Promise 到底解决了什么问题呢?在正式开始介绍之前,我想有必要明确下,Promise 解决的是异步编码风格的问题,而不是一些其他的问题,所以接下来我们聊的话题都是围绕编码风格展开的。
异步编程的问题:代码逻辑不连续
首先我们来回顾下 JavaScript 的异步编程模型,你应该已经非常熟悉页面的事件循环系统了,也知道页面中任务都是执行在主线程之上的,相对于页面来说,主线程就是它整个的世界,所以在执行一项耗时的任务时,比如下载网络文件任务、获取摄像头等设备信息任务,这些任务都会放到页面主线程之外的进程或者线程中去执行,这样就避免了耗时任务“霸占”页面主线程的情况。你可以结合下图来看看这个处理过程: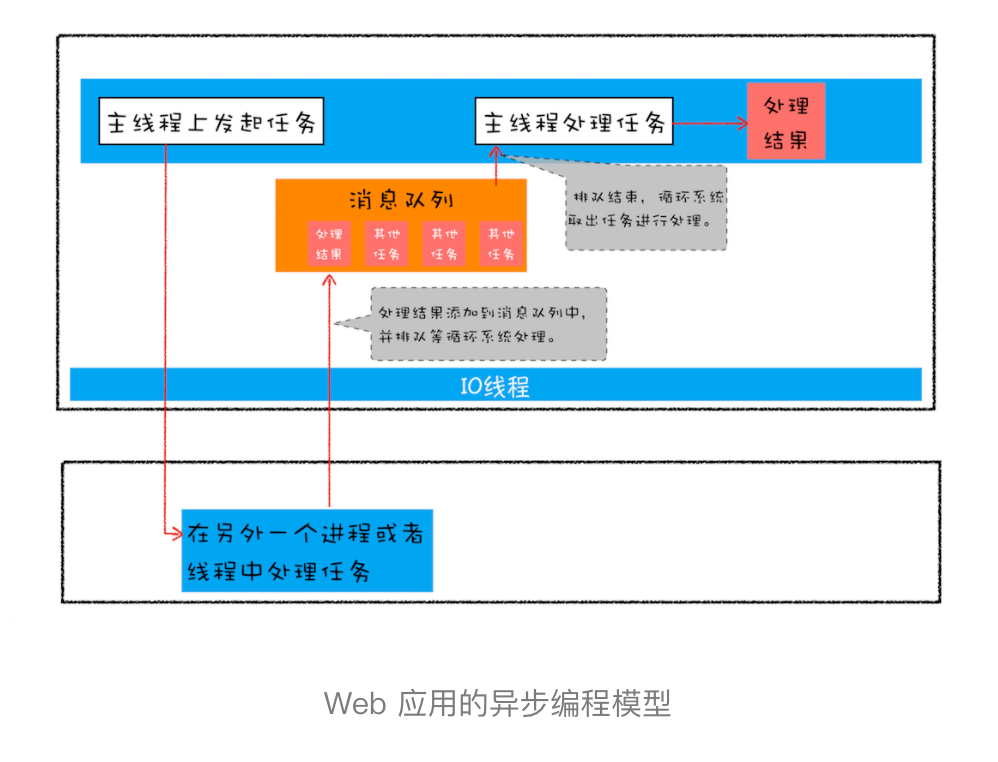
上图展示的是一个标准的异步编程模型,页面主线程发起了一个耗时的任务,并将任务交给另外一个进程去处理,这时页面主线程会继续执行消息队列中的任务。等该进程处理完这个任务后,会将该任务添加到渲染进程的消息队列中,并排队等待循环系统的处理。排队结束之后,循环系统会取出消息队列中的任务进行处理,并触发相关的回调操作。
这就是页面编程的一大特点:异步回调。
Web 页面的单线程架构决定了异步回调,而异步回调影响到了我们的编码方式,到底是如何影响的呢?假设有一个下载的需求,使用 XMLHttpRequest 来实现,具体的实现方式你可以参考下面这段代码:
//执行状态function onResolve(response){console.log(response) }function onReject(error){console.log(error) }let xhr = new XMLHttpRequest()xhr.ontimeout = function(e) { onReject(e)}xhr.onerror = function(e) { onReject(e) }xhr.onreadystatechange = function () { onResolve(xhr.response) }//设置请求类型,请求URL,是否同步信息let URL = 'https://time.geekbang.com'xhr.open('Get', URL, true);//设置参数xhr.timeout = 3000 //设置xhr请求的超时时间xhr.responseType = "text" //设置响应返回的数据格式xhr.setRequestHeader("X_TEST","time.geekbang")//发出请求xhr.send();
我们执行上面这段代码,可以正常输出结果的。但是,这短短的一段代码里面竟然出现了五次回调,这么多的回调会导致代码的逻辑不连贯、不线性,非常不符合人的直觉,这就是异步回调影响到我们的编码方式。那有什么方法可以解决这个问题吗?当然有,我们可以封装这堆凌乱的代码,降低处理异步回调的次数。
封装异步代码,让处理流程变得线性
由于我们重点关注的是输入内容(请求信息)和输出内容(回复信息),至于中间的异步请求过程,我们不想在代码里面体现太多,因为这会干扰核心的代码逻辑。整体思路如下图所示: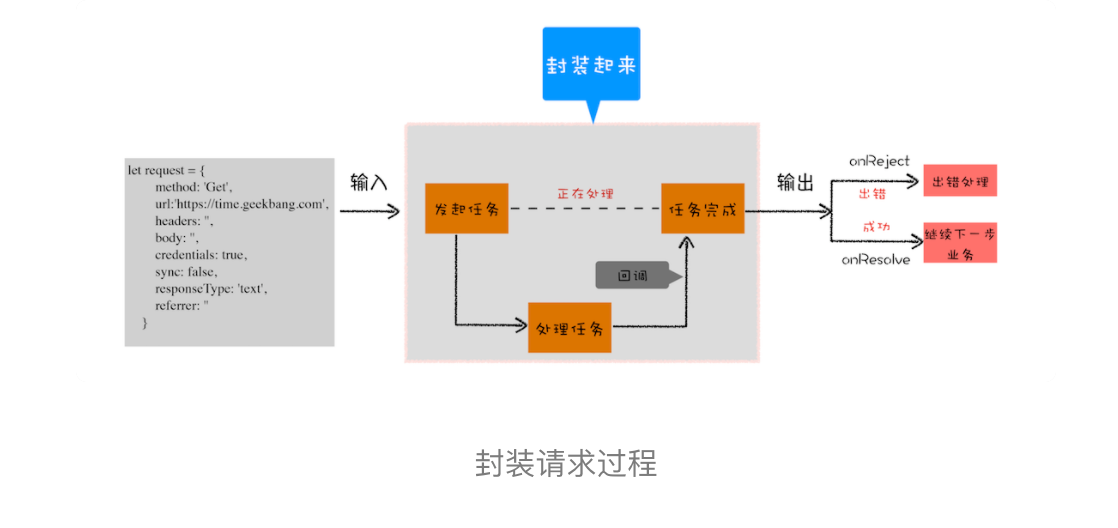
从图中你可以看到,我们将 XMLHttpRequest 请求过程的代码封装起来了,重点关注输入数据和输出结果。
那我们就按照这个思路来改造代码。首先,我们把输入的 HTTP 请求信息全部保存到一个 request 的结构中,包括请求地址、请求头、请求方式、引用地址、同步请求还是异步请求、安全设置等信息。request 结构如下所示:
//makeRequest用来构造request对象function makeRequest(request_url) {let request = {method: 'Get',url: request_url,headers: '',body: '',credentials: false,sync: true,responseType: 'text',referrer: ''}return request}
然后就可以封装请求过程了,这里我们将所有的请求细节封装进 XFetch 函数,XFetch 代码如下所示
//[in] request,请求信息,请求头,延时值,返回类型等//[out] resolve, 执行成功,回调该函数//[out] reject 执行失败,回调该函数function XFetch(request, resolve, reject) {let xhr = new XMLHttpRequest()xhr.ontimeout = function (e) { reject(e) }xhr.onerror = function (e) { reject(e) }xhr.onreadystatechange = function () {if (xhr.status = 200)resolve(xhr.response)}xhr.open(request.method, URL, request.sync);xhr.timeout = request.timeout;xhr.responseType = request.responseType;//补充其他请求信息//...xhr.send();}
