热身
二进制数据和文件
在 Web 开发中,当我们处理文件时(创建,上传,下载),经常会遇到二进制数据。另一个典型的应用场景是图像处理。
这些都可以通过 JavaScript 进行处理,而且二进制操作性能更高。
不过,在 JavaScript 中有很多种二进制数据格式,会有点容易混淆。仅举几个例子:
ArrayBuffer,Uint8Array,DataView,Blob,File及其他。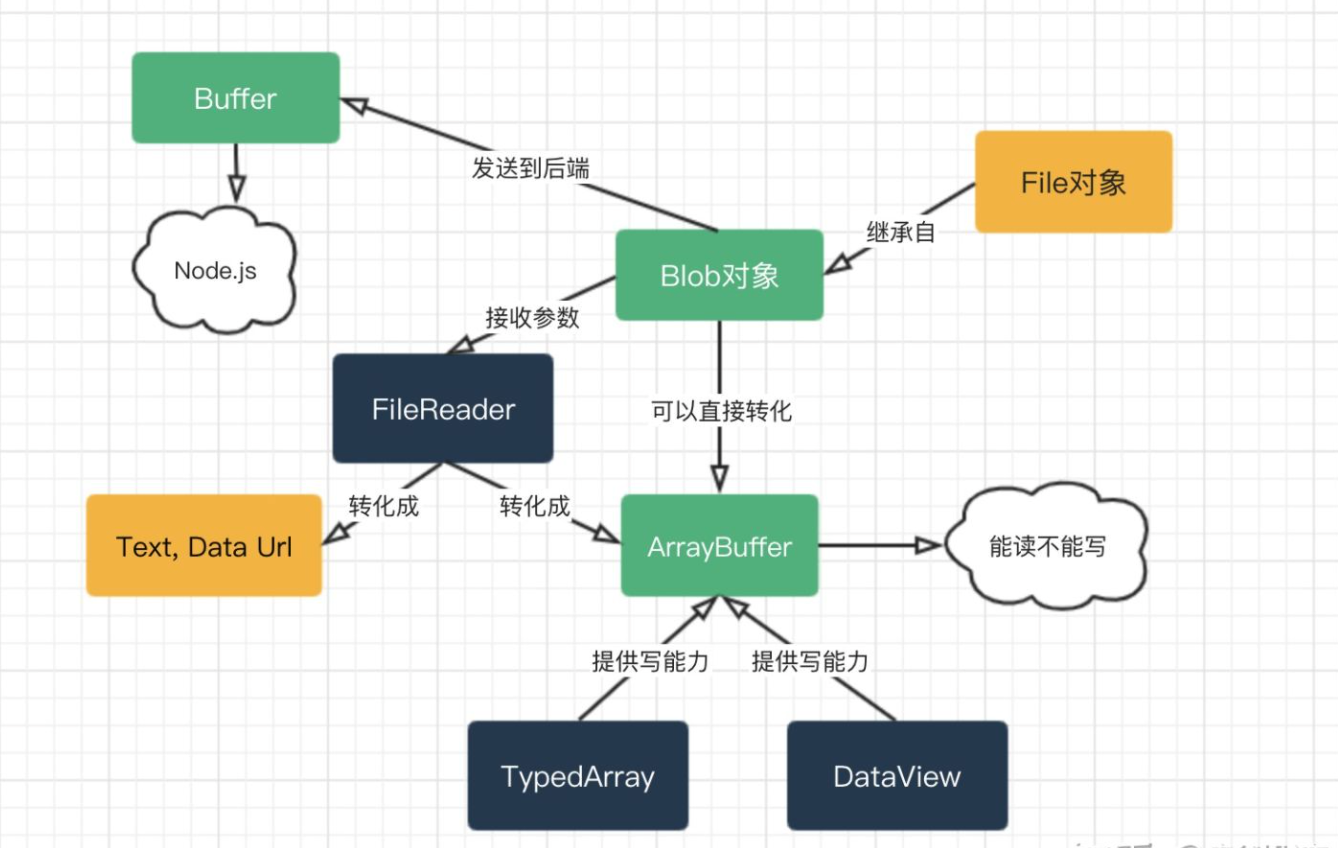
ArrayBuffer
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。 它是一个字节数组,通常在其他语言中称为“byte array”。 你不能直接操作ArrayBuffer的内容,而是要通过类型数组对象或DataView对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容。 ——————— From MDN
如何理解?
