NodeJS 事件循环(第一部分)- 事件循环机制概述
处理 I/O 方式的不同使得 Node.js 区别于其他的编程平台。我们一直听过这样的说法,在某人介绍 Node.js 说道 “一个基于 google v8 JavaScript 引擎的非阻塞,事件驱动的平台”。他们要表达的是什么?“非阻塞”和“事件驱动”是什么意思?所有这些问题的答案涉及到 NodeJs 的核心,事件驱动。在这个系列中,我将描述下 什么是事件驱动,它是如何工作的,如何影响我们的应用的,及如何有效的使用等等。为什么是一系列而不是一篇文章?如果它是一篇长篇文章并且肯定会错过某些东西。因此我写了一系列。在这篇文章中,我将会描述下 NodeJs 是如何工作的,如何访问 I/O 的,怎么与其他不同的平台工作的等等。
反应器模式(Reactor Pattern)
译者注:反应器模式与观察者模式在某些方面极为相似:当一个主体发生改变时,所有依属体都得到通知。不过,观察者模式与单个事件源关联,而反应器模式则与多个事件源关联 。
NodeJs 在一个事件驱动的模型中工作,涉及到一个事件多路分用器(Event Demultiplexer) 和一个事件队列(Event Queue)。所有的 I/O 请求最终会生成一个成功或失败的事件或其他的触发器,叫做事件(Event)。根据下面这些算法处理这些事件。
- 事件多路分用器接受 I/O 请求并且委托这些请求给适当的硬件。
- 一旦 I/O 请求处理了(例如:一个文件里里面的数据可以读取,从一个 socket 的数据可以读取等),事件多路分用器为在一个需要处理的队列中的特定行为添加注册的回调处理器。这些回调被称为事件,事件添加的队列被称为事件队列。
- 当在一个事件队列中有可以处理的事件的时候,会按接受它们的顺序循环执行,直到队列为空。
- 如果在事件队列中没有事件或者事件多路分用器没有即将发生的请求,程序会完成。否则,这个过程会从第一步开始继续。
协调整个机制的程序被称为事件循环(Event Loop)。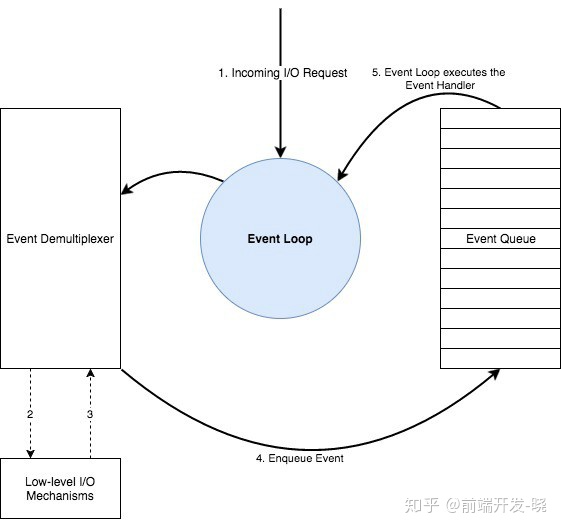
注意: 不要对事件循环和 NodeJs 事件触发感到迷惑。事件触发器跟这个机制相比完全是另一个不同的概念。在之后的文章中,我将会解释事件触发器是如何通过事件循环影响事件处理过程的。
上面的图解是 NodeJs 如何工作的一个抽象的概述,展示了反应器模式的主要组件。但是比这个要复杂的多,到底有多复杂?
事件多路分发器不是在所有的系统平台上面处理所有的 I/O 类型的一个单组件。
事件队列并不是像这里展示的那样,所有类型的事件从一个单一的队列入队和出队。并且 I/O 不是唯一正在排队的事件类型。
因此,让我们更深入些。
事件多路分发器
事件多路分发器在真实世界中存在的组件,而是反应器模式中一个抽象的概念。在现实世界中,事件多路分发器在不同的系统中实现,名字不同。比如在 Linux 中 epoll,在 BSD(MacOS) 系统中是 kqueue,在 Solaris 中 event ports,在 windows 系统中是 IOCP(Input Output Completion Port)等等。NodeJS 消费被那些实现的低级,非阻塞,异步的硬件 I/O 能力。
文件 I/O 的复杂性
但令人困惑的事实,并不是所有类型的 I/O 可以使用这些实现执行。甚至在一样的操作系统平台上,支持不同类型的 I/O 也有着复杂性。典型的,网络 I/O 使用这些 epoll 和 kqueu,events ports 和 IOCP 可以以非阻塞的方式执行。但是文件 I/O 更加复杂。特定的系统,如 Linux 不支持异步完成文件系统访问。并且在 MacOS 系统上面使用 kquue 的文件系统事件通知和信号有很多局限性。很复杂,几乎不可能解决所有这些文件系统的复杂性以提供完整的异步。
DNS 的复杂性
与文件 I/O 相似,某些被 Node API 提供的 DNS 功能节点也有一定的复杂性。因为 NodeJS DNS 函数如 dns.loogup,访问系统配置文件如 nsswitch.conf,resolve.conf 和 /etc/hosts,上述文件系统的复杂性也适用于 dns.resolve 函数。
解决办法?
