- 序列化与反序列化
- 模型保存与加载的两种形式
- 模型断点续训练
一、序列化与反序列化
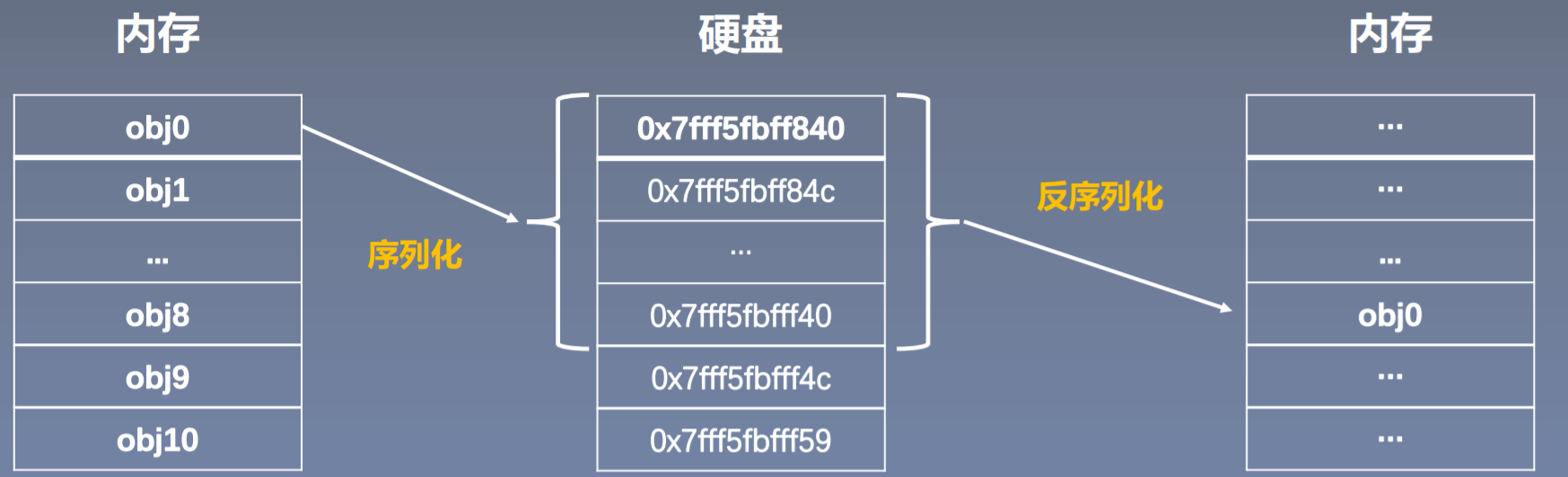
我们知道我们现在训练好一个模型是要在以后去使用它。但是在训练过程中,模型是存储到内存当中的,内存中的数据不具备有长久性存储的功能,所以我们需要把模型从内存上搬到我们的硬盘当中,进行长久的存储,以备将来使用。这就是模型的保存与加载,也被称为序列化与反序列化。这里我们就来理解一下为什么模型的保存与加载就称之为序列化与反序的。
序列化与反序列化主要指的是内存与硬盘之间的数据转换关系。我们知道模型在内存当中是以一个对象形式存储的,但是内存当中对象不能长久的保存,所以我们要将它保存到硬盘当中。但是在硬盘当中数据是以二进制数进行一个保存的,这些就是二进制序列。所以我们的序列化是指将内存当中的某一个对象保存到硬盘当中,以二进制序列的形式存储下来。对应了PyTorch中的模型。我们可以理解为将模型转成二进制的数存储到硬盘当中,已达到长久保存的目的。
那么什么是反序列化?就是将存储在硬盘中的二进制的数,再反序列化,放到我们内存当中,得到一个对象。这样就可以使用这个模型了。
以上就是整个序列化和反区别化的一个过程。那最主要的目的:是将数据、模型可以长久的保存。那么下面我们就具体来看PyTorch中所提供的序列化与反序列化的函数。
这是c然后我们看右边第二个函数load加载序列化它的主要参数也是两个,一个是我们文件的路径,就对应着我们cf当中的这一点。然后呢有个比较重要的参数是mp locution这个参数是来指定我们存储在什么。这个主要是用gpu剑修炼时候,这一个非常重要。因为我们gq上训练的模型保存下来之后呢,采用对话的方式是不能直接加载进来的,不能漏进来的。我们需要设置这个map location这一个具体的使用。在讲解gpu的时候要详细的分析。这里我们暂时不用去关心。因为现在我们都是cpu上保存,cpu上加载,所以这个不用关心。其实。
模型序列化 - torch.save()
主要参数:
obj:对象。想要保存的数据:可以是模型,可以是张量,也可以是dict等等。-
模型反序列化 -
torch.load() f:文件路径map_location:指定存放位置,CPU or GPU->
保存模型是为了在下一次继续去使用。那什么东西是在模型训练之后才得到的呢?其实就是一系列的可学习参数 parameters 。
所以有一种方法就是只保存模型的可学习parameters,将这些模型训练得到的参数保存下来。在下一次我们构建一个模型,再把这些可学习参数放回到我们的这个模型当中,这样就完成了模型的保存与加载。
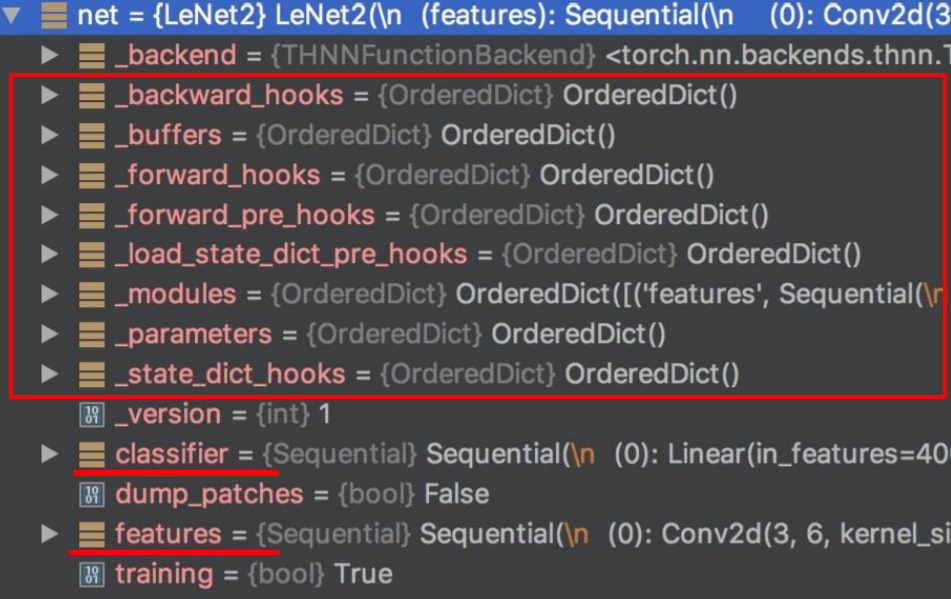
还有一种比较懒的方法呢,就是整个模型都保存下来。整个net都存储下就不用关心模型的结构是怎么样的。但是这个方法可能比较耗时、占内存。官方推荐第一种方法:只保存模型的参数。
**
在这里我们看到保存模型参数呢将要用到 module类 的一个方法叫做 state() 。这个函数可以把模型当中的可学习参数都保存下来,返回一个dict、字典的形式,我们通常会称为 state_dict。