这个 XFetch 函数需要一个 request 作为输入,然后还需要两个回调函数 resolve 和 reject,当请求成功时回调 resolve 函数,当请求出现问题时回调 reject 函数。
有了这些后,我们就可以来实现业务代码了,具体的实现方式如下所示
XFetch(makeRequest('https://time.geekbang.org'),function resolve(data) {console.log(data)}, function reject(e) {console.log(e)})
新的问题:回调地狱
上面的示例代码已经比较符合人的线性思维了,在一些简单的场景下运行效果也是非常好的,不过一旦接触到稍微复杂点的项目时,你就会发现,如果嵌套了太多的回调函数就很容易使得自己陷入了回调地狱,不能自拔。你可以参考下面这段让人凌乱的代码:
XFetch(makeRequest('https://time.geekbang.org/?category'),function resolve(response) {console.log(response)XFetch(makeRequest('https://time.geekbang.org/column'),function resolve(response) {console.log(response)XFetch(makeRequest('https://time.geekbang.org')function resolve(response) {console.log(response)}, function reject(e) {console.log(e)})}, function reject(e) {console.log(e)})}, function reject(e) {console.log(e)})
这段代码是先请求time.geekbang.org/?category,如果请求成功的话,那么再请求time.geekbang.org/column,如果再次请求成功的话,就继续请求time.geekbang.org。也就是说这段代码用了三层嵌套请求,就已经让代码变得混乱不堪,所以,我们还需要解决这种嵌套调用后混乱的代码结构。
这段代码之所以看上去很乱,归结其原因有两点:
第一是嵌套调用,下面的任务依赖上个任务的请求结果,并在上个任务的回调函数内部执行新的业务逻辑,这样当嵌套层次多了之后,代码的可读性就变得非常差了。
第二是任务的不确定性,执行每个任务都有两种可能的结果(成功或者失败),所以体现在代码中就需要对每个任务的执行结果做两次判断,这种对每个任务都要进行一次额外的错误处理的方式,明显增加了代码的混乱程度。
原因分析出来后,那么问题的解决思路就很清晰了:第一是消灭嵌套调用;第二是合并多个任务的错误处理。这么讲可能有点抽象,不过 Promise 已经帮助我们解决了这两个问题。那么接下来我们就来看看 Promise 是怎么消灭嵌套调用和合并多个任务的错误处理的。
Promise:消灭嵌套调用和多次错误处理
首先,我们使用 Promise 来重构 XFetch 的代码,示例代码如下所示:
function XFetch(request) {function executor(resolve, reject) {let xhr = new XMLHttpRequest()xhr.open('GET', request.url, true)xhr.ontimeout = function (e) { reject(e) }xhr.onerror = function (e) { reject(e) }xhr.onreadystatechange = function () {if (this.readyState === 4) {if (this.status === 200) {resolve(this.responseText, this)} else {let error = {code: this.status,response: this.response}reject(error, this)}}}xhr.send()}return new Promise(executor)}
接下来,我们再利用 XFetch 来构造请求流程,代码如下:
var x1 = XFetch(makeRequest('https://time.geekbang.org/?category'))var x2 = x1.then(value => {console.log(value)return XFetch(makeRequest('https://www.geekbang.org/column'))})var x3 = x2.then(value => {console.log(value)return XFetch(makeRequest('https://time.geekbang.org'))})x3.catch(error => {console.log(error)})