因此,引入了一个线程池来支持 I/O 功能,不能被硬件异步 I/O 工具直接处理(epoll/kqueue/event ports/IOCP)。现在我们知道并不是所有的 I/O 函数在线程池发生。NodeJS 使用非阻塞和异步硬件 I/O 尽最大的努力做大部分的 I/O 工作,但是对于那些阻塞或者处理起来复杂类型的 I/O,使用线程池。
把他们放在一起
正如我们看到的,在实际世界中,支持所有不同操作系统平台的所有的不同类型的 I/O(文件 I/O,网络 I/O,DNS 等)非常困难。一部分 I/O 可以使用本机硬件实现执行,同时保留完整的异步,有一部分类型的 I/O 需要在线程池中执行以便保证异步特性。
在 Node 开发者中间,一个普遍的误解是 Node 在线程池中处理所有的 I/O。
管理整个过程同时支持跨平台的 I/O,应该有一个抽象层,封装了 inter-platform 和 intra-platform 的复杂性并且为 Node 上层暴露通用的 API。
那么是谁呢?女士们,先生们,有请…
摘抄于官方 libuv 文档
libuv 最初为 NodeJS 编写的一个跨平台支持的库。围绕着事件驱动和异步 I/O 模型设计的。
这个库不仅仅提供了不同的 I/O 轮询机制的简单抽象:’handles’ 和 ‘streams’为 sockets 和 其他实体提供了一个高级的抽象;也提供了跨平台的文件 I/O 和线程功能。
让我们看下 libuv 的组成。下面的图表来自于官方文档,描述了暴露通用的 API 处理不同类型的 I/O。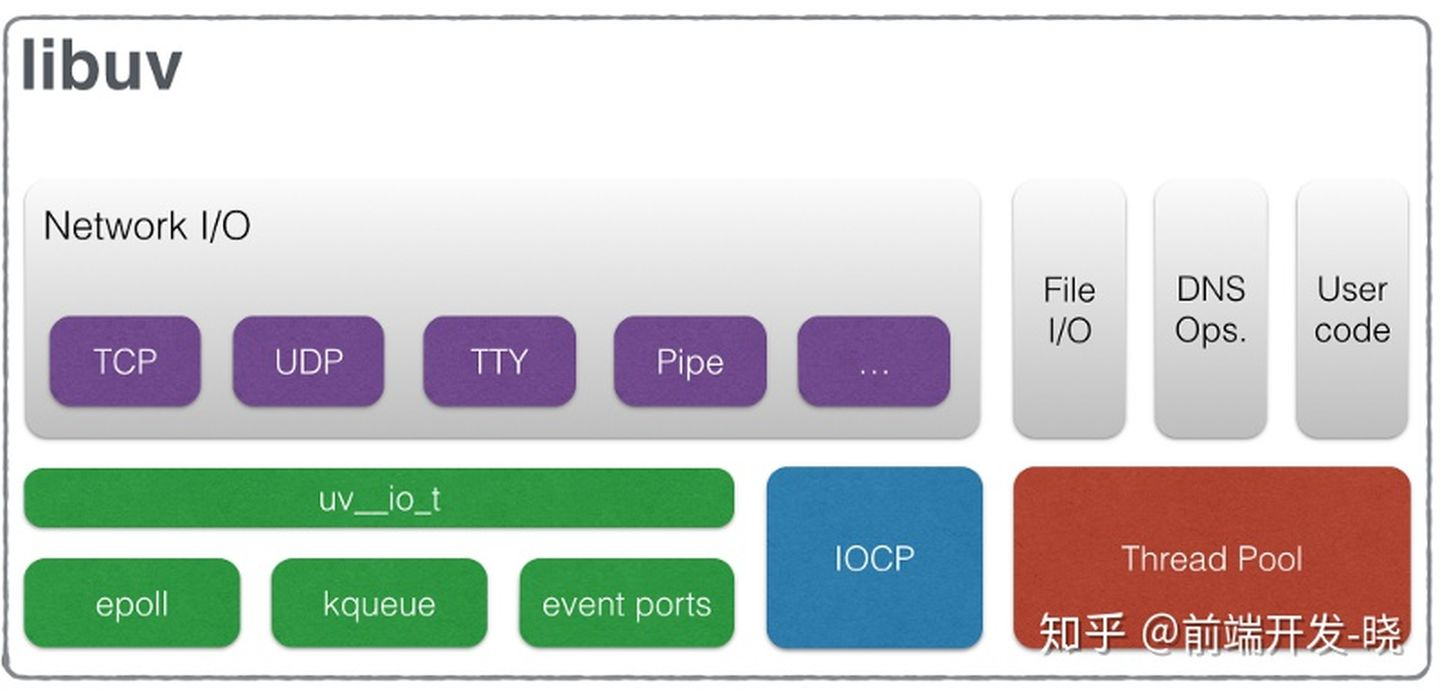
现在我们知道事件多路分发器,不是一个原子的实体,而是一个被 Libuv 抽象的处理 I/O 过程的 APIs 的集合暴露给 NodeJS 的上层。它不仅是一个 libuv 提供给 Node 的事件多路分发器。Libuv 为 NodeJS 提供了完整的事件循环功能,包含事件队列机制。
现在让我们看下 事件队列。
事件队列
所有的事件入队的队列应该是一个数据结构,按顺序处理事件循环,直到队列为空。但是在 Node 中是如何发生的,完全不同于反应器模式描述的那样。因此有哪些差异?
在 NodeJS 中不止一个队列,不同类型的事件在它们自己的队列中入队。
在处理完一个阶段后,移向下一个阶段之前,事件循环将会处理两个中间队列,直到两个中间队列为空。
那么这里有多少个队列呢?中间队列是什么?
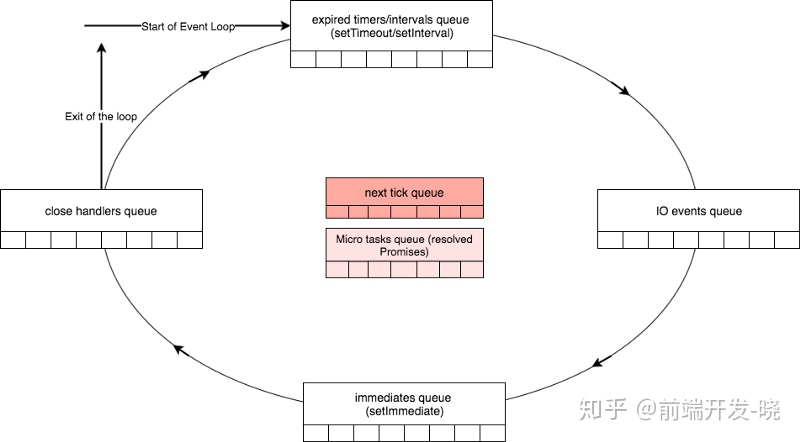
有 4 个主要类型的队列,被原生的 libuv 事件循环处理。
- 过期计时器和间隔队列(Expired timers and intervals queue) - 使用 setTimeout 添加的过期计时器的回调或者使用 setInterval 添加的间隔函数。
- IO 事件队列(IO Events Queue) - 完成的 I/O 事件
- 立即的队列(Immediate queue) - 使用 setImmediate 函数添加的回调
- 关闭操作队列(Close Handlers Queue) - 任何一个 close 事件处理器。
注意,尽管我在这里都简单说 “队列”,它们中的一些实际上是数据结构的不同类型(timers 被存储在最小堆里)
除了四个主要的队列,这里另外有两个有意思的队列,我之前提到的 “中间队列”,被 Node 处理。尽管这些队列不是 libuv 的一部分,但是 NodeJS 的一部分。它们是:
- 下一个运转队列(Next Ticks Queue) - 使用 process.nextTick() 函数添加的回调
- 其他的微队列(other Microtasks Queue) - 包含其他的微队列如成功的 Promise 回调
它是如何工作的?