import torchimport torch.nn as nnclass LeNet2(nn.Module):def __init__(self, classes):super(LeNet2, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 6, 5),nn.ReLU(),nn.MaxPool2d(2, 2),nn.Conv2d(6, 16, 5),nn.ReLU(),nn.MaxPool2d(2, 2))self.classifier = nn.Sequential(nn.Linear(16*5*5, 120),nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),nn.Linear(84, classes))def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return xdef initialize(self):for p in self.parameters():p.data.fill_(20191104)net = LeNet2(classes=2019)# "训练"print("训练前: ", net.features[0].weight[0, ...])net.initialize() # 模拟参数改变print("训练后: ", net.features[0].weight[0, ...])path_model = "./model.pkl"path_state_dict = "./model_state_dict.pkl"# 保存整个模型torch.save(net, path_model)# 保存模型参数net_state_dict = net.state_dict()torch.save(net_state_dict, path_state_dict)
import torchimport torch.nn as nnclass LeNet2(nn.Module):def __init__(self, classes):super(LeNet2, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 6, 5),nn.ReLU(),nn.MaxPool2d(2, 2),nn.Conv2d(6, 16, 5),nn.ReLU(),nn.MaxPool2d(2, 2))self.classifier = nn.Sequential(nn.Linear(16*5*5, 120),nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),nn.Linear(84, classes))def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return xdef initialize(self):for p in self.parameters():p.data.fill_(20191104)# ================================== load net ===========================flag = 1# flag = 0if flag:path_model = "./model.pkl"net_load = torch.load(path_model)print(net_load)# ================================== load state_dict ===========================flag = 1# flag = 0if flag:path_state_dict = "./model_state_dict.pkl"state_dict_load = torch.load(path_state_dict)print(state_dict_load.keys())# ================================== update state_dict ===========================flag = 1# flag = 0if flag:net_new = LeNet2(classes=2019)print("加载前: ", net_new.features[0].weight[0, ...])net_new.load_state_dict(state_dict_load)print("加载后: ", net_new.features[0].weight[0, ...])