你可以观察上面这两段代码,重点关注下 Promise 的使用方式。
- 首先我们引入了 Promise,在调用 XFetch 时,会返回一个 Promise 对象。
- 构建 Promise 对象时,需要传入一个 executor 函数,XFetch 的主要业务流程都在 executor 函数中执行。
- 如果运行在 excutor 函数中的业务执行成功了,会调用 resolve 函数;如果执行失败了,则调用 reject 函数。
- 在 excutor 函数中调用 resolve 函数时,会触发 promise.then 设置的回调函数;而调用 reject 函数时,会触发 promise.catch 设置的回调函数。
以上简单介绍了 Promise 一些主要的使用方法,通过引入 Promise,上面这段代码看起来就非常线性了,也非常符合人的直觉,是不是很酷?
基于这段代码,我们就可以来分析 Promise 是如何消灭嵌套回调和合并多个错误处理了。
我们先来看看 Promise 是怎么消灭嵌套回调的。产生嵌套函数的一个主要原因是在发起任务请求时会带上回调函数,这样当任务处理结束之后,下个任务就只能在回调函数中来处理了。
Promise 主要通过下面两步解决嵌套回调问题的。
- 首先,Promise 实现了回调函数的延时绑定。回调函数的延时绑定在代码上体现就是先创建 Promise 对象 x1,通过 Promise 的构造函数 executor 来执行业务逻辑;创建好 Promise 对象 x1 之后,再使用 x1.then 来设置回调函数。示范代码如下: ```
//创建Promise对象x1,并在executor函数中执行业务逻辑 function executor(resolve, reject){ resolve(100) } let x1 = new Promise(executor)
//x1延迟绑定回调函数onResolve function onResolve(value){ console.log(value) } x1.then(onResolve)
- **其次,需要将回调函数 onResolve 的返回值穿透到最外层**。因为我们会根据 onResolve 函数的传入值来决定创建什么类型的 Promise 任务,创建好的 Promise 对象需要返回到最外层,这样就可以摆脱嵌套循环了。你可以先看下面的代码:<br />现在我们知道了 Promise 通过回调函数延迟绑定和回调函数返回值穿透的技术,解决了循环嵌套。那接下来我们再来看看 Promise 是怎么处理异常的,你可以回顾上篇文章思考题留的那段代码,我把这段代码也贴在文中了,如下所示:
function executor(resolve, reject) { let rand = Math.random(); console.log(1) console.log(rand) if (rand > 0.5) resolve() else reject() } var p0 = new Promise(executor);
var p1 = p0.then((value) => { console.log(“succeed-1”) return new Promise(executor) })
var p3 = p1.then((value) => { console.log(“succeed-2”) return new Promise(executor) })
var p4 = p3.then((value) => { console.log(“succeed-3”) return new Promise(executor) })
p4.catch((error) => { console.log(“error”) }) console.log(2)
这段代码有四个 Promise 对象:p0~p4。无论哪个对象里面抛出异常,都可以通过最后一个对象 p4.catch 来捕获异常,通过这种方式可以将所有 Promise 对象的错误合并到一个函数来处理,这样就解决了每个任务都需要单独处理异常的问题。之所以可以使用最后一个对象来捕获所有异常,是因为 Promise 对象的错误具有“冒泡”性质,会一直向后传递,直到被 onReject 函数处理或 catch 语句捕获为止。具备了这样“冒泡”的特性后,就不需要在每个 Promise 对象中单独捕获异常了。至于 Promise 错误的“冒泡”性质是怎么实现的,就留给你课后思考了。通过这种方式,我们就消灭了嵌套调用和频繁的错误处理,这样使得我们写出来的代码更加优雅,更加符合人的线性思维。<a name="uIHPa"></a># Promise 与微任务<br />讲了这么多,我们似乎还没有将微任务和 Promise 关联起来,那么 Promise 和微任务的关系到底体现哪里呢?我们可以结合下面这个简单的 Promise 代码来回答这个问题:
