的 child_process . fork () 这个方法,怎么实现进程间端口共享呢? < a name = "PAg4m" ></ a > #### master、worker如何通信? 这个问题比较简单。 master 进程通过 cluster . fork () 来创建 worker 进程。 cluster . fork () 内部 是通过 child_process . fork () 来创建子进程。< br />也就是说: - master 进程、 worker 进程是父、子进程的关系。 - master 进程、 woker 进程可以通过 IPC 通道进行通信。(重要) < a name = "FEiiz" ></ a > #### 多个server实例,如何实现端口共享? 在前面的例子中,多个 woker 中创建的 server 监听了同个端口 3000 。通常来说,多个进程监听同个端口,系统会报错。< br />为什么我们的例子没问题呢?< br />秘密在于, net 模块中,对 listen () 方法进行了特殊处理。根据当前进程是 master 进程,还是 worker 进程: - master 进程:在该端口上正常监听请求。(没做特殊处理) - worker 进程:创建 server 实例。然后通过 IPC 通道,向 master 进程发送消息,让 master 进程也创建 server 实例,并在该端口上监听请求。当请求进来时, master 进程将请求转发给 worker 进程的 server 实例。 归纳起来,就是: master 进程监听特定端口,并将客户请求转发给 worker 进程。< br />“** Master 进程创建一个 Socket 并绑定监听到该目标端口,通过与子进程之间建立 IPC 通道之后,通过调用子进程的 send 方法,将 Socket (链接句柄)传递过去**”  - 创建 TCP 服务器时会在父进程中创建一个 server 并监听目标端口,新连接到达 Accept 这个 client 后,再通过 ipc 的高级方法将新连接的句柄(也就是这个 socket 的文件描述符)通过轮询的方式分配到一个子进程中,然后在这个子进程中通过 read 和 write 处理新连接的数据和请求,所以只有主进程会监听目标 ip 和端口。 - 创建 UDP 服务器,会共享在父进程中创建的 server 的句柄对象,并且在子进程中都会监听到跟对象相同的 ip 地址和端口上,所以创建 n 个子进程则会有 n + 1 个进程同时监听到目标 ip 和端口上。 < a name = "tpBke" ></ a > #### 多个server实例,来自客户端的请求如何分发到多个worker? 每当 worker 进程创建 server 实例来监听请求,都会通过 IPC 通道,在 master 上进行注册。当客户端请求到达, master 会负责将请求转发给对应的 worker 。< br /> 具体转发给哪个 worker ?这是由转发策略决定的。可以通过环境变量 NODE_CLUSTER_SCHED_POLICY 设置,也可以在 cluster . setupMaster ( options )时传入, 默认的转发策略是轮询( SCHED_RR )。< br />当有客户请求到达, master 会轮询一遍 worker 列表,找到第一个空闲的 worker ,然后将该请求转发给该 worker 。< br /> < a name = "BxRwt" ></ a > #### 负载均衡策略 - round-robin 所有请求是通过 master 进程分配的,要保证服务器负载比较均衡的分配到各个 worker 进程上,这就涉及到负载均衡策略了。 Node . js 默认采用的策略是 ** round - robin ** 时间片轮转法。 round - robin 是一种很常见的负载均衡算法, Nginx 上也采用了它作为负载均衡策略之一。它的原理很简单,每一次把来自用户的请求轮流分配给各个进程,从 1 开始,直到 N ( worker 进程个数),然后重新开始循环。这个算法的问题在于,它是假定各个进程或者说各个服务器的处理性能是一样的,但是如果请求处理间隔较长,就容易导致出现负载不均衡。因此我们通常在 Nginx 上采用另一种算法:** WRR **,加权轮转法。通过给各个服务器分配一定的权重,每次选出权重最大的,给其权重减 1 ,直到权重全部为 0 后,按照此时生成的序列轮询。< br />可以通过设置 NODE_CLUSTER_SCHED_POLICY 环境变量,或者通过 cluster . setupMaster ( options ) 来修改负载均衡策略。读到这里大家可以发现,我们可以 Nginx 做多机器集群上的负载均衡,然后用 Node . js Cluster 来实现单机多进程上的负载均衡。 < a name = "BFWmI" ></ a > ## < a name = "ZOqb2" ></ a > ## HTTP < a name = "rFUbP" ></ a > ## NET const net = require(‘net’);
const HOST = ‘127.0.0.1’;
const PORT = 3000;
// 创建一个 TCP 服务实例
const server = net.createServer();
// 监听端口
server.listen(PORT, HOST);
server.on(‘listening’, () => {
console.log(服务已开启在 ${HOST}:${PORT});
});
server.on(‘connection’, socket => {
// data 事件就是读取数据
socket.on(‘data’, buffer => {
const msg = buffer.toString();
console.log(msg);
// write 方法写入数据,发回给客户端 socket . write ( Buffer . from ( '你好 ' + msg )); }); })
server.on(‘close’, () => {
console.log(‘Server Close!’);
});
server.on(‘error’, err => {
if (err.code === ‘EADDRINUSE’) {
console.log(‘地址正被使用,重试中…’);
setTimeout (() => { server . close (); server . listen ( PORT , HOST ); }, 1000 ); } else { console . error ( '服务器异常:' , err ); } });
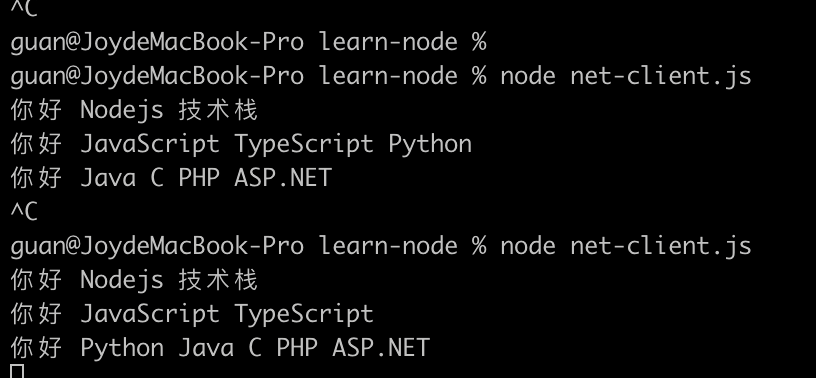
``` const net = require('net'); const client = net.createConnection({ host: '127.0.0.1', port: 3000 }); client.on('connect', () => { // 向服务器发送数据 client.write('Nodejs 技术栈'); setTimeout(() => { client.write('JavaScript '); client.write('TypeScript '); client.write('Python '); client.write('Java '); client.write('C '); client.write('PHP '); client.write('ASP.NET '); }, 1000); }) client.on('data', buffer => { console.log(buffer.toString()); }); // 例如监听一个未开启的端口就会报 ECONNREFUSED 错误 client.on('error', err => { console.error('服务器异常:', err); }); client.on('close', err => { console.log('客户端链接断开!', err); });
在客户端使用 client.write() 发送了多次数据,但是只有 setTimeout 之外的是正常的,setTimeout 里面连续发送的似乎并不是每一次一返回,而是会随机合并返回了,为什么呢?且看下面 TCP 的粘包问题介绍客户端(发送的一端)在发送之前会将短时间有多个发送的数据块缓冲到一起(发送端缓冲区),形成一个大的数据块一并发送 ,同样接收端也有一个接收端缓冲区 ,收到的数据先存放接收端缓冲区,然后程序从这里读取部分数据进行消费 ,这样做也是为了减少 I/O 消耗达到性能优化。