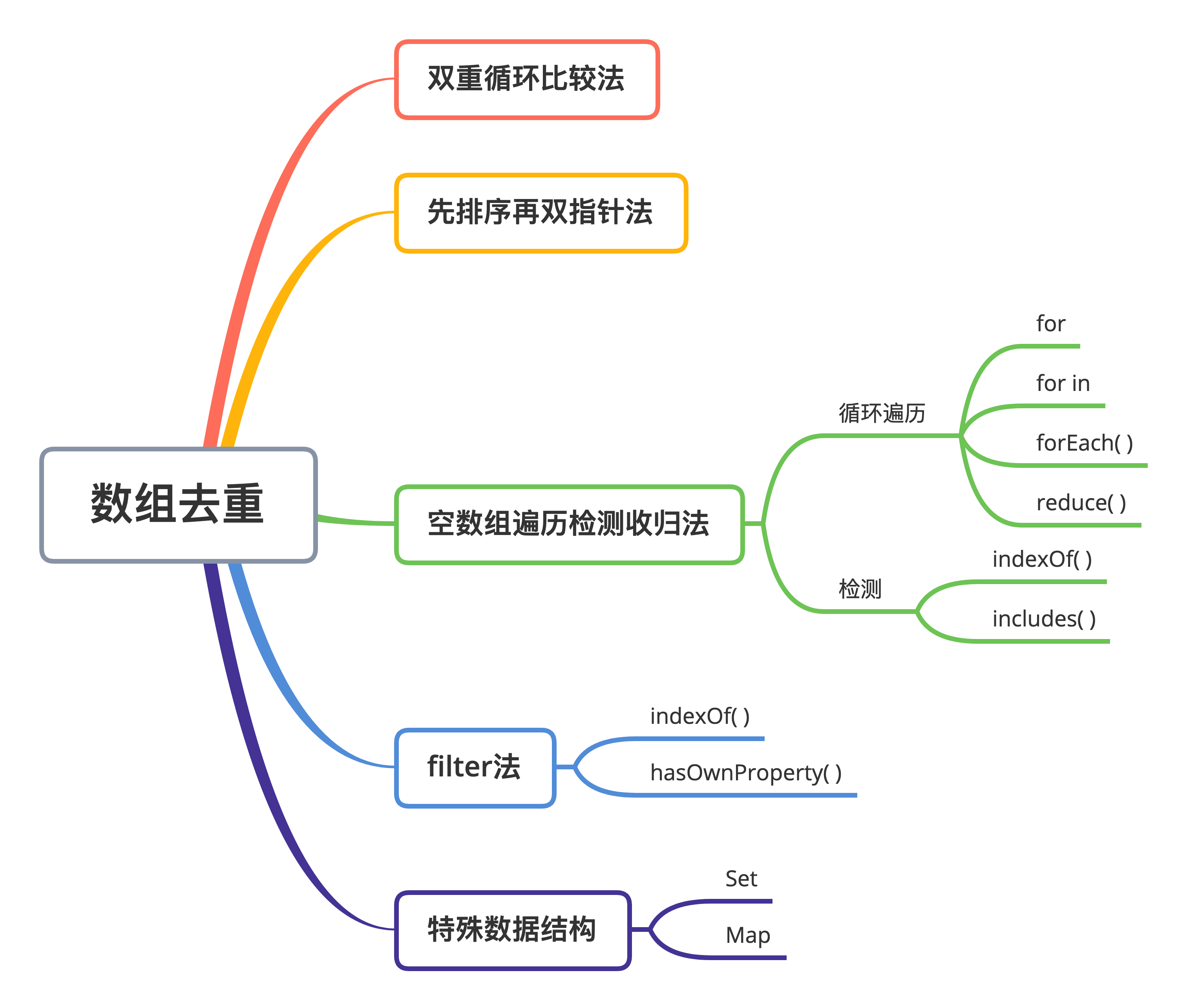
写在前面
- 关于数组去重,其实主要的算法可以大致分为以下这么几类
- 新建数组,循环遍历原数组并取新数组中不存在的唯一值push进新数组;
- 先排序,再从头到尾遍历取连续多个重复项的第一个;
- 使用过滤器filter;
- 利用JavaScript特殊的数据结构来去重(主要利用Set和Map中Key的唯一性);
双层循环比较法(笨死了)
这个算法是最容易
(用脚趾都可以)想到的方法,也就是双层循环比较法。外层循环遍历数组中每个元素,内层循环遍历其他元素并与外层循环的当前元素比较,如果不同就不进行操作,相同则删除掉。不必多说看代码。function unique(array) {// 外层循环遍历数组的所有元素for (let i = 0; i < array.length; i++) {// 内层循环遍历当前i位置之后的所有元素for (let j = i + 1; j < array.length; j++) {// 如果i位置后的元素中有和当前i位置元素值相同的if (array[i] === array[j]) {// 就使用splice()删除这个重复元素array.splice(j, 1);j--;}}}return array;}
为什么我们说它是最笨的方法呢,因为双层循环O(n)的时间复杂度实在是。。。当然也可能是因为它使用了splice()?(我并不确定),详见深入一点 - 为什么说splice效率低呢?
- 好了,是时候忘记这个渣男了!