function executor(resolve, reject) { resolve(100) } let demo = new Promise(executor)
function onResolve(value){ console.log(value) } demo.then(onResolve)
对于上面这段代码,我们需要重点关注下它的执行顺序。首先执行 new Promise 时,Promise 的构造函数会被执行,不过由于 Promise 是 V8 引擎提供的,所以暂时看不到 Promise 构造函数的细节。接下来,Promise 的构造函数会调用 Promise 的参数 executor 函数。然后在 executor 中执行了 resolve,resolve 函数也是在 V8 内部实现的,那么 resolve 函数到底做了什么呢?我们知道,执行 resolve 函数,会触发 demo.then 设置的回调函数 onResolve,所以可以推测,resolve 函数内部调用了通过 demo.then 设置的 onResolve 函数。不过这里需要注意一下,由于 Promise 采用了回调函数延迟绑定技术,所以在执行 resolve 函数的时候,回调函数还没有绑定,那么只能推迟回调函数的执行。这样按顺序陈述可能把你绕晕了,下面来模拟实现一个 Promise,我们会实现它的构造函数、resolve 方法以及 then 方法,以方便你能看清楚 Promise 的背后都发生了什么。这里我们就把这个对象称为 Bromise,下面就是 Bromise 的实现代码:
function Bromise(executor) { var onResolve = null var onReject = null //模拟实现resolve和then,暂不支持rejcet this.then = function (onResolve, onReject) { onResolve = onResolve }; function resolve(value) { //setTimeout(()=>{ onResolve(value) // },0) } executor(resolve, null); }
观察上面这段代码,我们实现了自己的构造函数、resolve、then 方法。接下来我们使用 Bromise 来实现我们的业务代码,实现后的代码如下所示:
function executor(resolve, reject) { resolve(100) } //将Promise改成我们自己的Bromsie let demo = new Bromise(executor)
function onResolve(value){ console.log(value) } demo.then(onResolve)
执行这段代码,我们发现执行出错,输出的内容是:
Uncaught TypeError: onResolve_ is not a function
at resolve (
之所以出现这个错误,是由于 Bromise 的延迟绑定导致的,在调用到 onResolve_ 函数的时候,Bromise.then 还没有执行,所以执行上述代码的时候,当然会报“onResolve_ is not a function“的错误了。也正是因为此,我们要改造 Bromise 中的 resolve 方法,让 resolve 延迟调用 onResolve_。要让 resolve 中的 onResolve_ 函数延后执行,可以在 resolve 函数里面加上一个定时器,让其延时执行 onResolve_ 函数,你可以参考下面改造后的代码:
function resolve(value) { setTimeout(()=>{ onResolve_(value) },0) }
上面采用了定时器来推迟 onResolve 的执行,不过使用定时器的效率并不是太高,好在我们有微任务,所以 Promise 又把这个定时器改造成了微任务了,这样既可以让 onResolve_ 延时被调用,又提升了代码的执行效率。这就是 Promise 中使用微任务的原由了。<a name="EJ7tF"></a># 总结首先,我们回顾了 Web 页面是单线程架构模型,这种模型决定了我们编写代码的形式——异步编程。基于异步编程模型写出来的代码会把一些关键的逻辑点打乱,所以这种风格的代码不符合人的线性思维方式。接下来我们试着把一些不必要的回调接口封装起来,简单封装取得了一定的效果,不过,在稍微复制点的场景下依然存在着回调地狱的问题。然后我们分析了产生回调地狱的原因:1. 多层嵌套的问题;1. 每种任务的处理结果存在两种可能性(成功或失败),那么需要在每种任务执行结束后分别处理这两种可能性。Promise 通过回调函数延迟绑定、回调函数返回值穿透和错误“冒泡”技术解决了上面的两个问题。思考时间1. Promise 中为什么要引入微任务?1. Promise 中是如何实现回调函数返回值穿透的?1. Promise 出错后,是怎么通过“冒泡”传递给最后那个捕获异常的函数?