- ArrayBuffer是一个内存区域。它里面存储了什么?无从判断。只是一个原始的字节序列。
- 如要操作ArrayBuffer,我们需要使用“视图”对象。视图对象本身并不存储任何东西。它是一副“眼镜”,透过它来解释存储在ArrayBuffer中的字节。
TypedArray
类型化数组的行为类似于常规数组:具有索引,并且是可迭代的。TypedArray具有常规的Array方法,但有个明显的例外。我们可以遍历(iterate),map,slice,find和reduce等。
- Uint8Array—— 将ArrayBuffer中的每个字节视为 0 到 255 之间的单个数字(每个字节是 8 位,因此只能容纳那么多)。这称为 “8 位无符号整数”。
- Uint16Array—— 将每 2 个字节视为一个 0 到 65535 之间的整数。这称为 “16 位无符号整数”。
- Uint32Array—— 将每 4 个字节视为一个 0 到 4294967295 之间的整数。这称为 “32 位无符号整数”。
- Float64Array—— 将每 8 个字节视为一个5.0x10-324到1.8x10308之间的浮点数。
``` let buffer = new ArrayBuffer(16); // 创建一个长度为 16 B 的 buffernewTypedArray(buffer,[byteOffset],[length]);newTypedArray(object);newTypedArray(typedArray);newTypedArray(length);newTypedArray();
let view = new Uint32Array(buffer); // 将 buffer 视为一个 32 位整数的序列
alert(Uint32Array.BYTES_PER_ELEMENT); // 每个整数 4 个字节
console.log(view.length); // 4,它存储了 4 个整数 console.log(view.byteLength); // 16,字节中的大小
// 让我们写入一个值 view[0] = 123456;
// 遍历值 for(let num of view) { console.log(num); // 123456,然后 0,0,0(一共 4 个值) }
<a name="Avoe1"></a>#### DataView> **DataView**视图是一个可以从 二进制[ArrayBuffer](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/ArrayBuffer)对象中读写多种数值类型的底层接口,使用它时,不用考虑不同平台的[字节序](https://developer.mozilla.org/zh-CN/docs/Glossary/Endianness)问题。
new DataView(buffer, [byteOffset], [byteLength])
当我们将混合格式的数据存储在同一缓冲区(buffer)中时,DataView非常有用。例如,当我们存储一个成对序列(16 位整数,32 位浮点数)时,用DataView可以轻松访问它们。
// 4 个字节的二进制数组,每个都是最大值 255 let buffer = new Uint8Array([255, 255, 255, 255]).buffer;
let dataView = new DataView(buffer);
// 在偏移量为 0 处获取 8 位数字 alert( dataView.getUint8(0) ); // 255
// 现在在偏移量为 0 处获取 16 位数字,它由 2 个字节组成,一起解析为 65535 alert( dataView.getUint16(0) ); // 65535(最大的 16 位无符号整数)
// 在偏移量为 0 处获取 32 位数字 alert( dataView.getUint32(0) ); // 4294967295(最大的 32 位无符号整数)
dataView.setUint32(0, 0); // 将 4 个字节的数字设为 0,即将所有字节都设为 0
<a name="RZBk8"></a>## <a name="vp1vz"></a>#### 应用通过ArrayBuffer的格式读取本地数据<a name="rApCW"></a>## Blob[Blob.xmind](https://www.yuque.com/attachments/yuque/0/2021/xmind/248010/1619185180302-d3664d3b-48e4-43db-89e1-c0ed2fd19250.xmind)
new Blob(blobParts, options); blob.slice([byteStart], [byteEnd], [contentType]);
- blobParts是Blob/BufferSource/String类型的值的数组。- options可选对象:- type——Blob类型,通常是 MIME 类型,例如image/png,- endings—— 是否转换换行符,使Blob对应于当前操作系统的换行符(\r\n或\n)。默认为"transparent"(啥也不做),不过也可以是"native"(转换)。<a name="S5Lk8"></a>### 下载实现
let link = document.createElement(‘a’); link.download = ‘hello.txt’;
let blob = new Blob([‘Hello, world!’], {type: ‘text/plain’});