我们先来看模型加载的第一种模式,就是整个模型保存、整个模型加载的这种模式。
path_model = "./model.pkl"
net_load = torch.load(path_model)
这里只有两行,非常简单。
- 第一步:设置pkl文件的路径。
- 第二部:
torch.load()加载模型序列化到硬盘的路径
设置debug,看一下 net_load 中有什么数据。在下图中可以看到,其实和我们刚刚保存的是一模一样的。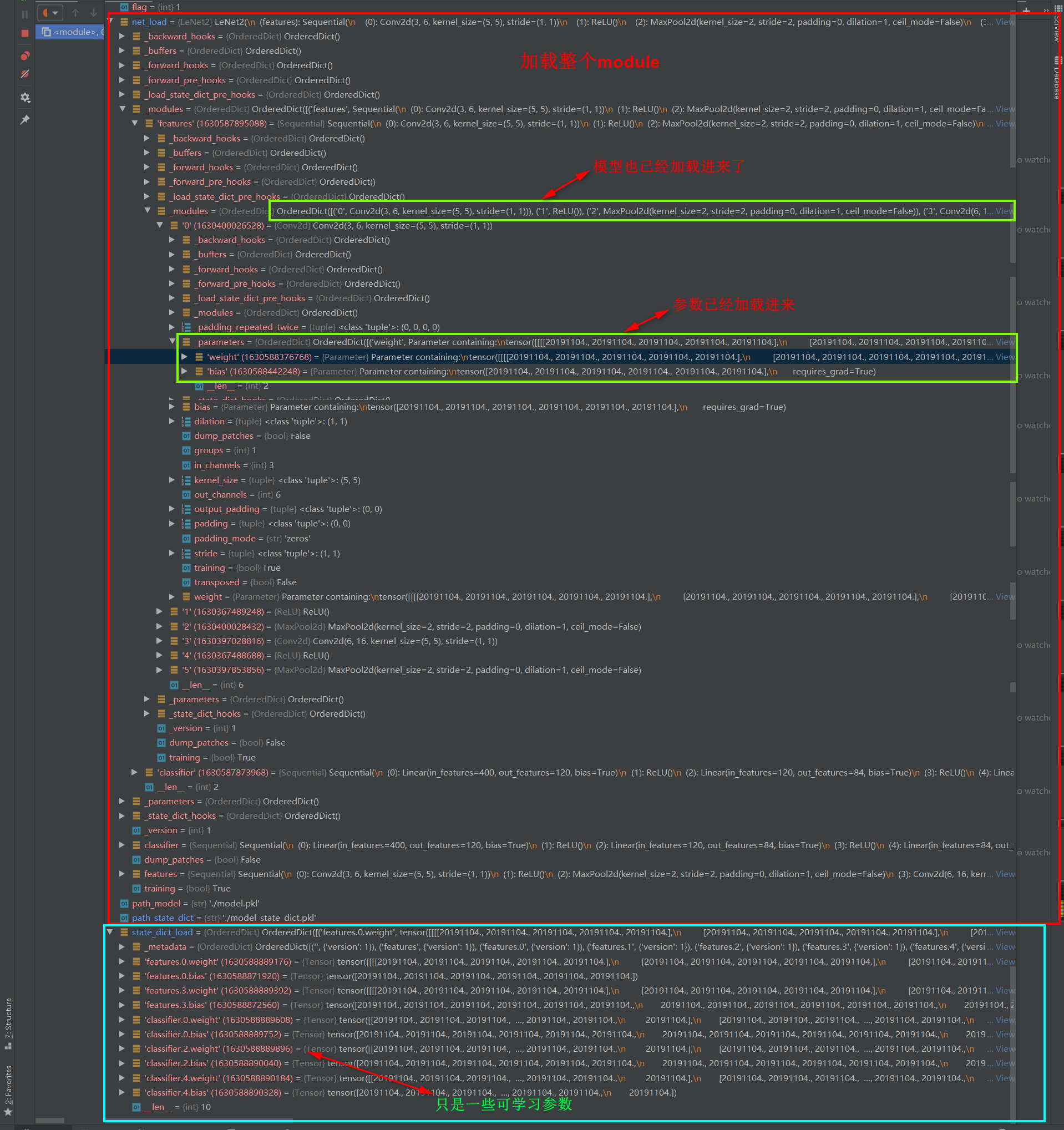
第二种方法:将可学习参数 state_dict_load 提取出来之后,还需要将 state_dict_load 提取出来的可学习参数放到一个模型当中,这样才算完成整个模型的重新加载。
所以通常需要再构建一个模型。这个模型里面的参数我们可以不用重新训练,我们可以通过 load_state_dict() 这个方法将可学习参数放到新的网络当中。这样我们这一网络,这与之前我们会保存下来的网络就是一样的了。因为可学习参数parameters都是一样的。
官方推荐第二种方法:只需要保存模型已经学习好的参数就可以了。
模型的保存与加载,不仅可以使得训练好的模型可以永久使用,而且在我们模型训练过程当中也是十分有用的。这里给大家讲解一个十分有用的技巧 — 断点续训练。
三、模型断点续训练
checkpoint = {
"model_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch
}
可以解决我们因某种意外的原因,导致了模型训练中止而需要重新训练、重复训练的这一个问题。我们知道有的模型很大,需要训练很长时间,假如需要训练10天,但是程序在7天因为某种原因停止运行,那么我们是希望从第零天重新开始训练呢,还是接着第七天开始训练。我们肯定是希望后者。所以我们在模型训练的过程当中,需要有一个机制来**保存模型的训练参数。**以备在意外中断之后可以接着这个 checkpoint 继续去训练,就不用重复的训练了。
那么我们来看一下,我们断点继续训练应该保存哪一些数据呢?我们回顾一下,训练过程主要需要四个模块,一个是数据、一个是模型、一个是损失函数、最后是优化器。
那么这四个模块当中哪些是会随着模型迭代训练和变化的呢?只有模型以及优化器是随着我们的迭代不断的变化的。我们知道数据是不变的,损失函数只是一个函数,也有没有可变的参数。而模型当中的权值等可学习参数是会变化的。优化器当中也有数据会变化,优化器中会有一些buffer、一些缓存。例如moment还要用到指数加权平均,之前的状态信息需要存储下来进行缓存。所以优化器中也有可变的参数。
因此我们知道整个 checkpoint 需要保存的数据,一个是模型的数据,一个是优化器数据。迭代次数epoch也要记录下来。我们要知道是在第几次训练的模型被保存下来。
其实以上所说的只是最基本的一个 checkpoint 要保存的数据。有的时候还会保存loss值或是一些指标,用来指示当前的一个模型的状态。下面我们来模拟意外中断,然后再续训练。
模型训练代码, 在第5个epoch中断
# -*- coding: utf-8 -*-
"""