正如你在下面图表中所见,Node 通过检查 timers 队列中任何一个过期 timers 开始事件循环(译者注:先检查事件循环是否活着),通过每个步骤的每个队列。处理完关闭处理器队列,如果在所有的队列中没有要处理的项,那么循环将会退出。在事件循环中每个队列的处理可以看做事件循环的一个阶段。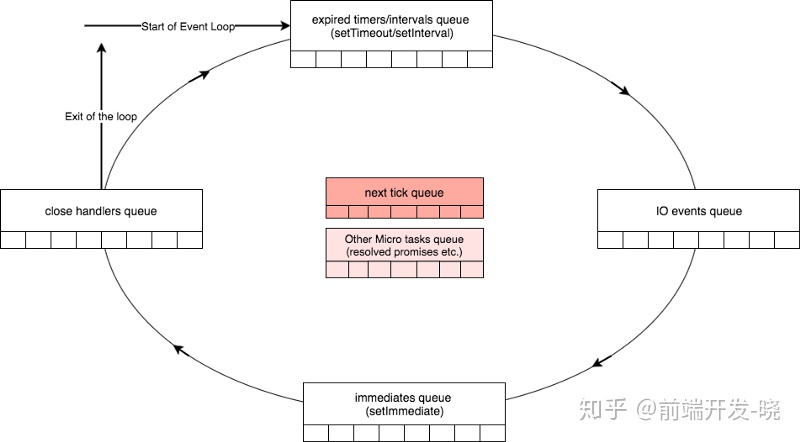
被描绘成红色的中间队列有趣的是,只要一个阶段结束,事件循环将会检查这两个中间阶段是否有要处理的项。如果有,事件循环会立马开始处理它们直到两个队列为空。一旦为空,事件循环就移到下一个阶段,实际上 next tick queue 比 micro tasks queue 有着更高的优先级。
E.g, 事件循环当前处理有着 5 个事件处理器的立即队列(immediate queue)。同时,两个处理器回调被添加到 下一个运转队列。一旦事件处理器完成立即队列中的 5 个事件处理器,事件循环将会在移到 close 事件处理器队列之前检测到在下一个运转队列里面,有两个要处理的项。然后事件处理器会处理完下一个运转队列里面的处理器。然后移到 close 事件队列。
下一个运转队列(next tick queue) VS 其他的微队列(other Micotasks)
下一个运转队列比微队列有着更高的优先级。尽管它们都在事件循环的两个阶段之间处理,在一个阶段的结尾 libuv 回到 Node 的跟高层进行通信。你将会注意到我用暗红色来表示 next tick queue,这意味着在开始处理 promise 的微队列之前,下一个运转队列是空的。
下一个运转队列的优先级比 promise 的高仅仅适合于 V8 提供的原生 JS 提供的 promise。如果你使用一个 q 库或者 bluebird, 你将会观察到一个不同的结果,因为它们提早于原生的 promise,有不同的语义。 q 和 bluebird 处理 promise 也有不同的方式,后面的文章我会解释。
这些所谓的中间队列引入了一个新的问题,IO 饿死。广泛的使用 process.nextTick 填充下一个运转队列将会强迫事件循环处理下一个运转队列而不前进。这将会导致 IO 饿死,因为时间循环不能继续,只有继续清空下一个运转队列。
为了防止这种清空,这里有一个下一个运转队的最大限制,可以使用 procsess.maxTickDepth 参数设置,但是已经从 NodeJS v0.12 移除了。具体查看原因。
我将会在之后的文章中用示例深入讨论这些队列。
最后,你知道了什么是 事件循环,如何实现的和 Node 处理异步的 I/O。让我们看下 Libuv 在 NodeJS 架构中的位置。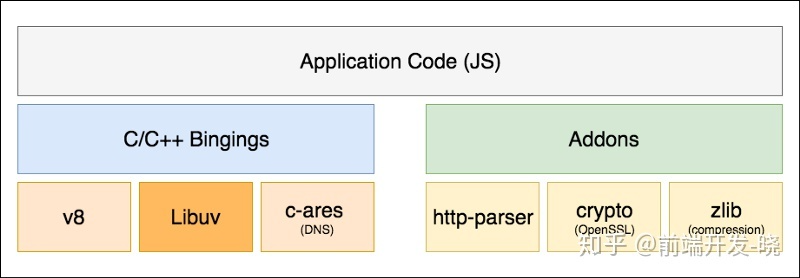
我希望你发现这个有用,在之后的文章中,我会讨论,
- 计时器,立即(Immediates)和 process.nextTick
- 解决成功的 Promise 和 process.nextTick
- 处理 I/O
- 使用事件循环的最佳实践
NodeJS 事件循环(第二部分)- Timers,Immediates,nextTick
Next Tick 队列
实际上 I/O 阶段也分了几个子阶段,具体参考 Node.js 事件循环工作流程 & 生命周期
Next tick 跟其他四个主要队列是分开的展示的,因为它不是被 libuv 提供的,而是由 Node 实现的。
因为事件循环的每个阶段(timers 队列,IO 事件队列,immediate 队列,close 处理器队列 ,四个主要的阶段),在移到下一个阶段之前,Node 会检查 nextTick 队列是否有入队的事件。如果队列不为空,Node 将会立马开始处理队列直到队列为空。
这引入了一个新的问题。递归地或者重复地使用 process.nextTick 往 nextTick 队列添加事件,可能会导致 I/O 或者其他的队列永远饿死(执行不到)。我们可以用以下代码片段模拟这个情节。
const fs = require('fs');function addNextTickRecurs(count) {let self = this;if (self.id === undefined) {self.id = 0;}if (self.id === count) return;process.nextTick(() => {console.log(`process.nextTick call ${++self.id}`);addNextTickRecurs.call(self, count);});}addNextTickRecurs(Infinity);setTimeout(() => {console.log('setTimeout called');}, 1000);setImmediate(() => { console.log('immediate called') });fs.readFile(__filename, () => {console.log('file read completely');});console.log('started');
你会发现无限循环地调用 nextTick 回调,setTimeout,setImmediate,fs.readFile 回调永远不会被调用。
startedprocess.nextTick call 1process.nextTick call 2process.nextTick call 3process.nextTick call 4process.nextTick call 5process.nextTick call 6process.nextTick call 7...
你可以给 addNextTickRecurs参数设置一个有限的值,setTimeout,setImmediate,fs.readFile 将会在 process.nextTick 调用结束调用。
在 Node v0.12 之前,有一个属性 process.maxTickDepth,可以设置 process.nextTick 队列长度的上限。可以手动被开发者设置,Node 不会从 nextTick 队列中每次执行时执行超过 maxTickDepth 数量的回调。由于某些原因被移除了。因此只能靠开发者来避免饿死的情况。
Timers 队列
当你使用 setTimeout 或者 setInterval 往 timers 队列中添加回调,Node 会往计时器堆里面添加 timer,计时器堆是一个通过 libuv 访问的数据结构,堆里面的 timer 根据过期时间升序排列的。在事件循环的 timers 阶段,Node 将会检查队列第一个 timer/interval 是否过期,如果有,然后调用它,出队。再检查当前队列的第一个,直到没有过期的,移到下一个阶段。如果有多个设置相同的过期时间的 timer,会按它们被添加到队列的顺序执行依次它们。
当一个 timer/interval 被设置特定的过期时间,回调肯定会在过期时间之后调用。至于会在回调过期时间多久调用,不能保证。依赖于系统的性能和当前事件循环中运行的进程(可能其他阶段有事情耽误了)。Node 在执行 timer 之前会检查是否过期(译者注:当前时间是否大于过期时间,有一个时间精度的问题,程序运行到 setTimeout 回调的时候,花费的时间是否超过那个精度,这是导致 setTimeout 和 setImmediate 顺序问题的原因),这也会消耗一部分 CPU 时间。
const start = process.hrtime();setTimeout(() => {const end = process.hrtime(start);console.log(`timeout callback executed after ${end[0]}s and ${end[1]/Math.pow(10,9)}ms`);}, 1000);
上面的程序将会在 1000ms 多之后执行到该 console.log 语句。如果你多次运行这个程序,你将会注意到,它会打印不同的时间。永远不会打印 “timeout callback executed after 1s and 0ms”。
timeout callback executed after 1s and 0.006058353mstimeout callback executed after 1s and 0.004489878mstimeout callback executed after 1s and 0.004307132ms...