function executor(resolve, reject) { let rand = Math.random(); console.log(1) console.log(rand) if (rand > 0.5) resolve() else reject()}var p0 = new Promise(executor);var p1 = p0.then((value) => { console.log(“succeed-1”) return new Promise(executor)})var p3 = p1.then((value) => { console.log(“succeed-2”) return new Promise(executor)})var p4 = p3.then((value) => { console.log(“succeed-3”) return new Promise(executor)})p4.catch((error) => { console.log(“error”)})console.log(2)
```async function foo() {console.log('foo')}async function bar() {console.log('bar start')await foo()console.log('bar end')}console.log('script start')setTimeout(function () {console.log('setTimeout')}, 0)bar();new Promise(function (resolve) {console.log('promise executor')resolve();}).then(function () {console.log('promise then')})console.log('script end')
Async/Await
使用 Promise 能很好地解决回调地狱的问题,但是这种方式充满了 Promise 的 then() 方法,如果处理流程比较复杂的话,那么整段代码将充斥着 then,语义化不明显,代码不能很好地表示执行流程。
比如下面这样一个实际的使用场景:我先请求极客邦的内容,等返回信息之后,我再请求极客邦的另外一个资源。下面代码展示的是使用 fetch 来实现这样的需求,fetch 被定义在 window 对象中,可以用它来发起对远程资源的请求,该方法返回的是一个 Promise 对象,这和我们上篇文章中讲的 XFetch 很像,只不过 fetch 是浏览器原生支持的,并有没利用 XMLHttpRequest 来封装。
fetch('https://www.geekbang.org').then((response) => {console.log(response)return fetch('https://www.geekbang.org/test')}).then((response) => {console.log(response)}).catch((error) => {console.log(error)})
从这段 Promise 代码可以看出来,使用 promise.then 也是相当复杂,虽然整个请求流程已经线性化了,但是代码里面包含了大量的 then 函数,使得代码依然不是太容易阅读。基于这个原因,ES7 引入了 async/await,这是 JavaScript 异步编程的一个重大改进,提供了在不阻塞主线程的情况下使用同步代码实现异步访问资源的能力,并且使得代码逻辑更加清晰。你可以参考下面这段代码
async function foo(){try{let response1 = await fetch('https://www.geekbang.org')console.log('response1')console.log(response1)let response2 = await fetch('https://www.geekbang.org/test')console.log('response2')console.log(response2)}catch(err) {console.error(err)}}foo()
通过上面代码,你会发现整个异步处理的逻辑都是使用同步代码的方式来实现的,而且还支持 try catch 来捕获异常,这就是完全在写同步代码,所以是非常符合人的线性思维的。但是很多人都习惯了异步回调的编程思维,对于这种采用同步代码实现异步逻辑的方式,还需要一个转换的过程,因为这中间隐藏了一些容易让人迷惑的细节。