//URL.createObjectURL 取一个 Blob,并为其创建一个唯一的 URL,形式为 blob:
link.click();
URL.revokeObjectURL(link.href);
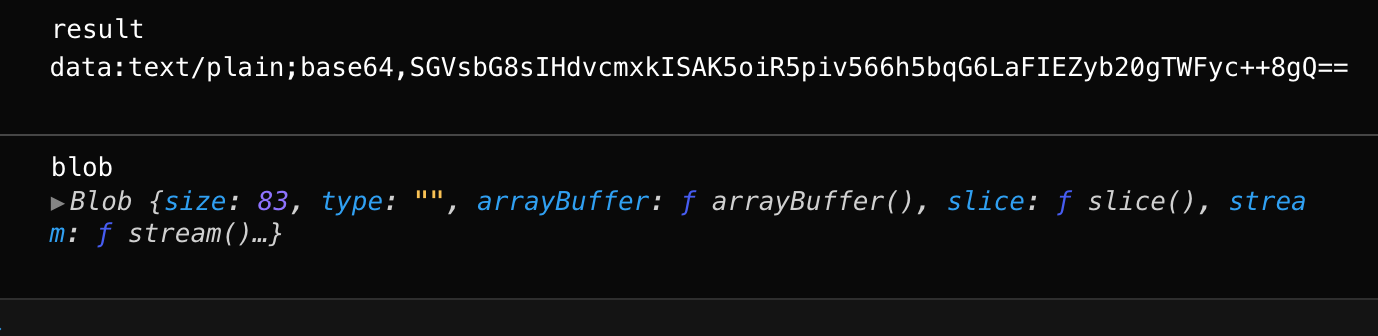
```let link = document.createElement('a');link.download = 'hello.txt';let blob = new Blob(['Hello, world!'], {type: 'text/plain'});let reader = new FileReader();reader.readAsDataURL(blob); // 将 Blob 转换为 base64 并调用 onloadreader.onload = function() {link.href = reader.result; // data urllink.click();};
File File Reader
File对象继承自Blob,并扩展了与文件系统相关的功能。
获取File:
- 构造函数
new File(fileParts, fileName, [options])
- fileParts—— Blob/BufferSource/String 类型值的数组。
- fileName—— 文件名字符串。
- options—— 可选对象:
- lastModified—— 最后一次修改的时间戳(整数日期)。
- 更常见的是,我们从或拖放或其他浏览器接口来获取文件。在这种情况下,file 将从操作系统(OS)获得 this 信息。
由于File是继承自Blob的,所以File对象具有相同的属性,附加:
- name—— 文件名,
- lastModified—— 最后一次修改的时间戳。
这就是我们从中获取File对象的方式:
<input type="file" onChange={(e) => handleChange(e)} />const handleChange = (e) => {let file = e.target.files[0];let reader = new FileReader();reader.readAsDataURL(file);reader.onload = function () {console.log(reader.result);};reader.onerror = function () {console.log(reader.error);};};
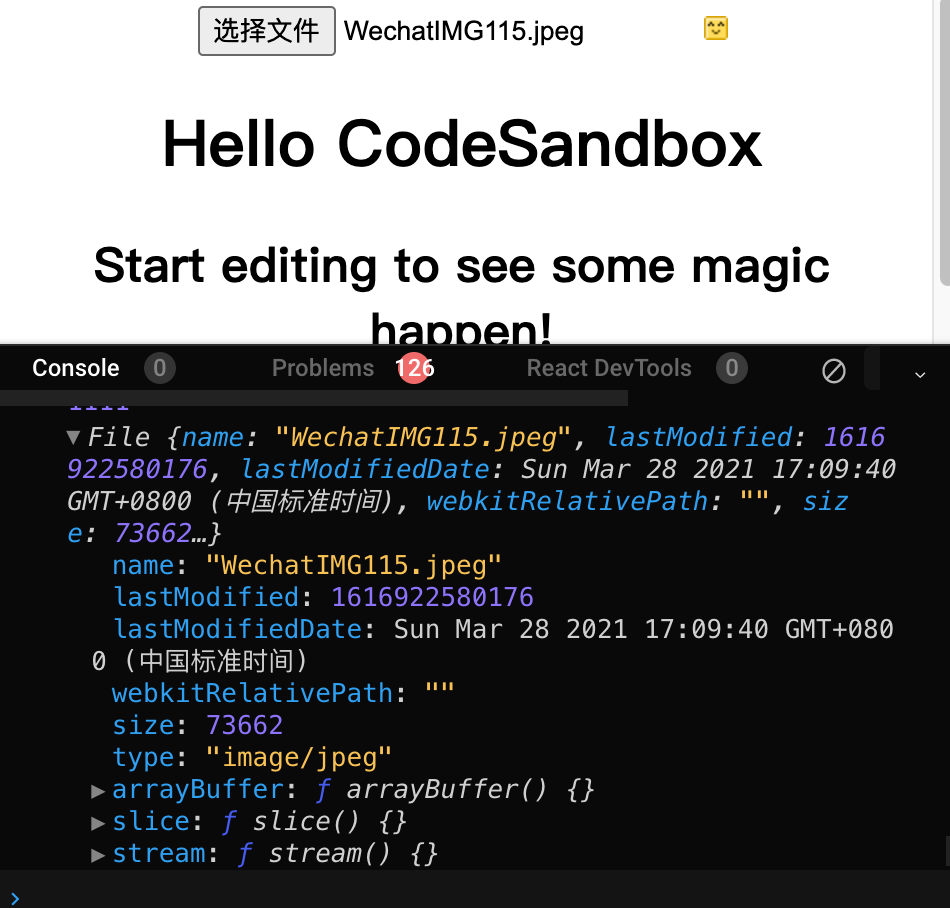
FileReader是一个对象,其唯一目的是从Blob(因此也从File)对象中读取数据。
它使用事件来传递数据,因为从磁盘读取数据可能比较费时间。
let reader = new FileReader(); // 没有参数
主要方法:
- readAsArrayBuffer(blob)—— 将数据读取为二进制格式的ArrayBuffer
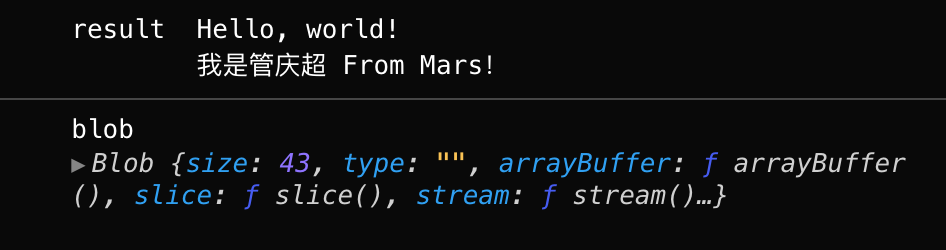
- readAsText(blob, [encoding])—— 将数据读取为给定编码(默认为utf-8编码)的文本字符串。
- readAsDataURL(blob)—— 读取二进制数据,并将其编码为 base64 的 data url。
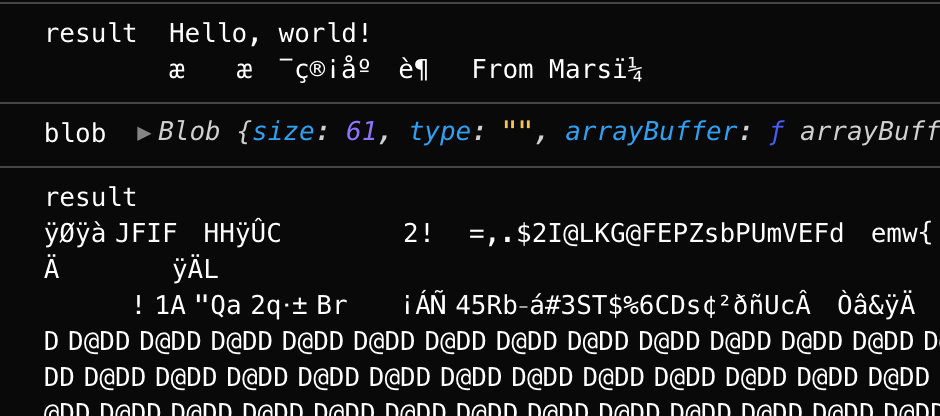
- readAsBinaryString 函数会按字节读取文件内容。然而诸如0101的二进制数据只能被机器识别,若想对外可见,还是需要进行一次编码,而readAsBinaryString的结果就是读取二进制并编码后的内容。尽管readAsBinaryString方法可以按字节读取文件,但由于读取后的内容被编码为字符,大小会受到影响,故不适合直接传输,也不推荐使用。如:测试的图片文件原大小为6764 字节,而通过readAsBinaryString读取后,内容被扩充到10092个字节
- abort()—— 取消操作。
read*方法的选择,取决于我们喜欢哪种格式,以及如何使用数据。
- readAsArrayBuffer—— 用于二进制文件,执行低级别的二进制操作。对于诸如切片(slicing)之类的高级别的操作,File是继承自Blob的,所以我们可以直接调用它们,而无需读取。
- readAsText—— 用于文本文件,当我们想要获取字符串时。
- readAsDataURL—— 当我们想在src中使用此数据,并将其用于img或其他标签时。正如我们在Blob一章中所讲的,还有一种用于此的读取文件的替代方案:URL.createObjectURL(file)。
读取过程中,有以下事件:
- loadstart—— 开始加载。
- progress—— 在读取过程中出现。
- load—— 读取完成,没有 error。
- abort—— 调用了abort()。
- error—— 出现 error。
- loadend—— 读取完成,无论成功还是失败。
读取完成后,我们可以通过以下方式访问读取结果:
- reader.result是结果(如果成功)
- reader.error是 error(如果失败)。
使用最广泛的事件无疑是load和error。
FileReader用于 blob
正如我们在Blob一章中所提到的,FileReader不仅可读取文件,还可读取任何 blob。
我们可以使用它将 blob 转换为其他格式:
- readAsArrayBuffer(blob)—— 转换为ArrayBuffer,