这种特性会在 timeout 和 setImmediate 一起使用时导致不可预知的结果。我会在后面解释这个情况。
Immediates 队列
尽管 immediates 队列与 timeout 的表现上有些许相似,他有自己独特的特点。不像 timers,即使将过期时间设置为 0 ,也不能保证得到马上执行。immediate 队列能够保证在事件循环的 I/O 阶段之后马上执行。
setImmediate(() => { console.log('Hi, this is an immediate'); });
setTimeout vs setImmediate
现在让我们回过头来看下事件循环的图表,可以看到事件循环从 timers 队列开始的。然后处理 I/O,再到 immediate 队列。看这个图表,很容易推断出下面的输出。
setTimeout(function() {console.log('setTimeout')}, 0);setImmediate(function() {console.log('setImmediate')});
你可能猜到,这个程序将会一直在 setImmediate 之前打印 setTimeout。因为过期 timer 回调在 immediate 之前调用。但是这个程序的输出顺序从来不能保证!如果你多次运行这个程序,你会得到不同的输出。
这是因为设置一个过期时间为 0 的 timer 不能保证 timer 的回调刚好 0 秒后执行。由于这个原因,事件循环开始可能不会立即看到计时器到期。然后事件循环移到 I/O 阶段,接着来到 immediate 队列。然后它会看到在 immediate 队列看到一个事件,它会执行它。
但是如果我们看下面这段程序,我们可以保证 immediate 一定在 timer 回调之前触发。
const fs = require('fs');fs.readFile(__filename, () => {setTimeout(() => {console.log('timeout')}, 0);setImmediate(() => {console.log('immediate')})});
让我们看下这个程序的执行流程
- 开始,程序使用 fs.readFile 异步读取当前文件,然后提供了一个回调用于在文件读取完后触发。
- 然后事件循环开始了
- 一旦文件读取完毕,它将会添加事件(需要执行的回调)到事件循环 I/O 队列中。
- 因为没有其他需要处理的事件,Node 在等待 I/O 事件。然后 Node 在 I/O 队列发现读取完毕的事件,并且执行它。
- 在回调的执行期间,timer 被添加到计时器堆里,和一个 immediate 被添加到 immediates 队列里。
- 现在我们发现事件循环在 I/O 阶段。因为没有需要处理的 I/O 事件,且发现 immediate 队列里有事件,事件循环不会等待即将到来的 I/O 事件,直接移到 Immediate 阶段。然后 immediate 回调将会执行。
- 在下一轮的事件循环中,它发现有过期的 timer,并且它会执行 timer 的回调。
结论
让我们看下不同阶段队列在事件循环中一起工作会怎么样。看下面的例子。
setImmediate(() => console.log('this is set immediate 1'));setImmediate(() => console.log('this is set immediate 2'));setImmediate(() => console.log('this is set immediate 3'));setTimeout(() => console.log('this is set timeout 1'), 0);setTimeout(() => {console.log('this is set timeout 2');process.nextTick(() => console.log('this is process.nextTick added inside setTimeout'));}, 0);setTimeout(() => console.log('this is set timeout 3'), 0);setTimeout(() => console.log('this is set timeout 4'), 0);setTimeout(() => console.log('this is set timeout 5'), 0);process.nextTick(() => console.log('this is process.nextTick 1'));process.nextTick(() => {process.nextTick(console.log.bind(console, 'this is the inner next tick inside next tick'));});process.nextTick(() => console.log('this is process.nextTick 2'));process.nextTick(() => console.log('this is process.nextTick 3'));process.nextTick(() => console.log('this is process.nextTick 4'));
运行完上面的代码,下面的事件分别被添加到自己的队列中。
- 3 个 immediates
- 5 个 timer 回调
- 5 个 nextTick 回调
让我们看下执行的流程:
- 当事件循环开始的时候,它会注意到 nextTick 队列,然后开始处理 nextTick 队列。在第二个 nextTick 执行期间,一个新的 nextTick 被添加到 nextTick 队列末尾,将会在队列的结束的时候执行。
- timer 队列里过期的回调将会被执行。在第二个 timer 回调执行期间,一个 nextTick 被添加到 nextTick 队列。
- 一旦所有的过期 timer 回调执行完毕,事件循环将会在 nextTick 队列中发现有一个事件回调(在第二个 timer 回调执行期间添加的)。然后事件循环执行它。
- 因为没有需要处理 I/O 事件,且immediate 还有要处理的回调。因此,事件循环会移到 immediates 阶段,并且会处理 immediate 队列里面的回调。
好!如果你执行上面的代码,你将会得到下面的输出。
this is process.nextTick 1this is process.nextTick 2this is process.nextTick 3this is process.nextTick 4this is the inner next tick inside next tickthis is set timeout 1this is set timeout 2this is set timeout 3this is set timeout 4this is set timeout 5this is process.nextTick added inside setTimeoutthis is set immediate 1this is set immediate 2this is set immediate 3