先排序再双指针法
- 先排序,再取多个连续重复项的第一个(可原地,节省空间)
这其实与Leetcode第26题非常相似,只不过那道题的要求是“对有序数组原地去重”:
Leetcode 26. 删除排序数组中的重复项 给定一个有序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
我们看一下这个动画可以更为形象地理解(视频来源:Leetcode.26 - 景禹)

源代码如下(快慢指针法)
function unique(array) {// 先对数组进行排序array = array.sort();// 如果数组只有0或1项,显然不可能有重复项// 直接返回原数组if (array.length < 2) {return array;}// 双指针法原地去重// 设慢指针指向数组的第一项let left = 0;// 快指针指向数组的第二项let right = 1;// 循环终止条件:快指针遍历完数组while (right < array.length) {if (array[left] === array[right]) {// 当快指针和慢指针的数据相同时// 不进行任何操作,快指针向后移动一位right++;} else {// 当快慢指针的数据不同时// 将慢指针后一位的数据变更为快指针当前位置数据// 快慢指针同时向后移动一位array[left + 1] = array[right];left++;right++;}}// 去重结束后,left指针刚好指向去重后数组的最后一位// 使用slice()取0-left正好是去重后的数组return array.slice(0, left + 1);}
这种方法的好处是:
- 原地算法,不需要占用额外的空间,空间复杂度O(1);
空数组遍历检测收归法(瞎起的)
- 这种方法的核心思想就是:
- 新建一个空数组,我们这里暂且称其为M
- 遍历原数组,检测其中的每个元素是否已经在M中
- 如果不在,则添加进去;如果已经存在,则不进行任何操作
- 当遍历完原数组后,获得的M也就是原数组去重后的结果
- 其中,循环可以使用普通
for循环、forEach()、或者for in,基本思想都是类似的,只不过运行的效率上可能有一些差别; - 而检测的过程可以使用
indexOf()或者includes()。当然indexOf()和includes()会有一些细微差别,主要有以下两点:
- indexOf()可以找到NaN和undefined,includes()不能;
- indexOf()无法区分”+0”和”-0”,includes()则可以;
-
使用普通
for循环搭配includes()// 使用的是普通for循环function unique(array) {// 新建一个空数组,用于临时存放结果let result = [];// 使用循环遍历原数组并检测for (let i = 0; i < array.length; i++) {// 如果一个元素不存在于新数组,则收入囊中// 如果已经存在,则不进行操作if (!result.includes(array[i])) {result.push(array[i]);}}// 遍历完原数组后,最后得到的result即为去重后的结果return result;}
forEach()搭配indexOf()function unique(array) {// 新建一个空数组,用于临时存放结果let result = [];// 使用forEach()循环遍历原数组并检测array.forEach(element => {// 如果一个元素不存在与新数组,则收入囊中// 如果已经存在,则不进行操作if (result.indexOf(element) === -1) {result.push(element)}});// 遍历完原数组后,最后得到的result即为去重后的结果return result;}
使用
reduce()拼接 虽然使用reduce来拼接看起来似乎与循环关系不大,但是本质上还是很相似的。那就是通过对原数组中每个元素的判断来进行不同的操作,将结果逐步添加到reduce累加器的结果中。
- 所以从本质上来讲,将这种方法归到了空数组遍历检测收归方法中。
- 看看代码吧:
function unique(array) {// 使用reduce来拼接数组// 对于原数组中的每个元素都进行判断// 如果这个元素已经存在于之前拼接好的数组中的话,就不再进行任何操作// 如果这个元素尚未存在于之前拼接好的数组中的话,就将它拼接到数组中// 最后返回拼接好的数组return array.reduce((previous, current) => previous.includes(current) ? previous : [...previous, current], []);}
过滤(filter)法
- 刚刚的方法中使用for循环其实是对每个元素逐一筛选,而这一节中我们使用
filter()来实现这种筛选。 - 另外一个值得注意的地方就是,
filter()是具有返回值的,可以直接将这个值作为函数的返回值。 -
filter搭配indexOf
基本思想是利用了“indexOf()会返回给定元素在数组中的第一个索引”,这样的话我们可以很容易找到重复元素中的第一个,并把它保留,任何不是重复值中第一个的,都会被抛弃。
function unique(array) {return array.filter((element, index, array) => {// indexOf会返回给定元素在数组中的第一个索引// 下面这句话会判断当前的element是否是同值元素中的第一个// 如果是,说明符合条件,就返回// 如果不是,说明是重复元素的第n个(n>=2),则跳过return array.indexOf(element) === index;})}
filter搭配hasOwnProperty()
利用了一个对象
- 对于数组中的每个元素,将它的值和类型拼接成一个字符串,并与对象的属性列表进行比对
- 如果对象的属性列表中已经存在这个拼接的字符串,说明这个值并不是原数组中重复元素的第一个,可以忽略
- 否则的话说明是第一次出现,需要加入到对象的属性列表中
function unique(array) {var obj = {};return array.filter(function (item, index, arr) {return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)})}
使用特殊数据结构法
使用Set
- 这种方法代码比较简洁,使用的是Set的Key值不能重复这个特征。
function unique (array) {// 先使用原数组构造一个Set对象,自然去重了// 然后再将这个Set对象转化为一个数组,并返回return Array.from(new Set(array))}
使用Map
- 在用Set成功实现了之后,再去使用Map可能看起来有点画蛇添足,但是当然也是可以实现的,但是写法着实不太优雅(可能是我写的不够优雅吧)。
- 使用的原理与Set一样,也是不能Key重复。
function unique(array) {// 新建一个Map对象用来存放已经判断过的数组元素// 确实有点画蛇添足let map = new Map();// result暂存结果let result = new Array();for (let i = 0; i < array.length; i++) {if (!map.has(array[i])) {// 如果没有该key值,// 首先在Map中标记,然后push进结果数组map.set(array[i], true);result.push(array[i]);}}return result;}
基本就这些,有一些比较冷门的后续再来补充

若有收获,就点个赞吧
0 人点赞