那么本篇文章我们继续深入,看看 JavaScript 引擎是如何实现 async/await 的。如果上来直接介绍 async/await 的使用方式的话,那么你可能会有点懵,所以我们就从其最底层的技术点一步步往上讲解,从而带你彻底弄清楚 async 和 await 到底是怎么工作的。
本文我们首先介绍生成器(Generator)是如何工作的,接着讲解 Generator 的底层实现机制——协程(Coroutine);又因为 async/await 使用了 Generator 和 Promise 两种技术,所以紧接着我们就通过 Generator 和 Promise 来分析 async/await 到底是如何以同步的方式来编写异步代码的。
生成器 VS 协程
我们先来看看什么是生成器函数?
生成器函数是一个带星号函数,而且是可以暂停执行和恢复执行的。
我们可以看下面这段代码:
function* genDemo() {console.log("开始执行第一段")yield 'generator 2'console.log("开始执行第二段")yield 'generator 2'console.log("开始执行第三段")yield 'generator 2'console.log("执行结束")return 'generator 2'}console.log('main 0')let gen = genDemo()console.log(gen.next().value)console.log('main 1')console.log(gen.next().value)console.log('main 2')console.log(gen.next().value)console.log('main 3')console.log(gen.next().value)console.log('main 4')
执行上面这段代码,观察输出结果,你会发现函数 genDemo 并不是一次执行完的,全局代码和 genDemo 函数交替执行。其实这就是生成器函数的特性,可以暂停执行,也可以恢复执行。下面我们就来看看生成器函数的具体使用方式:
- 在生成器函数内部执行一段代码,如果遇到 yield 关键字,那么 JavaScript 引擎将返回关键字后面的内容给外部,并暂停该函数的执行。
- 外部函数可以通过 next 方法恢复函数的执行。
关于函数的暂停和恢复,相信你一定很好奇这其中的原理,那么接下来我们就来简单介绍下 JavaScript 引擎 V8 是如何实现一个函数的暂停和恢复的,这也会有助于你理解后面要介绍的 async/await。
要搞懂函数为何能暂停和恢复,那你首先要了解协程的概念。协程是一种比线程更加轻量级的存在。你可以把协程看成是跑在线程上的任务,一个线程上可以存在多个协程,但是在线程上同时只能执行一个协程,比如当前执行的是 A 协程,要启动 B 协程,那么 A 协程就需要将主线程的控制权交给 B 协程,这就体现在 A 协程暂停执行,B 协程恢复执行;同样,也可以从 B 协程中启动 A 协程。通常,如果从 A 协程启动 B 协程,我们就把 A 协程称为 B 协程的父协程。
正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
为了让你更好地理解协程是怎么执行的,我结合上面那段代码的执行过程,画出了下面的“协程执行流程图”,你可以对照着代码来分析: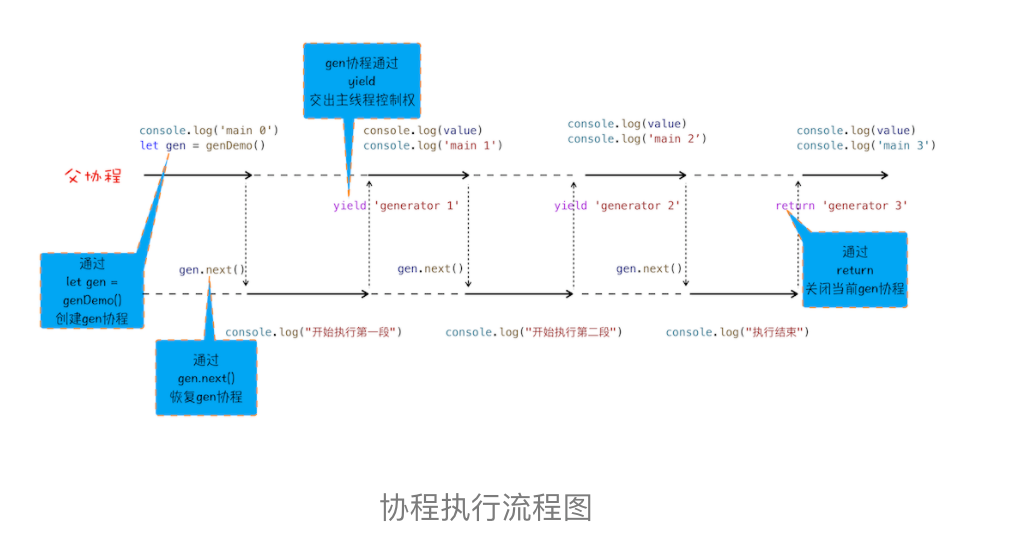
从图中可以看出来协程的四点规则:
- 通过调用生成器函数 genDemo 来创建一个协程 gen,创建之后,gen 协程并没有立即执行。
- 要让 gen 协程执行,需要通过调用 gen.next。
- 当协程正在执行的时候,可以通过 yield 关键字来暂停 gen 协程的执行,并返回主要信息给父协程。
- 如果协程在执行期间,遇到了 return 关键字,那么 JavaScript 引擎会结束当前协程,并将 return 后面的内容返回给父协程。
不过,对于上面这段代码,你可能又有这样疑问:父协程有自己的调用栈,gen 协程时也有自己的调用栈,当 gen 协程通过 yield 把控制权交给父协程时,V8 是如何切换到父协程的调用栈?当父协程通过 gen.next 恢复 gen 协程时,又是如何切换 gen 协程的调用栈?
要搞清楚上面的问题,你需要关注以下两点内容。