# @Time : 2020/5/13 9:15
# @Author : DarrenZhang
# @FileName: 03_save_checkpoint.py
# @Software: PyCharm
# @Blog :https://www.yuque.com/darrenzhang
# @Brief : 模拟训练意外停止
"""
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from PIL import Image
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import set_seed
import torchvision
set_seed(1) # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
checkpoint_interval = 5
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
train_dir = "H:/PyTorch_From_Zero_To_One/data/rmb_split/train"
valid_dir = "H:/PyTorch_From_Zero_To_One/data/rmb_split/valid"
print(train_dir)
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=6, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
start_epoch = -1
for epoch in range(start_epoch+1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
if (epoch+1) % checkpoint_interval == 0:
checkpoint = {"model_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch}
path_checkpoint = "./checkpoint_{}_epoch.pkl".format(epoch)
torch.save(checkpoint, path_checkpoint)
if epoch > 5:
print("训练意外中断...")
break
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss.item())
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val/len(valid_loader), correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
断点续训练
# -*- coding: utf-8 -*-
"""
# @Time : 2020/5/13 9:20
# @Author : DarrenZhang
# @FileName: 04_checkpoint_resume.py
# @Software: PyCharm
# @Blog :https://www.yuque.com/darrenzhang
# @Brief : checkpoint 续训练
"""
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from PIL import Image
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