- readAsText(blob, [encoding])—— 转换为字符串(TextDecoder的一个替代方案),
- readAsDataURL(blob)—— 转换为 base64 的 data url。
文件读取
const handleChange = (e) => {let file = e.target.files[0];let reader = new FileReader();reader.readAsDataURL(file);reader.onload = function () {console.log("result", reader.result);console.log("blob", new Blob([reader.result]));};reader.onerror = function () {console.log(reader.error);};};<input type="file" onChange={(e) => handleChange(e)} />
readAsDataURL

readAsText
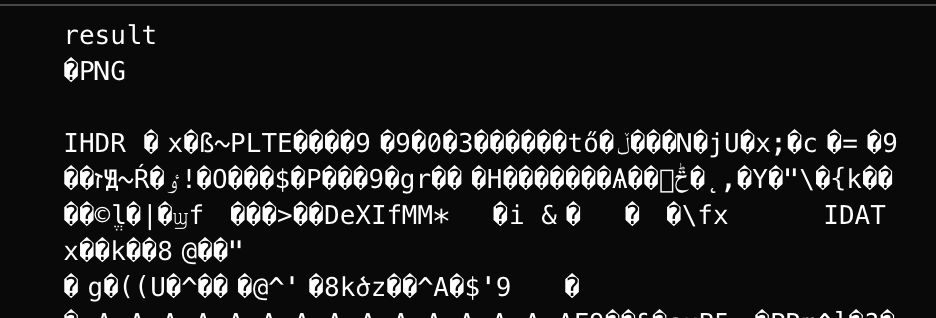
readAsBinaryString
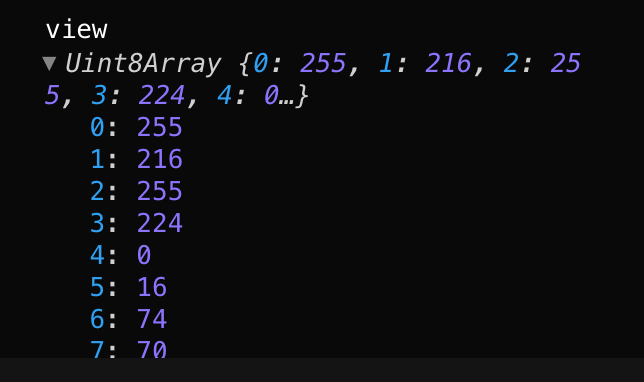
readAsArrayBuffer
本身ArrayBuffer中的内容对外是不可见的,若要查看其中的内容,就要引入另一个概念:类型化数组或者DataView
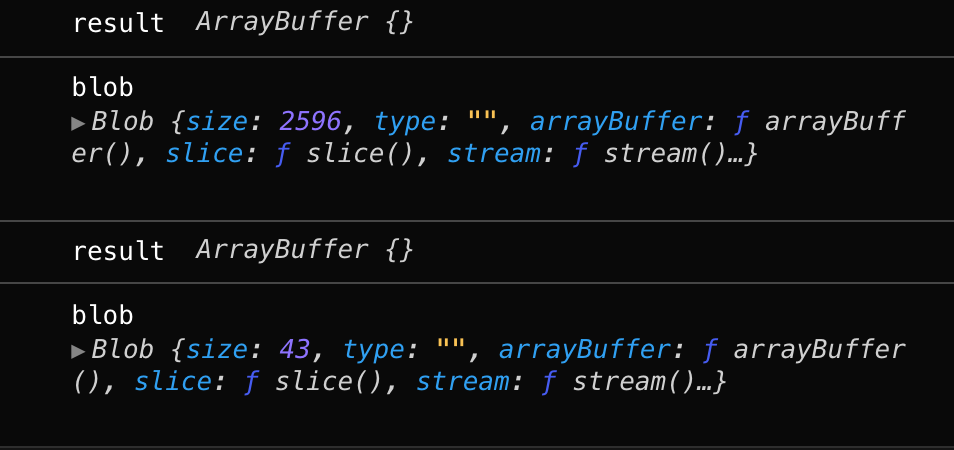
与readAsBinaryString类似,readAsArrayBuffer方法会按字节读取文件内容,并转换为ArrayBuffer对象。我们可以关注下文件读取后大小,与原文件大小一致。
readAsArrayBuffer与readAsBinaryString方法的区别,readAsArrayBuffer读取文件后,会在内存中创建一个ArrayBuffer对象(二进制缓冲区),将二进制数据存放在其中。通过此方式,我们可以直接在网络中传输二进制内容
reader.onload = function () {console.log("result", reader.result);const view = new Unit8Array(reader.result)console.log('view',view)console.log("blob", new Blob([reader.result]));};
应用
在线预览文件
我们知道,img的src属性或background的url属性,可以通过被赋值为图片网络地址或base64的方式显示图片。
在文件上传中,我们一般会先将本地文件上传到服务器,上传成功后,由后台返回图片的网络地址再在前端显示。
通过FileReader的readAsDataURL方法,我们可以不经过后台,直接将本地图片显示在页面上。这样做可以减少前后端频繁的交互过程,减少服务器端无用的图片资源
const handleChange = (e) => {let file = e.target.files[0];let reader = new FileReader();reader.readAsDataURL(file);reader.onload = function () {const img = document.createElement("img");img.src = reader.result;const APP = document.querySelector(".App");APP.append(img);};reader.onerror = function () {console.log(reader.error);};};<div className="App"><input type="file" onChange={(e) => handleChange(e)} /><hr /><div>预览区域</div><hr /></div>

二进制数据上传
const handleChange = (e) => {let file = e.target.files[0];let reader = new FileReader();reader.readAsDataURL(file);reader.onload = function () {upload(reader.result)};reader.onerror = function () {console.log(reader.error);};};const upload = (binary)=> {let response = await fetch('/article/fetch/post/user', {method: 'POST',headers: {// 'Content-Type': 'application/json;charset=utf-8'},body: binary});}<div className="App"><input type="file" onChange={(e) => handleChange(e)} /><hr /><div>预览区域</div><hr /></div>
网络上传 FormData
fetch
典型的 fetch 请求由两个await调用组成:
let response = await fetch(url, options); // 解析 response headerlet result = await response.json(); // 将 body 读取为 json
或者以 promise 形式:
fetch(url, options).then(response => response.json()).then(result => /* process result */)
响应的属性:
- response.status—— response 的 HTTP 状态码,
- response.ok—— HTTP 状态码为 200-299,则为true。
- response.headers—— 类似于 Map 的带有 HTTP header 的对象。
获取 response body 的方法:
- response.text()—— 读取 response,并以文本形式返回 response,
- response.json()—— 将 response 解析为 JSON 对象形式,
- response.formData()—— 以FormData对象(form/multipart 编码,参见下一章)的形式返回 response,
- response.blob()—— 以Blob(具有类型的二进制数据)形式返回 response,
- response.arrayBuffer()—— 以ArrayBuffer(低级别的二进制数据)形式返回 response。
到目前为止我们了解到的 fetch 选项:
- method—— HTTP 方法,
- headers—— 具有 request header 的对象(不是所有 header 都是被允许的)
- body—— 要以string,FormData,BufferSource,Blob或UrlSearchParams对象的形式发送的数据(request body)。
POST 请求
要创建一个POST请求,或者其他方法的请求,我们需要使用fetch选项:
- method—— HTTP 方法,例如POST,
- body—— request body,其中之一:
- 字符串(例如 JSON 编码的),
- FormData对象,以form/multipart形式发送数据,
- Blob/BufferSource发送二进制数据,
- URLSearchParams,以x-www-form-urlencoded编码形式发送数据,很少使用。body:’age=30$name=guanqingchao’
FormData
Form对象可以将数据编译成键值对的格式,以便于发送数据,主要用于:
(1) 发送表单数据(通过表单元素的name和value组成querystring,实现表单数据的序列化),也可以用来发送键值对格式的数据(非表单)。
(2)异步上传二进制文件。
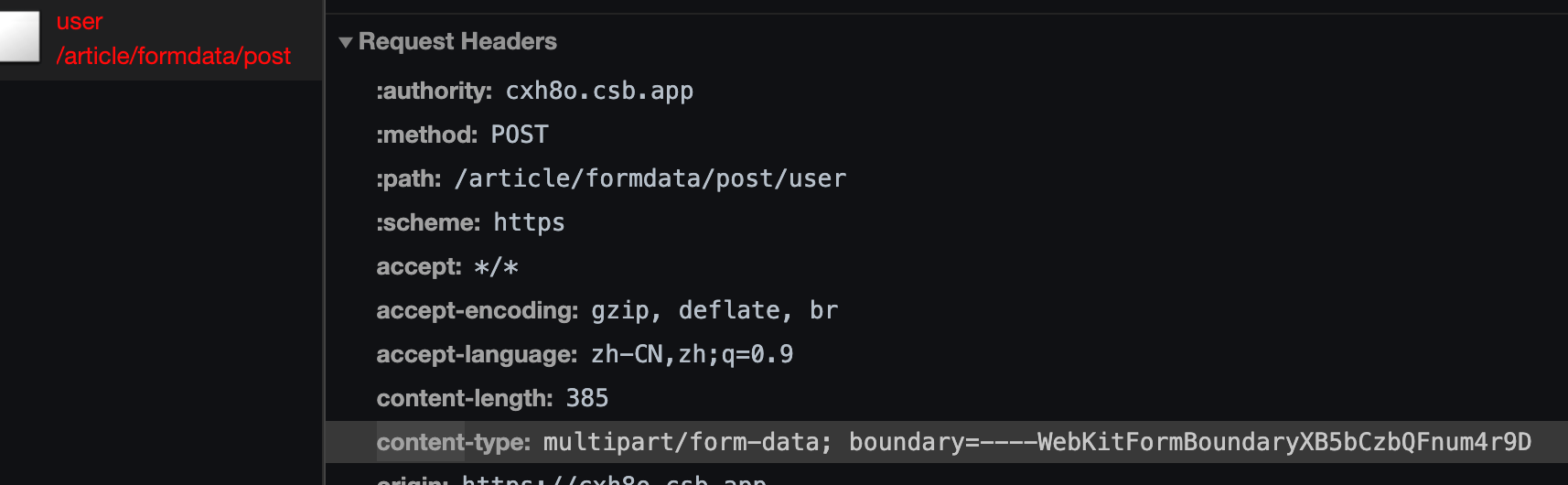
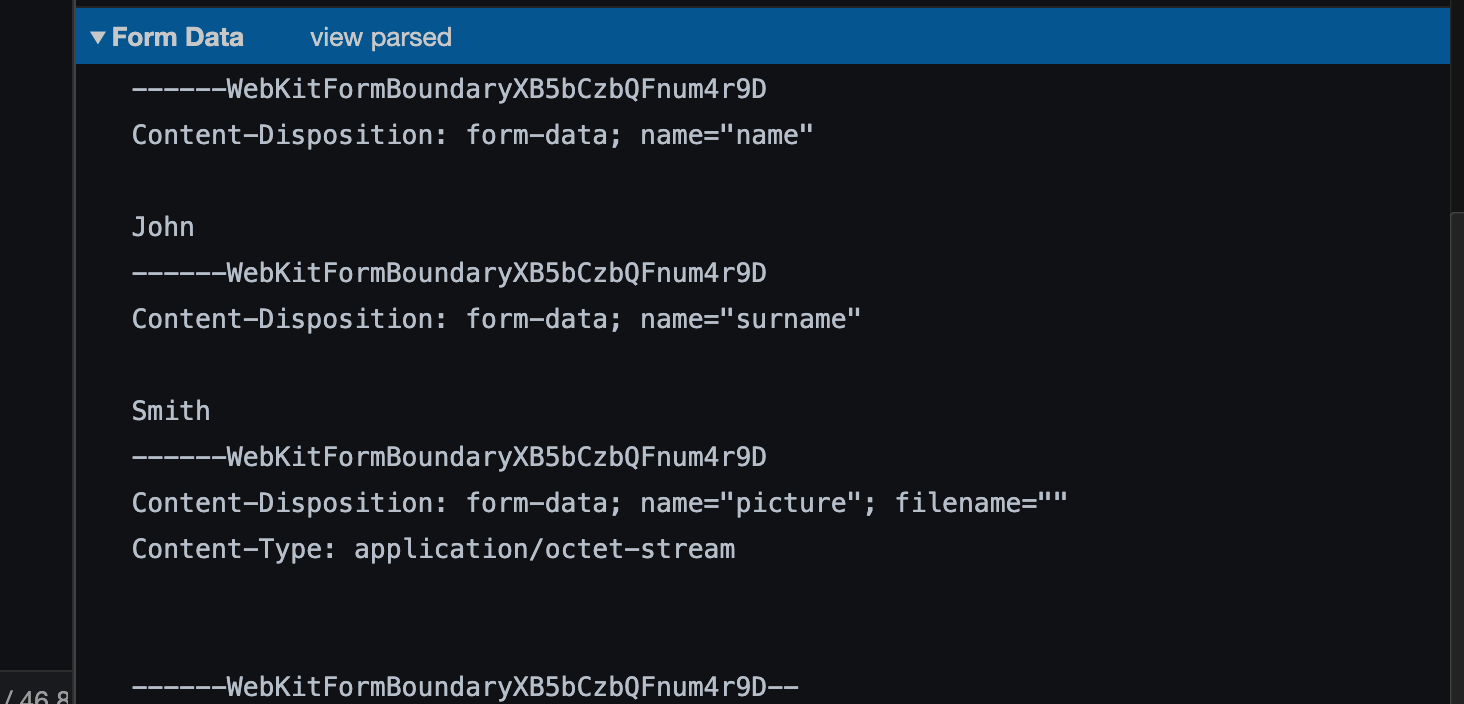
FormData的特殊之处在于网络方法(network methods),例如fetch可以接受一个FormData对象作为 body。它会被编码并发送出去,带有Content-Type: multipart/form-data。
<form className="formElem"><input type="text" name="name" value="John" /><input type="text" name="surname" value="Smith" />Picture: <input type="file" name="picture" accept="image/*" /><input type="submit" /></form>useEffect(() => {const form = document.querySelector(".formElem");const formData = new FormData(form);const name = formData.get("name");const surname = formData.get("surname");const picture = formData.get("picture");formData.append("token", "kshdfiwi3rh");console.log(name, surname, formData.get("token"), picture);form.onsubmit = async () => {let response = await fetch("/article/formdata/post/user", {method: "POST",body: new FormData(form)});let result = await response.json();};});
Buffer
大文件上传
思路总结
大文件切片
问题点:前端将文件做成切片进行传递,那么后端怎么知道已经全部接收到所有的文件切片
前端主动通知,当所有的切片传递完成后(Promise.all),再发送一个请求通知后端已经完成切片传递,后端进行切片合并
服务端合并切片
- 问题点:文件切片传递到后端,后端怎么将文件进行还原
文件编号,前端通过Blob.slice()进行文件切片,给每一个切片按顺序进行编号(index),将编号信息一并传递给后端(通过异步Promise发送请求)后端接收切片,在本地或者静态资源服务器新建切片文件夹,将切片保存到文件夹中(fs.createReadStream/fs.createWriteStream/pipe),得到合并通知读取文件按前端传递的文件顺序进行切片合并
文件秒传
所谓的文件秒传,即在服务端已经存在了上传的资源,所以当用户再次上传时会直接提示上传成功
文件秒传需要依赖上一步生成的 hash,即在上传前,先计算出文件 hash,并把 hash 发送给服务端进行验证,由于 hash 的唯一性,所以一旦服务端能找到 hash 相同的文件,则直接返回上传成功的信息即可