Nodejs 事件循环(第三部分)- Promise,nextTicks,immediate
原生 Promises
在原生 promises 的上下文中,一个 promise 的回调被看成一个微任务和在微任务队列中入队,在 next tick 队列后面处理。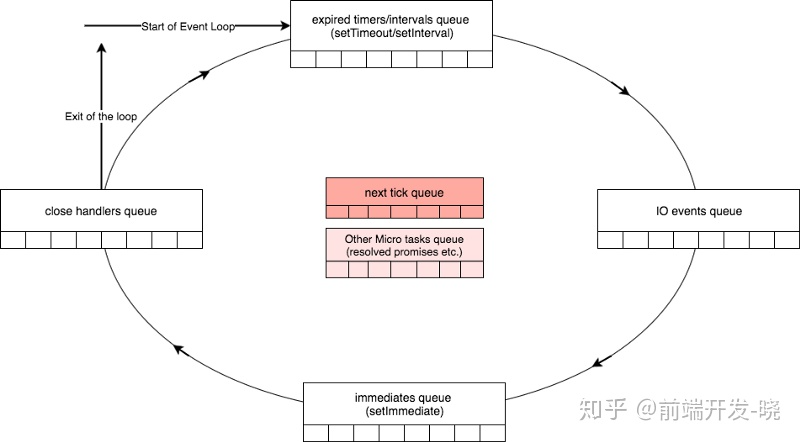
考虑下面的示例。
Promise.resolve().then(() => console.log('promise1 resolved'));Promise.resolve().then(() => console.log('promise2 resolved'));Promise.resolve().then(() => {console.log('promise3 resolved');process.nextTick(() => console.log('next tick inside promise resolve handler'));});Promise.resolve().then(() => console.log('promise4 resolved'));Promise.resolve().then(() => console.log('promise5 resolved'));setImmediate(() => console.log('set immediate1'));setImmediate(() => console.log('set immediate2'));process.nextTick(() => console.log('next tick1'));process.nextTick(() => console.log('next tick2'));process.nextTick(() => console.log('next tick3'));setTimeout(() => console.log('set timeout'), 0);setImmediate(() => console.log('set immediate3'));setImmediate(() => console.log('set immediate4'));
在上面的示例中,会发生下面的行为。
- 5 个回调处理器被添加到完成的 promise 的微队列中。(注意我添加了 5 个完成的回调处理器到 5 个已完成的 promise 中)
- setImmediate 队列中被添加 2 个回调处理器。
- process.nextTick 队列中被添加了 3 个回调处理器。
- 1 个带有过期时间为 0 的计时器,回调被加入到了计时器队列。
- setImmediate 队列中被添加了 2 个回调处理器。
然后事件循环将会开始检查 process.nextTick 队列。
- 循环将会辨识出在 process.nextTick 队列中有 3 项,Node 将会开始处理 nextTick 队列直到队列为空。
- 然后事件循环将会检查 promises 微队列并且辨识出有 5 项,然后开始处理队列。
- 在 promises 微队列处理过程中,process.nextTick 队列中再次被添加一项。
- promises 微队列被处理完后,事件循环会再次检测到 process.nextTick 队列中有一项(在处理 promises 微队列过程中添加的)。然后 node 将会处理 nextTick 队列中剩余的一项。
- 足够多的 promises 和 nextTicks。这里没有剩余的微任务了。然后事件循环移到第一个阶段,timers 阶段。这时,它会发现在计时器队列中有一个过期的 timer 回调,然后会处理这个回调。
- 现在没有其他定时器回调了,循环将会等待 I/O。因为我们没有任何的即将发生的(pengding) I/O,循环会继续,开始处理 setImmediate 队列。它在 immediate 队列中发现了 4 项,并且处理它们,直到 immediate 队列为空。
- 最后,循环做完了一切事情… 然后程序优雅地退出。
看到这两个词“promises 微任务”就足够了,而不是“微任务”。
我知道到处看到它是个痛苦,但是你知道 resolved/rejected promise 和 process.nextTick 都是微任务。因此相信我,我不能只说 nextTick 队列和 微任务(microtask)队列。
因此,我们看下上面示例的输出。
next tick1next tick2next tick3promise1 resolvedpromise2 resolvedpromise3 resolvedpromise4 resolvedpromise5 resolvednext tick inside promise resolve handlerset timeoutset immediate1set immediate2set immediate3set immediate4
NodeJS 事件循环(第四部分)- 处理 IO
异步 I/O … 因为阻塞太主流了
当谈论 NodeJS 时,我们谈论了很多异步 I/O。像我们在第一篇中讨论的那样,I/O 从来不意味着是同步的。
在所有的系统实现中,他们都为异步 I/O 提供了事件通知接口(Linux 中的 epoll/macOS 中的 kquue/ solaris 中的 event ports / windows 中的 IOCP)。NodeJS 利用这些平台级别的事件通知系统提供非阻塞的,异步 I/O。
正如我们看到的,NodeJS 是实体的集合最终聚合成高性能的 NodeJS 框架。包含以下实用工具:
- Chrome v8 引擎 — 高性能 JavaScript 执行
- Libuv — 提供异步 I/O 的事件循环
- c-ares — 提供 DNS 操作
- 其他的插件如 (http-parser, crypto and zlib)
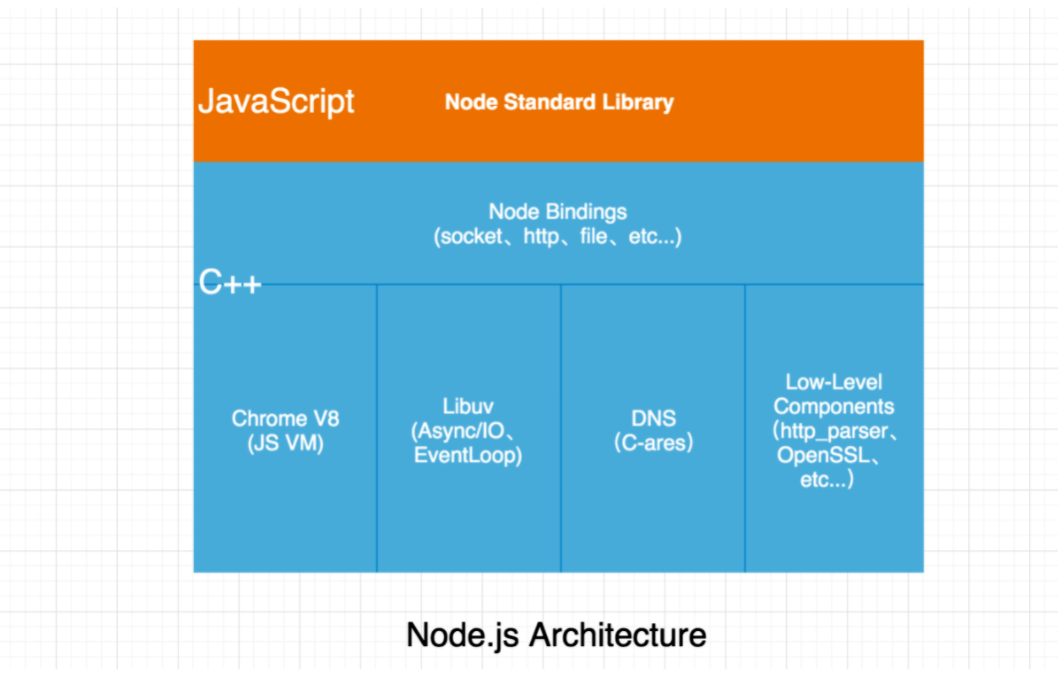
NodeJS 的架构
在这篇文章中,我们将会讨论 Libuv 及如何为 Node 提供异步的 I/O。让我们看下事件循环图表。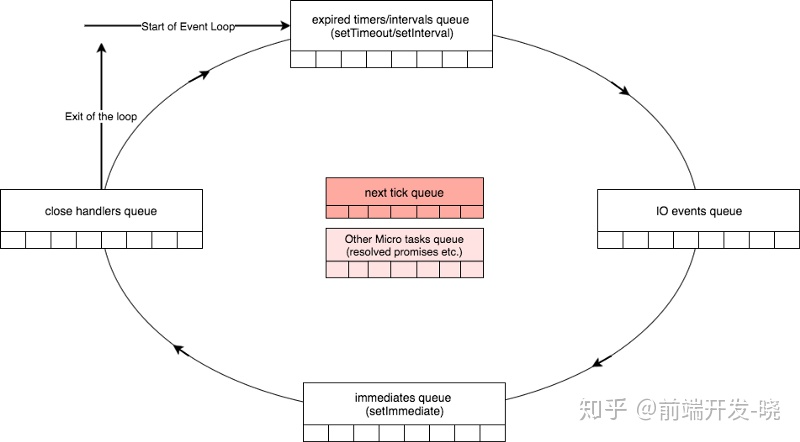
图表2:事件循环概括
到目前为止关于事件循环我们学了哪些:
- 事件循环从处理所有过期的计时器开始。(实际上在处理之前还会检查下 nextTick 和 microtask)
- 然后它将处理所有的即将发生的(本来大多数 I/O 回调会在本轮的 I/O 轮询阶段处理掉,但有上一轮延迟到这一轮的 I/O 回调。另外还有一些 I/O 错误回调) I/O 操作,然后选择性(是否等待,取决于 Immediate 队列是否为空或 timers 队列是否有过期的 timer 等)地等待 I/O 事件。
- 然后会移到 immediate 队列处理 setImmediate 回调
- 最后会处理所有的 I/O 关闭回调
- 在每个阶段之间,libuv 需要和 Node 架构的高层沟通(JavaScript),将会处理 process.nextTick 和 microtask 回调。
现在让我们试着理解下事件循环中如何处理 I/O。
I/O 是什么?