- 第一点:gen 协程和父协程是在主线程上交互执行的,并不是并发执行的,它们之前的切换是通过 yield 和 gen.next 来配合完成的。
- 第二点:当在 gen 协程中调用了 yield 方法时,JavaScript 引擎会保存 gen 协程当前的调用栈信息,并恢复父协程的调用栈信息。同样,当在父协程中执行 gen.next 时,JavaScript 引擎会保存父协程的调用栈信息,并恢复 gen 协程的调用栈信息。
为了直观理解父协程和 gen 协程是如何切换调用栈的,你可以参考下图: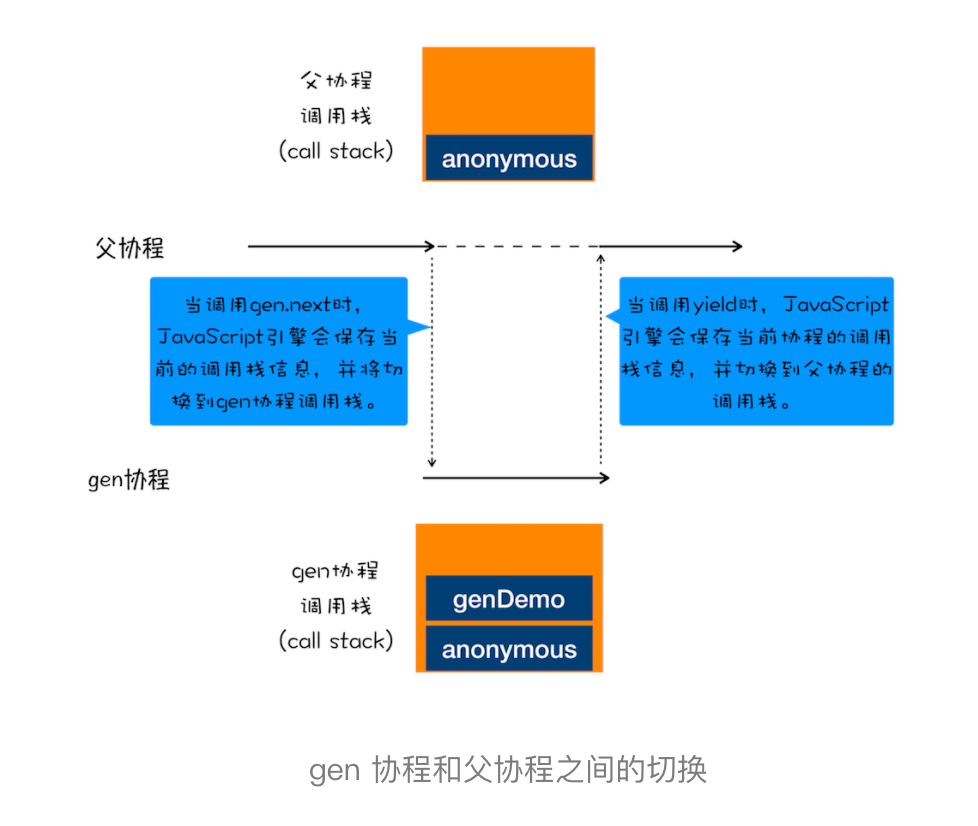
到这里相信你已经弄清楚了协程是怎么工作的,其实在 JavaScript 中,生成器就是协程的一种实现方式,这样相信你也就理解什么是生成器了。那么接下来,我们使用生成器和 Promise 来改造开头的那段 Promise 代码。改造后的代码如下所示:
//foo函数function* foo() {let response1 = yield fetch('https://www.geekbang.org')console.log('response1')console.log(response1)let response2 = yield fetch('https://www.geekbang.org/test')console.log('response2')console.log(response2)}//执行foo函数的代码let gen = foo()function getGenPromise(gen) {return gen.next().value}getGenPromise(gen).then((response) => {console.log('response1')console.log(response)return getGenPromise(gen)}).then((response) => {console.log('response2')console.log(response)})
从图中可以看到,foo 函数是一个生成器函数,在 foo 函数里面实现了用同步代码形式来实现异步操作;但是在 foo 函数外部,我们还需要写一段执行 foo 函数的代码,如上述代码的后半部分所示,那下面我们就来分析下这段代码是如何工作的。
- 首先执行的是let gen = foo(),创建了 gen 协程。
- 然后在父协程中通过执行 gen.next 把主线程的控制权交给 gen 协程。
- gen 协程获取到主线程的控制权后,就调用 fetch 函数创建了一个 Promise 对象 response1,然后通过 yield 暂停 gen 协程的执行,并将 response1 返回给父协程。
- 父协程恢复执行后,调用 response1.then 方法等待请求结果。
- 等通过 fetch 发起的请求完成之后,会调用 then 中的回调函数,then 中的回调函数拿到结果之后,通过调用 gen.next 放弃主线程的控制权,将控制权交 gen 协程继续执行下个请求。
以上就是协程和 Promise 相互配合执行的一个大致流程。不过通常,我们把执行生成器的代码封装成一个函数,并把这个执行生成器代码的函数称为执行器(可参考著名的 co 框架),如下面这种方式:
function* foo() {let response1 = yield fetch('https://www.geekbang.org')console.log('response1')console.log(response1)let response2 = yield fetch('https://www.geekbang.org/test')console.log('response2')console.log(response2)}co(foo());
通过使用生成器配合执行器,就能实现使用同步的方式写出异步代码了,这样也大大加强了代码的可读性。
async/await
虽然生成器已经能很好地满足我们的需求了,但是程序员的追求是无止境的,这不又在 ES7 中引入了 async/await,这种方式能够彻底告别执行器和生成器,实现更加直观简洁的代码。其实 async/await 技术背后的秘密就是 Promise 和生成器应用,往低层说就是微任务和协程应用。要搞清楚 async 和 await 的工作原理,我们就得对 async 和 await 分开分析。
1. async
我们先来看看 async 到底是什么?