断点续传
问题点:断点续传如何实现,暂停上传之后,怎么继续上传
<br /> 服务端保存已上传的切片 hash,前端每次上传前向服务端获取已上传的切片<br /> <br />无论是前端还是服务端,都必须要生成文件和切片的 hash,使用文件名 + 切片下标作为切片 hash,文件名一旦修改就失去了效果,而事实上只要文件内容不变,hash 就不应该变化,所以正确的做法是根据文件内容生成 hash
这里用到另一个库 spark-md5,它可以根据文件内容计算出文件的 hash 值【抽样hash】
考虑到如果上传一个超大文件,读取文件内容计算 hash 是非常耗费时间的,并且会引起 UI 的阻塞,导致页面假死状态,所以我们使用 web-worker 在 worker 线程计算 hash【也可以时间分片requestIdleCallback】,这样用户仍可以在主界面正常的交互
由于实例化 web-worker 时,参数是一个 js 文件路径且不能跨域,所以我们单独创建一个 hash.js 文件放在 public 目录下,另外在 worker 中也是不允许访问 dom 的,但它提供了importScripts 函数用于导入外部脚本,通过它导入 spark-md5
spark-md5 需要根据所有切片才能算出一个 hash 值,不能直接将整个文件放入计算,否则即使不同文件也会有相同的 hash,具体可以看官方文档 spark-md5
将所有请求放到uploadFileQuene队列中,每当一个切片上传成功时,将对应的请求从队列中删除,uploadFileQuene只保存正在上传切片的请求
文件切片上传后,服务端会建立一个文件夹存储所有上传的切片,所以每次前端上传前可以调用一个接口,服务端将已上传的切片的切片名返回,前端跳过这些已经上传切片,这样就实现了“续传”的效果
- 服务端已存在该文件,不需要再次上传 实现文件秒传
- 服务端不存在该文件或者已上传部分文件切片,通知前端进行上传,并把已上传的文件切片返回给前端
暂停上传 : 点击暂停,调用保存在 uploadFileQuene 中的 abort 方法,取消并清空所有正在上传的切片
恢复上传 : 恢复上传的时候,获取已经上传过的分片文件,前端再次上传的时候,过滤掉已经上传的文件
axios的取消 参见 axios取消
大文件上传
- 将大文件转换成二进制流的格式
- 利用流可以切割的属性,将二进制流切割成多份
- 组装和分割块同等数量的请求块,并行或串行的形式发出请求
待我们监听到所有请求都成功发出去以后,再给服务端发出一个合并的信号
断点续传
为每一个文件切割块添加不同的标识hash
- 当上传成功的之后,记录上传成功的标识
- 当我们暂停或者发送失败后,可以重新发送没有上传成功的切割文件
进度条显示
ajax可以获取到请求进度 onUploadProgress
后端
接收每一个切割文件,并在接收成功后,存到指定位置,并告诉前端接收成功
- 收到合并信号,将所有的切割文件排序,合并,生成最终的大文件,然后删除切割小文件,并告知前端大文件的地址
实现
前端
文件上传的时候,对文件进行切片,通过blob.slice()方法对文件进行切割,通过formData封装form信息,示例中按照SIZE固定大小进行分割,返回对应的文件切块、文件名称和hash(hash使用文件名 + 下标,以便后端知道当前切片是第几个切片,用于之后的合并切片)
【hash优化】
点击上传,全部上传完毕,发送合并请求
create-react-app
import logo from './logo.svg';import { useState } from "react";import './App.css';const axios = require('axios').default;const SIZE = 1024 * 1024; //切片大小 1KBfunction App() {const [file, setFile] = useState(null);const [chunkFileList, setChunkFileList] = useState([]); //切片信息//上传文件const handleInputFile = (e) => {const files = e.target.files;setFile(files[0]);const chunkFileList = createChunkFile(files);setChunkFileList(chunkFileList);};// 生成切片文件 返回文件切片大小 文件名称const createChunkFile = (files = []) => {if (!files.length) return;const fileChunks = [];for (let file of files) {const fileSize = file.size;const fileName = file.name;let curSize = 0;let curIndex = 0;while (curSize <= fileSize) {let end = curSize + SIZE <= fileSize ? curSize + SIZE : fileSize;curIndex++;fileChunks.push({chunk: file.slice(curSize, end),filename: fileName,hash: fileName + '_' + curIndex,});curSize += SIZE;}}return fileChunks;};const handleUpload = () => {if (!chunkFileList.length) return;const uploadFileQuene = [];console.log('切片信息', chunkFileList)chunkFileList.forEach((file, index) => {const { chunk, filename, hash } = file;const form = new FormData();form.append(`chunks`, chunk);form.append("hash", hash);form.append("filename", filename);uploadFileQuene.push(uploadApi({url: "http://localhost:3000/api/upload", //上传切片data: form}));});Promise.all(uploadFileQuene).then(async () => {const res = await uploadApi({url: "http://localhost:3000/api/merge", //合并切片data: {filename: file.name,size: SIZE,//切片大小},});console.log('全部上传完毕', res);});};const uploadApi = async ({ url, data }) => {return axios({method: 'post',url: url,data: data,});//用fetch 无法获取koa返回的response// fetch(url, {// method: "POST",// mode: 'no-cors',// headers: {// 'Accept': 'application/json',// 'Content-Type': 'application/json',// // "Content-Type": "application/json;charset=utf-8"// },// body: data// }).then(res=>console.log(999999,res));};return (<div className="App"><header className="App-header"><input type="file" multiple="multiple" onChange={handleInputFile} /><button onClick={handleUpload}>点击我上传大文件呀</button><hr /><p>显示进度条</p></header></div>);}export default App;
后端:
- 接收前端上传的文件信息,filename、hash等,将切片文件保存到临时文件夹中
- 接收到合并文件请求,读取切片,按照序号顺序将切换合并,将切片文件作为可独流,通过pipe,写入到文件存放路径下,转成文件
- 切片合并之后,删除临时文件夹 ``` const Koa = require(‘koa’); const Router = require(‘koa-router’); const koabody = require(‘koa-body’); const fs = require(‘fs’); const path = require(‘path’); const cors = require(‘@koa/cors’); const multiparty = require(“multiparty”); const fse = require(“fs-extra”);
const app = new Koa(); const router = new Router();
const UPLOAD_DIR_TMP = path.resolve(dirname, “file-tmp”); // 大文件临时存储目录 const UPLOAD_DIR_REAL = path.resolve(dirname, “file”); // 大文件存储目录 if (!fs.existsSync(UPLOAD_DIR_TMP)) { fs.mkdirSync(UPLOAD_DIR_TMP); }
if (!fs.existsSync(UPLOAD_DIR_REAL)) { fs.mkdirSync(UPLOAD_DIR_REAL); }
app.use(cors()); app.use(koabody({ multipart: true }))
router.post(‘/api/upload’, ctx => { //切片保存接口 const chunks = { …ctx.request.files, …ctx.request.body } if (!Object.keys(chunks).length) { ctx.response.body = JSON.stringify({ message: ‘没有上传文件呢’, status: 0 }); return; }
const { filename, hash, chunks: chunk } = chunks;const fileName = path.basename(filename, path.extname(filename)); //去除文件扩展名const chunkDir = path.resolve(UPLOAD_DIR_TMP, fileName);const chunksSavePath = path.resolve(UPLOAD_DIR_TMP, fileName, hash);//创建保存切片的文件夹!fs.existsSync(chunkDir) && fs.mkdirSync(chunkDir);//写入const readStream = fs.createReadStream(chunk.path);//???Why pathconst writeStream = fs.createWriteStream(chunksSavePath);//写入流是文件路径 非目录readStream.pipe(writeStream);ctx.response.body = JSON.stringify({message: '本片段上传成功啦',status: 1});