通常来说,任何涉及到额外的设备(除了 CPU)都被称为 I/O。最普遍抽象 I/O 是文件操作和 TCP/UDP 网络操作
Libuv 和 NodeJS I/O
JavaScript 本身没有处理 I/O 的设施。在 NodeJS 开发期间,libuv 最初就是为 Node 提供异步的 I/O,尽管当前,Libuv 作为一个独立库可以被单独使用。Libuv 在 NodeJS 架构中的角色是抽象内部 I/O 的复杂性和为Node 的上层(JavaScript)提供一个通用的接口,以便 Node 可以异步的处理 I/O 而不用担心目前运行所在的平台类型。
当心!
如果你不理解事件循环,我建议你读之前的文章。这里我会省略某些细节,因为我会更关注 I/O 本身。
我可能使用一些 libuv 的代码片段,我只会使用 Unix 平台的代码片段,只让事情简单点。window 平台的可能有点儿差异,应该差异不大。
我假设你有 C 语言的一些基础。没有经验要求,有个基本的了解就足够了。
正如我们在 NodeJS 架构图表中看到的,libuv 驻留在层架构中较低的层。JavaScript 的高层和 libuv 事件循环阶段的关系。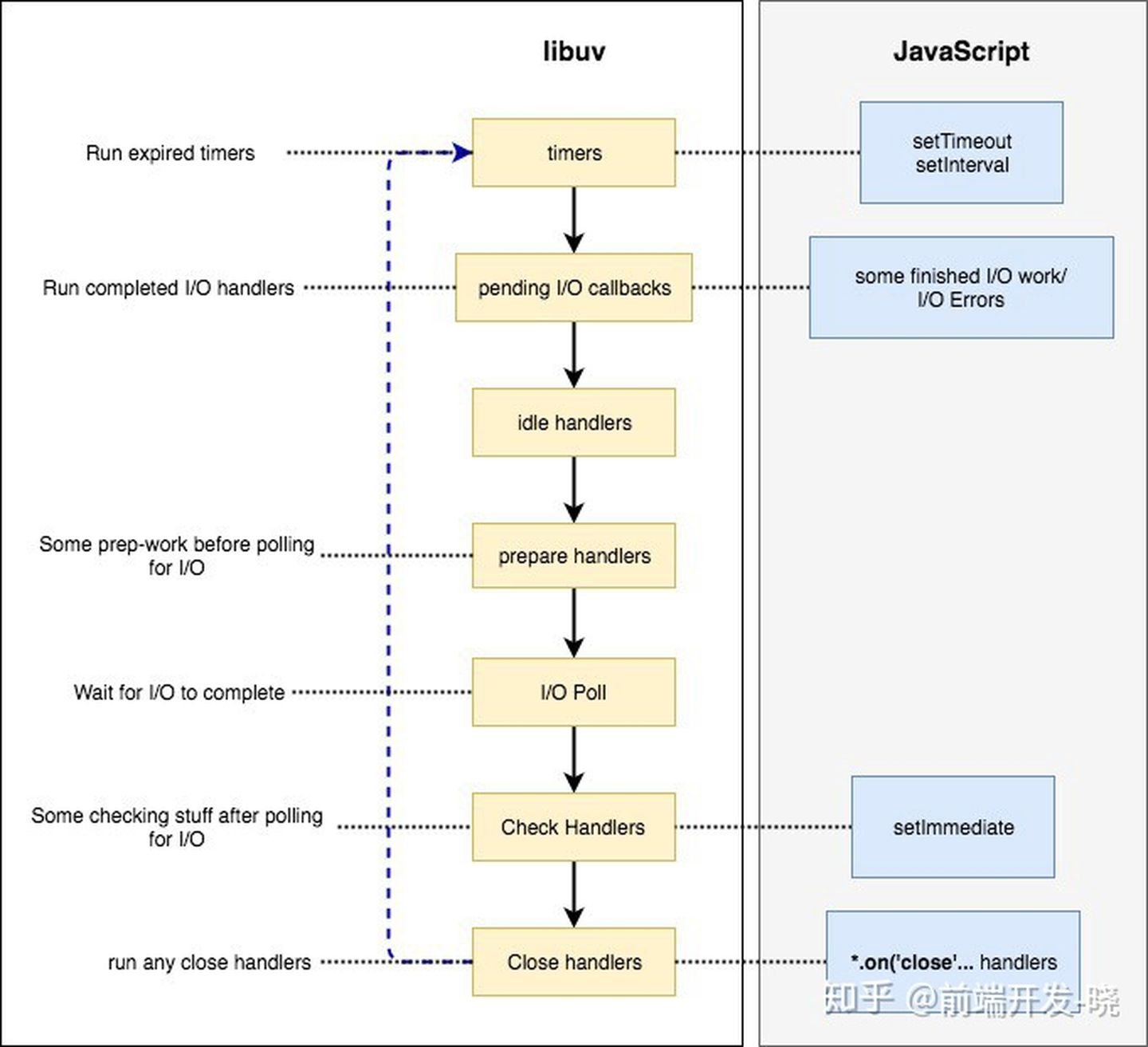
图表3:事件循环和 JavaScript
正如我们在图表2 中看到的,事件循环中有 4 个阶段。但是,当谈论到 libuv,有 7 个阶段。它们是:
- Timers — 被 setTimeout 和 setInterval 调度的过期 timer 和 interval 回调 在这个阶段触发
- 即将发生的 I/O 回调 — 任何 完成的/错误的I/O 操作将在这里执行。(完成是指上一轮完成的,延迟到这一轮了)
- Idle 处理器 — libuv 一些内部操作
- Prepare 处理器 — 在 I/O 轮询之前的一些准备工作
- I/O 轮询 — 处理 I/O 回调及选择性地等待 I/O 操作
- Check 处理器 — 执行一些 I/O 轮询后的一些时候工作, 通常, 执行被 setImmediate 调度的回调。
- Close 处理器 — 处理所有的关闭 I/O 回调 ( 关闭的 socket 连接等)
现在,如果你记得这个系列的第一篇文章,你可能会猜想…
- 什么是检查处理器?在事件循环图表中没有的
- I/O 轮询是什么? 为什么执行完完成的 I/O 后要阻塞 I/O ?Node 不应该是非阻塞的吗?