根据 MDN 定义,async 是一个通过异步执行并隐式返回 Promise 作为结果的函数。
对 async 函数的理解,这里需要重点关注两个词:异步执行和隐式返回 Promise。
关于异步执行的原因,我们一会儿再分析。这里我们先来看看是如何隐式返回 Promise 的,你可以参考下面的代码:
async function foo() {return 2}console.log(foo()) // Promise {<resolved>:
执行这段代码,我们可以看到调用 async 声明的 foo 函数返回了一个 Promise 对象,状态是 resolved,返回结果如下所示:
Promise {<resolved>: 2}
2. await
我们知道了 async 函数返回的是一个 Promise 对象,那下面我们再结合文中这段代码来看看 await 到底是什么。
async function foo() {console.log(1)let a = await 100console.log(a)console.log(2)}console.log(0)foo()console.log(3)
观察上面这段代码,你能判断出打印出来的内容是什么吗?这得先来分析 async 结合 await 到底会发生什么。在详细介绍之前,我们先站在协程的视角来看看这段代码的整体执行流程图: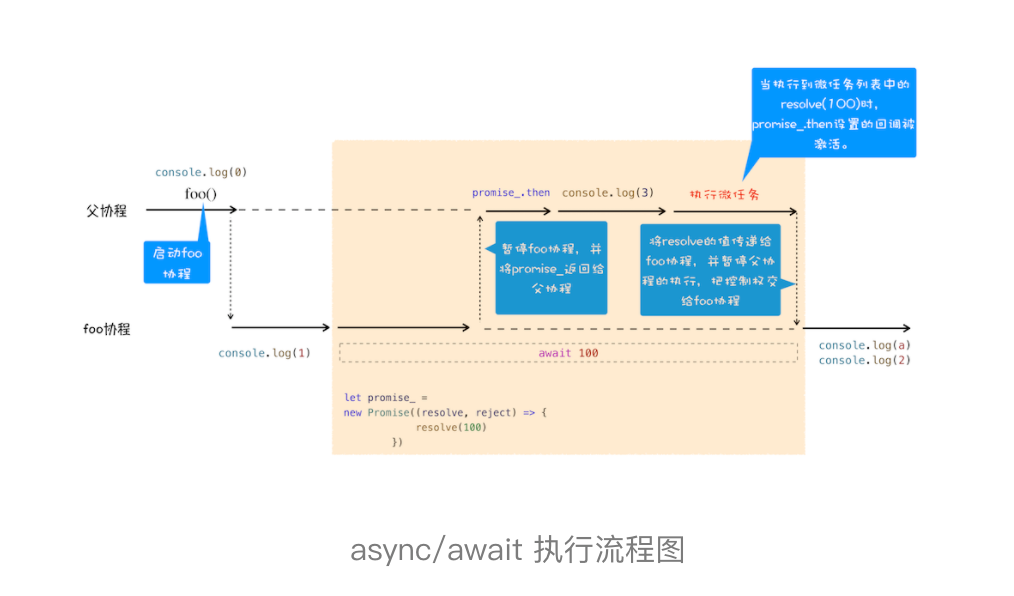
结合上图,我们来一起分析下 async/await 的执行流程。
首先,执行console.log(0)这个语句,打印出来 0。
紧接着就是执行 foo 函数,由于 foo 函数是被 async 标记过的,所以当进入该函数的时候,JavaScript 引擎会保存当前的调用栈等信息,然后执行 foo 函数中的console.log(1)语句,并打印出 1。
接下来就执行到 foo 函数中的await 100这个语句了,这里是我们分析的重点,因为在执行await 100这个语句时,JavaScript 引擎在背后为我们默默做了太多的事情,那么下面我们就把这个语句拆开,来看看 JavaScript 到底都做了哪些事情。
当执行到await 100时,会默认创建一个 Promise 对象,代码如下所示:
let promise_ = new Promise((resolve,reject){resolve(100)})
在这个 promise_ 对象创建的过程中,我们可以看到在 executor 函数中调用了 resolve 函数,JavaScript 引擎会将该任务提交给微任务队列(上一篇文章中我们讲解过)。
然后 JavaScript 引擎会暂停当前协程的执行,将主线程的控制权转交给父协程执行,同时会将 promise_ 对象返回给父协程。
主线程的控制权已经交给父协程了,这时候父协程要做的一件事是调用 promise_.then 来监控 promise 状态的改变。
接下来继续执行父协程的流程,这里我们执行console.log(3),并打印出来 3。随后父协程将执行结束,在结束之前,会进入微任务的检查点,然后执行微任务队列,微任务队列中有resolve(100)的任务等待执行,执行到这里的时候,会触发 promise_.then 中的回调函数,如下所示:
promise_.then((value)=>{//回调函数被激活后//将主线程控制权交给foo协程,并将vaule值传给协程})
该回调函数被激活以后,会将主线程的控制权交给 foo 函数的协程,并同时将 value 值传给该协程。
foo 协程激活之后,会把刚才的 value 值赋给了变量 a,然后 foo 协程继续执行后续语句,执行完成之后,将控制权归还给父协程。
以上就是 await/async 的执行流程。正是因为 async 和 await 在背后为我们做了大量的工作,所以我们才能用同步的方式写出异步代码来。
总结
Promise 的编程模型依然充斥着大量的 then 方法,虽然解决了回调地狱的问题,但是在语义方面依然存在缺陷,代码中充斥着大量的 then 函数,这就是 async/await 出现的原因。
使用 async/await 可以实现用同步代码的风格来编写异步代码,这是因为 async/await 的基础技术使用了生成器和 Promise,生成器是协程的实现,利用生成器能实现生成器函数的暂停和恢复。
另外,V8 引擎还为 async/await 做了大量的语法层面包装,所以了解隐藏在背后的代码有助于加深你对 async/await 的理解。
async/await 无疑是异步编程领域非常大的一个革新,也是未来的一个主流的编程风格。其实,除了 JavaScript,Python、Dart、C# 等语言也都引入了 async/await,使用它不仅能让代码更加整洁美观,而且还能确保该函数始终都能返回 Promise
TODO

若有收获,就点个赞吧
0 人点赞