})
router.post(‘/api/merge’, async (ctx, next) => { //切片合并接口
const mergeInfo = ctx.request.body;const { filename, size } = mergeInfo;const bigFilePath = path.resolve(UPLOAD_DIR_REAL, filename);//文件最后存放路径await mergeChunks(filename, size);ctx.response.body = JSON.stringify({message: '恭喜你全部文件上传成功啦!!!',url: bigFilePath,status: 1});
})
app.use(router.routes()) app.listen(3000);
/**
- @description: 合并切片
- @param {*} fileName
- @param {*} chunksNameList
- @return {}
/
async function mergeChunks(filename, size) {
const chunkDir = genDir(filename, UPLOAD_DIR_TMP);
const chunkPaths = await fs.readdirSync(chunkDir); //获取chunk路径
const bigFilePath = path.resolve(UPLOAD_DIR_REAL, filename);//文件最后存放路径
// 根据切片下标进行排序
// 否则直接读取目录的获得的顺序可能会错乱
chunkPaths.sort((a, b) => a.split(“-“)[1] - b.split(“-“)[1]);
await Promise.all(
) delDir(chunkDir);// 合并后删除保存切片的目录 // fse.rmdirSync(chunkDir); // 合并后删除保存切片的目录chunkPaths.map((chunkPath, index) => {//写入新的文件中const writeStream = fs.createWriteStream(bigFilePath, {start: index * size,end: (index + 1) * size});return pipeStream(path.resolve(chunkDir, chunkPath), writeStream)})
}
function genDir(filename, dirPath) { const fileName = path.basename(filename, path.extname(filename)); //去除文件扩展名 const chunkDir = path.resolve(dirPath, fileName); return chunkDir; }
const pipeStream = (path, writeStream) => new Promise(resolve => { const readStream = fs.createReadStream(path); readStream.on(“end”, () => { fs.unlinkSync(path); resolve(); }); readStream.pipe(writeStream); });
/**
- @description: 删除文件夹
- @param {String} path
- @return {}
/
function delDir(path) {
const dirs = fs.readdirSync(path);//读取当前路径下的文件及文件夹
dirs.forEach(dir => {
}) fs.rmdirSync(path)//删除空文件夹 } ```let curPath = path + '/' + dir//获得当前路径console.log('临时文件下文件', dirs)if (fs.statSync(curPath).isDirectory()) {//是否为文件夹delDir(curPath);//遍历} else if (fs.statSync(curPath).isFile()) {//是否为文件fs.unlinkSync(curPath)}
优化【TODO】
- 抽样hash
- 时间分片
- 文件碎片清理
- 并发请求数优化
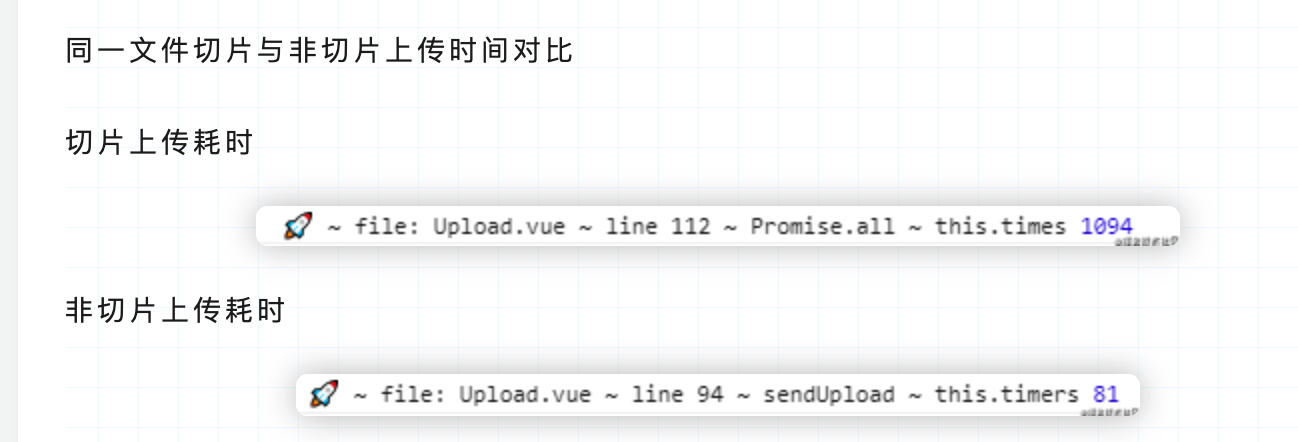
【TODO 时间对比】
References
https://juejin.cn/post/6844904046436843527#heading-2
https://juejin.cn/post/6902304890081509383
https://juejin.cn/post/6844903534689796110
https://zhuanlan.zhihu.com/p/104826733

若有收获,就点个赞吧
0 人点赞