检查处理器
当 NodeJS 初始化后,它会在 Libuv 中设置所有的 setImmediate 回调注册为检查处理器。这本质上意味着任何一个你使用 setImmediate 的回调最终会在 libuv 的检查处理器队列,保证在 I/O 轮询之后处理。
I/O 轮询
你现在可能想知道 I/O 轮询是什么。尽管我在图表 1 中将 I/O 回调队列和 I/O 轮询放在了一个阶段,消费完 completed/errored I/O 回调会发生 I/O 轮询。
但是,在 I/O 轮询中最重要的是,可选择的。I/O 轮询是否会发生依赖于特定的情景。为了彻底地理解,让我们看下如何在 libuv 中实现的。
r = uv__loop_alive(loop);if (!r)uv__update_time(loop);while (r != 0 && loop->stop_flag == 0) {uv__update_time(loop);uv__run_timers(loop);ran_pending = uv__run_pending(loop);uv__run_idle(loop);uv__run_prepare(loop);timeout = 0;if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)timeout = uv_backend_timeout(loop);uv__io_poll(loop, timeout);uv__run_check(loop);uv__run_closing_handles(loop);if (mode == UV_RUN_ONCE) {uv__update_time(loop);uv__run_timers(loop);}r = uv__loop_alive(loop);if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)break;}
哎呀!如果不熟悉 C 可能看起来有点儿眼花。但让我们试着看下,不用担心。上面的代码在 libuv 源码 core.c 文件中,是 uv_run 方法的一部分。但最为重要的是,这是 NodeJS 事件循环的核心。
如果你再次看下图表 3,上面的代码将更有意义。让我们试着一行一行地看下。
- uv_loop_alive - 检查下是否有引用的需要触发的处理器,或者任何活跃的即将发生的操作
- uv_update_time - 这会发送一个系统调用获取当前的时间,并且更新循环时间(为了辨识计时器是否过期)
- uv_run_timers - 运行所有过期的计时器
- uv_run_pending - 运行所有的 完成的/错误的 I/O 回调
- uv_io_poll - I/O 轮询
- uv_run_check - 运行所有的检查处理器(setImmediate 回调将会在这里运行)
- uv_run_closing_handles - 运行所有的关闭回调
首先,事件循环会检查事件循环是否活着,通过触发 uv_loop_alive 函数。这个函数很简单。
static int uv__loop_alive(const uv_loop_t* loop) {return uv__has_active_handles(loop) ||uv__has_active_reqs(loop) ||loop->closing_handles != NULL;}
uv_loop_alive 简单地返回了一个 boolean 值。这个值是 true, 如果:
- 有需要触发的活跃的处理器(handles)
- 有活跃的未决的请求(活跃的操作)
- 有任何一个关闭处理器需要触发
事件循环将会继续旋转只要 uv__loop_alive 函数返回 true。
运行完所有的过期的计时器,uv_run_pending 将会被触发。这个函数会仔细检查存储在pending_queue 中完成的 I/O 操作。如果 pending_queue 队列是空的,这个函数会返回个 0。否则,所有在 pending_queue 队列的回调会被执行,并且函数会返回 1。
static int uv__run_pending(uv_loop_t* loop) {QUEUE* q;QUEUE pq;uv__io_t* w;if (QUEUE_EMPTY(&loop->pending_queue))return 0;QUEUE_MOVE(&loop->pending_queue, &pq);while (!QUEUE_EMPTY(&pq)) {q = QUEUE_HEAD(&pq);QUEUE_REMOVE(q);QUEUE_INIT(q);w = QUEUE_DATA(q, uv__io_t, pending_queue);w->cb(loop, w, POLLOUT);}return 1;}
现在,让我们看下 I/O 轮询,通过触发 libuv 中的 uvio_poll 函数。
你应该看到 uv_io_poll 函数接受第二个 timeout 参数,该参数是由 uv_backend_timeout 返回的。uvio_poll 使用 timeout 决定应该阻塞多长的 I/O。如果 timeout 是 0,I/O 轮询将会跳过并且事件循环会移到检查处理器阶段(setImmediate phase)。timeout 值得由来是一个有趣的部分。基于上面 uv_run 的代码,我们可以推断出:
- 如果事件循环以 UV_RUN_DEFAULT 模式运行,timeout 是由 uv_backend_timeout 函数算出来的。
- 如果事件循环运行在 UV_RUN_ONCE模式,并且如果 uv_run_pending 返回 0(pending_queue 是空的),timeout 由uv_backend_timeout 方法算出来的。
- 否则,timeout 是 0。
不要担心 事件循环模式的差异性比如 UV_RUN_DEFAULT 和 UV_RUN_ONCE。但是如果你特别感兴趣,可以看这里
让我们窥视下 uv_backend_timeout 方法理解 timeout 是如何被算出来的。
int uv_backend_timeout(const uv_loop_t* loop) {if (loop->stop_flag != 0)return 0;if (!uv__has_active_handles(loop) && !uv__has_active_reqs(loop))return 0;if (!QUEUE_EMPTY(&loop->idle_handles))return 0;if (!QUEUE_EMPTY(&loop->pending_queue))return 0;if (loop->closing_handles)return 0;return uv__next_timeout(loop);}
- 如果循环的 stop_flag 被设置了,决定着循环要准备退出了,timeout 是 0。
- 如果没有活跃的处理器或者活跃的未决的操作,是没有意义的等待。因此 timeout 是 0。
- 如果这里有未决的空闲的处理器需要处理,不应该等待,因此 timeout 是 0。
- 如果在 pengding_queue 中有完成的 I/O 处理器,不应该等待,因此 timeout 是 0。
- 如果有任何未决的关闭的处理器要处理,不应该等待,因此 timeout 是 0。
如果满足以上标准,uv__next_timeout 方法会被调用决定 libuv 等待 I/O 多长时间。
int uv__next_timeout(const uv_loop_t* loop) {const struct heap_node* heap_node;const uv_timer_t* handle;uint64_t diff;heap_node = heap_min((const struct heap*) &loop->timer_heap);if (heap_node == NULL)return -1; /* block indefinitely */handle = container_of(heap_node, uv_timer_t, heap_node);if (handle->timeout <= loop->time)return 0;diff = handle->timeout - loop->time;if (diff > INT_MAX)diff = INT_MAX;return diff;}
uv__next_timeout 做了什么,返回返回最近的 timer 的过期时间,如果没有 timers,它将返回 -1,表明 无限等待。
现在,你应该对这个问题有答案了。“为什么执行完任何一个完成的 I/O 回调要阻塞 I/O?Node 不应该是非阻塞的吗”….