from tools.common_tools import set_seed
import torchvision
set_seed(1) # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
checkpoint_interval = 5
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
train_dir = "H:/PyTorch_From_Zero_To_One/data/rmb_split/train"
valid_dir = "H:/PyTorch_From_Zero_To_One/data/rmb_split/valid"
print(train_dir)
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.RandomGrayscale(p=0.8),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=6, gamma=0.1) # 设置学习率下降策略
# ============================ step 5+/5 断点恢复 ============================
path_checkpoint = "./checkpoint_4_epoch.pkl"
checkpoint = torch.load(path_checkpoint)
net.load_state_dict(checkpoint['model_state_dict']) # 模型参数更新
optimizer.load_state_dict(checkpoint['optimizer_state_dict']) # 模型优化器更新
start_epoch = checkpoint['epoch'] # 模型迭代次数要更新
#### 下面一步也是不可缺少的,更新学习率的epoch
scheduler.last_epoch = start_epoch # last_epoch:上一个epoch
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(start_epoch + 1, MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
if (epoch+1) % checkpoint_interval == 0:
checkpoint = {"model_state_dict": net.state_dict(),
"optimizer_state_dic": optimizer.state_dict(),
"loss": loss,
"epoch": epoch}
path_checkpoint = "./checkpint_{}_epoch.pkl".format(epoch)
torch.save(checkpoint, path_checkpoint)
# if epoch > 5:
# print("训练意外中断...")
# break
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
valid_curve.append(loss.item())
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val/len(valid_loader), correct / total))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()

若有收获,就点个赞吧
0 人点赞