如果有任何未决的任务需要处理,事件循环就不会阻塞。如果这里没有未决的任务需要执行,它将会阻塞直到下一个 timer 到期,会重新激活循环。
我希望你仍然在跟着我的思路!!!我知道这里牵扯了太多的细节,但是为了彻底高明白,必须清楚发生了什么。
现在我们知道循环应该等待 I/O 多长时间。timerout 值被传递给了 uv__io_poll 函数。这个函数会等待任何一个到来的 I/O 操作,直到 timeout 过期或者到达系统指定的最大安全的 timeout。timeout 之后,事件循环将会再一次变得 活跃并且会移到 “检查处理器”阶段。
I/O 循环在不同的操作系统上面发生的不一样。在 Linux 中,是被 epoll_wait 内核系统调用,在 macOS 上使用的是 kqueue。在 windows 上面,使用的是 IOCP 的 getQueueCompletionStatus。我不会深入到 I/O 轮询是如何工作的,因为非常复杂,需要另一个系列才能说清楚(应该是不会写的)。
IO 轮询阶段总结:
1.回到 timer 阶段执行回调
2.执行 I/O 回调
并且在进入该阶段时如果没有设定了 timer 的话,会发生以下两件事情
- 如果 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
- 如果 poll 队列为空时,会有两件事发生
- 如果有 setImmediate 回调需要执行,poll 阶段会停止并且进入到 check 阶段执行回调
- 如果没有 setImmediate 回调需要执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
关于线程池
目前为止,在这篇文章中还没有谈论线程池。像我们在这个系列的第一篇文章看到的,线程池被用来执行部分 I/O 操作,在 DNS 操作中,调用 getaddrinfo 和 getnameinfo 仅仅是因为在不同操作系统平台文件 I/O 的复杂性。因为线程池限制的大小(默认 4),多个文件系统操作的请求可能阻塞直到一个线程变得可用。然而,线程池的大小使用环境变量 UV_THREADPOOL_SIZE 可以增加到 128(在本文撰写的时候),以增加应用的性能。
不过固定大小的线程池已经被确定为 NodeJS 应用程序的一个瓶颈,因为文件 I/O,getaddrinfo,getnameinfo 并不是唯一在线程池上运行的。特定的 CPU 密集型的加密操作,如 randomBytes,randomFill 和 pbkdf2 也是在线程池上运行的,防止负面影响程序的性能,但也应让 I/O 操作稀缺的线程资源变得可用。
从上一个 libuv 的改进建议,建议让线程池基于负载变得可扩展,但是这个提议被撤销了,可能在未来会换成一个插件化的 API。
NodeJS 事件循环(第五部分)- 最佳实践
在同步代码块避免同步 I/O
平时试着在重复触发的代码块(如循环,常调用的函数)避免同步 I/O 函数。否则会在相当大的范围降低你应用的性能,因为每次同步 I/O 执行,事件循环会阻塞直到完成。同步函数最安全的用例是在程序启动时间读取配置文件。
函数应该异步完成还是同步完成
你的应用有很多小的被称为函数的组件组成。在 NodeJS 应用中,这里会有两个类型的函数。
- 同步函数 - 大多数使用 return 返回输出(比如 Math 函数,fs.readFileSync 等)或者使用 CPS 风格(函数式编程中的)返回结果或者执行操作(Array prototype 函数如 map,filter,reduce 等)。
- 异步函数 - 返回结果延迟使用回调或者一个 promise(fs.readFile,dns.resolve 等)
经验法则是,你书写的函数应该是,
- 完全同步的 - 所有的输入和条件同步行为
- 完全异步的 - 所有的输入和条件异步行为
如果你的函数是一个上面两种不同行为的混合。可能会导致你应用不可预见的输出。让我们看下示例,
const cache = {}function readFile(fileName, callback) {if(cache[fileName]) {return callback(null, cache[fileName])}fs.readFile(fileName, (err, fileContent) => {if(err) return callback(err);cache[fileName] = fileContent;callback(null, fileContent);})}
现在让我们使用上面不一致的函数写一个小的应用。为了容易阅读,省略了错误处理。
function letsRead() {readFile('myfile.txt', (err, result) => {// error handler redactedconsole.log('文件读取完成');});console.log('文件读取开始');}
现在如果你使用 letsRead 函数两次,你会得到下面的输出。
file read initiatedfile read completefile read completefile read initiated
看到了吧,两次的输出并不一样。当你的应用变得复杂,这些不一致的同步-异步混合函数可能导致很多问题,异常的难修复和调试。因此强烈建议遵循上面的同步、异步原则。
那么,我们如何修复上面的 readFile 函数。有两个方法:
方法1:使用 readFileSync 函数把上面的 readFile 函数完全变成同步的
方法2:通过触发异步回调把 readFile 函数变成异步的
正如我们看到的,我们知道在多次调用函数内部调用函数的异步形式一直都是提倡的。因此,我们不应该使用方法1,它会有性能问题。然后我们如何实现方法 2呢,我们怎么异步调用函数,简单,使用 process.nextTick
const cache = {};function readFile(filename, callback) {if(cache[filename]) {return process.nextTick(() => callback(null, cache[filename]));}fs.readFile(filename, (err, fileContent) => {if(err) return callback(err);cache[filename] = fileContent;callback(null, fileContent);})}
process.nextTick 将会延迟回调到事件循环的下一个阶段执行。现在,如果你执行 letsRead 函数两次,你将会得到输出:
file read initiatedfile read completefile read initiatedfile read complete
你也可以使用 setImmediate 达到同样的目的,但是我愿意使用 process.nextTick,因为 nextTick 队列比 immediate 队列处理的要频繁。
太多的 nextTicks
尽管 process.nextTick 在很多情形下很有用,递归使用 process.nextTick 可能会导致 I/O 饿死。这会强制 Node 递归执行 nextTick,不会移动到 I/O 阶段。
之前的版本(<0.10)提供了一个方式,使用 process.maxTickDepth 设置 nextTick 回调调用的最大的次数。但是被移除了,目前没有办法限制 nextTick 无限期地调用。

若有收获,就点个赞吧
0 人点赞
